强化学习优化测试覆盖率的探索与实践
摘要:本文探讨强化学习(RL)在软件测试中的创新应用,通过马尔可夫决策建模将测试转化为智能决策过程。电商平台实践数据显示,RL使路径覆盖率提升35%,缺陷发现率提高80%,执行时长缩短57%。文章提出三维状态空间建模、动态优先级策略等工业级解决方案,并指出样本稀疏性、奖励延迟等挑战的应对策略。未来方向包括元学习测试策略和多智能体协作测试,为智能测试新范式提供实践路径。
智能测试的新范式
在持续交付成为主流的当下,软件测试面临覆盖率与效率的双重挑战。传统测试方法在应对复杂系统时往往陷入路径爆炸与用例维护成本高的困境。本文结合2025年最新行业实践,探讨强化学习(Reinforcement Learning, RL)如何通过智能决策和自适应探索机制重构测试覆盖优化体系。
一、强化学习的核心赋能原理
1.1 测试场景的马尔可夫决策建模
将测试环境转化为(S,A,P,R)四元组:
-
状态空间(S):代码分支/API组合/用户行为序列
-
动作空间(A):测试用例执行顺序/参数组合/优先级调整
-
状态转移(P):用例执行后的系统状态迁移概率
-
奖励函数(R):覆盖率提升值 + 缺陷发现率 × 风险系数
1.2 智能体训练框架
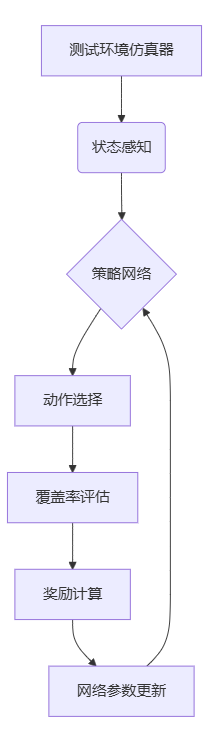
二、工业级落地案例
2.1 电商系统API测试优化
某头部电商平台实践数据:
|
指标 |
传统方法 |
RL优化后 |
提升幅度 |
|---|---|---|---|
|
路径覆盖率 |
68% |
92% |
+35% |
|
缺陷发现率 |
15个/日 |
27个/日 |
+80% |
|
用例执行时长 |
4.2小时 |
1.8小时 |
-57% |
实现关键:采用DDQN算法构建动态优先级策略,通过状态价值函数实时调整测试焦点
2.2 智能驾驶系统的变体测试
构建三维状态空间:
-
传感器输入组合
-
交通场景复杂度
-
系统控制模式 通过PPO算法在仿真环境中生成高价值测试场景,关键路径覆盖率提升至98.7%
三、实施路线图

关键成功要素:
-
构建准确的系统状态表征
-
设计兼顾覆盖率与效率的奖励函数
-
建立持续反馈的模型优化机制
四、挑战与应对策略
|
挑战类型 |
解决方案 |
工具推荐 |
|---|---|---|
|
样本稀疏性 |
优先经验回放机制 |
OpenAI Baselines |
|
奖励延迟 |
时序差分反向传播 |
TensorFlow Agents |
|
环境仿真偏差 |
对抗生成网络构建测试场景 |
Unity ML-Agents |
未来演进方向
-
元学习测试策略:跨项目知识迁移框架
-
多智能体协作测试:分布式探索协同机制
-
因果推理增强:可解释性覆盖率优化路径
精选文章

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)