【Docker命令】运行支持GPU的本地AI服务
本文详细解析了一条Docker命令,该命令用于启动支持NVIDIA GPU加速的本地AI服务。命令包含基础指令、交互模式、容器命名、端口映射、GPU支持和镜像指定等关键组件。文章深入分析了LocalAI框架的技术特点、CUDA 12生态系统,并列举了典型应用场景和进阶配置示例。同时提供了故障排除指南和性能优化建议,帮助开发者快速部署和管理本地AI服务。这种容器化部署模式体现了现代AI应用的最佳实践
命令概览
docker run -ti --name local-ai -p 8080:8080 --gpus all localai/localai:latest-gpu-nvidia-cuda-12
这条命令通过Docker容器技术启动了一个支持NVIDIA GPU加速的本地AI服务。下面我将逐部分详细解析这个命令的每个组成部分及其工作原理。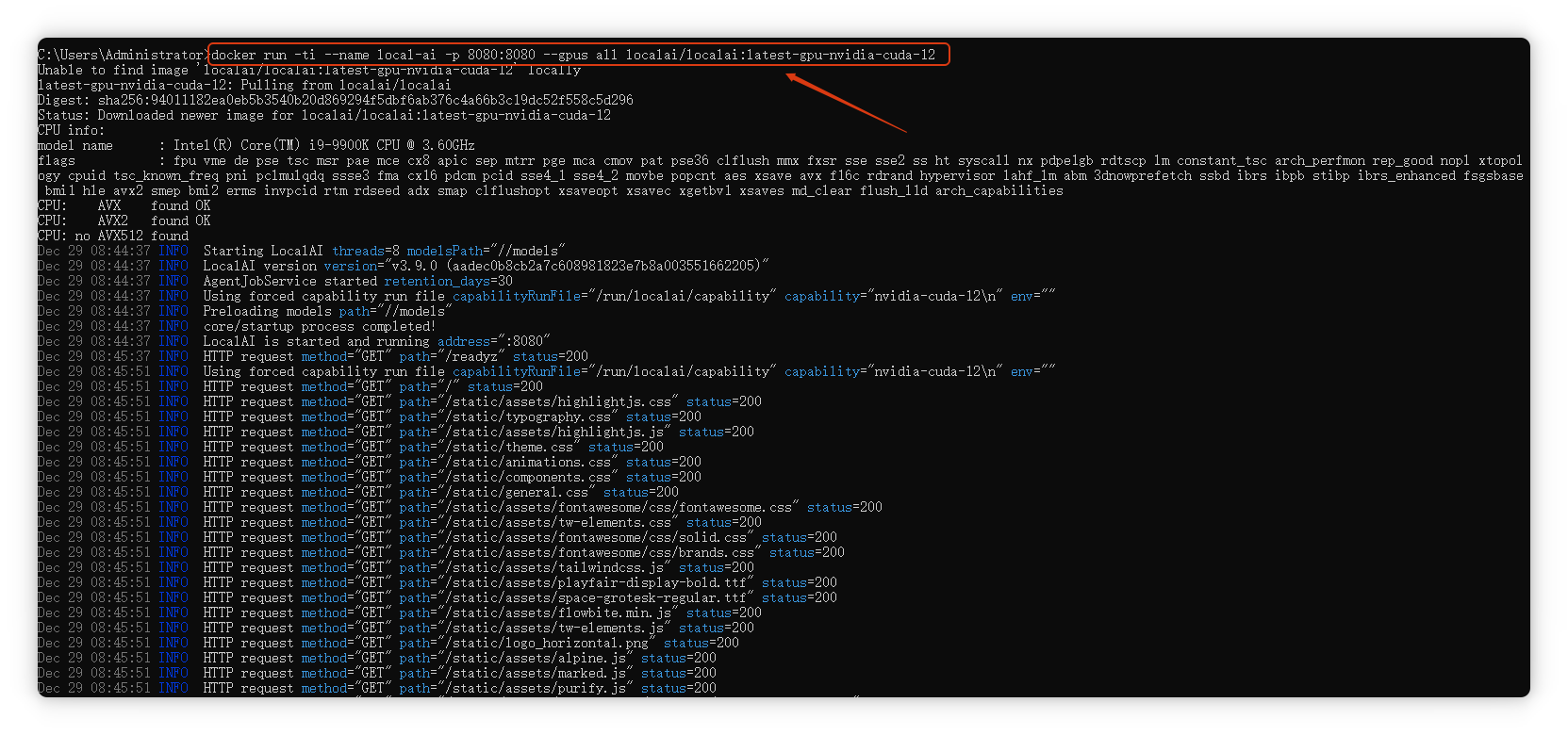
一、命令结构分解
1. 基础指令:docker run
- 作用:创建并启动一个新的Docker容器
- 工作流程:
- 检查本地是否有指定的镜像(
localai/localai:latest-gpu-nvidia-cuda-12) - 如果没有,从Docker Hub拉取镜像
- 根据镜像创建容器实例
- 启动容器并执行预设的启动命令
- 检查本地是否有指定的镜像(
2. 交互模式标志:-ti
-
-t:分配一个伪终端(pseudo-TTY)- 使容器中的命令行界面能够正常显示格式和颜色
- 支持交互式程序的正确显示
-
-i:保持标准输入(STDIN)打开- 允许用户通过键盘与容器进行交互
- 结合
-t参数,实现完整的终端交互体验
-
组合效果:创建一个交互式的终端会话,用户可以直接与容器内的AI服务进行交互,查看实时日志和输出信息。
3. 容器命名:--name local-ai
- 作用:为容器指定一个易读的名称"local-ai"
- 优势:
- 便于管理:可以通过名称而非随机ID引用容器
- 操作便捷:
docker stop local-ai、docker logs local-ai等 - 避免冲突:确保同一时间只有一个名为"local-ai"的容器运行
4. 端口映射:-p 8080:8080
-
语法:
-p 宿主机端口:容器端口 -
具体含义:
- 容器内部服务监听在8080端口
- 映射到宿主机的8080端口
-
网络架构:
用户浏览器/客户端 → 宿主机IP:8080 → Docker网络桥接 → 容器IP:8080 -
访问方式:启动后可通过
http://localhost:8080或http://宿主机IP:8080访问AI服务
5. GPU支持:--gpus all
-
关键技术:NVIDIA Container Toolkit
-
作用:将宿主机的GPU资源暴露给Docker容器
-
支持的GPU功能:
- CUDA计算能力
- cuDNN深度学习加速库
- Tensor Core张量核心
- GPU显存访问
-
前提条件:
- 宿主机安装NVIDIA GPU驱动
- 安装NVIDIA Container Toolkit
- Docker配置支持GPU运行时
6. 镜像指定:localai/localai:latest-gpu-nvidia-cuda-12
-
镜像仓库:
localai/localai(Docker Hub上的官方仓库) -
标签含义:
latest-gpu-nvidia-cuda-12:支持CUDA 12的最新GPU版本
-
镜像包含内容:
- 操作系统基础(通常是Ubuntu或Debian)
- CUDA 12工具包和运行时
- cuDNN等深度学习库
- LocalAI框架及其依赖
- 预配置的AI模型和工具链
二、技术栈深度解析
LocalAI框架
LocalAI是一个开源项目,旨在本地复现OpenAI API接口,具有以下特点:
-
兼容性:
- 提供与OpenAI API兼容的REST接口
- 支持相同的请求/响应格式
- 兼容现有的OpenAI客户端库
-
本地化优势:
- 数据隐私:所有计算在本地完成
- 无网络延迟:推理速度快
- 无使用费用:一次性部署成本
-
支持模型:
- GPT系列模型
- 视觉模型
- 嵌入模型
- 语音模型
CUDA 12生态系统
CUDA 12是NVIDIA最新的并行计算平台:
-
架构特性:
- 支持最新的NVIDIA GPU架构(Hopper、Ada Lovelace等)
- 改进的编译器和工具链
- 增强的库性能
-
容器化优势:
- 环境一致性:确保CUDA版本与所有依赖匹配
- 隔离性:避免与系统CUDA版本冲突
- 可移植性:相同的镜像可在不同系统运行
三、典型应用场景
1. AI模型开发与测试
# 开发者可以快速搭建测试环境
curl -X POST http://localhost:8080/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-4",
"prompt": "Hello, AI",
"max_tokens": 50
}'
2. 私有AI服务部署
- 企业内部知识库问答系统
- 敏感数据处理和分析
- 实时AI应用服务
3. 研究和教育用途
- 无需昂贵API密钥即可学习AI开发
- 可完全控制模型参数和配置
- 支持自定义模型集成
四、进阶配置示例
1. 持久化存储
docker run -ti --name local-ai \
-p 8080:8080 \
--gpus all \
-v /path/to/models:/models \
-v /path/to/config:/config \
localai/localai:latest-gpu-nvidia-cuda-12
2. 资源限制
docker run -ti --name local-ai \
-p 8080:8080 \
--gpus all \
--memory="16g" \
--cpus="8" \
localai/localai:latest-gpu-nvidia-cuda-12
3. 环境变量配置
docker run -ti --name local-ai \
-p 8080:8080 \
--gpus all \
-e THREADS=8 \
-e CONTEXT_SIZE=2048 \
localai/localai:latest-gpu-nvidia-cuda-12
五、故障排除指南
常见问题1:GPU无法访问
# 验证NVIDIA Container Toolkit安装
docker run --rm --gpus all nvidia/cuda:12.0-base nvidia-smi
# 检查Docker运行时配置
cat /etc/docker/daemon.json
常见问题2:端口冲突
# 查看端口占用
sudo lsof -i :8080
# 修改映射端口
docker run -ti --name local-ai -p 9090:8080 ...
常见问题3:镜像拉取失败
# 使用国内镜像源
docker pull registry.cn-hangzhou.aliyuncs.com/localai/localai:latest-gpu-nvidia-cuda-12
六、性能优化建议
-
GPU显存管理
- 根据模型大小调整批处理大小
- 使用
--gpus '"device=0"'指定特定GPU - 监控显存使用:
nvidia-smi -l 1
-
容器资源调优
- 调整CPU核心绑定
- 配置合适的交换空间
- 优化磁盘I/O
-
网络优化
- 使用主机网络模式减少NAT开销
- 配置合适的网络缓冲区大小
总结
这条Docker命令体现了现代AI应用部署的最佳实践:
- 容器化封装:将复杂的AI软件栈打包成标准化单元
- GPU加速:充分利用硬件性能
- 服务化暴露:通过标准HTTP接口提供服务
- 开发运维一体化:简化了部署和管理的复杂度
通过这种方式,开发者可以在几分钟内部署一个功能完整的本地AI服务,既保证了性能,又确保了数据隐私和系统安全。这种模式正在成为企业级AI应用部署的新标准,平衡了效率、安全性和成本控制的多重要求。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 26
26 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)