AI基石 | 特征值分解:它是矩阵的“灵魂”,更是大模型 LoRA 微调的基石
特征值分解是矩阵的核心数学工具,揭示了数据的内在结构。通过提取矩阵的特征向量和特征值,可以识别数据变换中的主要方向与能量分布。这一原理在AI领域广泛应用:PCA降维利用协方差矩阵的特征值分解保留关键信息;大模型微调技术LoRA则基于矩阵的低秩特性(源于特征值分布),将巨大参数矩阵分解为小型矩阵乘积,实现高效参数更新。特征值分解从数学理论演变为支撑现代AI技术的重要基石,其"提取主成分"的思想贯穿了
AI基石 | 特征值分解:它是矩阵的“灵魂”,更是大模型 LoRA 微调的基石
前言 在上一期,我们通过力扣“旋转图像”一题,直观感受了矩阵作为“变换工具”的威力。如果说矩阵旋转是在操纵数据的表面形态,那么今天我们要讲的特征值分解(Eigenvalue Decomposition),则是在挖掘数据的内在灵魂。
在 AI 的自学路线中,你可能听过无数次 PCA 降维、SVD 分解,或者如今大红大紫的大模型微调技术 LoRA(Low-Rank Adaptation)。请记住,这些高大上技术的数学源头,都指向同一个概念——特征值分解。
今天,我们不谈枯燥的定理证明,而是从“上帝视角”看看:如何提取一个矩阵的“主心骨”。
一、 概念引入:从“百变”中寻找“不变”
想象你手里有一个橡皮泥做的正方形(代表一个向量空间)。矩阵乘法就像是一双手,它把这个正方形揉圆、拉长、压扁、旋转(线性变换)。
在这个过程中,大部分原本指向某个方向的箭头(向量),在变形后都改变了方向。但是,有极少数特殊的箭头,它们在变形前后,方向竟然保持不变! 它们仅仅是被拉长或缩短了而已。
- 这些“方向不变”的向量,就是特征向量(Eigenvector)。
- 它们被拉伸或缩短的倍数,就是特征值(Eigenvalue)。
数学定义
如果一个非零向量 vvv 和一个方阵 AAA 满足以下关系:
Av=λv Av = \lambda v Av=λv
- AAA:变换矩阵(The Action)
- vvv:特征向量(The Direction)
- λ\lambdaλ:特征值(The Scalar/Scaling factor)
直觉理解:
特征向量告诉了我们矩阵变换的主要轴向(比如数据分布的主方向),而特征值告诉了我们在这个轴向上数据的能量大小(拉伸了多少)。
二、 核心应用场景:为什么 AI 离不开它?
在机器学习中,我们面对的往往是成千上万维的数据(比如一张 1024x1024 的图片)。处理这么多数据太慢且容易过拟合。我们需要找到数据中最重要的信息,扔掉噪音。
特征值分解就是那个“提纯”的筛子:
- PCA 降维:把数据投影到特征值最大的几个特征向量方向上,保留主要信息(特征值大),丢弃次要信息(特征值小)。
- PageRank:Google 搜索的核心,通过计算网页链接矩阵的特征向量,判断哪个网页最重要。
- 大模型微调:利用矩阵的低秩特性(源于特征值分布),极大幅度减少参数量。
三、 代码实战:手写一个 PCA(主成分分析)
虽然力扣上没有直接求特征值的题,但在工程面试中,“手写 PCA 算法” 是一道经典的考察编程与数学结合能力的题目。PCA 的本质就是求协方差矩阵的特征值分解。
我们将使用 NumPy 来复现这个过程,看看如何把二维数据降到一维,却依然保留数据的“精髓”。
1. 问题描述
假设有一组 2D 数据,分布在一个扁长的椭圆区域内。我们需要找到这个椭圆的长轴方向(第一主成分),把数据投影上去。
2. Python 代码实现
import numpy as np
import matplotlib.pyplot as plt
def pca_from_scratch(data, k):
"""
使用特征值分解实现 PCA (Principal Component Analysis)
参数:
data: shape (m, n) 的数据矩阵,m为样本数,n为特征数
k: 降维后的目标维度
返回:
transformed_data: 降维后的数据
eigenvectors: 前k个主成分方向
"""
# 1. 归一化/去中心化:将数据的中心移到原点
# 这是关键一步,否则方差计算会出错
data_mean = np.mean(data, axis=0)
data_centered = data - data_mean
# 2. 计算协方差矩阵 (Covariance Matrix)
# 协方差矩阵描述了数据的形状(相关性)
# rowvar=False 表示每一列是一个特征
cov_matrix = np.cov(data_centered, rowvar=False)
# 3. 特征值分解
# np.linalg.eigh 专用于对称矩阵(协方差矩阵是对称的),数值更稳定
eigenvalues, eigenvectors = np.linalg.eigh(cov_matrix)
# 4. 排序
# eigh 返回的结果是升序的,我们需要降序排列(找最大的特征值)
sorted_indices = np.argsort(eigenvalues)[::-1]
top_k_indices = sorted_indices[:k]
top_eigenvalues = eigenvalues[top_k_indices]
top_eigenvectors = eigenvectors[:, top_k_indices]
# 5. 投影
# 将去中心化的数据点投影到选定的特征向量上
transformed_data = np.dot(data_centered, top_eigenvectors)
return transformed_data, top_eigenvectors, data_centered, data_mean
# --- 测试与可视化 ---
if __name__ == "__main__":
# 生成一些随机数据(具有明显的线性相关性)
np.random.seed(42)
# 这里的变换矩阵隐含了特征方向
transformation = np.array([[2.5, 1.2], [0.8, 0.5]])
raw_data = np.dot(np.random.randn(100, 2), transformation)
# 执行 PCA,降维到 1 维
reduced_data, components, centered_data, mean = pca_from_scratch(raw_data, k=1)
print(f"提取的主成分方向 (特征向量):\n {components}")
# 可视化
plt.figure(figsize=(8, 8))
plt.scatter(centered_data[:, 0], centered_data[:, 1], alpha=0.5, label='Original Data')
# 绘制主成分轴
# 此时 components 是一列向量,为了画线我们需要延长它
pc1 = components[:, 0]
start_point = mean * 0 # 因为已经去中心化,起点是 (0,0)
end_point = pc1 * 3 # 放大一点便于观察方向
plt.arrow(0, 0, pc1[0]*3, pc1[1]*3, head_width=0.2, color='red', linewidth=2, label='Principal Component (Eigenvector)')
plt.title('PCA: Finding the "Main Axis" via Eigenvalue Decomposition')
plt.grid(True)
plt.legend()
plt.axis('equal')
plt.show()
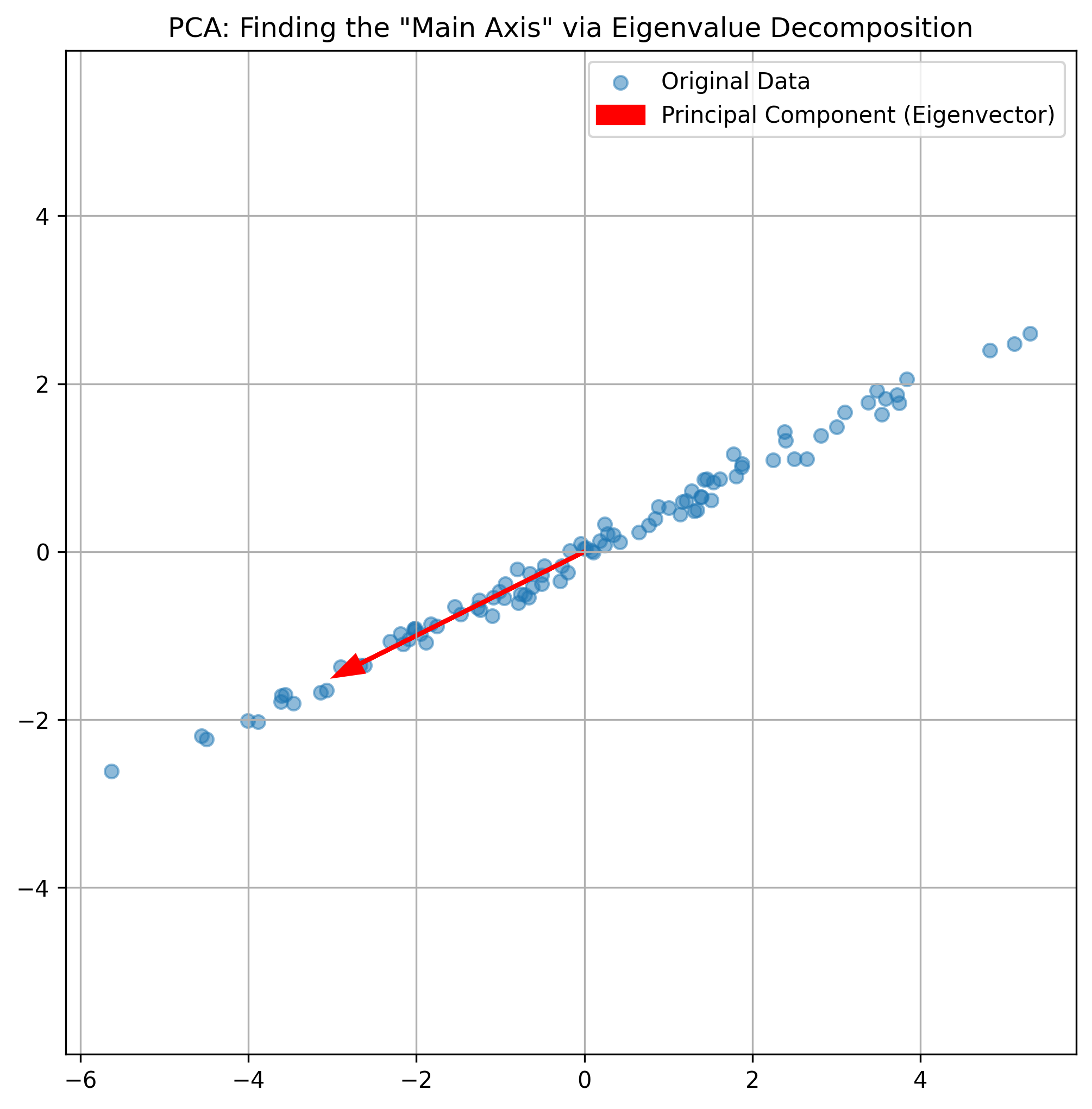
3. 算法解析
- 协方差矩阵:它是一个 n×nn \times nn×n 的方阵,捕捉了特征之间的线性关系。
- 特征值分解:
np.linalg.eigh帮我们找到了协方差矩阵的本征方向。可视化图中红色的箭头就是特征向量指向的方向。 - 物理意义:你可以看到,红色的箭头完美地穿过了数据分布最“长”的方向。这就是数据蕴含信息量最大的方向。
四、 进阶连接:从特征值到大模型微调(LoRA)
作为大模型时代的学习者,你可能会问:“这玩意儿除了降维,和 GPT 有什么关系?”
关系巨大。
在第二阶段的学习中,我们将接触到 LoRA (Low-Rank Adaptation)。它的核心思想直接源于矩阵分解的特性。
1. 大模型的痛点
微调一个 70B 参数的模型,权重矩阵 WWW 可能高达几万乘几万的维度。全量微调(更新所有参数)需要消耗巨大的显存,普通人根本玩不起。
2. 假设与洞察
研究人员发现,虽然大模型的参数矩阵巨大,但它们在特定任务中实际起作用的参数主要集中在极少数的几个方向上。
用数学语言说:权重更新矩阵 ΔW\Delta WΔW 是“低秩”(Low-Rank)的。
所谓“低秩”,通俗解释就是:虽然矩阵很大,但它的非零特征值很少。
3. LoRA 的魔法
基于这个原理,LoRA 不直接训练巨大的 ΔW\Delta WΔW,而是把它分解为两个小矩阵 AAA 和 BBB 的乘积:
ΔW=B×A \Delta W = B \times A ΔW=B×A
- ΔW\Delta WΔW 维度:d×dd \times dd×d (超级大,比如 4096 x 4096)
- AAA 维度:r×dr \times dr×d (rrr 很小,比如 8 或 16)
- BBB 维度:d×rd \times rd×r
通过这种分解,原本需要训练 d×dd \times dd×d 个参数,现在只需要训练 2×d×r2 \times d \times r2×d×r 个参数。如果 d=4096,r=8d=4096, r=8d=4096,r=8,参数量直接压缩了数百倍!
你看,特征值分解所揭示的“矩阵主要能量集中在少数方向”这一原理,正是 LoRA 能够让我们在单张消费级显卡上微调大模型的理论基石。
五、 结语:抓住数据的“主旋律”
如果把矩阵看作一首复杂的交响乐,充满了各种噪音和和声,那么特征值分解就是那个能让你瞬间听出“主旋律”的工具。
- 在数学课本里,它是 Av=λvAv = \lambda vAv=λv。
- 在数据分析中,它是 PCA 降维。
- 在 AI 前沿,它是 LoRA 微调的灵魂。
学习数学基础往往是枯燥的,但当你意识到,你正在推导的这个公式,正是 ChatGPT 能够“变聪明”且“轻量化”的秘密时,这种枯燥是否变成了一种掌控底层规律的兴奋?
下一阶段预告:
掌握了矩阵的运算与分解后,我们将进入概率统计的世界。下一篇,我们将探讨贝叶斯公式与极大似然估计(MLE)——看看 AI 是如何像侦探一样,在不确定的世界中通过“蛛丝马迹”推断出“事实真相”的。
参考资料
- NumPy 官方文档:
numpy.linalg.eig - LoRA 原论文:LoRA: Low-Rank Adaptation of Large Language Models
- 3Blue1Brown 线性代数的本质:https://space.bilibili.com/88461692

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)