【AI量化投研】- Modeling(五, 软化F1 + 加权交叉熵 修正为 F1 + 交叉熵 + 提升精度权重)
本文探讨了AI量化投资建模中损失函数的优化问题。针对前期单纯使用软化F1损失函数导致模型仅学习噪声的问题,作者提出了一种融合损失函数方案:将软化F1损失与加权交叉熵损失相结合,并引入类别权重处理数据不平衡。实验发现正负样本权重设置对模型性能影响显著,1:1.2的权重比例效果优于极端悬殊的设置。通过调整样本量和权重比例,模型在6000样本规模下展现出较好的收敛趋势,为后续扩展到更大规模数据集奠定了基
@[TOC](【AI量化投研】- Modeling(五, 软化F1 + 加权交叉熵 修正为 F1 + 交叉熵 + 提升精度权重))
背景
上一篇 【AI量化投研】- Modeling(四, 意外之喜) 中,我们针对遇到的训练不稳定 寻优方向不匹配等问题,做了一个理论探索和实证研究. 当时否定了之前的 加入盈亏比元素 的损失函数, 因为盈亏比在策略中通过止损调整即可, 在模型训练上是不需要作出体现. 模型训练只需做好盈亏类别判断,把胜率提升上来, 策略加上止损就能成为一个 胜率高 盈亏比也高的 高期望值策略. 已达成最终追求.
当时认为,应转向以F1为优化方向才是正确的, 并因此有了 近似F1的损失函数:
def soft_f1_loss(self, y_pred, y_true):
"""
计算软化F1损失(基于Dice Loss思想)
使用概率值而非硬标签,使得损失函数可微
"""
# 将真实标签转换为one-hot编码
y_true_oh = nnF.one_hot(y_true, num_classes=y_pred.size(1)).float()
# 对预测值应用softmax
y_pred_softmax = nnF.softmax(y_pred, dim=1)
# 计算真正例、假正例、假负例的软化版本
tp = (y_true_oh * y_pred_softmax).sum(dim=0)
fp = ((1 - y_true_oh) * y_pred_softmax).sum(dim=0)
fn = (y_true_oh * (1 - y_pred_softmax)).sum(dim=0)
# 计算软化精确率和召回率
precision = tp / (tp + fp + self.epsilon)
recall = tp / (tp + fn + self.epsilon)
# 计算软化F1分数
soft_f1 = 2 * (precision * recall) / (precision + recall + self.epsilon)
# 返回平均F1损失(最小化1-F1)
return 1 - soft_f1.mean()
以此方法为基础的 test016_train 惨遭失败, 训练中验证损失 测试损失都不随训练损失降低,模型仅学到噪声.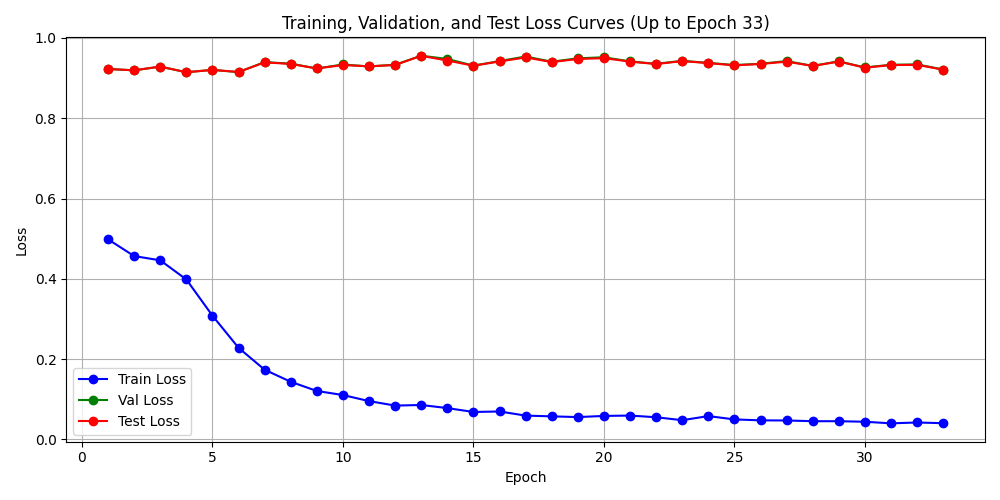
看起来是因为我丢了2个的东西: 正负类权重 交叉熵.
尝试融合损失
接下来, 要基于近似F1, 把这两者加回来. 然后有了下面的融合损失:
def calculate_class_weights(labels):
"""计算类别权重,处理不平衡数据"""
class_counts = torch.bincount(labels)
total_samples = len(labels)
class_weights = total_samples / (len(class_counts) * class_counts.float())
return class_weights
class ImprovedLossFunctions:
"""改进的损失函数集合"""
@staticmethod
def create_adaptive_loss(dataset, loss_type='composite'):
if isinstance(dataset, Subset):
labels = [dataset.dataset.binary_labels[i] for i in dataset.indices]
else:
labels = dataset.binary_labels
pos_count = sum(1 for label in labels if label == 1)
neg_count = sum(1 for label in labels if label == 0)
total = len(labels)
print(f"📊 类别分布统计:")
print(f" 正样本: {pos_count} ({pos_count / total * 100:.1f}%)")
print(f" 负样本: {neg_count} ({neg_count / total * 100:.1f}%)")
labels_tensor = torch.tensor(labels)
class_weights = calculate_class_weights(labels_tensor).to(device)
if loss_type == 'composite':
print(" 使用 CompositeF1CrossEntropyLoss")
return CompositeF1CrossEntropyLoss(alpha=0.5, beta=0.5, class_weights=class_weights)
else:
print(" 使用标准交叉熵损失")
return nn.CrossEntropyLoss()
# ==================== 改进的损失函数 ====================
class CompositeF1CrossEntropyLoss(nn.Module):
"""
结合软化F1损失与加权交叉熵的复合损失函数
目标:同时优化分类准确性和F1分数,特别适用于不平衡数据
"""
def __init__(self, alpha=0.5, beta=0.5, class_weights=None, epsilon=1e-7):
"""
Args:
alpha: 软化F1损失的权重
beta: 加权交叉熵损失的权重 (alpha + beta 通常为1)
class_weights: 各类别的权重张量,用于处理类别不平衡
epsilon: 平滑项,防止除零
"""
super().__init__()
self.alpha = alpha
self.beta = beta
self.epsilon = epsilon
self.class_weights = class_weights
# 初始化加权交叉熵损失
if class_weights is not None:
self.cross_entropy = nn.CrossEntropyLoss(
weight=class_weights, reduction='mean'
)
else:
self.cross_entropy = nn.CrossEntropyLoss(reduction='mean')
def soft_f1_loss(self, y_pred, y_true):
"""
计算软化F1损失(基于Dice Loss思想)
使用概率值而非硬标签,使得损失函数可微
"""
# 将真实标签转换为one-hot编码
y_true_oh = nnF.one_hot(y_true, num_classes=y_pred.size(1)).float()
# 对预测值应用softmax
y_pred_softmax = nnF.softmax(y_pred, dim=1)
# 计算真正例、假正例、假负例的软化版本
tp = (y_true_oh * y_pred_softmax).sum(dim=0)
fp = ((1 - y_true_oh) * y_pred_softmax).sum(dim=0)
fn = (y_true_oh * (1 - y_pred_softmax)).sum(dim=0)
# 计算软化精确率和召回率
precision = tp / (tp + fp + self.epsilon)
recall = tp / (tp + fn + self.epsilon)
# 计算软化F1分数
soft_f1 = 2 * (precision * recall) / (precision + recall + self.epsilon)
# 返回平均F1损失(最小化1-F1)
return 1 - soft_f1.mean()
def forward(self, y_pred, y_true):
# 计算软化F1损失
f1_loss = self.soft_f1_loss(y_pred, y_true)
# 计算加权交叉熵损失
ce_loss = self.cross_entropy(y_pred, y_true)
# 组合损失
composite_loss = self.alpha * f1_loss + self.beta * ce_loss
return composite_loss, f1_loss, ce_loss
融合损失小样本跑起来: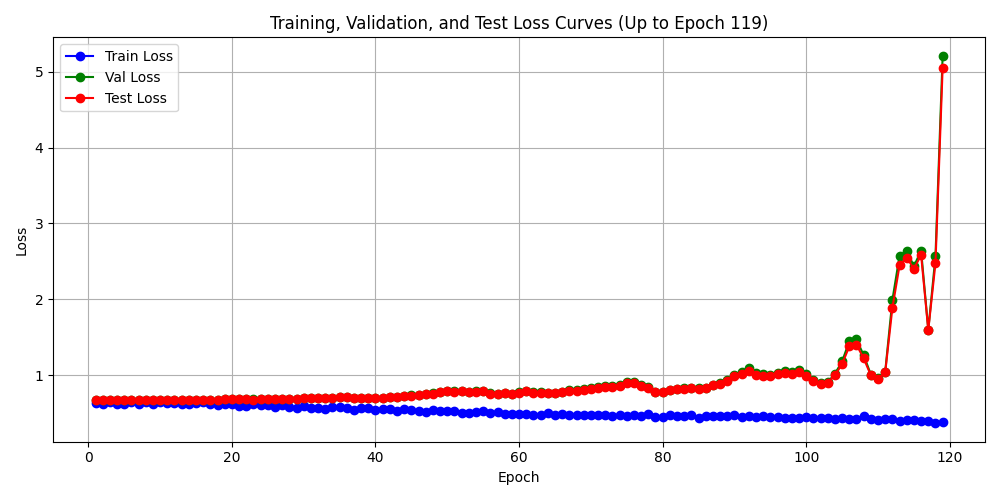
经验上看, 应该还是权重设置的问题,查询下正负类权重设置:
负: 0.5538
正: 5.1429
太过于悬殊.之前就遇到这个情况, 最后设置为1:1.6能有好结果. 这次设置为1:1.382 试试. (我原本的理解,1:1.382 和 1:1 是不是没什么差别?)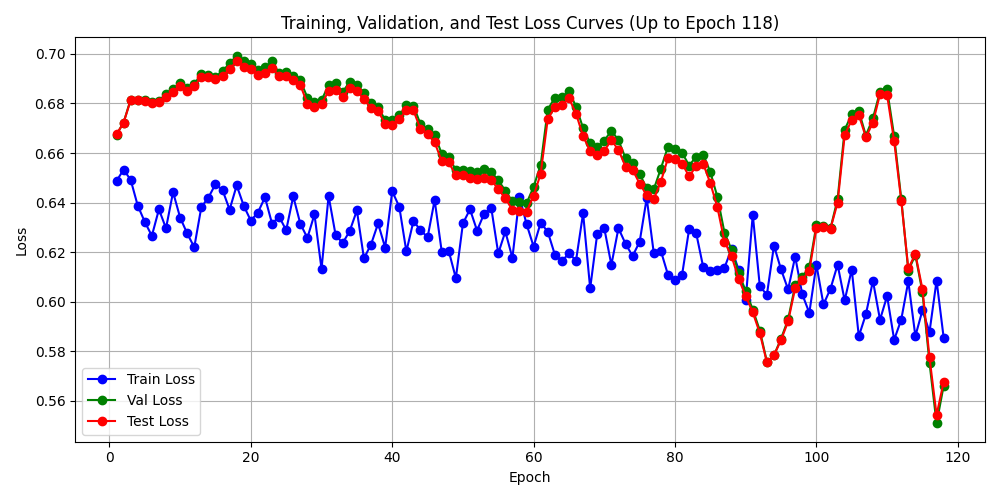
果然如我所料, 正负样本比设置为1:1.2, 增大样本至6000, 训练来观察观察. 收敛情况如果还可以 可扩大到75000+样本.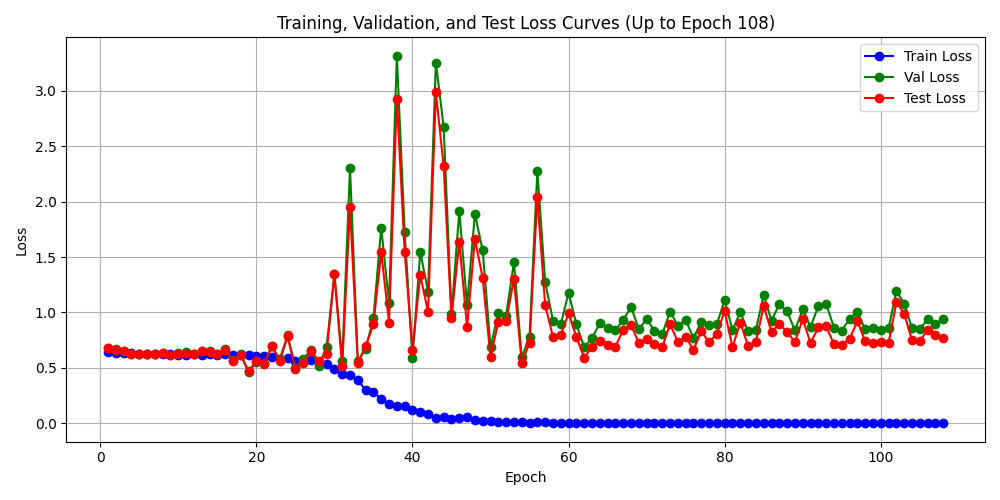
融合后效果 从结果来看, 训练损失能达到 0.000250, 精确率 召回率能达到100%, 训练是可以有效的, 模型结构有用,能训练,能学习,而且可以学得很好,潜力没问题. 再看训练的损失函数的变化过程,很标准.
📊 Epoch 108 结果:
训练损失: 0.000250 | 验证损失: 0.938170 | 测试损失: 0.765741
训练准确率: 100.00% | 验证准确率: 80.03% | 测试准确率: 84.13%
训练精确率: 1.0000 | 验证精确率: 0.1271 | 测试精确率: 0.2087
训练召回率: 1.0000 | 验证召回率: 0.2308 | 测试召回率: 0.3158
训练F1分数: 1.0000 | 验证F1分数: 0.1639 | 测试F1分数: 0.2513
训练期望值: 2.4024 | 验证期望值: 0.1311 | 测试期望值: 0.4064
训练混淆矩阵:
[[600 0]
[ 0 360]]
验证混淆矩阵:
[[598 103]
[ 50 15]]
测试混淆矩阵:
[[734 91]
[ 52 24]]
📈 验证集指标绝对提升值(相对于原始样本比例基线):
准确率提升: -0.1277
精确率提升: 0.1271
召回率提升: 0.2308
F1分数提升: 0.1639
💾 Epoch 108 模型已保存至: model_epoch_108_20251229_121722.pth
验证损失和测试损失确实不尽如人意,但没有太漂,还是压住了,收敛在1以下. 所以训练结果是能有一定的参考意义的. 非随机.
训练精确率: 1.0000 | 验证精确率: 0.1271 | 测试精确率: 0.2087
训练召回率: 1.0000 | 验证召回率: 0.2308 | 测试召回率: 0.3158
训练F1分数: 1.0000 | 验证F1分数: 0.1639 | 测试F1分数: 0.2513
训练期望值: 2.4024 | 验证期望值: 0.1311 | 测试期望值: 0.4064
测试精确率20%,高于随机的8.5%; 虽离实战有距离,但提升也显著.召回率31%,对应的数量也是庞大的,具备统计意义.
小结
训练Okay(精确率 召回率达100%), 测试 验证 不Okay, 说明很可能收敛到样本局部最优点,这个局部点远离验证和测试的点,导致样本外差. 学习能力okay,则参数没问题, 需要做的只是扩大样本量即可. 将 test017_train 扩样本到75000+执行训练.
F1为目标引起的无意义高召
另外,我发现当前这个损失的一个问题: 以F1为目标,很容易引起寻优往高召回率的方向走,高召回很容易实现但只有在高精准率前提下才有意义, 而且难的也是精准率. 所以,我要做修改: 以精准度为第一目标, F1为第二目标, 精准度比F1的重要性比初始设置为3:1(应是前置条件,现简化设置,通过权重调节).相当于在当前基础上 加入精准度方向,并赋予更高的权重.做如下损失设计:
(1) 优先精准率(Precision):引入软化Precision损失,权重设置为3:1与F1损失,引导模型更注重减少假阳性。
(2) 兼容性强:保留原交叉熵(CE)融合框架,确保训练稳定;软化版本保持可微分。
设置 正 负类样本权重;设置以 F1 为损失主体寻优方向, 但精准率赋予更高权重;设置 交叉熵 仍然占有重要位置. 此三者,符合当前探索认知中的最佳损失配置. 源码如下:
# ==================== 改进的损失函数 ====================
class CompositeF1CrossEntropyLoss(nn.Module):
"""
结合软化F1损失与加权交叉熵的复合损失函数
目标:同时优化分类准确性和F1分数,特别适用于不平衡数据
"""
def __init__(self, alpha=0.5, beta=0.5, class_weights=None, epsilon=1e-7):
"""
Args:
alpha: 软化F1损失的权重
beta: 加权交叉熵损失的权重 (alpha + beta 通常为1)
class_weights: 各类别的权重张量,用于处理类别不平衡
epsilon: 平滑项,防止除零
"""
super().__init__()
self.alpha = alpha
self.beta = beta
self.epsilon = epsilon
self.class_weights = class_weights
# 初始化加权交叉熵损失
if class_weights is not None:
self.cross_entropy = nn.CrossEntropyLoss(
weight=class_weights, reduction='mean'
)
else:
self.cross_entropy = nn.CrossEntropyLoss(reduction='mean')
def soft_f1_loss(self, y_pred, y_true):
"""
计算软化F1损失(基于Dice Loss思想)
使用概率值而非硬标签,使得损失函数可微
"""
# 将真实标签转换为one-hot编码
y_true_oh = nnF.one_hot(y_true, num_classes=y_pred.size(1)).float()
# 对预测值应用softmax
y_pred_softmax = nnF.softmax(y_pred, dim=1)
# 计算真正例、假正例、假负例的软化版本
tp = (y_true_oh * y_pred_softmax).sum(dim=0)
fp = ((1 - y_true_oh) * y_pred_softmax).sum(dim=0)
fn = (y_true_oh * (1 - y_pred_softmax)).sum(dim=0)
# 计算软化精确率和召回率
precision = tp / (tp + fp + self.epsilon)
recall = tp / (tp + fn + self.epsilon)
# 计算软化F1分数
soft_f1 = 2 * (precision * recall) / (precision + recall + self.epsilon)
# 返回平均F1损失(最小化1-F1)
return 1 - soft_f1.mean()
def forward(self, y_pred, y_true):
# 将真实标签转换为one-hot编码
y_true_oh = nnF.one_hot(y_true, num_classes=y_pred.size(1)).float()
# 对预测值应用softmax
y_pred_softmax = nnF.softmax(y_pred, dim=1)
# 计算真正例、假正例的软化版本(用于precision)
tp = (y_true_oh * y_pred_softmax).sum(dim=0)
fp = ((1 - y_true_oh) * y_pred_softmax).sum(dim=0)
# 计算软化精确率损失
precision = tp / (tp + fp + self.epsilon)
precision_loss = 1 - precision.mean()
# 计算软化F1损失
f1_loss = self.soft_f1_loss(y_pred, y_true)
# 加权组合Precision损失和F1损失(3:1)
gamma = 3.0
weighted_metric_loss = (gamma * precision_loss + f1_loss) / (gamma + 1)
# 计算加权交叉熵损失
ce_loss = self.cross_entropy(y_pred, y_true)
# 组合损失
composite_loss = self.alpha * weighted_metric_loss + self.beta * ce_loss
return composite_loss, f1_loss, ce_loss
def get_training_schedule(total_epochs=100):
"""
制定渐进式训练计划
前期:侧重交叉熵,稳定收敛
后期:侧重F1损失,优化目标指标
"""
schedule = {
'phase1': {'epochs': int(0.3 * total_epochs), 'alpha': 0.3, 'beta': 0.7},
'phase2': {'epochs': int(0.5 * total_epochs), 'alpha': 0.5, 'beta': 0.5},
'phase3': {'epochs': int(0.2 * total_epochs), 'alpha': 0.7, 'beta': 0.3}
}
return schedule
def calculate_class_weights(labels):
"""计算类别权重,处理不平衡数据"""
class_counts = torch.bincount(labels)
total_samples = len(labels)
class_weights = total_samples / (len(class_counts) * class_counts.float())
return class_weights
class ImprovedLossFunctions:
"""改进的损失函数集合"""
@staticmethod
def create_adaptive_loss(dataset, loss_type='composite'):
if isinstance(dataset, Subset):
labels = [dataset.dataset.binary_labels[i] for i in dataset.indices]
else:
labels = dataset.binary_labels
pos_count = sum(1 for label in labels if label == 1)
neg_count = sum(1 for label in labels if label == 0)
total = len(labels)
print(f"📊 类别分布统计:")
print(f" 正样本: {pos_count} ({pos_count / total * 100:.1f}%)")
print(f" 负样本: {neg_count} ({neg_count / total * 100:.1f}%)")
# labels_tensor = torch.tensor(labels)
# class_weights = calculate_class_weights(labels_tensor).to(device)
class_weights = torch.tensor([1, 1.382]).to(device)
if loss_type == 'composite':
print(" 使用 CompositeF1CrossEntropyLoss")
return CompositeF1CrossEntropyLoss(alpha=0.5, beta=0.5, class_weights=class_weights)
else:
print(" 使用标准交叉熵损失")
return nn.CrossEntropyLoss()
小样本(400)训练效果: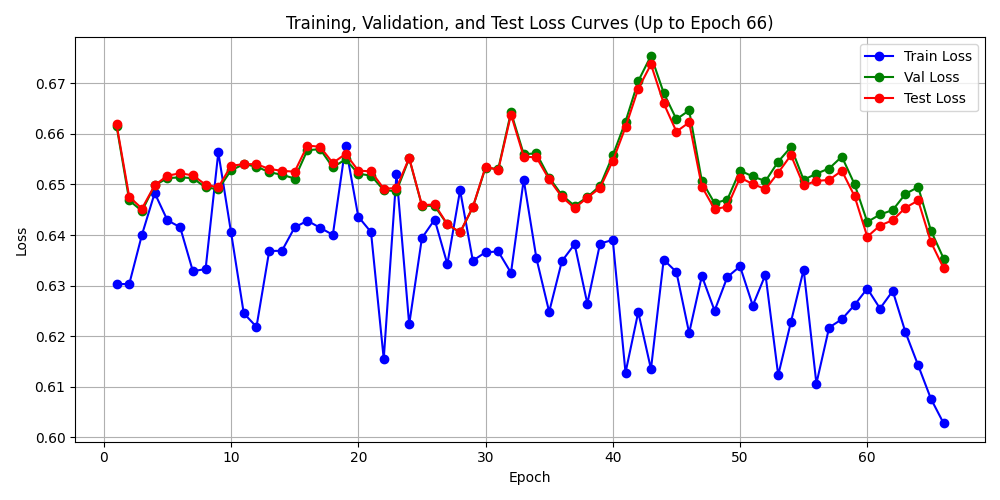
初期震荡, 整体向下, 训练损失下降, 验证和测试损失有跟随趋势. 还算不错的开端, 换大数据量(7000样本)启动训练, 进行训练效果观察,如果效果可行,执行75000+样本. 7000样本训练效果如下: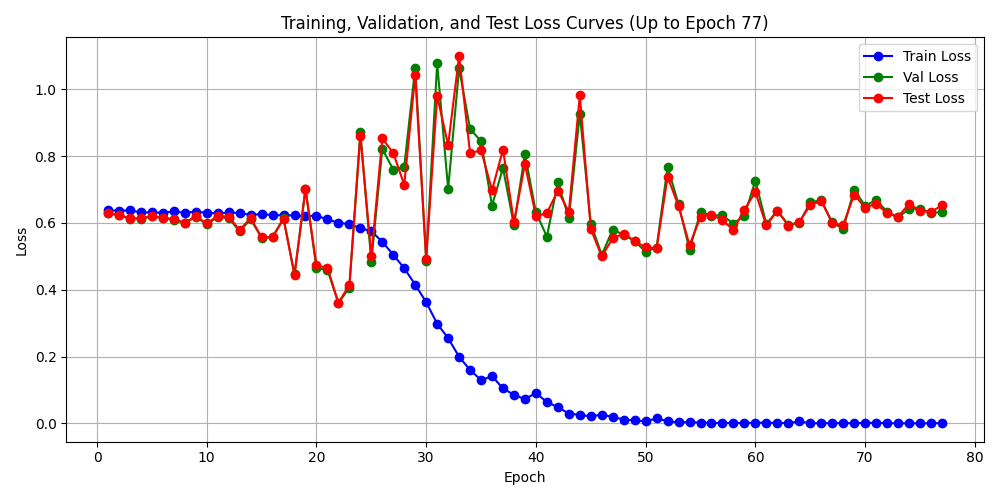
📊 划分训练集、验证集和测试集...
2025-12-29 12:21:37 - - 训练集大小: 5056
2025-12-29 12:21:37 - - 验证集大小: 893
2025-12-29 12:21:37 - - 测试集大小: 1051
2025-12-29 12:21:37 -
🔄 创建数据加载器...
2025-12-29 12:21:37 - - 训练批次/epoch: 72
2025-12-29 12:21:37 - - 验证批次/epoch: 56
2025-12-29 12:21:37 - - 测试批次/epoch: 66
📊 Epoch 077 结果:
2025-12-29 18:04:55 - 训练损失: 0.001473 | 验证损失: 0.632186 | 测试损失: 0.652395
2025-12-29 18:04:55 - 训练准确率: 100.00% | 验证准确率: 86.00% | 测试准确率: 85.82%
2025-12-29 18:04:55 - 训练精确率: 1.0000 | 验证精确率: 0.1923 | 测试精确率: 0.1628
2025-12-29 18:04:55 - 训练召回率: 1.0000 | 验证召回率: 0.1948 | 测试召回率: 0.1538
2025-12-29 18:04:55 - 训练F1分数: 1.0000 | 验证F1分数: 0.1935 | 测试F1分数: 0.1582
2025-12-29 18:04:55 - 训练期望值: 2.3610 | 验证期望值: 0.1499 | 测试期望值: 0.1587
2025-12-29 18:04:55 - 训练混淆矩阵:
[[720 0]
[ 0 432]]
2025-12-29 18:04:55 - 验证混淆矩阵:
[[753 63]
[ 62 15]]
2025-12-29 18:04:55 - 测试混淆矩阵:
[[888 72]
[ 77 14]]
2025-12-29 18:04:55 -
📈 验证集指标绝对提升值(相对于原始样本比例基线):
2025-12-29 18:04:55 - 准确率提升: -0.0680
2025-12-29 18:04:55 - 精确率提升: 0.1923
2025-12-29 18:04:55 - 召回率提升: 0.1948
2025-12-29 18:04:55 - F1分数提升: 0.1935
2025-12-29 18:04:55 - 💾 Epoch 77 模型已保存至: model_epoch_77_20251229_121736.pth
训练损失达到 0.001473, 曲线收敛正常,模型结构具备学习能力, 能收敛. 训练精确率 召回率 F1 能达到100%, 交易期望值达+2.36. 思考: 期望达 + 2.36 代表什么? (期望为0 代表盈亏平衡)
大样本训练结果
基于以上训练,认为参数可行,于是跑大样本(75000+)
test017_train: 没做精确率加权 (样本加权: 1:1.2)
test018_train: 做了精确率加权(样本加权:1:1.6)
二者均进行了同大样本的训练. 训练结果:
- test017_train
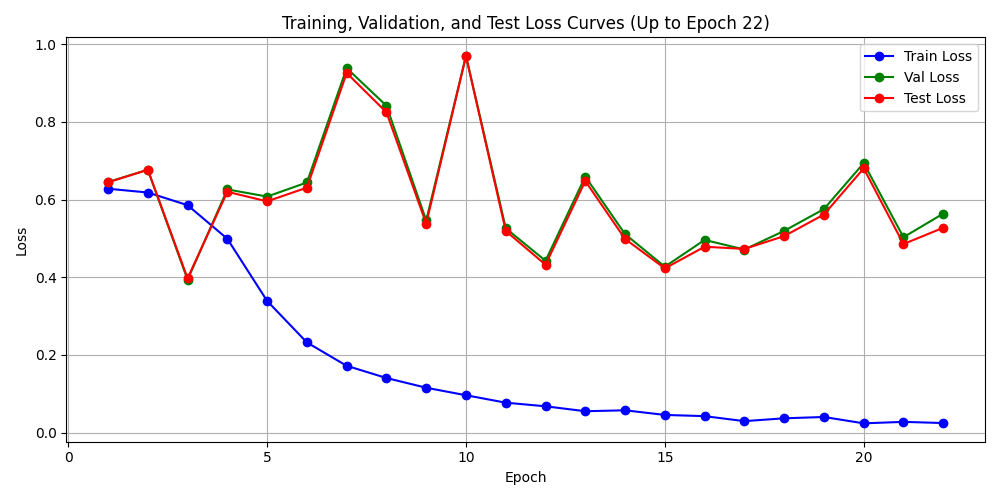
精确率最高的结果:
📊 Epoch 017 结果:
训练损失: 0.029679 | 验证损失: 0.471512 | 测试损失: 0.473021
训练准确率: 98.77% | 验证准确率: 91.43% | 测试准确率: 91.34%
训练精确率: 0.9818 | 验证精确率: 0.4955 | 测试精确率: 0.4871
训练召回率: 0.9856 | 验证召回率: 0.2695 | 测试召回率: 0.2736
训练F1分数: 0.9837 | 验证F1分数: 0.3491 | 测试F1分数: 0.3504
训练期望值: 2.4839 | 验证期望值: 1.4079 | 测试期望值: 1.2461
训练混淆矩阵:
[[7655 85]
[ 67 4577]]
验证混淆矩阵:
[[8569 225]
[ 599 221]]
测试混淆矩阵:
[[10068 278]
[ 701 264]]
📈 验证集指标绝对提升值(相对于原始样本比例基线):
准确率提升: -0.0137
精确率提升: 0.4955
召回率提升: 0.2695
F1分数提升: 0.3491
💾 Epoch 17 模型已保存至: model_epoch_17_20251229_191956.pth
✅ 新最佳验证期望模型已保存!验证期望: 1.4079
Epoch 030/2000: 100%|██████████| 774/774 [22:52<00:00, 1.77s/it, loss=0.0076, acc=99.35%]
📉 损失曲线图已保存至: plots/losses_20251229_191956_epoch_30_t17.png
📊 Epoch 030 结果:
训练损失: 0.018755 | 验证损失: 0.573060 | 测试损失: 0.538801
训练准确率: 99.35% | 验证准确率: 91.45% | 测试准确率: 91.74%
训练精确率: 0.9901 | 验证精确率: 0.4984 | 测试精确率: 0.5202
训练召回率: 0.9927 | 验证召回率: 0.3890 | 测试召回率: 0.4145
训练F1分数: 0.9914 | 验证F1分数: 0.4370 | 测试F1分数: 0.4614
训练期望值: 2.4980 | 验证期望值: 1.3466 | 测试期望值: 1.3617
训练混淆矩阵:
[[7694 46]
[ 34 4610]]
验证混淆矩阵:
[[8473 321]
[ 501 319]]
测试混淆矩阵:
[[9977 369]
[ 565 400]]
📈 验证集指标绝对提升值(相对于原始样本比例基线):
准确率提升: -0.0135
精确率提升: 0.4984
召回率提升: 0.3890
F1分数提升: 0.4370
💾 Epoch 30 模型已保存至: model_epoch_30_20251229_191956.pth
- test018_train
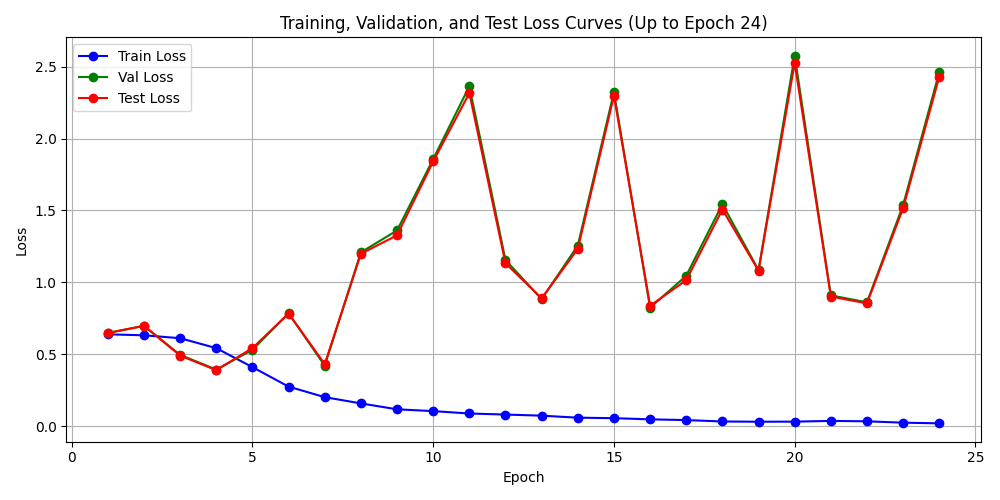
📊 Epoch 004 结果:
训练损失: 0.542239 | 验证损失: 0.393404 | 测试损失: 0.388852
训练准确率: 68.10% | 验证准确率: 90.41% | 测试准确率: 90.18%
训练精确率: 0.5596 | 验证精确率: 0.3517 | 测试精确率: 0.3245
训练召回率: 0.7011 | 验证召回率: 0.1476 | 测试召回率: 0.1399
训练F1分数: 0.6224 | 验证F1分数: 0.2079 | 测试F1分数: 0.1955
训练期望值: 1.3861 | 验证期望值: 0.9628 | 测试期望值: 0.8399
训练混淆矩阵:
[[5178 2562]
[1388 3256]]
验证混淆矩阵:
[[8571 223]
[ 699 121]]
测试混淆矩阵:
[[10065 281]
[ 830 135]]
📈 验证集指标绝对提升值(相对于原始样本比例基线):
准确率提升: -0.0239
精确率提升: 0.3517
召回率提升: 0.1476
F1分数提升: 0.2079
💾 Epoch 4 模型已保存至: model_epoch_4_20251229_180529.pth
✅ 新最佳验证期望模型已保存!验证期望: 0.9628
Epoch 005/2000: 0%| | 0/774 [00:00<?, ?it/s]/home/hyt/anaconda3/envs/tqsdk/lib/python3.9/site-packages/torch/optim/lr_scheduler.py:209: UserWarning: The epoch parameter in scheduler.step() was not necessary and is being deprecated where possible. Please use scheduler.step() to step the scheduler. During the deprecation, if epoch is different from None, the closed form is used instead of the new chainable form, where available. Please open an issue if you are unable to replicate your use case: https://github.com/pytorch/pytorch/issues/new/choose.
warnings.warn(EPOCH_DEPRECATION_WARNING, UserWarning)
Epoch 005/2000: 100%|██████████| 774/774 [19:57<00:00, 1.55s/it, loss=0.3153, acc=78.52%]
📉 损失曲线图已保存至: plots/losses_20251229_180529_epoch_5_t18.png
意料之外的是,test 17比 test 18好. test 17得到较多的高精确率(40%+), test 18 只得到偶然的一次(30%+).
问题
想到一个可能严重的问题: 样本没按时间切割划分 训练 验证 测试. 模型可能从训练集样本中 获得验证集未来走势的信息,从而造成信息泄露. 因此,下一个版本, 需修改样本集, 根据时间窗切分样本. 用当前训练最佳的脚本去跑一遍重新切割的样本集. 看看能否依然训练出效果不错的模型,如果可行,那基本是能用了.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)