Atlas 800T A2 训练卡 推理优化的工程手册
本文介绍了在昇腾NPU上高效运行大语言模型的实践方案。通过vLLMAscend插件实现昇腾NPU与vLLM框架的无缝对接,结合MindIETurbo加速套件,可在Atlas800TA2训练卡上实现高效推理。文章详细说明了从环境配置、模型下载到推理优化的完整流程,包括Python环境搭建、模型加载、推理参数设置等关键步骤,并提供了性能优化建议和常见问题解决方案。重点强调了输入控制、显存管理和稳定性保
国产大模型落地三件套:模型权重、推理框架、算力底座。当国内主流模型如 Qwen 已经开源、推理框架如 vLLM 已经成熟,最后一道门槛就是算力。
vLLM Ascend是用于在昇腾NPU上高效运行vLLM推理框架的硬件适配插件,实现了昇腾NPU与vLLM框架的无缝对接。借助MindIE Turbo昇腾通用加速套件可在昇腾NPU上实现高效大语言模型推理支持,达到更大的吞吐、更低的时延。
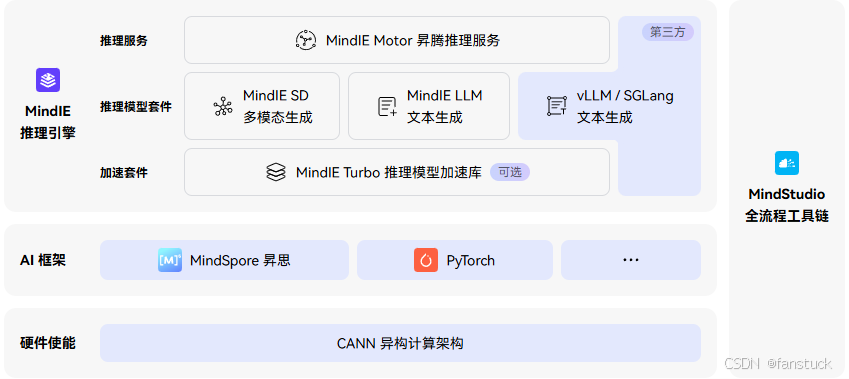
想用国产算力跑通主流 SOTA 模型,Atlas 800T A2 训练卡是目前开箱即用、性能不缩水的主流方案。
目前已支持模型如下:
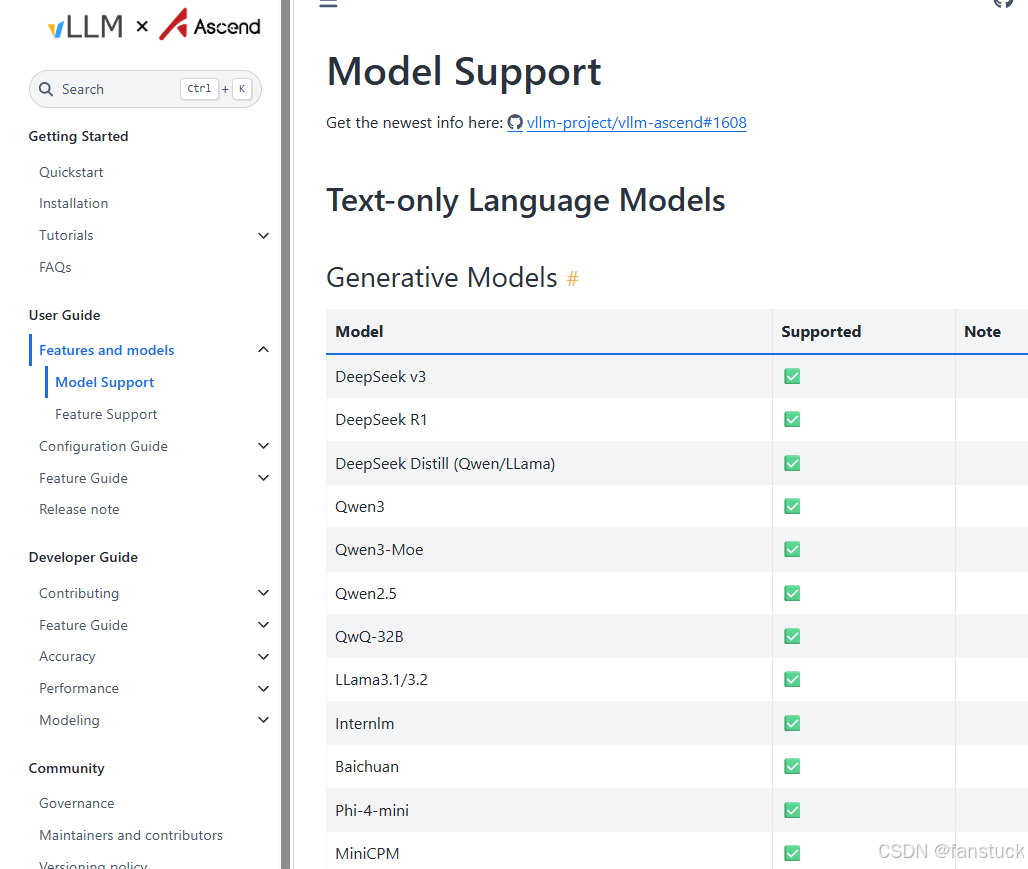
地址详情如下:https://docs.vllm.ai/projects/ascend/en/latest/
快速跑通 Llama3-8B
环境配置
如果你对在Atlas 800T A2 训练卡跑模型有兴趣,但是没环境也没关系,
地址如下:https://ai.gitcode.com/dashboard?tab=created&subtab=all
本教程以单个NPU为主。
激活Notebook
直接选择Atlas 800T A2 训练卡即可,如图所示:
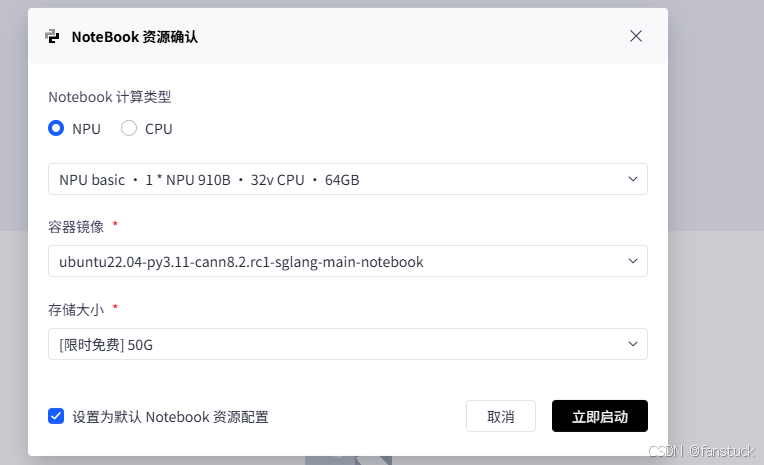
点击立即启动。
模型下载
pip install -U openmind-hub
import os
from openmind_hub import snapshot_download
os.environ["OPENMIND_HUB_ENDPOINT"] = "https://hub.gitcode.com"
# 由于系统限制,模型默认下载到root路径下,如果需要指定路径,需要给新下载的模型开通白名单路径
os.environ["HUB_WHITE_LIST_PATHS"] = '/opt/huawei/edu-apaas/src/init/model/Llama3-8B-Chinese-Chat'
# 如果是三级目录,将第一个/ 换成 %2F
snapshot_download("hf_mirrors%2Fshenzhi-wang/Llama3-8B-Chinese-Chat", local_dir = './model/Llama3-8B-Chinese-Chat')
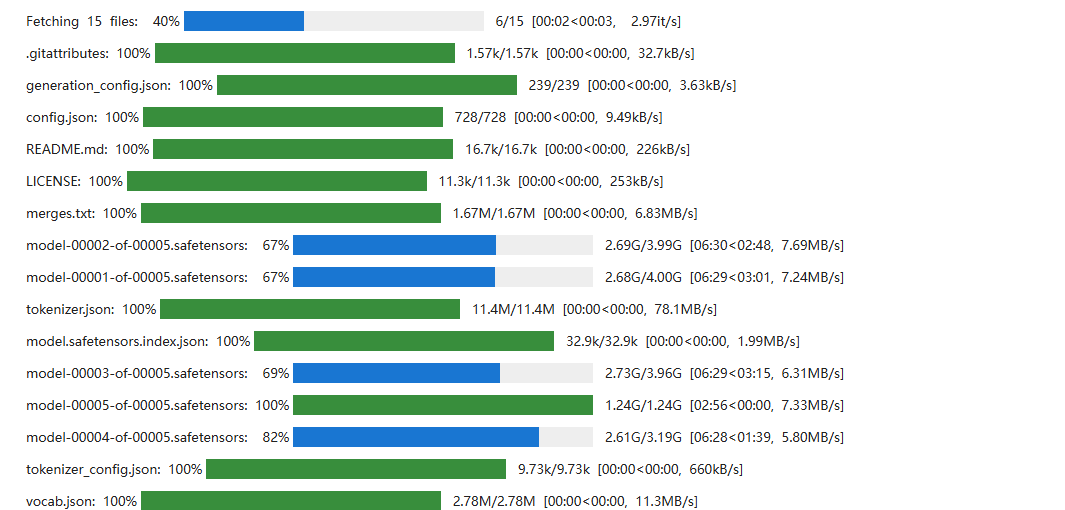
这边系统默认是py3.8环境,但是这里的依赖都是基于3.9+的,所以我们需要安装下py高版本环境。
安装 Miniconda
1.1 下载安装包
-
ARM 架构(aarch64)
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh -O miniconda.sh
-
x86_64 架构
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O miniconda.sh
1.2 执行安装
bash miniconda.sh
安装提示:
路径建议:
~/miniconda3(回车确认)自动写入
.bashrc:输入yes
1.3 激活 Conda
source ~/.bashrc conda --version
创建 Python 虚拟环境
2.1 创建名为 myenv 的 Python 3.10 环境
conda create -n myenv python=3.10
2.2 激活环境
conda activate myenv
配置 Jupyter Notebook 内核
3.1 安装 Jupyter 与 ipykernel
在 myenv 环境中执行:
conda install jupyter ipykernel
3.2 将环境注册为 Notebook 内核
python -m ipykernel install --user --name=myenv --display-name "Python (myenv)"
| 参数 | 说明 |
|---|---|
--name=myenv |
内核系统标识名(建议与 Conda 环境名一致) |
--display-name |
Notebook 界面显示的名称,可自定义,如 "Python 3.10 (My Project)" |
在线推理
推理之前我们先安装下基本环境。
pip install -U transformers torch_npu==2.5.1 torch accelerate numpy==1.26.4 scipy
推理demo代码如下:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
import torch_npu
model_name = "./model/Llama3-8B-Chinese-Chat"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto"
).to("npu:0")
prompt = "比较一下9.11和9"
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to('npu:0')
generated_ids = model.generate(
**model_inputs,
max_new_tokens=1024
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content) # no opening <think> tag
print("content:", content)
最终效果如下:

性能优化
我还是按自己的习惯来,把做法讲稳,把边界摆清楚。下面这些优化都是我在昇腾 NPU(Atlas 800T A2)上跑大模型时实测出来的,偏工程,能直接拿去用。没有花里胡哨,只有能让你少踩坑的细节。
环境校准与运行参数
-
设置必要的环境变量,降低无关警告、避免回退到 CPU:
export ASCEND_SKIP_CPU_FALLBACK_WARNING=1 export TRANSFORMERS_CACHE="/home/service/.cache/huggingface/hub"
-
检查设备与驱动匹配,优先用
npu-smi info确认型号、温度、HBM 占用;有异常先处理稳定性,再谈性能。 -
只用一个设备跑通先验流程(
npu:0),多设备扩展前先把单卡状态控稳。
模型加载与缓存
-
统一缓存目录,避免重复下载与磁盘抖动;加载时显式指向缓存。示例:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch, os
os.environ["TRANSFORMERS_CACHE"] = "/home/service/.cache/huggingface/hub"
model_name = "./model/Llama3-8B-Chinese-Chat"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
trust_remote_code=True,
).to("npu:0").eval()
-
精度选择偏稳:
torch.float16。如果出现数值不稳定或某些算子不支持,再考虑bfloat16或auto,但要确认算子兼容性。 -
加载完成后打印一次显存占用用于基线确认:
print(f"显存占用: {torch.npu.memory_allocated()/1e9:.2f} GB")
推理参数与生成策略
-
先把采样关掉,追求可复现与稳定:
GEN_CFG = {
"max_new_tokens": 256,
"min_new_tokens": 32,
"do_sample": False,
"temperature": 0.0,
"top_p": 1.0,
"pad_token_id": tokenizer.eos_token_id,
}
-
输入控制更重要:合理截断(例如 512~1024 token)能显著降低显存压力;极长上下文先做摘要或滑窗分片。
-
对话类模型优先走官方模板(
apply_chat_template),避免自己拼接导致特殊符号错位。
计时与资源观测
-
每次生成做最小埋点:耗时、生成 token 数、速度、显存占用。足够判断是否需要继续优化。
import time
def run_once(model, tokenizer, device, text):
inputs = tokenizer([text], return_tensors="pt").to(device)
start = time.time()
with torch.no_grad():
out = model.generate(**inputs, **GEN_CFG)
elapsed = time.time() - start
total = len(out[0])
prompt = len(inputs["input_ids"][0])
gen_tokens = total - prompt
speed = gen_tokens / elapsed if elapsed > 0 else 0
mem = torch.npu.memory_allocated() / 1e9
print(f"耗时 {elapsed:.2f}s | 生成 {gen_tokens} token | 速度 {speed:.2f} tok/s | 显存 {mem:.2f} GB")
return out
首字节延迟(TTFT)测量
def ttft(text):
inputs = tokenizer([text], return_tensors="pt").to(device)
t0 = time.time()
with torch.no_grad():
_ = model.generate(**inputs, max_new_tokens=1, do_sample=False, pad_token_id=tokenizer.eos_token_id)
return time.time() - t0
messages = [{"role": "user", "content": "用三句话解释 Transformer 的核心思路"}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
print(f"TTFT: {ttft(text):.2f}s")
内存与稳定性
-
控输入、稳精度、少波动。
max_new_tokens是一等公民,别一上来就 1024。 -
连续长时间测试时,适度做同步与清理(别滥用):
torch.npu.synchronize()
-
监控峰值显存,有异常就缩小生成长度或降低并发。
print(f"峰值显存: {torch.npu.max_memory_allocated()/1e9:.2f} GB")
小批量与吞吐权衡
-
小批量(2~4)能提升吞吐,但显存会抬头。先以目标延迟为约束做尝试,再看是否需要改造数据管道。
-
如果以在线交互为主,别为了吞吐牺牲响应稳定性;离线批处理另开配置。
def bench_batch(texts, runs=3):
times = []
for _ in range(runs):
inputs = tokenizer(texts, return_tensors="pt", padding=True, truncation=True).to(device)
t0 = time.time()
with torch.no_grad():
_ = model.generate(**inputs, **GEN_CFG)
times.append(time.time() - t0)
print(f"batch={len(texts)} 平均耗时: {sum(times)/len(times):.2f}s")
messages = [{"role": "user", "content": "简要说明注意力机制的作用"}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
bench_batch([text])
bench_batch([text, text])
def bench(text, runs=5):
times, speeds, mems = [], [], []
for _ in range(runs):
inputs = tokenizer([text], return_tensors="pt").to(device)
t0 = time.time()
with torch.no_grad():
out = model.generate(**inputs, **GEN_CFG)
dt = time.time() - t0
total = len(out[0]); prompt = len(inputs["input_ids"][0])
gen_tokens = total - prompt
speed = gen_tokens / dt if dt > 0 else 0
mem = torch.npu.memory_allocated() / 1e9
times.append(dt); speeds.append(speed); mems.append(mem)
print(f"耗时 平均/方差/极差: {stats.mean(times):.2f}s / {stats.pvariance(times):.4f} / {max(times)-min(times):.2f}s")
print(f"速度 平均/方差/极差: {stats.mean(speeds):.2f}tok/s / {stats.pvariance(speeds):.4f} / {max(speeds)-min(speeds):.2f}")
print(f"显存 平均/峰值: {stats.mean(mems):.2f}GB / {torch.npu.max_memory_allocated()/1e9:.2f}GB")
def set_gen(max_new_tokens=256, min_new_tokens=32, do_sample=False):
GEN_CFG.update({
"max_new_tokens": max_new_tokens,
"min_new_tokens": min_new_tokens,
"do_sample": do_sample,
"temperature": 0.0,
"top_p": 1.0,
"pad_token_id": tokenizer.eos_token_id,
})
messages = [{"role": "user", "content": "用三句话解释 Transformer 的核心思路"}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
print("=== 基线:max_new_tokens=256, do_sample=False ===")
set_gen(256, 32, False); bench(text)
print("=== 缩短输出:max_new_tokens=128 ===")
set_gen(128, 32, False); bench(text)
print("=== 最短输出:max_new_tokens=64 ===")
set_gen(64, 16, False); bench(text)
print("=== 采样开启:do_sample=True(仅观察稳定性变化) ===")
set_gen(128, 32, True); bench(text)
常见坑与替代路径
-
载入报兼容警告:先确认
torch_npu与版本匹配,必要时降版本;不稳定就回到float16与较短上下文。 -
文本异常或乱码:优先检查模板与特殊符号,必要时切换官方分词器版本。
-
显存不够:缩短
max_new_tokens,减少并发,必要时改成流式生成(分段返回),别硬顶。
下面是一次对照实验的原始观测输出(同 Prompt、禁采样),用于判断延迟与稳定性:
13.33s 256 19.21tok/s 15.28GB 11.95s 256 21.43tok/s 15.28GB 11.65s 256 21.97tok/s 15.28GB peak 15.33 GB = 基线:max_new_tokens=256, do_sample=False = 耗时 平均/方差/极差: 5.22s / 0.0570 / 0.64s 速度 平均/方差/极差: 21.84tok/s / 0.0652 / 0.75 显存 平均/峰值: 15.28GB / 15.33GB = 缩短输出:max_new_tokens=128 = 耗时 平均/方差/极差: 5.12s / 0.1031 / 0.82s 速度 平均/方差/极差: 21.92tok/s / 0.0451 / 0.61 显存 平均/峰值: 15.28GB / 15.33GB = 最短输出:max_new_tokens=64 = 耗时 平均/方差/极差: 2.96s / 0.0049 / 0.19s 速度 平均/方差/极差: 21.64tok/s / 0.2683 / 1.37 显存 平均/峰值: 15.28GB / 15.33GB
看完以后我们的完成标准很明确:在同一输入规模下,耗时的极差收敛、速度稳定在目标区间,即可判定优化成立。
总结
跑通是底线,稳定是第一性。我更在意的是你能不能在自己的 NPU 环境里把这套做法复用起来:先把输入控住、把生成参数稳住、把显存和速度观测起来,然后再谈吞吐与并发。性能优化不求花哨,关键是有边界、有取舍、有确认。把这些动作做扎实,你的线上表现自然会好看,而且不需要靠“玄学”去解释每一次波动。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 19
19 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)