Google Cloud Vertex 与 Compue Engine 的交互实验。(Compute Engine 上创建一个Gemini LLM)
本文聚焦于探索 Google Cloud Vertex AI 与其它云服务 API 的集成与依赖关系。通过深入研究,我们发现了利用 Vertex AI Workbench 创建虚拟机实例的灵活应用模式,并在此之上实践了两种基于大型语言模型(LLM)的核心场景:任务式调用、服务化部署。
最近一直在研究 Google Cloud Asset Agentless Scanning(谷歌云资源无代理扫描)技术,为了构建 Vertex AI 与其依赖 API 的关系,我对 Vertex AI 进行了深入探索,重点关注哪些 API 可能与其形成相互依赖,以及如何建立这种联系及其潜在价值。在这个过程中,我发现可以利用 Vertex AI 中的 Workbench 功能创建一台虚拟机(VM),进而实现两种不同的应用路径:
- 一是直接在 VM 上调用大型语言模型(LLM)处理各类任务;
- 二是在该 VM 上部署一个自托管的 LLM 服务。
本文将从这两个方向出发,分别分享具体实现步骤与相关经验。
场景一: VM上利用LLM处理各类任务
在 Google Cloud Console 中,选择 Vertex AI,然后在左侧导航栏点击 Notebooks 下的 Workbench。进入页面后,点击蓝色的 Create new 按钮,输入你的 VM 名称,然后点击 Create。如下图:
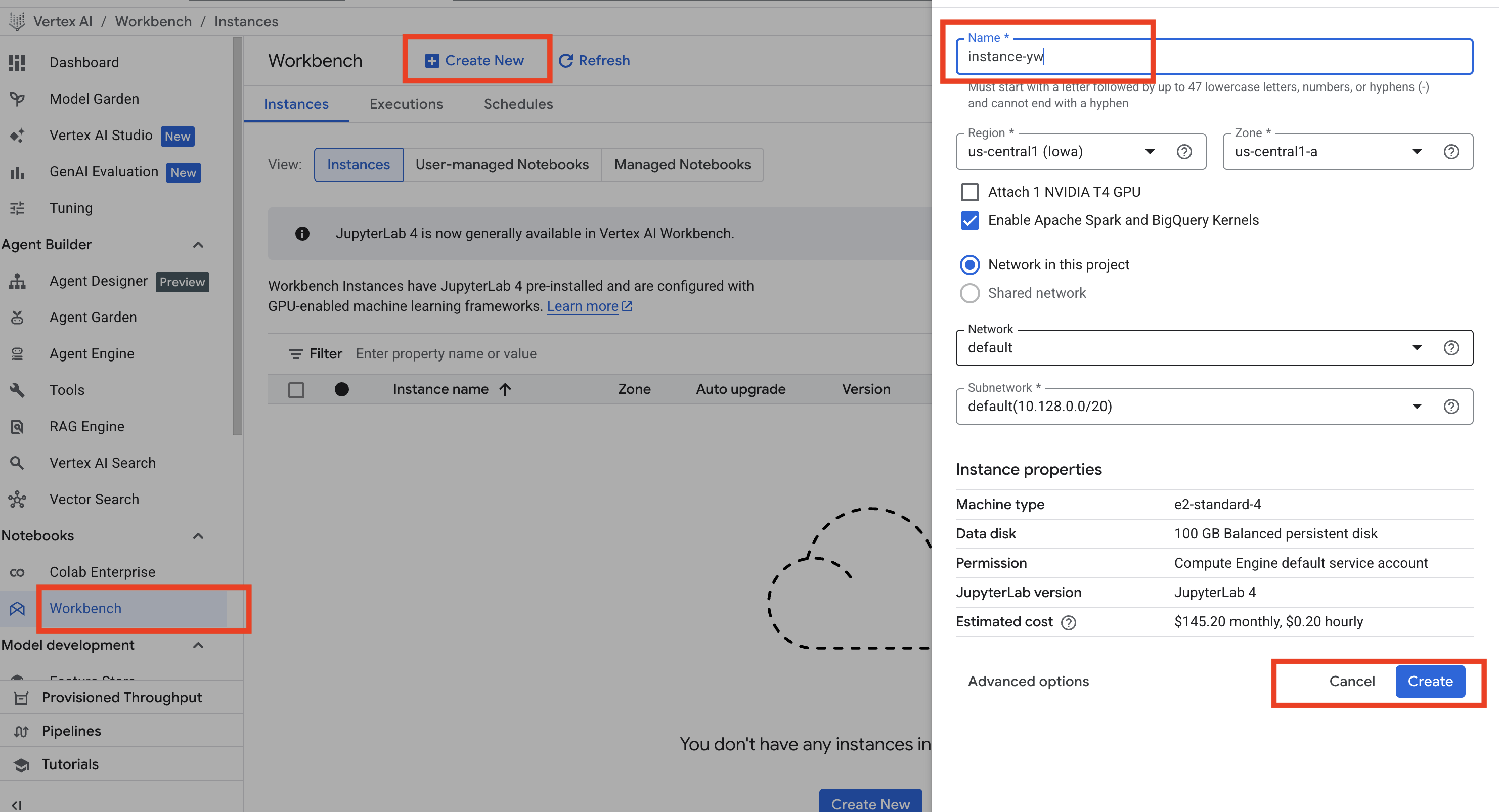
(PS: 新手注册时有一个 Quota 为 250 的 size 限制,如果你在该区域下创建过 VM,可能会在创建时报错,提示超过 Quota。可以尝试删除之前的 VM,或更换其他区域。我最初在默认的 us-central1 区域创建失败,正是因为这个问题,后来换成 us-west1 才成功。)
创建完 VM 后,稍等片刻,Workbench 页面会显示你刚创建的 VM,并且在 VM 名称旁边会出现蓝色的 Open JupyterLab 字样。点击进入 Open JupyterLab。如下图:
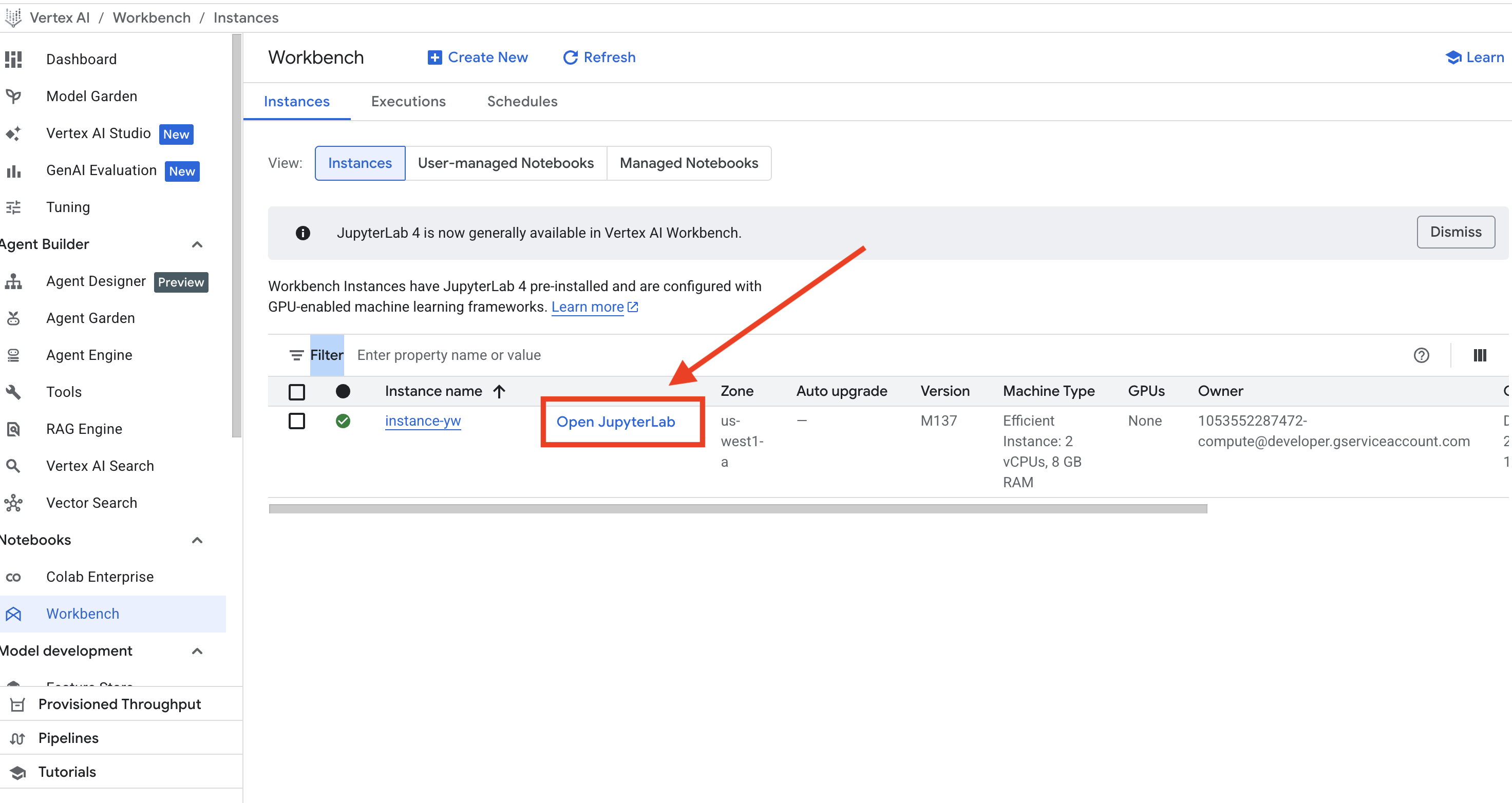
进入 JupyterLab 页面后,创建一个 Python3 的文件,粘贴以下代码:
import os
# 注意:新版 SDK 推荐使用 google.genai
from google import genai
from google.cloud import storage
# --- 配置区 ---
PROJECT_ID = "your project id"
LOCATION = "us-central1"
BUCKET_NAME = f"{PROJECT_ID}-ai-output-demo"
# 步骤 2 & 3: 初始化并实例化客户端 (新版合并了这一步)
# vertex_ai=True 表示使用 Vertex AI 平台而非 AI Studio
client = genai.Client(vertexai=True, project=PROJECT_ID, location=LOCATION)
MODEL_ID = "gemini-2.0-flash" # 或者使用你需要的模型版本
# 步骤 4: 定义任务
styles = ["幽默风", "像个老学究", "充满激情的销售"]
results = ""
print("--- 开始生成内容 ---")
for style in styles:
print(f"正在生成: {style}...")
prompt = f"请用{style}写一段 50 字以内的自我介绍。"
# 新版的调用方式是 client.models.generate_content
response = client.models.generate_content(
model=MODEL_ID,
contents=prompt
)
# 获取文字的方式更直接
results += f"【{style}】\n{response.text}\n\n"
# 步骤 5: 存入 Storage (这部分代码保持不变,因为 storage 库没变)
storage_client = storage.Client()
try:
bucket = storage_client.get_bucket(BUCKET_NAME)
except:
bucket = storage_client.create_bucket(BUCKET_NAME, location=LOCATION)
blob = bucket.blob("my_ai_results.txt")
blob.upload_from_string(results, content_type='text/plain; charset=utf-8')
print(f"成功!结果已保存到: gs://{BUCKET_NAME}/my_ai_results.txt")(PS: 注意,在配置区 PROJECT_ID = "your project id" 中,请务必将 your project id 替换为你自己的 Project ID。)
填写完成后,运行这段代码,会出现以下提示:
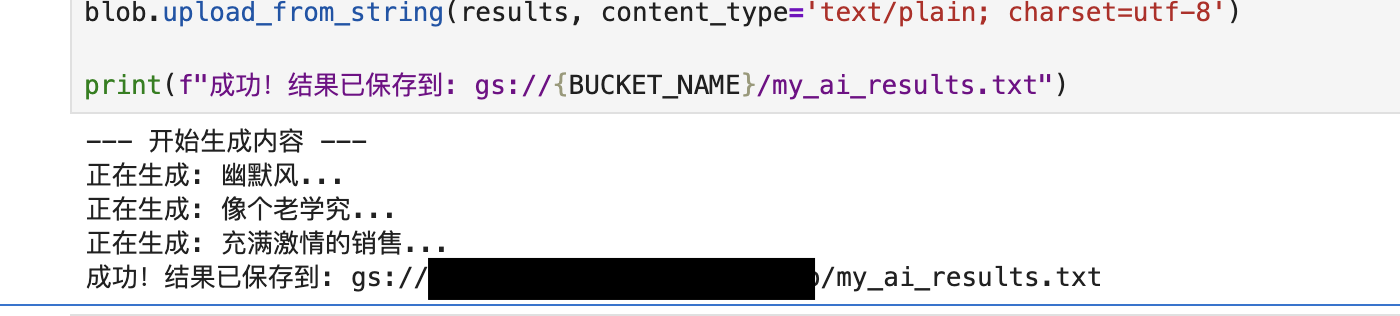
至此,你就相当于在你创建的 VM 上运行了一个基于 Gemini-2.0-Flash 的 LLM 作业,并将生成的结果保存到了名为 {PROJECT_ID}-ai-output-demo 的 Bucket(Google Cloud Storage 服务)下的 my_ai_results.txt 文件中。
此时,你可以前往 Cloud Storage → Bucket,找到该 Bucket,进入后可以看到结果文件。点击该文件,选择 Authenticated URL 对应的链接,即可查看文件内容。如下:

场景二:VM 上部署一个自托管的 Gemini LLM 服务
在场景一创建的 VM 中,同样进入 Open JupyterLab 页面后,选择 Terminal。输入以下命令,创建一个 app.py 文件,内容如下:
cat <<EOF > app.py
import streamlit as st
from google import genai
# 配置
PROJECT_ID = "your project id"
LOCATION = "us-central1"
MODEL_ID = "gemini-2.0-flash-001"
# 初始化客户端
client = genai.Client(vertexai=True, project=PROJECT_ID, location=LOCATION)
st.title("我的 AI 助理 (Streamlit 版)")
user_input = st.text_input("请输入你的问题:", "你好")
if st.button("发送给 Gemini"):
if user_input:
with st.spinner('Gemini 正在思考...'):
try:
response = client.models.generate_content(
model=MODEL_ID,
contents=user_input
)
st.success("回答完成:")
st.write(response.text)
except Exception as e:
st.error(f"报错信息: {e}")
EOF(PS: 注意,在配置区 PROJECT_ID = "your project id" 中,请务必将 your project id 替换为你自己的 Project ID。)
接下来继续在 Terminal 中安装相关依赖库,命令如下:
pip install streamlit google-genai然后,启动Streamlit,运行app.py,如下:
streamlit run app.py --server.port 8501启动成功后,Terminal 中会显示运行状态及服务访问地址,如下所示:
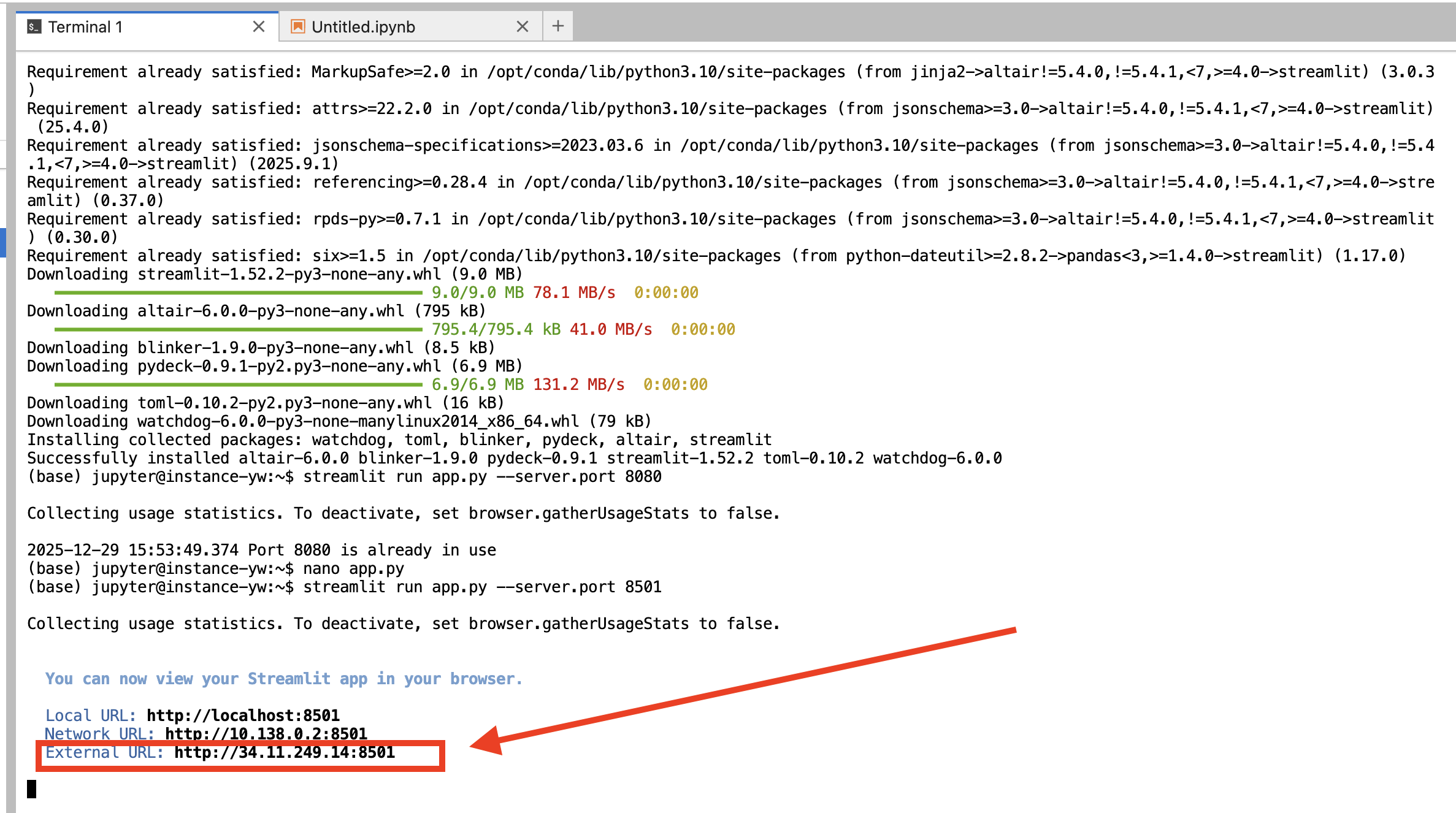
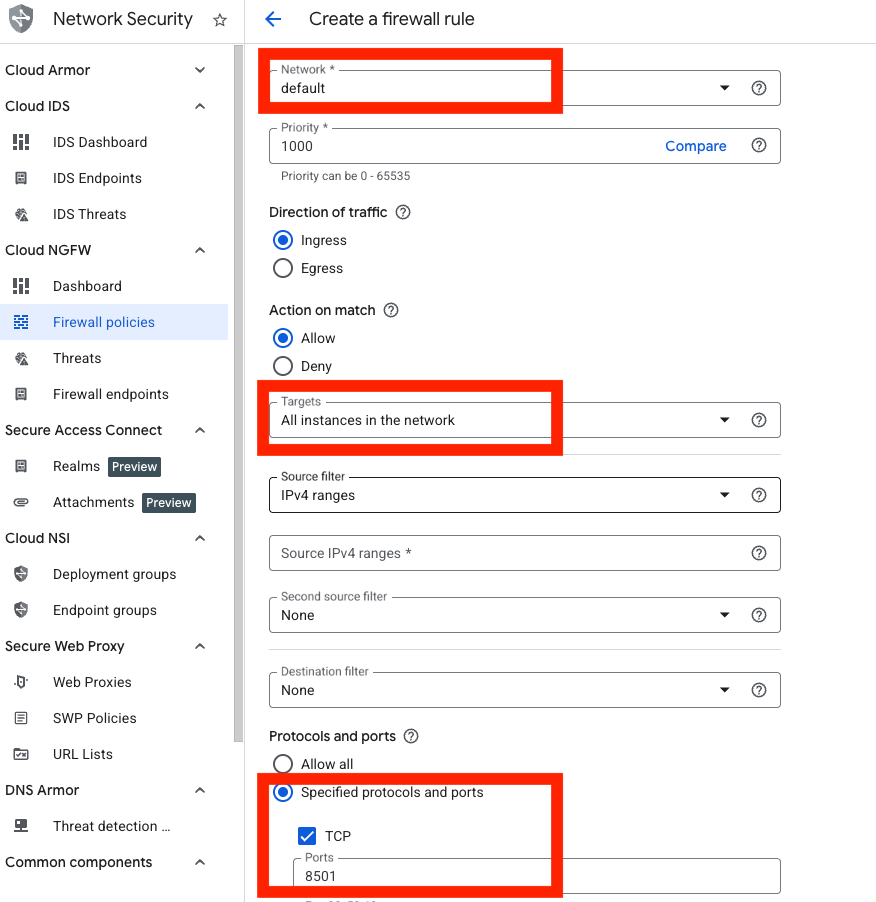
最后,需要在 VM 所在的防火墙中开放对应端口(8501):
- 进入 Google Console 导航栏 → VPC Network → Firewall
- 点击 Create firewall rule
- 在规则配置页面,选择你 VM 对应的 Network
- Targets 选择 All instances in the network
- Protocols and ports 选择 Specified protocols and ports
- 选择 TCP 协议,输入端口 8501 (这个端口号要和运行app.py时的端口号一致)
- 点击创建即可,如下图:
至此,一个基于 Gemini-2.0-Flash 的自托管 LLM 服务即部署完成。任何人都可以通过对应 IP 地址和端口访问该服务,访问效果如下:
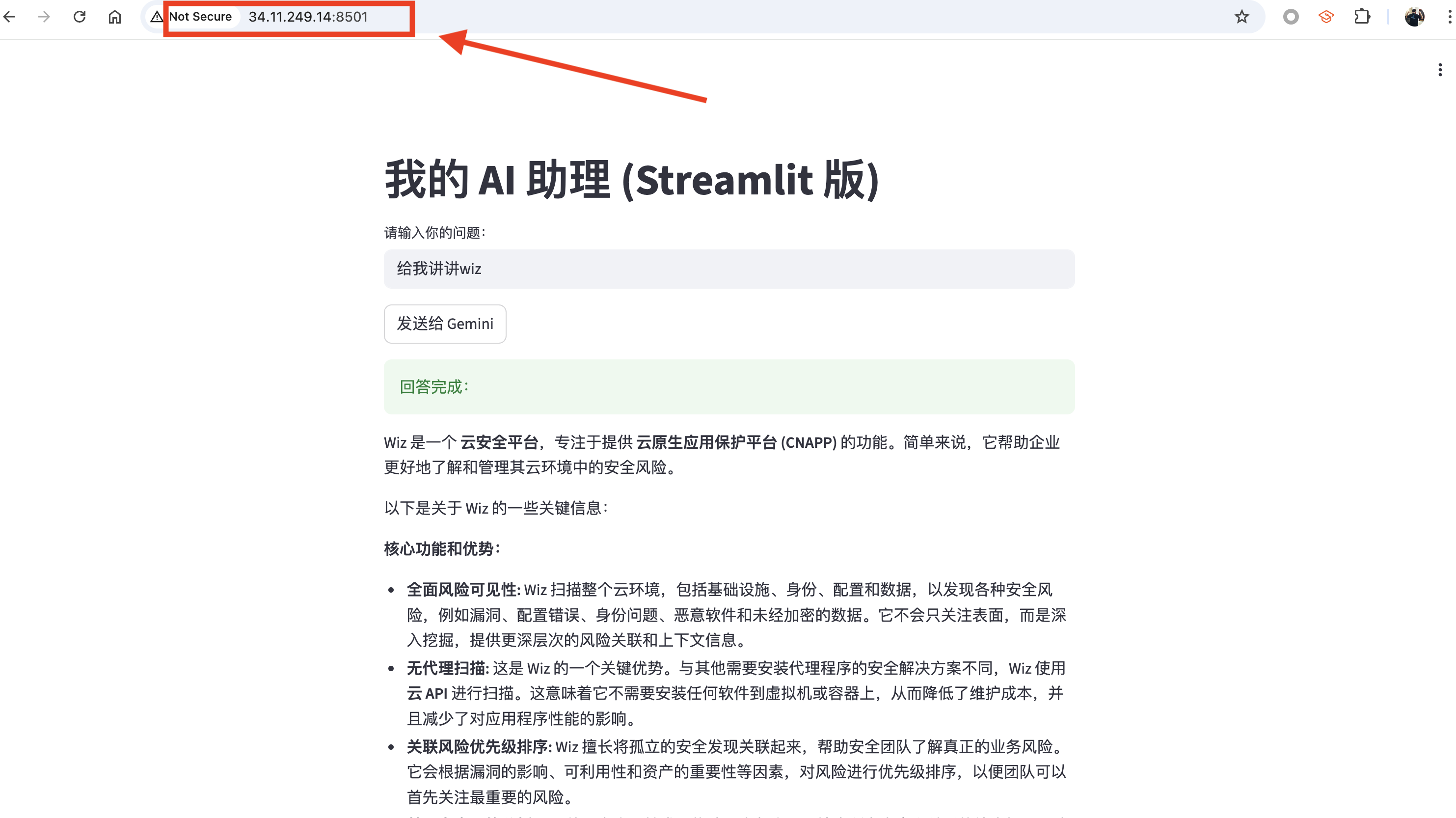
重要提醒:
你所部署的 LLM 服务可以通过该地址被任何人访问(无需梯子),所产生的费用将全部由你的 Project ID 承担。请务必注意避免地址泄露,否则可能产生大量资源消耗。在不使用时,建议关闭服务或直接删除该 VM。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 24
24 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)