(2025|Nvidia & 斯坦福,VLA,游戏视频-动作数据集,流匹配)NitroGen:面向通用游戏智能体的开放式基础模型
NitroGen 是一种扩展视频游戏智能体基础预训练的方法,利用公开数据源构建了网络规模的视频-动作数据集,并通过成功训练多游戏策略实证了其有效性。NitroGen 在微调实验中显示出积极的泛化迹象。
NitroGen: An Open Foundation Model forGeneralist Gaming Agents

论文地址:https://nitrogen.minedojo.org/assets/documents/nitrogen.pdf
项目页面:https://nitrogen.minedojo.org/
进 Q 学术交流群:922230617 或加 CV_EDPJ 进 W 交流群
目录
1. 引言
构建能在未知环境中运行的 通用具身智能体 长期以来被视为 AI 研究的 “圣杯”。尽管计算机视觉和大型语言模型通过互联网数据的大规模预训练实现了这种泛化,但具身 AI 的类似进展因 缺乏大规模、多样且带标签的动作数据集 而受阻。
电子游戏因其提供视觉丰富的交互环境以及涵盖广泛复杂度和时间跨度的任务,成为推进具身 AI 的理想领域。然而,先前方法存在显著局限。
- 基于 LLM 的方法 利用(1)手工设计的程序化 API 暴露内部游戏状态以控制智能体,或(2)复杂的感知模块进行文本信息提取和物体检测。它们支持复杂任务求解,但需要复杂的领域特定设计和调优。
- 强化学习 在《星际争霸II》、《Dota 2》等单个游戏中达到超人类水平,但这些智能体功能狭窄、训练成本高昂,且依赖很少能用于任意游戏的专用模拟器。
- 基于像素观察的行为克隆(Behavior-cloning)依赖昂贵收集的演示数据,由于数据收集成本过高,训练仅限于少数游戏。迄今为止,在开发能支持通用游戏智能体训练和评估的开源框架方面进展甚微。
为解决这些局限,本文推出 NitroGen,一个基于涵盖 1000 多款游戏的 4 万小时公开网络视频训练的开放基础模型。三大主要贡献如下:
- 网络规模的动作标注视频数据集。本文提出利用内容创作者实时叠加输入指令的公开视频作为新数据源。通过训练一个标注模型,来高精度提取帧级动作,避免了昂贵的手动数据收集,并捕获了广泛的真实玩家行为。
- 多任务多游戏评估套件。为评估实际场景下的泛化能力,本文设计了涵盖 10 款商业游戏中 30 个不同复杂度任务的基准环境,覆盖战斗、导航、决策、平台跳跃、探索和解谜等挑战。
- 大规模行为克隆预训练。本文展示了网络规模预训练的可行性和优势,在收集的数据集上训练了一个 视觉-动作 Transformer 模型。
在基准测试中展示了强劲结果,验证了端到端流程,并证明仅使用嘈杂的网络数据也能训练出强大的多游戏策略。与从零训练的模型相比,基于预训练 NitroGen 权重微调的模型在固定数据和计算预算下,任务成功率最高实现 52% 的相对提升。
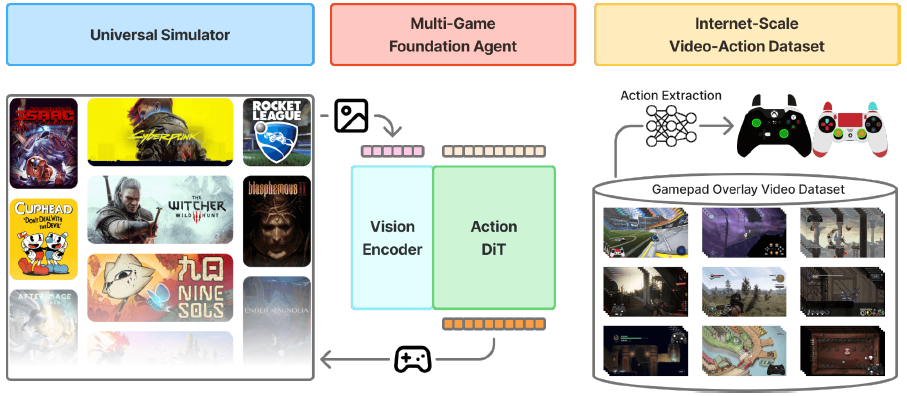
图 1:NitroGen 框架概览。NitroGen 包含三个核心组件:
- 多游戏基础智能体(图中)——一个通用型视觉-动作模型,接收游戏画面观测并生成手柄操控动作,支持在多款游戏中实现零样本游玩,并可作为基础模型用于新游戏的微调;
- 通用模拟器(图左)——一个环境封装层,允许通过 Gymnasium API 控制任何商业游戏;
- 互联网规模数据集(图右)——从 4 万小时公开游戏视频中构建的最大规模、最多样化开源游戏数据集,涵盖超 1000 款游戏并已提取动作标注。
2. 方法
2.1 网络规模多游戏视频-动作数据集

标注挑战:
- 从网络视频训练策略的核心挑战是恢复对应的玩家动作,因为大多数游戏录像通常不包含玩家输入。
- 可通过利用一种可恢复此类标签的新型公开视频源来解决此问题。
- 这些视频包含 输入叠加(input overlay)软件,该软件以 2D 游戏手柄图像的形式实时可视化玩家动作(通常位于屏幕一角,高亮按下的按钮)。
数据集构建:
- 收集了 7.1 万小时包含手柄叠加层的原始视频。
- 为避免单一游戏占比过高,本文结合了基于关键词的搜索和内容多样性引导的筛选,确保覆盖不同游戏、类型和技能水平。
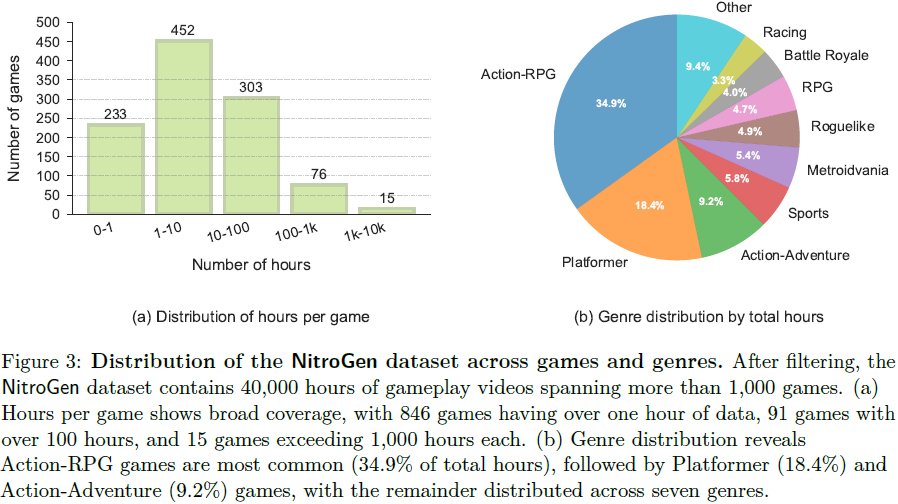
- 最终数据集包含 4 万小时游戏视频,涵盖 1000 多款独立游戏,是迄今为止规模最大的游戏视频-动作标注数据集。
动作提取:通过三阶段流程从游戏视频中提取玩家输入:
-
模板匹配:使用约 300 个常见手柄模板,通过 SIFT 和 XFeat 特征匹配定位并裁剪手柄叠加区域。
-
手柄动作解析:使用微调的 SegFormer 分割模型处理连续帧对,输出离散网格上的摇杆位置分割掩码和二进制按钮状态。模型使用合成数据训练,模拟真实视觉伪影。
-
质量过滤:为避免模型过度预测 “无动作”,可基于动作密度进行筛选,只保留至少 50% 时间步包含非零按钮或摇杆动作的数据段,最终保留 55% 的数据。训练时遮挡画面中的手柄显示,防止捷径学习
2.2 评估套件
通用模拟器:本文开发了一个通用模拟器,可为任何商业游戏包装 Gymnasium API,实现程序化控制。该库通过拦截游戏引擎的系统时钟来控制模拟时间,支持逐帧交互而无需修改游戏代码。
统一的观察与动作空间:观察空间为单帧 RGB 图像。动作空间为标准化的 16 维二进制向量(对应手柄按钮)加上 4 维连续向量(对应摇杆位置)。这种统一布局便于策略在不同游戏间直接迁移。
多样化评估任务:评估套件涵盖 10 款不同视觉风格和类型的游戏,共 30 个任务,分为战斗、导航和游戏特定任务三类。任务具有明确定义的起始和目标状态,通常持续几分钟。
2.3 NitroGen 基础模型
架构:
- NitroGen 采用 流匹配(flow matching)技术,以单帧 RGB 图像为条件,直接生成一段未来动作序列。
- 架构基于 GR00T N1 进行适配,移除了语言和状态编码器,使用单个动作头。
- RGB 输入通过 SigLIP 2 视觉 Transformer 编码,动作由 扩散 Transformer 生成,单次前向传播输出多个动作。
设计选择:研究发现使用多于一个过去帧作为上下文并无益处,因此使用单帧上下文并生成 16 个动作的块,这相比单动作生成提高了时间一致性。
训练与推理:采用标准的条件流匹配目标函数,推理时通过固定步数(16 步)的去噪过程生成动作序列。
3. 实验
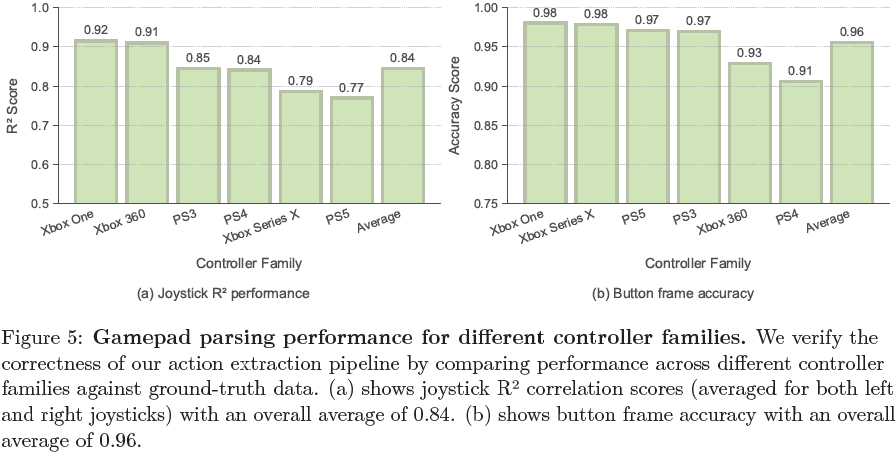
手柄动作提取模型的性能:在涵盖不同手柄家族的基准测试中,本文的动作提取流程平均摇杆位置精度 R² 为 0.84,平均每帧按钮准确率为 0.96。
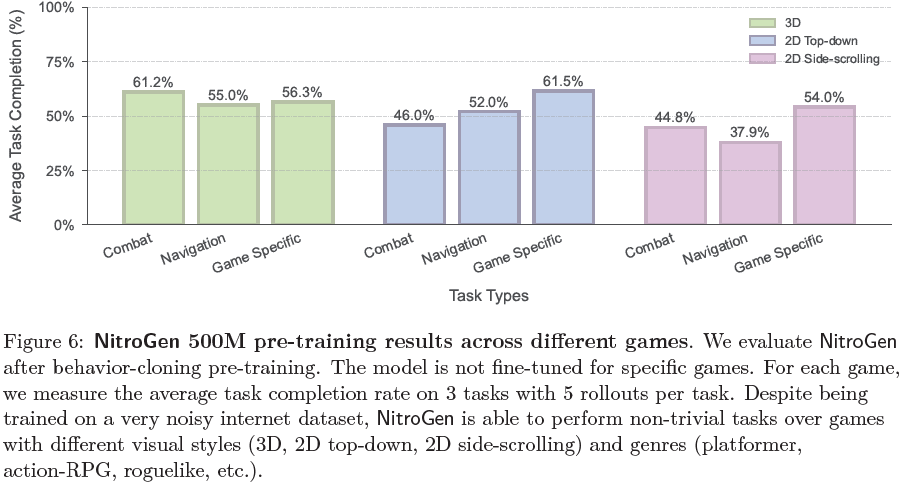
NitroGen在广泛游戏中的强大能力:在未微调的情况下,NitroGen 在许多游戏和任务上取得了显著的成功率。模型在可记忆的任务和需要零样本泛化的任务上均表现良好,表明其既能利用记忆,也能适应未见场景。
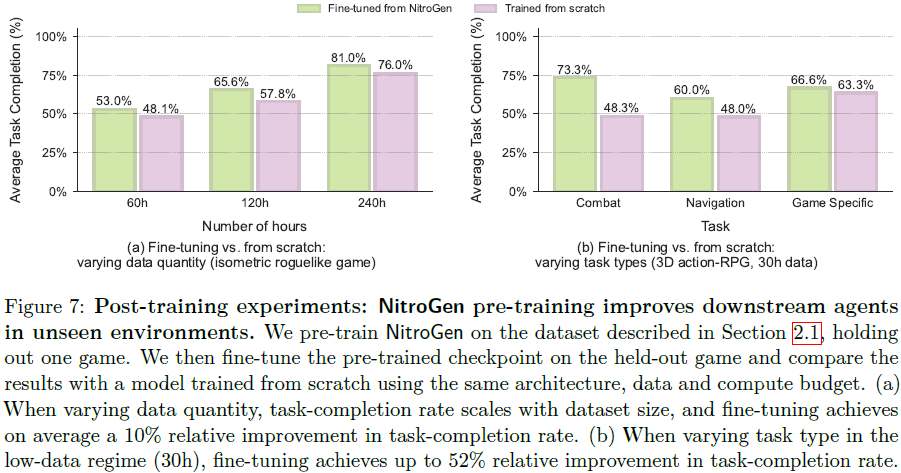
预训练提升下游任务微调效果:在未见游戏上进行有限数据微调时,基于预训练 NitroGen 微调的模型相比从零训练的模型平均有 10% 到 25% 的相对提升。其中,通用任务(如战斗和导航)受益更显著,而游戏特定任务提升较小。
4. 局限性与未来工作
设计局限:NitroGen 目前是一个快速反应的 System-1 感知模型(sensory model),无法进行长期规划或遵循语言指令。未来可通过语言跟随和强化学习进行后训练以增强规划能力。
数据集偏差:数据集偏向动作游戏和通常使用手柄玩的游戏,对仅用键盘的游戏或涉及复杂操作的游戏覆盖不足,这可能限制模型在策略或模拟类游戏上的泛化能力。
5. 相关工作
游戏智能体:相关工作主要分为三类:强化学习、基于LLM的高层推理以及直接从像素或状态进行行为克隆。NitroGen 通过将行为克隆扩展到网络规模,推动了第三类方向的发展。
具身基础模型:现有方法通常采用分层推理或端到端学习。NitroGen 的不同之处在于摒弃了语言条件,专注于利用多样游戏数据学习可扩展的视觉-动作映射。
【Game Video-Actiong is all you need for VLA training! 哈哈 】
大规模动作数据集:与其他需要昂贵收集或缺乏多样性的数据集相比,NitroGen 通过利用输入叠加软件,提供了一种可扩展的替代方案。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 28
28 0
0- 0



 已为社区贡献59条内容
已为社区贡献59条内容

所有评论(0)