Hive 3小时面试速成指南(大数据开发必备)
/ 1. 继承UDF类// 2. 实现evaluate方法if (title.contains("教程")) return "教学";if (title.contains("VLOG")) return "生活";if (title.contains("测评")) return "评测";return "其他";// 3. 在Hive中使用Hive是数据仓库工具,不是数据库,适合离线分析外部表+分
Hive 3小时面试速成指南(大数据开发必备)
hive是分布式SQL计算工具,将SQL语句翻译成MapReduce程序运行
写sql,执行的是MapReduce
一、Hive核心思想:1分钟抓住本质
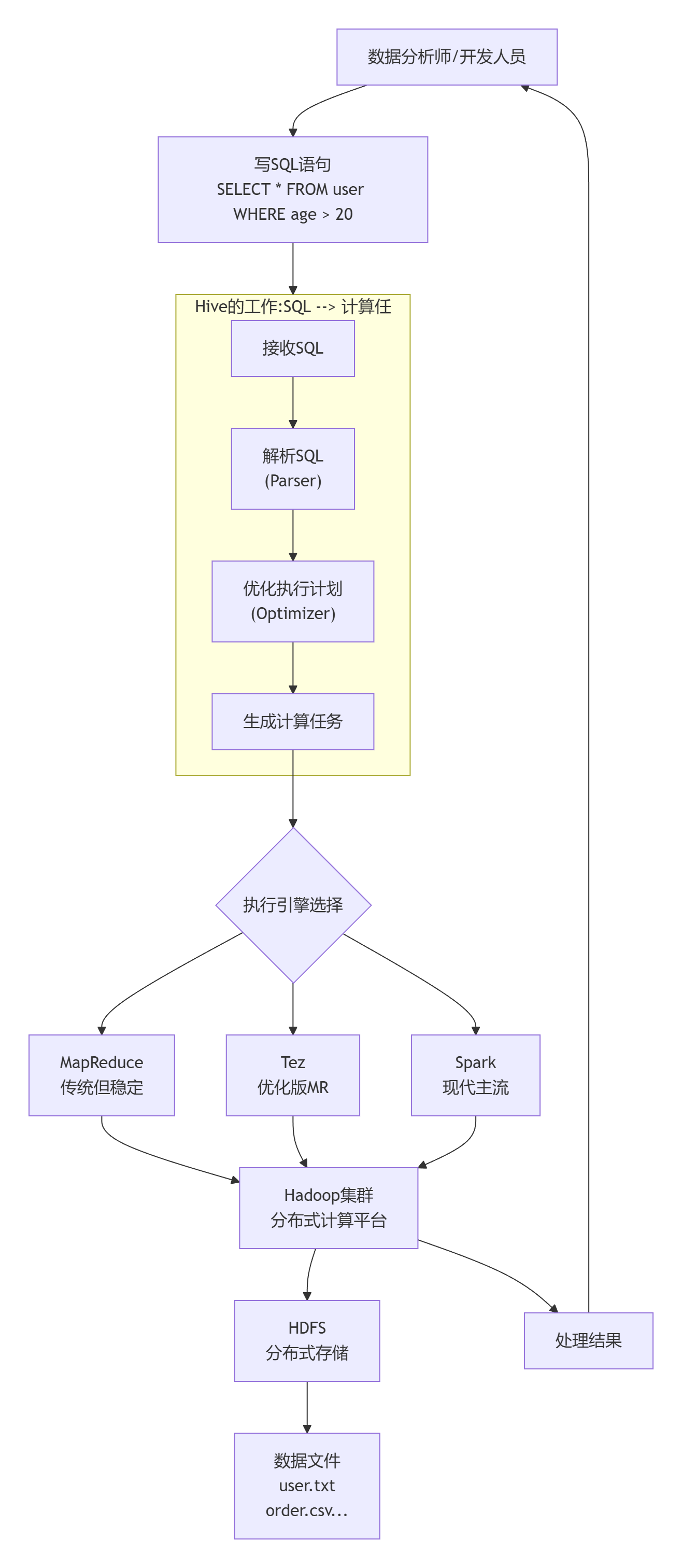
一句话理解Hive:Hive是一个数据仓库工具,它让你能用写SQL的方式处理HDFS上的大数据,而不用写复杂的MapReduce程序。
二、Hive架构:三层结构清晰理解
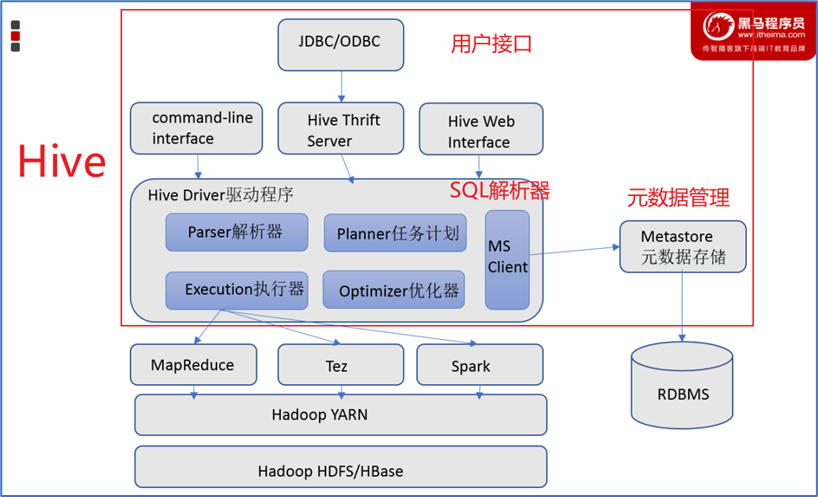
1. 客户端层(Client)
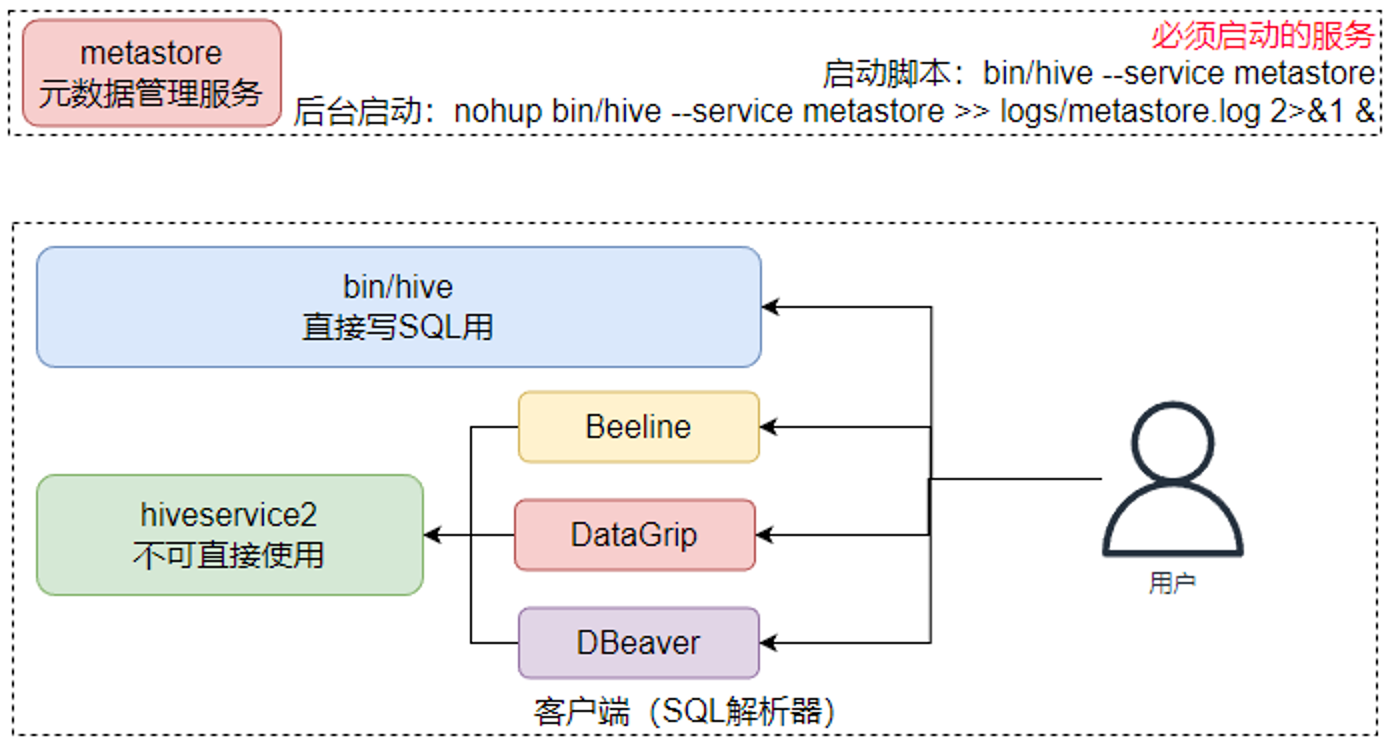
1. CLI(命令行) : hive命令
2. JDBC/ODBC : Java/Python等程序连接
3. HWI(Web界面) : 网页访问2. 服务层(关键!)
Driver(驱动程序)- "总指挥"
│
├─ Parser(解析器) : SQL → 抽象语法树(AST)
│
├─ Optimizer(优化器) : 优化查询计划(如谓词下推)
│
├─ Executor(执行器) : 执行任务
│
└─ Metastore(元数据存储)- "数据字典管理员"
↓
存储:表名、列、分区、位置、格式...
默认数据库:Derby(单机)/ MySQL(生产)3. 计算存储层
计算引擎:
- MapReduce(默认)
- Tez(更快)
- Spark(企业主流)
存储:
- HDFS(主要)
- S3、OSS(云存储)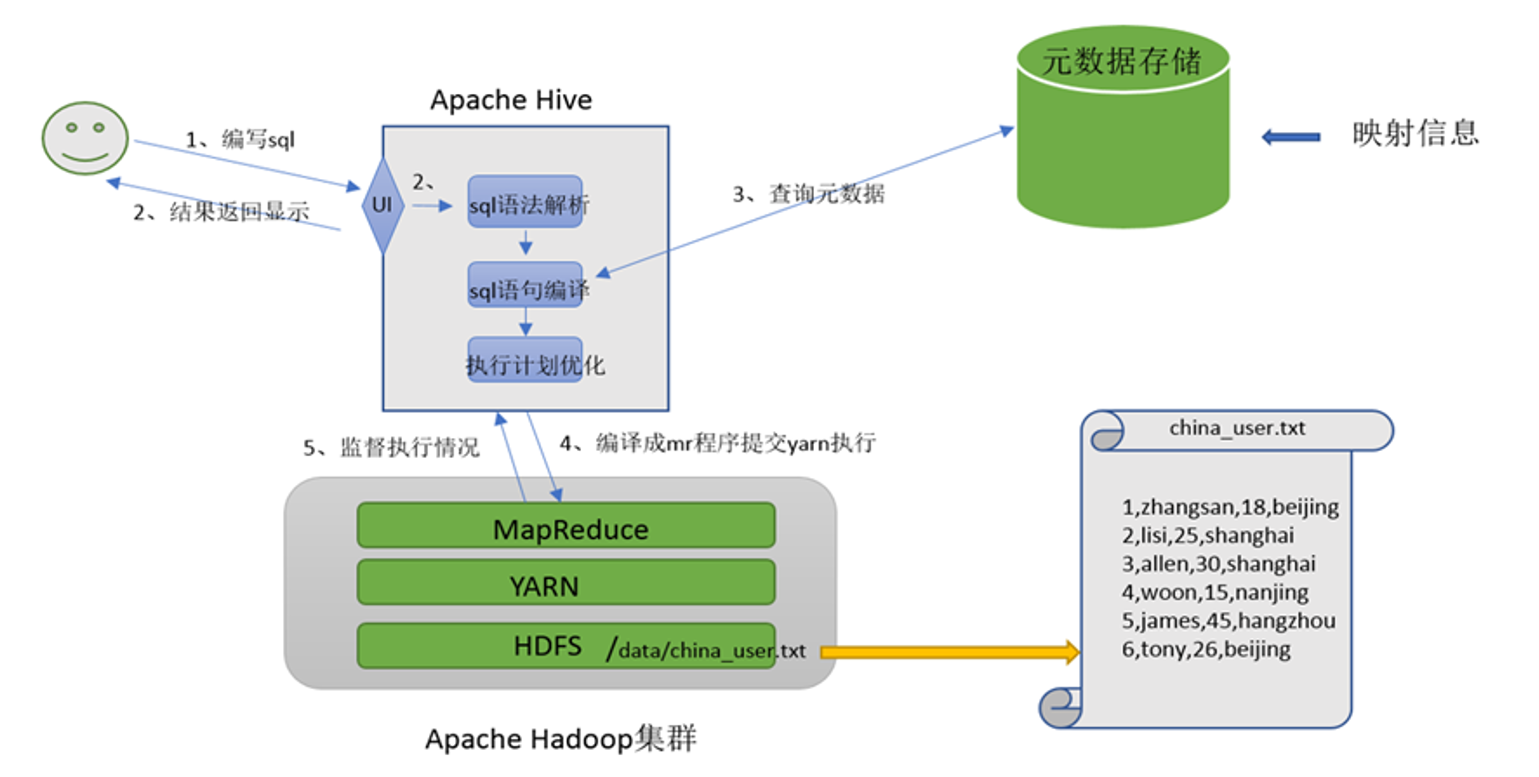
两大核心组件:SQL解析器,元数据存储
三、Hive核心概念速记表
|
概念 |
一句话解释 |
例子/注意 |
|---|---|---|
|
内部表 |
Hive完全管理的表,删表时数据一起删 |
临时中间表用这个 |
|
外部表 |
Hive只管理元数据,删表时只删元数据 |
生产数据都用外部表 |
|
分区 |
按文件夹物理分割数据,加快查询 |
|
|
分桶 |
按文件逻辑分割,优化JOIN和抽样 |
|
|
HQL |
Hive SQL,类似标准SQL但有扩展 |
多行插入、复杂类型等 |
|
SerDe |
序列化/反序列化,决定如何读数据 |
JSON、CSV、Parquet等格式 |
四、Hive SQL速成:20个最常用操作
1. 数据库操作
-- 创建数据库(指定位置)
CREATE DATABASE IF NOT EXISTS video_db
COMMENT '视频数据库'
LOCATION '/data/video_db';
-- 查看数据库
SHOW DATABASES LIKE 'video*';
-- 切换数据库
USE video_db;2. 表操作(重点!)
-- 创建外部表(企业常用)
CREATE EXTERNAL TABLE IF NOT EXISTS video_plays (
video_id BIGINT COMMENT '视频ID',
user_id BIGINT COMMENT '用户ID',
play_duration INT COMMENT '播放时长(秒)',
play_time TIMESTAMP COMMENT '播放时间',
device_type STRING COMMENT '设备类型'
) COMMENT '视频播放记录表'
PARTITIONED BY (dt STRING) -- 按天分区
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',' -- 字段分隔符
STORED AS TEXTFILE -- 存储格式
LOCATION '/data/video/plays' -- HDFS路径
TBLPROPERTIES ('creator'='yingshijufeng');
-- 创建ORC表(性能优化)
CREATE TABLE video_stats_orc (
video_id BIGINT,
play_count BIGINT,
like_count BIGINT,
avg_duration DOUBLE
) STORED AS ORC; -- ORC格式:列式存储,压缩率高,查询快3. 分区表操作(面试必问!)
-- 添加分区
ALTER TABLE video_plays ADD PARTITION (dt='2024-01-01');
ALTER TABLE video_plays ADD PARTITION (dt='2024-01-02');
-- 动态分区插入(常用!)
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
INSERT OVERWRITE TABLE video_plays PARTITION (dt)
SELECT
video_id,
user_id,
play_duration,
play_time,
device_type,
DATE_FORMAT(play_time, 'yyyy-MM-dd') as dt -- 自动分区
FROM source_table;
-- 查看分区
SHOW PARTITIONS video_plays;
-- 查询指定分区(避免全表扫描)
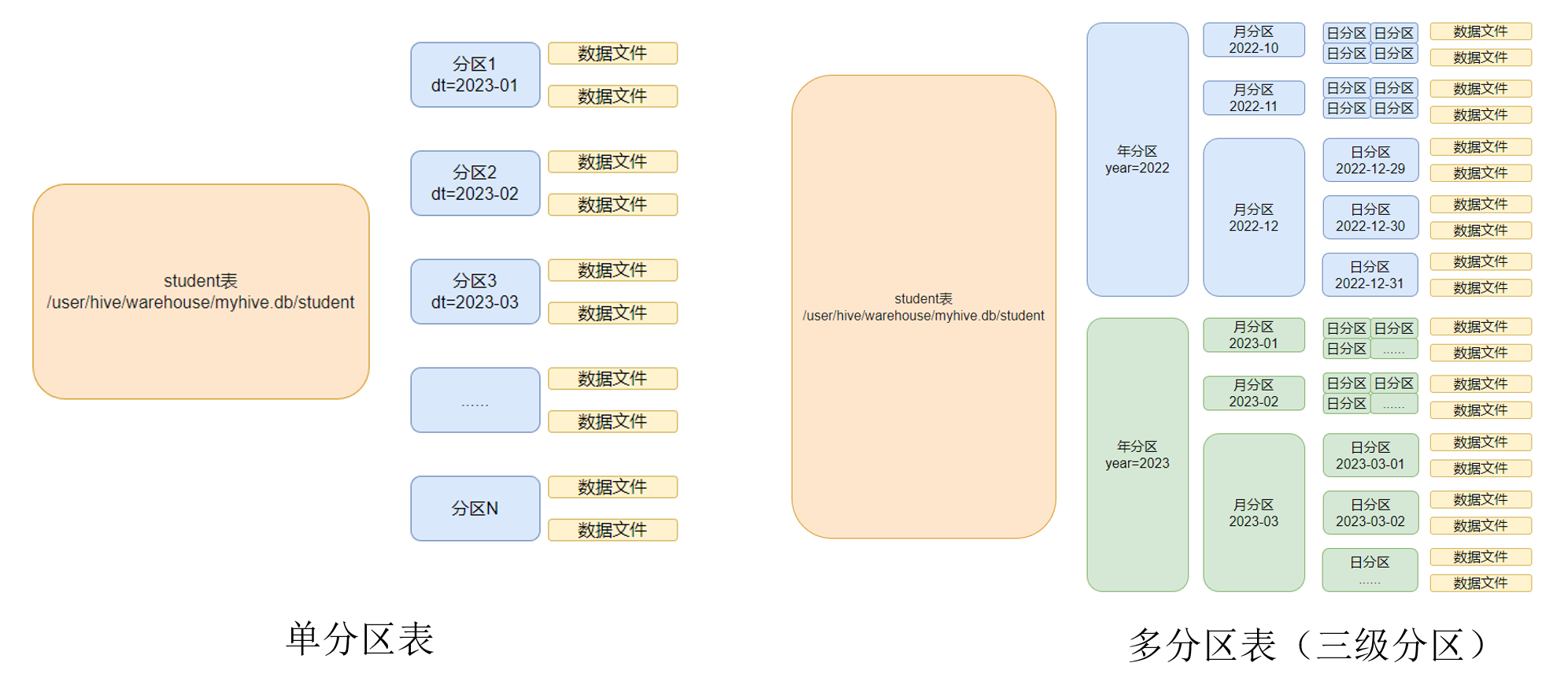
SELECT * FROM video_plays WHERE dt='2024-01-01';按照时间,将数据划分位小块,如:一个月一个分区、一年一个分区。每一个分区就是文件夹
一个表里可以有多个分区(按时间分区),每个分区有对应的数据文件
4. 数据加载
-- 1. 从本地加载
LOAD DATA LOCAL INPATH '/home/data/plays.csv'
OVERWRITE INTO TABLE video_plays
PARTITION (dt='2024-01-01');
-- 2. 从HDFS加载
LOAD DATA INPATH '/tmp/plays.csv'
INTO TABLE video_plays
PARTITION (dt='2024-01-01');
-- 3. INSERT方式(最常用)
INSERT OVERWRITE TABLE video_plays PARTITION (dt='2024-01-01')
SELECT * FROM temp_table;
5. 查询优化技巧
-- 1. 避免SELECT *,只取需要的列
SELECT video_id, play_duration FROM video_plays;
-- 2. 分区过滤在前
SELECT * FROM video_plays
WHERE dt='2024-01-01' -- 分区条件在前
AND play_duration > 60; -- 普通条件在后
-- 3. 使用EXPLAIN查看执行计划
EXPLAIN
SELECT video_id, COUNT(*) as plays
FROM video_plays
WHERE dt='2024-01-01'
GROUP BY video_id
HAVING plays > 1000;
-- 4. JOIN优化:小表在前,大表在后
SELECT /*+ MAPJOIN(small_table) */
a.*, b.*
FROM small_table a
JOIN large_table b ON a.id = b.id;5. 数据分桶
将一个表的数据差分到固定的不同文件夹中(可以自定义文件夹的数量,图下为3)
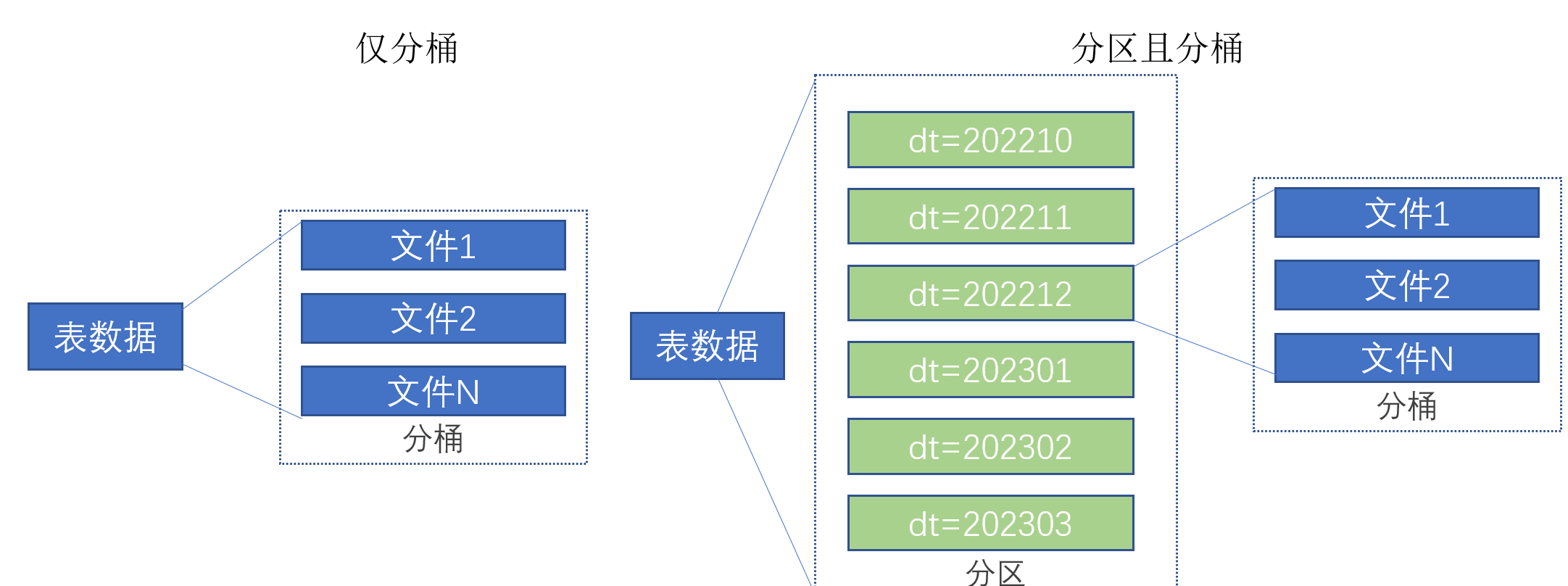
新来的数据到底要插入到哪个桶,是根据分桶列决定的。
向分桶表里加载数据不能直接用load data,因为分桶表不支持,所以要用一个中转表load data,再将中转表insert到分桶表里。
问题就在于:如何将数据分成三份,划分的规则是什么?
数据的三份划分基于分桶列的值进行hash取模来决定。由于load data不会触发MapReduce,也就是没有计算过程(无法执行Hash算法),只是简单的移动数据而已。所以无法用于分桶表数据插入。
五、Hive企业实战:影视数据分析案例
场景:分析视频播放数据
-- 1. 创建播放记录表
CREATE EXTERNAL TABLE video_plays (
video_id BIGINT,
user_id BIGINT,
duration INT,
play_time TIMESTAMP,
device STRING
) PARTITIONED BY (dt STRING)
STORED AS PARQUET; -- Parquet格式,列式存储,查询快
-- 2. 创建视频维度表
CREATE EXTERNAL TABLE video_info (
video_id BIGINT,
title STRING,
category STRING,
duration INT,
uploader STRING,
upload_time TIMESTAMP
) STORED AS ORC;
-- 3. 核心分析:每日播放统计
SELECT
v.dt as 日期,
i.category as 视频类别,
COUNT(DISTINCT v.user_id) as 观看人数,
COUNT(*) as 播放次数,
AVG(v.duration) as 平均观看时长,
SUM(CASE WHEN v.duration >= i.duration * 0.8 THEN 1 ELSE 0 END)
/ COUNT(*) as 完播率
FROM video_plays v
JOIN video_info i ON v.video_id = i.video_id
WHERE v.dt >= '2024-01-01'
AND v.dt <= '2024-01-07'
GROUP BY v.dt, i.category
ORDER BY 观看人数 DESC;
-- 4. 用户行为分析:观看时段分布
SELECT
HOUR(play_time) as 时段,
COUNT(*) as 播放量,
COUNT(DISTINCT user_id) as 独立用户数
FROM video_plays
WHERE dt = '2024-01-01'
GROUP BY HOUR(play_time)
ORDER BY 时段;
-- 5. 热门视频TOP10
SELECT
v.video_id,
i.title,
COUNT(*) as 播放量,
COUNT(DISTINCT v.user_id) as 观看人数,
AVG(v.duration) as 平均观看时长
FROM video_plays v
JOIN video_info i ON v.video_id = i.video_id
WHERE v.dt = '2024-01-01'
GROUP BY v.video_id, i.title
ORDER BY 播放量 DESC
LIMIT 10;六、性能优化:企业级调优策略
1. 存储格式选择
-- 不同格式对比
TEXTFILE: -- 默认,可读性好,查询慢
CSV: -- 文本,兼容性好
ORC: -- 列式存储,压缩率高,查询快(推荐)
PARQUET: -- 列式存储,兼容性好(推荐)
AVRO: -- 支持Schema演进2. 压缩优化
-- 启用压缩
SET hive.exec.compress.intermediate=true; -- 中间结果压缩
SET hive.exec.compress.output=true; -- 输出结果压缩
SET mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
SET mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;3. 参数调优(面试高频!)
-- 1. 动态分区设置
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
SET hive.exec.max.dynamic.partitions=1000;
-- 2. 向量化查询(性能大幅提升)
SET hive.vectorized.execution.enabled=true;
SET hive.vectorized.execution.reduce.enabled=true;
-- 3. 并行执行
SET hive.exec.parallel=true;
SET hive.exec.parallel.thread.number=8;
-- 4. 合并小文件(HDFS优化)
SET hive.merge.mapfiles=true; -- Map-only任务输出合并
SET hive.merge.mapredfiles=true; -- MapReduce任务输出合并
SET hive.merge.size.per.task=256000000; -- 合并后文件大小
SET hive.merge.smallfiles.avgsize=16000000; -- 平均文件小于16M就合并4. 数据倾斜解决方案(最重要!)
-- 场景:GROUP BY时某些key数据量过大
-- 方案1:启用Map端聚合
SET hive.map.aggr=true;
SET hive.groupby.mapaggr.checkinterval=100000;
-- 方案2:启用倾斜数据优化
SET hive.groupby.skewindata=true; -- 生成两个MR Job
-- 第一个Job:Map结果随机分发到Reduce
-- 第二个Job:在Reduce端聚合
-- 方案3:JOIN数据倾斜优化
SET hive.optimize.skewjoin=true;
SET hive.skewjoin.key=100000; -- 认为超过10万的key是倾斜key七、Hive vs Spark SQL vs 传统数据库
|
特性 |
Hive |
Spark SQL |
MySQL |
|---|---|---|---|
|
定位 |
数据仓库 |
分布式SQL引擎 |
关系型数据库 |
|
计算引擎 |
MR/Tez/Spark |
Spark |
单机/主从 |
|
延迟 |
分钟/小时级 |
秒/分钟级 |
毫秒级 |
|
数据规模 |
PB级 |
PB级 |
TB级 |
|
更新 |
批量(INSERT OVERWRITE) |
批量/准实时 |
实时 |
|
事务 |
支持(有限制) |
支持 |
完整ACID |
|
适用场景 |
离线分析、ETL |
离线+实时分析 |
在线事务 |
八、Hive必知的6个高级特性
1. 复杂数据类型
-- ARRAY
SELECT
video_id,
collect_set(user_id) as viewers_array -- 去重聚合
FROM video_plays
GROUP BY video_id;
-- MAP
CREATE TABLE user_tags (
user_id BIGINT,
tags MAP<STRING, STRING> -- 键值对
);
-- STRUCT
SELECT
video_id,
named_struct('plays', COUNT(*),
'users', COUNT(DISTINCT user_id)) as stats
FROM video_plays
GROUP BY video_id;2. 窗口函数(面试高频!)
-- 计算每个视频的播放排名
SELECT
video_id,
dt,
play_count,
ROW_NUMBER() OVER (PARTITION BY dt ORDER BY play_count DESC) as rank,
SUM(play_count) OVER (PARTITION BY dt) as daily_total,
AVG(play_count) OVER (PARTITION BY dt) as daily_avg
FROM (
SELECT
video_id,
dt,
COUNT(*) as play_count
FROM video_plays
WHERE dt >= '2024-01-01'
GROUP BY video_id, dt
) t;3. UDF开发(自定义函数)
// 1. 继承UDF类
public class VideoCategoryUDF extends UDF {
// 2. 实现evaluate方法
public String evaluate(String title) {
if (title.contains("教程")) return "教学";
if (title.contains("VLOG")) return "生活";
if (title.contains("测评")) return "评测";
return "其他";
}
}
// 3. 在Hive中使用
ADD JAR /path/to/udf.jar;
CREATE TEMPORARY FUNCTION video_category AS 'com.ysjf.VideoCategoryUDF';
SELECT video_category(title) as category FROM video_info;九、面试高频问题与回答模板
Q1: Hive内部表和外部表的区别?
标准回答:
"内部表由Hive全权管理,删除表时元数据和HDFS数据都会被删除,适合存储中间结果。外部表Hive只管理元数据,删除表时只删除元数据,HDFS数据依然保留,适合存储原始数据,避免误删。生产环境通常都使用外部表。"
Q2: 分区和分桶的区别?
标准回答:
"分区是按文件夹物理划分数据,通常按时间、地域等维度,能显著加快过滤查询。分桶是按文件逻辑划分,通常按某个字段的哈希值,主要用于优化JOIN、加快抽样、提高聚合效率。两者可结合使用,先分区再分桶。"
Q3: 如何优化Hive查询性能?
标准回答:
"我通常从五个层面优化:第一,存储层,使用ORC/Parquet列式存储并启用压缩。第二,表设计层,合理使用分区和分桶。第三,查询层,避免SELECT *,尽早过滤,小表放在JOIN左边。第四,参数调优,如开启向量化查询、并行执行。第五,处理数据倾斜,如启用hive.groupby.skewindata。"
Q4: Hive on MapReduce vs Hive on Spark?
标准回答:
"Hive on MR稳定但较慢,适合对延迟不敏感的离线任务。Hive on Spark利用Spark内存计算,速度更快,支持更复杂的DAG执行,是现代大数据平台的标配。我们通常用Spark处理ETL和复杂分析,Hive做数仓存储和即席查询。"
Q5: 数据倾斜如何处理?
标准回答:
"先定位倾斜key,然后针对性处理:如果是GROUP BY倾斜,开启hive.groupby.skewindata生成两阶段Job。如果是JOIN倾斜,可拆分成两个任务分别处理倾斜和非倾斜数据,或给倾斜key加随机前缀打散。还可以调大reduce数,或开启hive.optimize.skewjoin自动处理。"
十、实战速成:2小时搭建Hive环境
Docker快速体验
# 1. 拉取Hive镜像
docker pull bde2020/hive:2.3.2-postgresql-metastore
# 2. 启动Hive
docker-compose up -d
# 3. 进入Hive CLI
docker exec -it hive-server bash
/opt/hive/bin/beeline -u jdbc:hive2://localhost:10000
# 4. 运行示例
CREATE TABLE test (id INT, name STRING);
INSERT INTO test VALUES (1, 'video1'), (2, 'video2');
SELECT * FROM test;常用Hive命令备忘
# 启动Hive CLI
hive
# 执行SQL文件
hive -f /path/to/query.sql
# 执行单条SQL
hive -e "SELECT * FROM video_plays LIMIT 10;"
# 查看表结构
DESCRIBE FORMATTED video_plays;
# 导入数据
LOAD DATA LOCAL INPATH '/home/data.csv' INTO TABLE my_table;十一、针对影视的Hive应用建议
数据仓库分层设计
-- ODS层:原始数据
CREATE TABLE ods_video_play ( ... ) PARTITIONED BY (dt STRING);
-- DWD层:明细宽表
CREATE TABLE dwd_video_user_play (
-- 整合视频、用户、设备信息
) PARTITIONED BY (dt STRING);
-- DWS层:聚合层
CREATE TABLE dws_video_daily (
-- 视频日度汇总
) PARTITIONED BY (dt STRING);
-- ADS层:应用层
CREATE TABLE ads_video_hot_top10 (
-- 热门视频TOP10
);典型业务场景SQL
-- 场景1:用户观看偏好分析
SELECT
user_id,
COLLECT_SET(category) as categories, -- 观看的类别
COUNT(DISTINCT video_id) as video_cnt,
AVG(duration) as avg_duration
FROM dwd_video_user_play
WHERE dt >= '2024-01-01'
GROUP BY user_id
HAVING video_cnt > 5;
-- 场景2:视频推荐候选集
WITH user_watch AS (
-- 用户最近观看的视频
SELECT user_id, video_id
FROM dwd_video_user_play
WHERE dt >= DATE_SUB(CURRENT_DATE, 7)
),
similar_video AS (
-- 基于协同过滤的相似视频
SELECT ...
)
-- 为用户推荐未观看的相似视频
SELECT ...📊 最后总结:Hive面试速记要点
必须掌握的3个核心:
-
Hive是数据仓库工具,不是数据库,适合离线分析
-
外部表+分区+ORC格式是企业标配
-
SQL转MapReduce/Spark任务是核心原理
必须理解的4个概念:
-
分区:按文件夹切分,加快查询
-
分桶:按文件切分,优化JOIN
-
存储格式:ORC/Parquet比Textfile快10倍
-
数据倾斜:GROUP BY和JOIN的常见问题
必须知道的3个优化:
-
使用分区过滤减少数据扫描
-
启用向量化查询提升性能
-
开启压缩减少存储和传输
面试一句话总结:
"Hive让我能用熟悉的SQL处理大数据,我了解它的架构原理,掌握外部表、分区、ORC等优化手段,能处理数据倾斜等常见问题,能够为影视飓风设计合理的数据仓库分层和ETL流程。"
现在你可以:
-
解释Hive的架构和原理
-
写出常用的Hive SQL
-
说出3个以上优化技巧
-
设计一个简单的数仓分层
-
回答面试中的Hive问题
你已经掌握了Hive的核心!实际工作中,Hive就是"写SQL",但理解背后的原理能让你写出更高效的SQL。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)