(2025|上交,Agent 泛化,VLM 推理 + 世界模型推演 + RL,PhysCode)IPR-1:交互式物理推理器
IPR 是一种通过将以物理为中心的潜在动作空间与预测引导的 VLM 优化相结合来用预测强化物理推理的范式,使得物理和因果规律直接从交互后果中提炼,而非来自静态语料库。IPR 相较于基于 VLM、基于预测和基于强化学习的基线都产生了稳健的增益,并显示出对未见游戏的强大零样本迁移能力。
IPR-1: Interactive Physical Reasoner

论文地址:https://arxiv.org/abs/2511.15407
项目页面:https://mybearyzhang.github.io/ipr-1/
进 Q 学术交流群:922230617 或加 CV_EDPJ 进 W 交流群
目录
1. 引言
人类通过观察、与环境持续互动以及内化物理规律和因果关系进行学习。智能体(Agent)是否能够像人类一样,随着经验积累不断提升推理能力?
现有范式难以支撑这一目标。
- 预训练 VLM 虽具备丰富的语义与推理能力,但主要停留在静态模式匹配层面,缺乏对交互后果的前瞻预测;
- 行为克隆式(Behavior-cloned) VLA 受限于示例覆盖与质量,难以应对环境变化;
- RL 方法 在复杂环境中样本效率低,容易学习任务捷径;
- 世界模型 虽然可以进行想象,却常退化为视觉相关性的模仿,而非真正理解物理与因果。
这些问题的共同根源在于:模型过度拟合视觉外观与接口形式,而未能抽取跨环境共享的物理与因果机制。
- 生成式世界模型 捕捉动力学,但经常 过度建模 整个感知空间;
- VLM 尽管提供了丰富的语义先验,却缺乏精确物理一致性所需的预测性基础;
- RL 擅长通过交互进行优化,但依赖于稀疏、与任务纠缠的信号,这阻碍了泛化。
这促使人们采取一种 “混合” 视角:不应完全致力于探索、全场景预测或静态先验,而应重新考虑吸收这些组分的比例。
为实现这一想法,本文的方法遵循 潜在世界模型(Latent World Model)范式,以此作为整合这些优势的结构骨架。具体而言,一个可扩展的推理器应当:
- (潜在动作空间)仅建模预测后果所必需的 基本潜在动力学(essential latent dynamics)——舍弃高保真的像素重建;
- (VLM 推理)通过一个由 基于 VLM 的语义先验 丰富的策略与原始多模态信号交互;
- (世界模型推演)使用反映物理可行性的 预测反馈 来强化此策略。
通过将预测目标从原始观察转移到抽象表征,系统过滤掉与任务无关的感知噪声,使智能体能够捕捉物理和因果机制的 “本质” 而非世界的 “表象”。
基于此,本文提出 交互式物理推理器(Interactive Physical Reasoner, IPR),通过将世界模型的预测能力与 VLM 的语义推理能力在同一 物理中心的潜在动作空间 中对齐,使交互经验能够持续反向强化推理能力。
为系统评估该范式,本文提出 Game-to-Unseen(G2U) 设定:
- 构建包含 1000+ 高度异构(heterogeneous)游戏的大规模基准
- 并采用马斯洛的 “生存-好奇-效用” 三层评估体系,覆盖从物理直觉到目标导向推理的能力谱系。
- 实验表明,IPR 在三层任务上均保持稳健表现,整体性能超过 GPT-5,并可零样本泛化至未见游戏。
2. 基础
2.1 问题设定
本文考虑一系列交互环境 M,每个环境形式化为一个 部分可观察马尔可夫决策过程(Partially Observable Markov Decision Process,POMDP),其中包含潜在的物理参数 φ(例如,重力,摩擦力,质量等)。
![]()
在时间步 t,环境产生图像 x,将其编码为 z;智能体执行动作 a ∈ A 并根据状态转移函数 T 和奖励函数 R 进行状态转移,其中物理机制体现在状态转移函数中,因果关系体现在奖励函数中。
![]()
控制可以使用几种接口中的一种:键盘、语言或潜在空间;
- 一个以目标为条件的(goal-conditioned) VLM 通过一个策略在所选空间中选择动作。
- 然后,一个特征级的世界模型在同一动作空间中对选定动作序列进行想象未来的推演。
- 给定时间范围,初始化并选择一个动作序列。推演定义为,其中索引从时间到时间内的想象轨迹中的步骤。
2.2 PhysCode:以物理为中心的动作代码
受原始按键语义别名问题以及用语言表达时细粒度视觉动力学失真(dynamics distortion)的启发,本文提出了 PhysCode,一种基于 VQ 码本(codebook)的离散潜在动作表示。在每一步,动作是一个短代码(code)序列,其嵌入(embedding)通过查找并池化(pooling)码本向量获得。
每个代码以三个线索为条件:
- 通过 DINOv3 特征获得的 领域特定 视觉外观;
- 通过光流(optical flow)获得的 领域无关 运动;
- 通过 T5 编码器提取的轻量级语义提示。
由于仅凭自然语言无法表达细粒度的动力学,可依赖光流和视觉特征来承载这些细节,同时将语义作为指导。
通过设计,
- 生成的代码捕获了 与物理相关的 干预基元(intervention primitives),
- 这些基元在具有相似底层物理的环境间 共享,在物理不同的环境间 分离,
- 从而在匹配的物理条件下实现一致重用(reuse),在变化的动力学下实现区分。
3. 方法
本节介绍 IPR 的三个组成部分:
- 学习一个跨越不同物理原理和因果机制的 以物理为中心的动作代码词汇表;
- 训练一个 以潜在条件为基础的世界模型,该模型预测潜在动作序列下的未来特征和奖励;
- 在交互环境中,使用对齐的潜在动作代码,通过世界模型推演预测来强化 VLM。
在推理时,VLM 提出候选潜在动作,查询世界模型进行短视距想象和价值估计以对它们评分,并执行得分最高的动作。
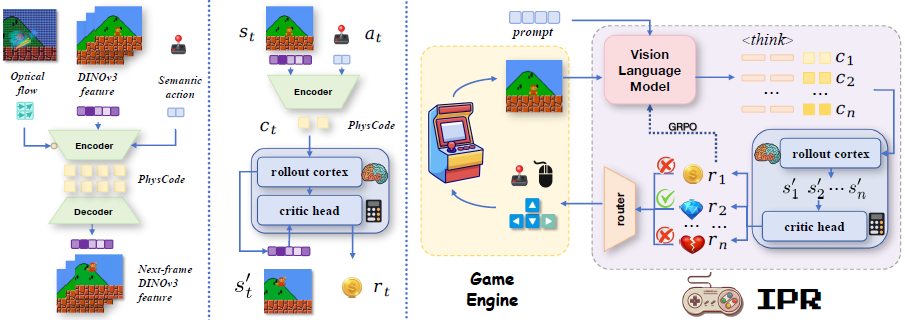
(左)归纳潜在动作词汇表。
- 对于第 2.2 节中的三个线索,使用一个小型门控融合模块形成融合表征 h
- 一个时空编码器 E 将融合表征 h 映射到一个连续代码 z,
- 该代码通过码本 c 向量量化为一个索引 a,
- 解码器基于过去的特征 f_t 和码本 c_a 来预测未来特征 f_(t+Δ)。
本文使用标准的 VQ-VAE 目标进行训练,并在光流上增加了模态丢弃以及温和的门控稀疏正则化器,以避免过度依赖可选线索。由于光流仅在预训练期间可用,它作为特权信息帮助 塑造以物理为中心的码本,而丢弃和门控稀疏性则将这种结构提炼到编码器中,使得在测试时仅依赖于外观和语义线索。
在推理时,禁用光流门控,并重用相同的编码器仅从外观+语义中获得及其量化索引。得到的离散词汇表产生具有时间预测性的 token,这些 token 在匹配的物理下聚类,在不同动力学下分离,为 VLM 推理和世界模型预测提供了一个共享接口。
(中)用评论器(critic)训练潜在级世界模型。 固定潜在动作词汇表后,训练一个特征级世界模型来预测以潜在动作为条件的未来特征,用它们的 PhysCode 索引替换原始控制。对于三元组
![]()
将 a_t 嵌入为 e_(a_t) 并计算
![]()
预测在 潜空间 中进行,因为特征压缩了外观变化和渲染噪声,使得动力学在游戏间更可共享。具体而言,
- 首先用特征预测损失训练世界模型
- 然后用 Q 学习风格的目标学习一个评论器头 V_θ
![]()
其中,y_t 是通过标准时序差分备份从推演回报(rollout returns)计算的目标价值。
(右)预测强化的交互式推理。 基于预测来强化交互式推理:世界模型想象推演,VLM 在相同的潜在动作空间中规划。本文采用 Qwen3-VL-8B 作为骨干,并用 PhysCode token 扩展其 tokenizer,使 VLM 能够直接输出离散潜在动作,同时保留其语言能力。
- 首先通过(f_t,c_t)对进行监督训练来对齐感知和动作,其中 f_t 是当前帧的 DINOv3 特征,c_t 是在阶段 1 学习的潜在动作。
- 给定当前上下文和目标 g,VLM 采样 B 个候选 PhysCode 序列 a^(b),世界模型运行短视距想象推演为每个序列分配一个预测回报,据此计算优势 A。
- 然后使用 GRPO 更新策略
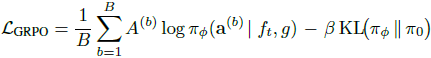
在推理时,VLM 提出潜在动作候选,世界模型通过短视距推演对它们进行评分和剪枝,路由器将选定的 PhysCode 映射到环境控制。通过在这种预测循环方案下的反复交互,从想象和执行轨迹中收集的经验强化了 VLM,改善了其在交互环境中的物理推理。
4. 实验
本节旨在回答三个问题:
- 与原始键盘输入或语言指令相比,为什么 PhysCode 是必要的?
- 世界模型预测如何强化 VLM 推理?
- IPR 是否会显示出迁移到未见游戏的扩展潜力?
4.1 设置:数据集、任务和指标
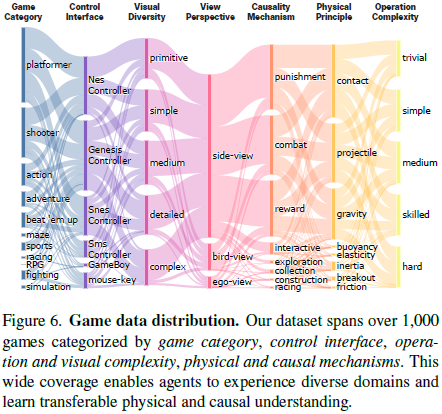
数据集:实验基于 1000+ 游戏构建的数据集,覆盖游戏类别、控制接口、视觉复杂度、视角、因果机制、物理原理和操作难度等七个维度。
数据收集和预处理。
- 在整个 1000+ 游戏语料库中,以 60 FPS 记录每个游戏 4 分钟的人类游戏过程,并获得每款游戏的注释,涵盖物理原理、因果机制、动作语义 和 游戏指令。
- 此外,执行了一系列预处理,包括归一化时间间隔、移除非交互片段、重新平衡过长的空闲/无操作时段等。
分层级设计。 受马斯洛需求层次理论启发,将游戏视为一个三级进程:生存 → 好奇 → 效用,从直觉到推理。
-
生存:目标是尽可能长时间地存活,忽略原始目标并避免风险。本文报告每款游戏归一化的生存时间。
-
好奇:目标是像婴儿一样访问新状态,以揭示环境的动力学和因果机制中的规律。本文使用预训练的 CLIP 视觉编码器嵌入帧,计算轨迹的多尺度度量空间幅度曲线,并将探索分数定义为该曲线下的面积,更大的表示更广泛的状态空间覆盖。
-
效用:效用衡量智能体实现 Bentham 的生命效用的程度:致力于以更高奖励和更短时间完成目标。本文根据游戏类型评估下游目标,并报告每款游戏的人类归一化分数。
4.2 PhysCode 的必要性
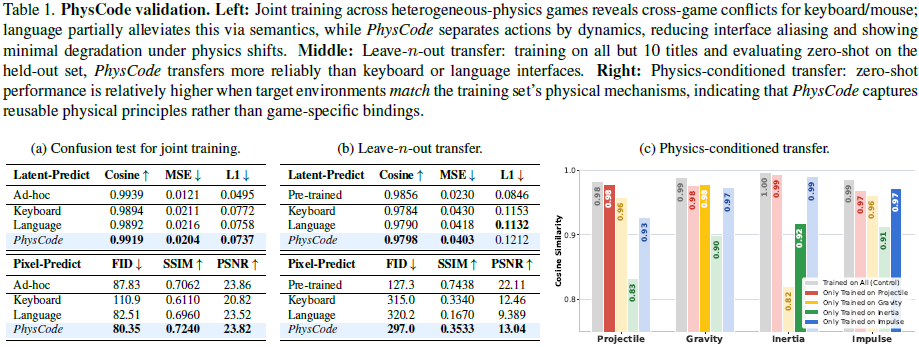
本节调查与原始键盘/鼠标输入和自然语言指令相比,PhysCode 是否必要。
1)在具有异构物理的混合游戏联合训练下评估稳健性,检查哪种动作空间在多样化的物理机制和不同控制台/游戏接口中表现最佳。如表 1 a 所示,
- 在这种机制下,原始键盘/鼠标输入表现出跨游戏冲突(同一按键在不同环境中触发不同行为)。
- 语言接口通过显式语义部分缓解了此问题。
- PhysCode 通过动力学分离动作,减少了接口别名,并在物理变化下显示出最小的性能下降。
2)测试迁移:在源游戏上学习的共享 PhysCode 在具有匹配物理的未见环境中提高了零样本性能,证明了真正的物理基础,而非接口记忆。
- 在一个留出-n-个的协议中,在除 10 个游戏外的所有游戏上训练,并在留出的游戏上进行零样本评估。如表 1 b 所示,PhysCode 比键盘或语言指令迁移更可靠。
- 此外,根据环境的物理条件进行迁移。按主导物理机制对游戏分组,在一个原理下训练,并在具有匹配或不匹配机制的留出游戏上进行零样本评估。如表 1 c 所示,当目标匹配训练物理时,零样本性能通常更高,但也有明显的例外,例如惯性(inertia),可能已被抛射物/冲量所覆盖。这表明 PhysCode 捕获了可重用的物理机制,而不是游戏特定的绑定,尽管本文粗略的物理分类法与智能体的内部抽象并不完全一致。
4.3 在多样化物理世界中游戏
本文在 200 个游戏上评估 IPR 与主流基线,所选游戏匹配完整数据集在类型、动作空间和物理/因果上的分布。基线包括:
-
强化学习:本文使用多任务 PPO 和共享参数 DQN 作为标准的强化学习方法。
-
视觉语言模型:本文采用一系列视觉语言模型,包括闭源模型如 GPT-4o 和 GPT-5,以及开源模型如 Qwen3-VL-30B-A3B。
-
世界模型:本文比较三种不同的世界模型:DreamerV3、V-JEPA2 和 Genie。
-
模仿学习:本文应用模仿学习模型,包括 ACT 和 Qwen3-VL-8B。
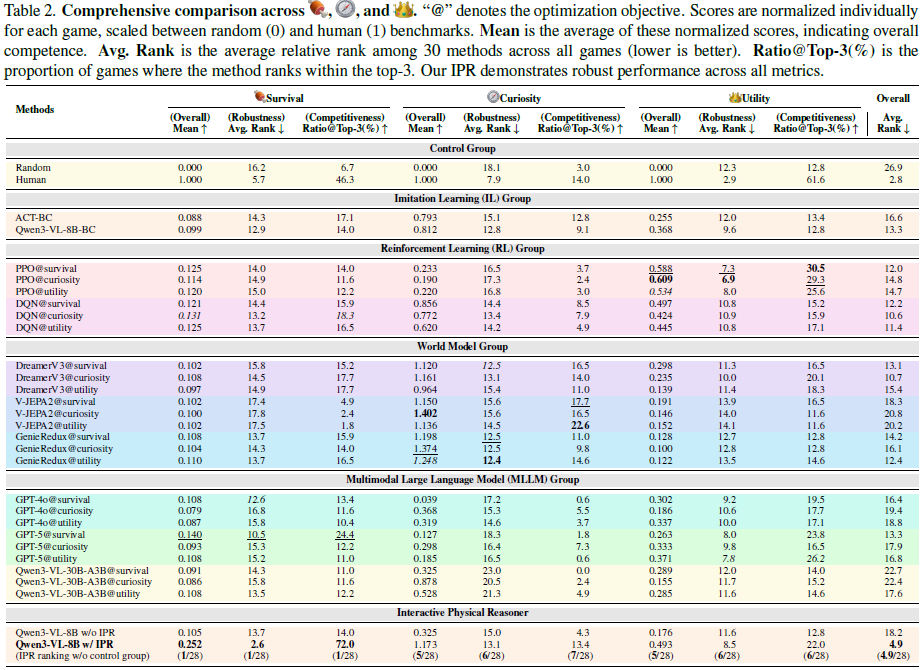
本文在三个分层(生存/Survival,好奇/Curiosity,效用/Utility)目标上评估每个模型,实例化特定层级的训练或提示。关键结果总结如下:
-
基于预测的方法:在好奇层级强,但在生存和效用层级较弱。训练于广泛的探索性轨迹,潜在推演拓宽了覆盖范围并揭示了动力学,但倾向于模仿视觉相似的未来,而非可靠地追求目标。因此,预测作为风险和候选动作的前瞻先验是有用的。
-
基于强化学习的方法:当奖励设计良好时,在生存和效用层级强,但在好奇和无显式目标的任务上较弱。奖励梯度在正确的信号下支持有效的信用分配,然而稀疏性和部分可观察性会引发不稳定和接口过度拟合,因此强化学习最适合作为一种优化方法。
-
基于经验的方法:在类人的生存层级强,但在好奇和效用层级较弱。刻意模仿人类轨迹,因此在低风险生存上表现出色,但一旦任务需要精确控制或探索时就会遇到困难,其性能严重依赖于演示的覆盖范围和质量。
-
基于推理的预训练视觉语言模型:在以目标为条件的生存和效用层级强,在好奇层级较弱。它们擅长指令驱动的推理,但无法预测视觉状态空间中的后果,因此最适合作为需要辅助预测模块来进行结果感知决策的高级推理器。
-
交互式物理推理器:在生存、好奇和效用三个层级上均表现稳健。本文结合了所有三种范式的优势:视觉语言模型提供目标驱动的因果推理,世界模型提供推演预测,强化学习利用想象奖励优化决策,在所有三个层级上均产生了一致的强大性能。
总结:基于预测的世界模型理解动力学,但无法可靠地规划长周期目标;基于推理的视觉语言模型可以进行语义规划,但缺乏对物理结果的基础预测。IPR 通过使用世界模型推演作为物理先验和视觉语言模型推理来选择并追求可行的未来,将它们结合起来,并以 8B 参数的骨干模型超越了 GPT-5。
4.4 向未见游戏的零样本迁移
为了验证 Game-to-Unseen 设定,
- 本文构建了一个包含 50 个从未用于训练的游戏的留出目标集。
- 从剩余的池中,形成大小 N 递增的分层训练子集 S_N,并通过物理和因果机制进行平衡以控制领域偏差。
- 在每个子集 S_N 上端到端训练 IPR 范式,并直接在留出目标集上进行零样本评估,无需任何适应或奖励重新缩放。
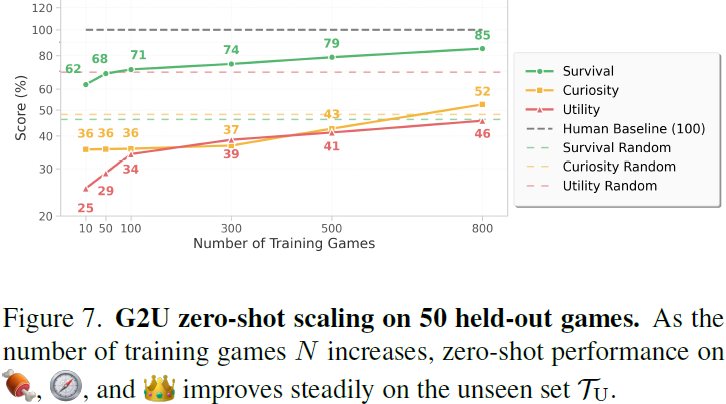
在所有三个目标上,
- 性能随着 N 增大稳步提高,在好奇层级早期增益最陡峭,随后在生存和效用层级上持续改善,因为观察到更多样化的交互。
- 这表明在 物理和因果相关 的环境中进行训练有助于 IPR 超越领域特定的怪癖(视觉风格、控制接口),专注于 共享的物理和因果模式。
- 换句话说,随着交互经验的积累,IPR 表现得更加 类人:它传递物理先验和因果预期,而非记忆领域外观或控制,展示了在更丰富交互领域中进一步扩展的潜力。
4.5 消融和分析
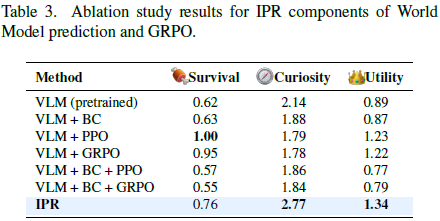
预测是否有助于 VLM 推理? 表 3 比较了同一 Qwen3-VL-8B 骨干上的变体。
- 从预训练的 VLM 开始,简单的行为克隆几乎不改变生存分数,但损害了好奇和效用,表明低质量的演示可能会覆盖有用的先验,而非改善控制。
- 在 VLM 基础上使用 PPO 实现了最佳生存和更高的效用,但进一步抑制了好奇心,将 PPO 与行为克隆结合会降低所有三个指标,表明仅强化学习在偏置数据下倾向于过度拟合短期奖励。
- 相比之下,IPR 通过世界模型预测和 GRPO 更新增强了 VLM,在保持强生存和效用的同时获得了最高的好奇分数,表明基于预测的强化是增强长周期物理推理的关键,而非简单地追求更高的即时分数。
5. 讨论
本文研究了一种交互式物理推理器范式,其中通用 VLM 用语言进行推理,通过以物理为中心的潜在接口行动,并由世界模型的想象奖励强化,探讨此类智能体能否从异构游戏中内化物理和因果规律,并随着经验增长显示出清晰的扩展性。
从这个角度看,潜在动作世界模型学习离散动作抽象和用于可控推演的潜在动力学;基于想象的控制方法在习得的世界模型内优化基于设备级动作的策略;基于大规模 VLM 的游戏智能体用海量人类演示和辅助多模态任务扩展视觉-语言-动作模型。
然而,从以物理为中心的视角看,这些方法并未明确地按数百个游戏间的共享物理机制组织动作,也未将 VLM 的推理能力与公共潜在空间中的预测能力对齐。
IPR 结合了它们的优势,研究在统一的生存-好奇-效用评估下,物理知识和迁移是如何出现的,尽管它仍然局限于游戏环境和短视距想象,将现实世界迁移和更长视距的推理留给未来工作。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献59条内容
已为社区贡献59条内容

所有评论(0)