顶级性价比:Gemini 3 Flash 实战指南
【摘要】Gemini3Flash颠覆行业认知,以1/4价格实现超越Pro模型的性能表现。其核心优势在于:1)具备自检逻辑能力,HLE测试成绩提升3倍,适合代码审查等高频场景;2)创新的ContextCaching技术将缓存成本降至$0.05/MB,大幅降低长文本处理费用;3)多模态能力突出(MMMU-Pro81.2%),特别适合实时视频流分析。建议开发者采用CoT机制提升准确性,配合指数退避策略优

如果你还在无脑调用 Gemini 3 Pro 或者死等 GPT-5.2 的生成进度条,那你大概率是在给大厂交智商税。谷歌刚发布的 Gemini 3 Flash 根本不是什么阉割版,它是专门为了把 Pro 模型赶下神坛而生的。用四分之一的价格跑出比 Pro 还猛的逻辑,这才是 2025 年底开发者该有的觉醒。
1. 别把牛马当苦力,它能自检逻辑
以前我们用 Flash 模型,纯粹是因为它便宜、响应快,拿它当个分词器或者“格式转换器”。但 Gemini 3 Flash 这一次在 HLE(人类终极难题)测试里拿下了 33.7%,比上一代 2.5 Flash 的 11% 翻了三倍。这意味着它不再是只会搬砖的苦力,而是一个具备多轮自检(Self-Correction)能力的逻辑代理。
实操建议:别再用昂贵的 Pro 跑日常的 Code Review 了。直接把 Flash 接入 CI/CD,让它针对每一行改动去做安全扫描。它能在一秒钟内扫完一万行代码并指出逻辑漏洞,这种吞吐量是那些贵族模型根本给不了的。如果担心准确率,因为 Flash 够快够便宜,你完全可以让它在后台自己跟自己复核三次,跑三轮推理的综合耗时和成本依然比 Pro 单次推理要低,但结果的鲁棒性直接爆表。

2. 暴力并发:Context Caching 的省钱逻辑
省钱只是表象,真正的护城河是利用低成本实现的暴力并发。很多哥们儿反馈 Gemini API 调着调着发现 Token 消耗太快,那是因为你没用好 Context Caching(上下文缓存)。在这个版本里,谷歌把缓存成本压到了 $0.05/MB 左右。
如果你在做一个法律或金融类的 RAG 系统,要把上千页的 PDF 传给模型。以往每问一句话都要重传一次 Context,心都在滴血。现在的正确姿势是: 1. 先把 PDF 这种重资产缓存起来。 2. 设置一个 TTL(过期时间)。 3. 剩下的所有后续对话只付那一点点微乎其微的 Input Token 钱。
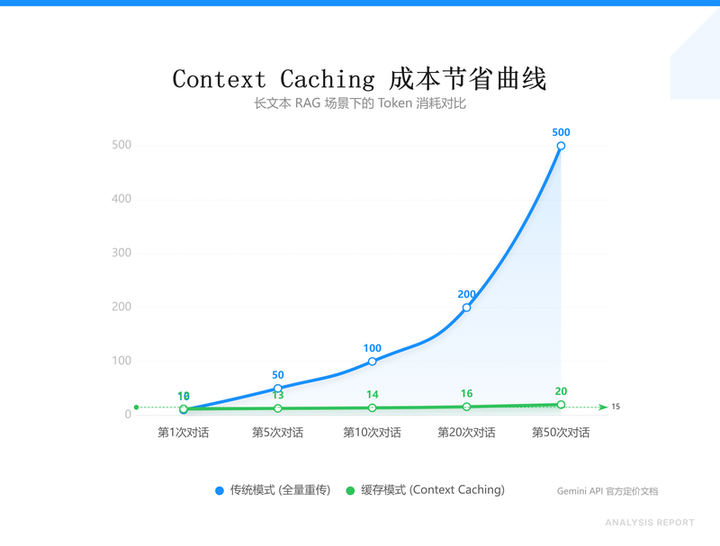
避坑指南:虽然 3 Flash 推理性极强,但在处理超过 50k token 的超长文本时,逻辑回溯偶尔会发生幻觉漂移。解决办法很简单:在 System Instruction 里强制开启 Chain of Thought (CoT),让它输出结果前先写一段隐藏的推理草稿,这能让它的逻辑准确度提升至少 15%。
如果你受够了折腾海外信用卡或者复杂的网络配置,直接去 nunu.chat 试试。
NunuAI 把所有顶级模型(包括这次最火的 Gemini 3 和 GPT-5.2)都聚合在了一起,国内直连,送的免费额度足够你把这些牛马模型驯服,省去了一堆环境搭建的破事儿。
3. 多模态实战:当牛马学会了盯监控
Gemini 3 Flash 的 MMMU-Pro 跑分是 81.2%,这个分数已经把 GPT-5.2 甩在后面了。最实用的场景不是让它画图,而是视频理解。如果你有大量的长视频需要切片或者提取关键帧逻辑,3 Pro 的响应延迟会让你想撞墙。而 3 Flash 配合 API 的抽帧功能,能实现近乎实时的视频流监控。
手把手调优参数: * 视频处理:不要直接塞整个原始文件。利用 API 的抽帧功能,每秒抽 1-2 帧就足够它理解逻辑了。 * 温度设置:做逻辑提取建议把 Temperature 设为 0.1 以下;如果是做创意脚本,0.7 是上限。 * 响应抖动:虽然 Flash 号称飞快,但在高并发请求下,首字延迟依然会有波动。建议在客户端加上指数退避重试(Exponential Backoff)机制,别让一次网络波动毁了你的 Agent 链路。

现在的 AI 圈子早已不是“大力出奇迹”的草莽时代,而是工程效率的时代。Gemini 3 Flash 的出现,宣告了昂贵模型只能作为“最终决策者”存在,而中间 90% 的业务逻辑、长对话管理和多模态理解,都应该是 3 Flash 这种极致性价比选手的战场。懂行的已经换装了,你还在等什么?

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)