Trae vs Cursor:实测复盘
上周带团队复盘一个高并发重构项目,带队的几个老猿还在那抠Python迭代器的内存分配,我直接把手里的咖啡放下了。都2025年底了,哥几个还在冷兵器时代肉搏呢?YC创始人那句语法已死不是在画饼,是真把饭碗砸了。现在的玩法是Vibe Coding,别被这洋词儿唬住,它本质上就是剥离体力活。你得像个主理人一样盯着业务逻辑的生死线,至于那些要把人眼睛看瞎的闭包和递归,丢给AI去填。以前我们是代码的搬运工,
上周带团队复盘一个高并发重构项目,带队的几个老猿还在那抠Python迭代器的内存分配,我直接把手里的咖啡放下了。
都2025年底了,哥几个还在冷兵器时代肉搏呢?
YC创始人那句语法已死不是在画饼,是真把饭碗砸了。现在的玩法是Vibe Coding,别被这洋词儿唬住,它本质上就是剥离体力活。你得像个主理人一样盯着业务逻辑的生死线,至于那些要把人眼睛看瞎的闭包和递归,丢给AI去填。以前我们是代码的搬运工,现在我们是逻辑的监工。
如果你还在纠结Go和Rust的并发模型哪个优雅,那你离被降维打击就不远了。

字节Trae vs 硅谷Cursor:谁在薅开发者的羊毛
这半年我把市面上能叫出名字的AI IDE都试了个遍。
Cursor之前确实是屠龙宝刀,但最近字节推出的Trae真的有点意思。它懂中文语境下那些含糊其辞的业务逻辑,最关键的是它集成了DeepSeek-R1。
我做过一个对比测试:把一份三十多页、充满了各种槽点的“企业高并发架构规范”塞给它们,然它们根据规范写一个秒杀接口。
Cursor还在那里纠结于语法风格的对齐,而Trae直接利用MCP(模型上下文协议)打穿了我的私有文档库。它不仅写出了代码,还顺手帮我把Redis分布式锁的超时时间,按照我文档里那个只有内部人知道的黄金比例给设好了。
这种心领神会的感觉,这种深度耦合私有知识库的能力,标志着AI从代码助手正式进化为架构学徒。
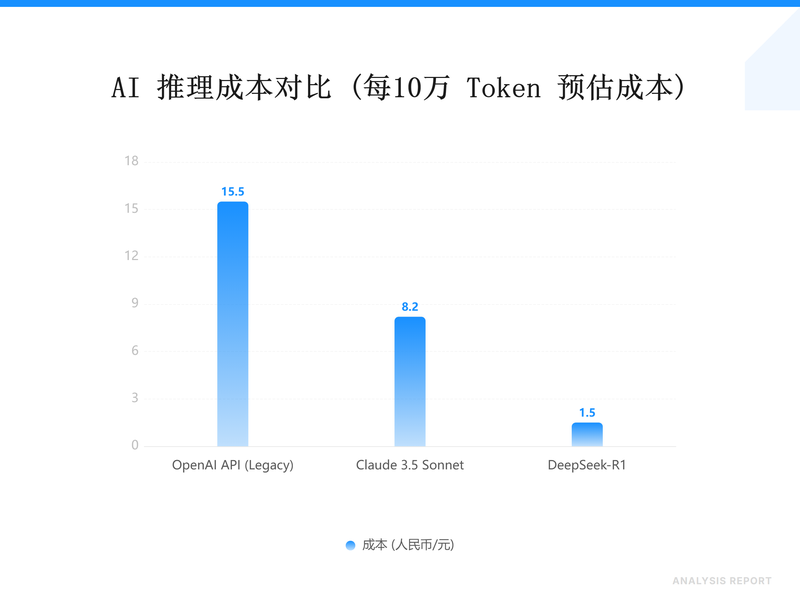
DeepSeek-R1在处理这种长上下文时的成本控制也很有趣。同样处理一个10万Token的工程上下文,用OpenAI的API可能够我吃两顿日料,但换成DeepSeek方案,也就一瓶矿泉水的钱。这种“Token经济学”的本质是:当推理成本降低到忽略不计时,‘思维链(CoT)’的反复迭代才真正具备了大规模工程化的可能。
现在的痛点不再是模型不够强,而是API Key的管理成本太高。如果你厌倦了在不同厂商的后台反复横跳,找一个能集成Claude-4.5和Gemini 2.0的全家桶中转站是刚需,把省下的环境搭建时间拿去打磨业务逻辑更有价值。
降维打击下的代偿代价:别被那94%的覆盖率骗了
很多人跟我吹嘘,说用了AI之后,由于单元测试都是自动生成的,覆盖率咔嚓一下到了94%。
我点开一看,全是这类逻辑:if (a == 1) return true;。这种测试跑一百遍也没意义。
AI最容易把球传丢的地方,就是那最后30%的长尾逻辑。它生成的代码经常有一种逻辑幻觉:乍一看逻辑缜密,实测时遇到RAG架构下的私有库关联就抓瞎。
这就跟在居酒屋喝酒一样,AI是那个手脚利索的倒酒小弟,但这瓶酒是辛口还是甘口,该配什么下酒菜,最后拍板的还得是你这个老饕。
与其说是审查,不如说是防坑。第一步,先把你的宏大叙事切碎,AI吞不下庞然大物,一次只让它磨一个零件。第二步,当个“悲观主义者”,它默认网络永远通畅、库永远在线,你得往它嘴里塞点断网和死锁的剧本。最后,守住底线:超过50行你一眼看不透的代码,统统视为定时炸弹,哪怕它跑得再欢也得砍掉。
避坑清单: 重点检查AI生成的异常捕获块,它最爱写 catch (Exception e) {} 这种吞掉报错的垃圾代码;另外,强制要求AI在生成复杂逻辑前,先输出一段 Mermaid 流程图让你确认意图。
重构2048:30分钟的效率幻觉
那天我试着在Trae里用30分钟重构了一个2048小游戏。从空白文件夹到丝滑运行,我敲的键盘字符加起来还没这篇文章的一半多。
但这种效率是有代价的。代码膨胀(Code Bloat)正在成为新的开发灾难。AI会为了实现一个简单的功能,给你堆砌大量看似专业实则冗余的抽象层。如果你不具备手术刀式的精简能力,很快你的项目就会变成一个谁也看不懂、谁也不敢动的怪物。
所谓的高效率,不是看你生成了多少代码,而是看你删掉了多少废话。
2026年就要到了,程序员这个职业不会消失,但“只会写代码的程序员”已经死在了2024年的那个冬天。现在的游戏规则是:用Trae这种IDE搞定重构,而你,得守住那个名为逻辑常识的最后阵地。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)