OpenAI Realtime API 深度技术架构与实现指南——如何实现AI实时通话
OpenAI Realtime API实现了AI交互从传统请求-响应到流式多模态的范式转变,通过WebSocket/WebRTC提供毫秒级延迟的实时对话体验。其核心创新包括:1)有状态会话模型实现上下文持久化;2)原生多模态处理消除级联架构延迟;3)灵活的话轮控制机制支持打断功能。技术规范涵盖音频编码标准(24kHz PCM)、事件驱动协议和成本优化策略,为开发者构建实时语音AI应用提供了完整框架
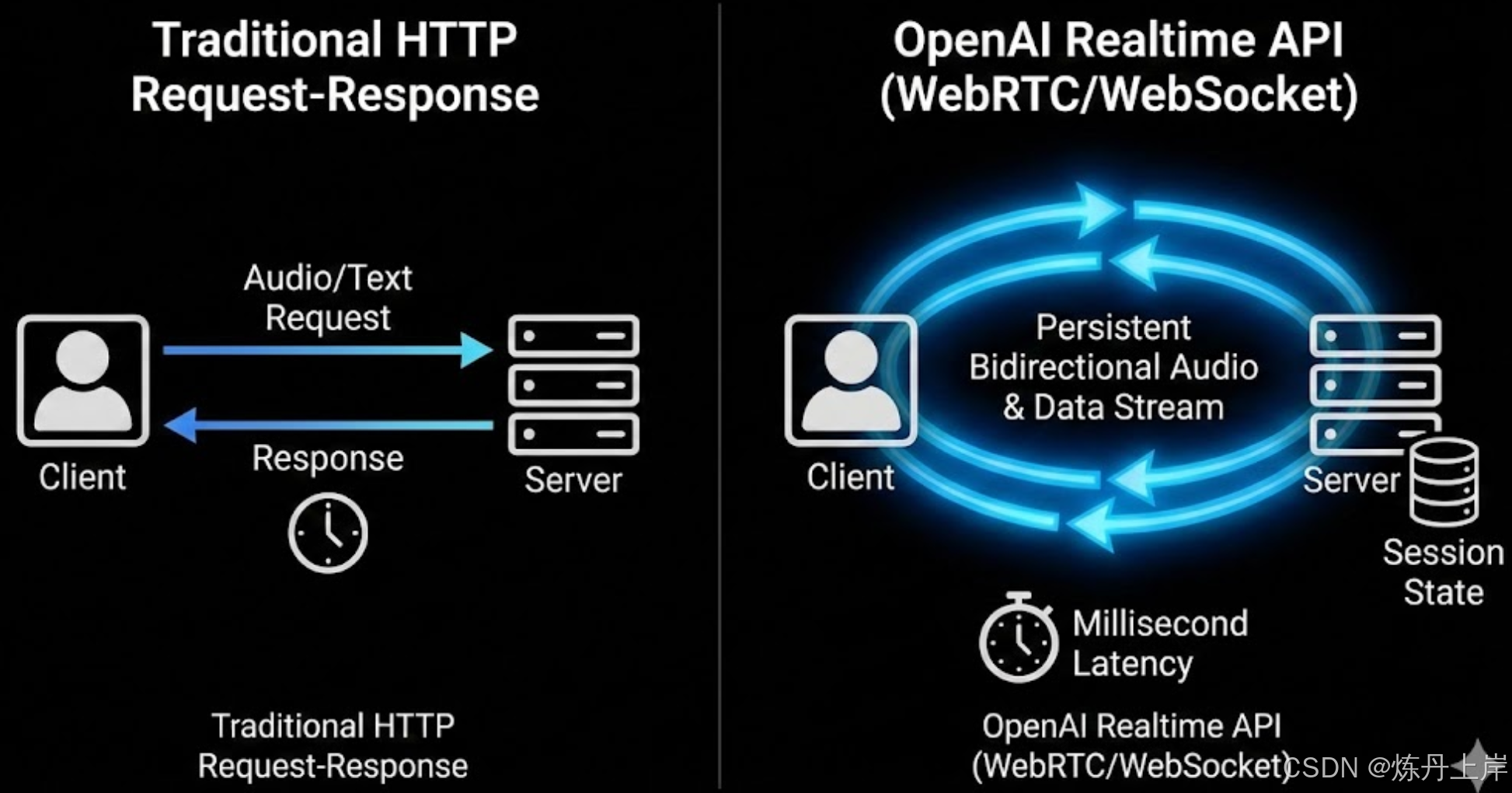
执行摘要:从请求-响应到流式多模态的范式转变
OpenAI Realtime API 标志着 AI 交互从传统的 HTTP 请求-响应模型向持久化、有状态连接架构的根本性转变。通过 WebSocket 和 WebRTC,它实现了毫秒级延迟、原生的“打断”功能以及音视频流的并行传输,将模型从被动的指令执行者重构为具备实时感知能力的“对话伙伴”。
1. 核心架构与能力分析
Realtime API 基于 GPT-4o 模型,摒弃了传统的级联架构(ASR -> LLM -> TTS),采用原生多模态处理,消除了信息损耗和延迟叠加。
1.1 有状态会话模型 (Stateful Session Model)
与无状态的 REST API 不同,Realtime API 引入了**会话(Session)**概念:
- 状态持久化 (State Persistence): 服务器自动维护对话历史、配置和音频缓冲区,客户端无需重复上传上下文,降低带宽消耗。
- 配置作用域 (Configuration Scope): 支持全局默认配置,同时也允许通过
response.create事件对单次响应进行“覆盖”配置(例如:从“教学模式”临时切换为“指令确认模式”)。 - 生命周期管理 (Lifecycle Management): 会话持续至连接断开或达到 60 分钟上限。客户端需实现健壮的重连逻辑以应对网络波动。
1.2 原生多模态 vs. 传统级联架构
| 特性 | 传统级联架构 (ASR+LLM+TTS) | Realtime API (原生多模态) |
|---|---|---|
| 处理流程 | 串行处理 (识别->生成->合成) | 端到端流式处理 (Speech-to-Speech) |
| 延迟 | 高 (各阶段延迟叠加) | 极低 (毫秒级) |
| 非语言信息 | 丢失 (情感、语调被剥离) | 保留 (感知讽刺、急切、犹豫等) |
| 情感表达 | 机械,缺乏语境感 | 根据语境自适应情感语调 |
1.3 语音活动检测 (VAD) 与话轮转换
- 服务器端 VAD (默认): 自动检测静音触发响应。优点是开发门槛低,缺点是可能在用户思考停顿时的误判(抢话)。
- 客户端手动控制 (Push-to-Talk): 设置
turn_detection: null。客户端通过input_audio_buffer.commit显式控制发送。适用于对讲机或嘈杂环境。 - 混合调节模式 (Hybrid Moderation): 开启 VAD 但禁用自动响应 (
create_response: false)。适用于“人在回路”场景(如内容审查、RAG 查询后再触发回复)。
2. 连接协议深度解析
根据集成环境不同,提供三种连接协议:
2.1 WebRTC:浏览器与客户端首选
基于 UDP 传输,利用抖动缓冲和丢包隐藏技术,适合不稳定网络。
- 安全机制: 使用临时令牌 (Ephemeral Token)。后端持有 API Key 并生成临时令牌,前端浏览器使用该令牌直接连接 OpenAI,避免密钥暴露和音频路由延迟。
- SDP 握手:
- 客户端创建
RTCPeerConnection和oai-events数据通道。 - 发送 SDP Offer 至
/v1/realtime/calls。 - 接收 SDP Answer 完成连接。
- 注:音频走 MediaStreamTrack,控制指令走数据通道。
2.2 WebSocket:服务器端集成中枢
适用于 Server-to-Server 场景。
- 端点:
wss://api.openai.com/v1/realtime?model=gpt-realtime - 认证: HTTP Header 中直接使用
Authorization: Bearer sk-...。 - 挑战: 需手动封装音频(Base64 编码的 JSON 消息),相比原始二进制体积增加约 33%,且需自行管理音频分帧(建议 20ms-60ms)。
2.3 SIP:传统电信网络的桥梁
允许 PSTN 电话直接接入 AI。
- 配置: 将 Twilio/Vonage 的 SIP Trunk 指向
sip:$PROJECT_ID@sip.api.openai.com;transport=tls。 - 鉴权与路由: 通过 Webhook (
realtime.call.incoming) 处理呼入请求,返回 JSON 决定接听或挂断,并可注入初始配置。
3. 音频工程规范与最佳实践
3.1 输入音频硬性指标
⚠️ 严禁直接传输错误格式
Realtime API 不支持自动格式转换。任何偏差都会导致噪音或连接失败。
- 编码: PCM (Pulse Code Modulation)
- 采样率: 24,000 Hz (24kHz)
- 位深: 16-bit
- 声道: 单声道 (Mono)
- 字节序: Little-endian
关键陷阱:重采样 (Resampling)
传统电话系统通常为 8kHz,VoIP 为 16kHz。必须在发送给 OpenAI 前使用 ffmpeg/sox 将其插值提升至 24kHz,否则会导致严重的变调(慢放效果)。
3.2 输出音频处理
- 格式: 24kHz PCM 16-bit 裸流(无 WAV 头)。
- 播放: 客户端需实现抖动缓冲区 (Jitter Buffer)(如缓存 50-100ms)以平滑播放。如需保存文件,需手动添加 44 字节 WAV 头。
3.3 回声消除 (AEC)
- 必要性: 防止模型听到自己的声音而触发打断。
- WebRTC: 浏览器自带 (
echoCancellation: true)。 - WebSocket/SIP: 需开发者自行集成 DSP 库或依赖运营商的网络侧消除。
4. 事件驱动协议与状态机模型
4.1 关键客户端事件 (Client Events)
| 事件名称 | 关键 Payload | 描述与注意点 |
|---|---|---|
session.update |
instructions, voice |
更新全局配置。慎用: 中途修改系统指令可能导致上下文漂移。 |
input_audio_buffer.append |
audio (Base64) |
高频事件。服务器不返回确认,依赖底层协议可靠性。 |
input_audio_buffer.commit |
- | 仅 PTT 模式使用。强制提交缓冲区,翻转 VAD 状态。 |
response.create |
response |
触发推理。允许通过 instructions 覆盖单次回复的配置。 |
conversation.item.create |
item |
注入对话历史(如系统消息、函数调用结果)。不能用于直接注入音频。 |
4.2 关键服务器事件 (Server Events)
| 事件名称 | 描述 | 用途 |
|---|---|---|
input_audio_buffer.speech_started |
检测到用户说话 | 打断信号。UI 显示“聆听中”,立即停止播放当前音频。 |
response.audio.delta |
实时音频流 | Base64 音频数据。需立即解码并推入播放缓冲区。 |
response.audio_transcript.delta |
实时文本流 | 用于前端字幕展示。 |
response.done |
响应结束 | 包含 Token 消耗统计。计费和日志记录的最佳时机。 |
4.3 “打断” (Barge-in) 实现逻辑
- 服务器检测: 发送
speech_started事件,停止推理,回滚上下文(删除未播放内容的记录)。 - 客户端响应:
- 立即清空本地音频队列 (
input_audio_buffer.clear)。 - 调用音频引擎
stop()。 - UI 切换状态。
5. 函数调用 (Function Calling)
5.1 标准生命周期
- 定义: 在
session.update中定义工具。 - 识别: 模型发送
response.done(type:function_call)。 - 执行: 客户端执行本地代码。
- 回填: 发送
conversation.item.create(type:function_call_output)。 - 触发: 发送
response.create请求模型基于结果生成回复。
5.2 填补“静默期” (Dead Air)
为避免 API 调用期间的尴尬沉默,建议采用以下策略:
- 填充词机制: 检测到
function_call时,立即播放预录制的音效(键盘声)或语音(“正在查询…”)。 - 带外响应: 对于无需语音反馈的操作(如调暗背景),让模型生成
conversation: "none"的回复,仅在客户端执行 UI 变更。
6. 面向语音的提示词工程 (Prompt Engineering)
- 简洁性原则: 语音对冗余容忍度低。System Prompt 需强约束:“回答极其简练,禁止列表格式,像打电话一样自然”。
- 禁止 Markdown: 严禁输出
**加粗**或###,TTS 会将其朗读出来造成体验事故。 - 情感引导: 通过指令(“富有同情心”、“语速缓慢”)直接改变模型的声学特征(音高、节奏)。
- 音色锁定: 音色在会话首帧确定后不可变更。
7. 经济模型与配额
7.1 计费参考 (Based on GPT-4o Realtime)
| 计费项 | 估算价格 (每百万 Token) | 说明 |
|---|---|---|
| 文本输入 | ~$5.00 | 上下文历史、System Prompt。 |
| 音频输入 | ~$40.00 | 用户说话内容。 |
| 文本输出 | ~$20.00 | 模型生成的文本思维链。 |
| 音频输出 | ~$80.00 | 成本黑洞。模型生成的语音。 |
(注:价格仅供参考,请以 OpenAI 官网实时公示为准)
7.2 成本优化
- 纯转录模式: 设置
session.type: transcription,仅识别不生成语音。 - 极致简洁: 强制模型一句话回答。
- 文本辅助: 长内容通过
output_modalities: ["text"]发送文本卡片,而非朗读全文。
8. 集成路线图
- 阶段一:原型验证 (WebRTC)
- 工具:Browser + JS。
- 目标:跑通 Hello World,验证网络穿透和麦克风权限。
- 阶段二:服务器编排 (WebSocket)
- 工具:Node.js/Python 后端。
- 目标:实现函数调用、数据库连接、Base64 音频流处理。
- 阶段三:全渠道接入 (SIP)
- 工具:Twilio/Vonage。
- 目标:落地电话场景,解决重采样和 PSTN 特有延迟。
- 阶段四:生产级加固
- 速率限制: 实现网关层排队或降级策略。
- 可观测性: 记录
response.audio_transcript.delta日志,监控首字延迟 (TTFT) 和 WebSocket 异常。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 29
29 0
0- 0



 已为社区贡献46条内容
已为社区贡献46条内容

所有评论(0)