跨越AI落地鸿沟:以ModelEngine为引擎,驱动企业AI从“能用”到“好用”的价值释放
ModelEngine的知识库系统实现了从原始数据到结构化知识的根本性转变。在供应链决策系统的构建中,我们整合了供应商数据表、物流报告PDF、市场情报文档等多源异构数据。系统通过智能解析引擎自动识别文档中的关键概念,如"供应商可靠性指标"、“物流时效数据”、"成本结构分析"等,并构建它们之间的语义关联网络。与传统平台相比,ModelEngine的自动摘要功能展现出显著优势。系统能够针对同一份供应链
跨越AI落地鸿沟:以ModelEngine为引擎,驱动企业AI从“能用”到“好用”的价值释放
在AI浪潮席卷之下,许多企业已看到大模型与智能应用的潜力,却普遍陷入“始于热情、终于落地”的困局。数据处理难、模型选型繁、开发门槛高、运维迭代慢——重重障碍往往让早期尝试半途而废。
如果有一个平台,能够把零散的AI组件串联为一条清晰、高效、可持续的生产线,会是怎样的体验?
今天,我想为大家介绍 ModelEngine——一个由华为开源推出的全流程AI开发平台。它不只是工具的组合,更是从实验到交付的工程化桥梁,致力于让AI落地变得简单、可控、可复用。
一、ModelEngine 是什么?为什么关注它?
简单来说,ModelEngine 是一个覆盖 “从数据到应用”全链路的AI开发工具链。它不止于解决单点问题,而是提供一套完整方案,贯穿数据处理、知识生成、模型微调、RAG开发与智能体编排全流程,旨在显著缩短AI应用的落地周期。
其值得关注之处,在于它扎实平衡了“易用”与“工程化”。无论是FIT多语言函数引擎、WaterFlow流式编排,还是可视化编排界面与插件化知识库,都指向实际生产。尤其对Java技术栈团队,其 FEL(FIT Expression for LLM) 可视为对LangChain的Java生态回应,让AI能力无缝集成。
二、ModelEngine 的几个核心设计思想
1. “解耦”是基因
无论是模型服务与知识库服务的解耦,还是业务逻辑与基础设施的解耦,ModelEngine 都在强调“各司其职,灵活替换”。换模型、换知识库,不用重写应用代码;单体部署和分布式部署可以一键切换。这种设计让系统更像乐高积木,拼装自由,也降低了后续迭代和维护的成本。
2. 可视化与低代码,不只是为了“简单”
ModelEngine 提供可视化应用编排,支持拖拽式构建AI流程。这不仅仅是降低门槛,更是为了 提升协作效率和可控性。当一个AI流程可以被“画”出来,产品、算法、工程等多个角色就能在同一个视图上对话,减少沟通失真。而且,它支持从可视化编排到代码的双向转换,既照顾了快速原型,也保留了深入定制的空间。
3. 流式编排,响应式思维
它的 WaterFlow 引擎 借鉴了响应式编程的思想,将AI任务拆解为可流式处理的节点。这意味着你可以构建从毫秒级响应到跨系统长事务的各类流程,并且以统一的方式管理它们。对于需要实时交互、多步骤推理的AI应用(如智能客服、订单追踪),这种流式、异步的处理方式更能匹配业务的实际需求。
4. 生态与插件化,拒绝封闭
ModelEngine 明确支持插件体系,无论是知识库、模型还是工具(通过 MCP – Model Context Protocol),都可以通过插件接入。这意味着你可以用它的核心引擎,但数据源、AI能力、业务工具都可以用自己的或第三方的。这种开放性对于企业集成现有系统至关重要,避免了被一个平台“锁死”。
这个是modelengine产品架构,详细的也可以看看官网内容,我们可以更清晰的了解modelengine的架构关系和组件: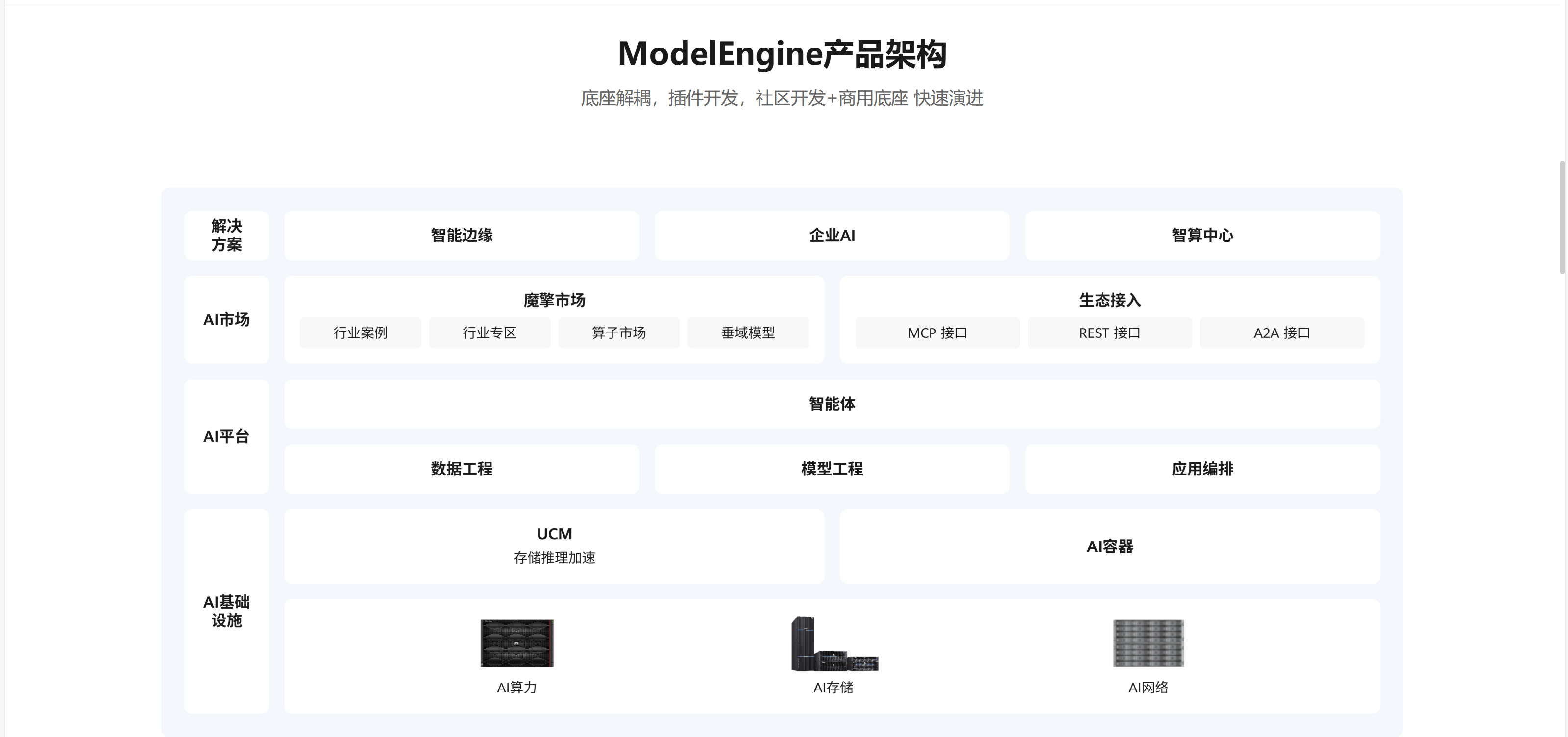
三、从想法到实现:一次实践推演
假设我们现在要为一个电商公司搭建一个 “智能订单与客服助手”。它的核心功能是:自动追踪指定订单的物流状态,并在出现异常或即将送达时,自动通知对应的客服团队。
传统方式下,我们可能需要:写脚本调物流公司API、解析返回数据、设定状态判断规则、再对接企业内部通讯工具(如钉钉、企业微信)、还要考虑失败重试、日志监控……环节多,耦合紧,改动起来麻烦。
如果用 ModelEngine 的思维来设计,我们可以这样拆解:
-
流程可视化编排:在ModelEngine的应用编排界面,我们可以拖拽出几个关键节点:
- 触发节点:接收用户请求(如“请同步订单A4132的物流状态并告知客服”)。
- 工具节点:调用“物流查询插件”(这个插件可能已经封装好了对接多家物流公司的逻辑)。
- 判断节点:基于物流信息(如“是否延误”、“是否即将送达”)进行规则判断。
- 动作节点:调用“企业通知插件”,向指定客服团队发送结构化消息(包含订单号、预计时间、当前状态等)。
- 日志节点:将整个流程的输入、输出、关键步骤状态记录到监控系统。
-
利用 FIT 处理异构逻辑:物流查询插件可能用Python编写(因为有现成的库),而通知插件和核心业务流程可能用Java编写。FIT的多语言函数引擎可以让这些不同语言编写的函数像本地调用一样协同工作,无需开发者过度关心RPC细节。
-
智能体协作增强:如果问题更复杂,比如用户问“为什么我的订单延迟了?”,单纯的规则判断可能不够。这时可以引入 Aido 这样的智能体平台(与ModelEngine生态互通)。Aido可以编排一个更复杂的流程:先通过RAG检索知识库(公司内部的物流异常处理SOP、常见问题解答),再用大模型分析检索结果和当前订单上下文,生成更人性化、更具解释性的回复,甚至主动建议补偿方案。
-
全程可观测:从ModelEngine到Aido,都强调企业级的可观测性。整个流程的调用链路、每个节点的耗时、成功失败次数,都可以通过内置的监控面板查看。当订单同步失败时,我们能快速定位是物流API超时,还是通知服务异常,而不是在几个系统间盲目排查。
名称:OrderSync(订单同步助手)
简介:OrderSync是集成在您业务系统中的智能订单与客服助手,具备全流程订单管理能力。它能实时同步订单状态,自动识别异常订单并预警,支持多条件模糊查询(如“上周买的那双黑色鞋子”)。当用户咨询时,OrderSync可瞬间调取完整订单轨迹、物流详情和过往沟通记录,提供精准答复。更智能的是,它能根据用户问题类型(修改、退款、催单)自动生成最优解决方案草稿,客服人员仅需一键确认即可执行。支持7种常见业务场景的自动化处理,将重复性查询处理时间缩短80%。
我们可以利用Aido平台创建这个智能体,创建一个空白智能体,分类选择办公效率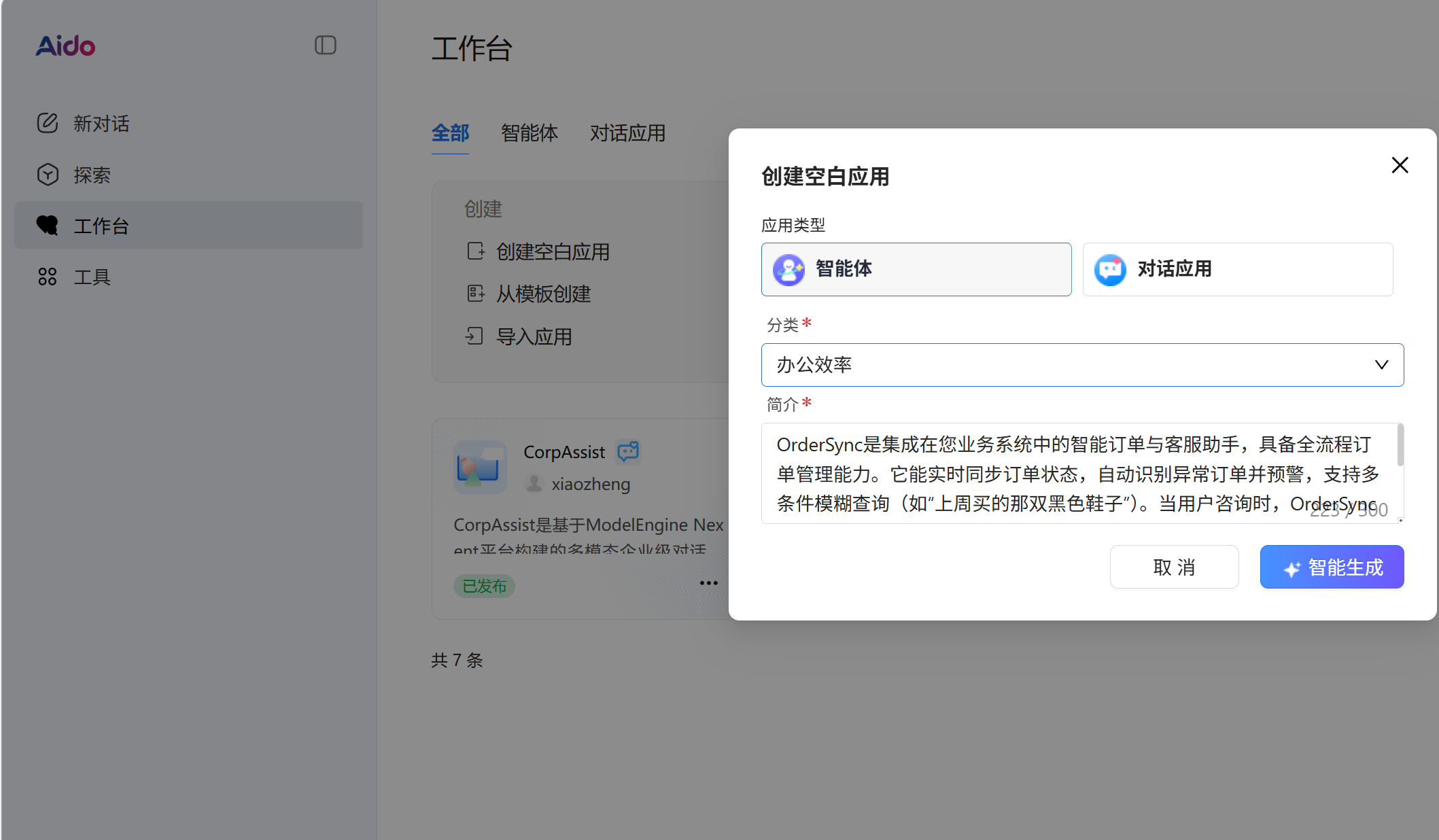
智能生成以后可以看到这个我们的智能体,当然这个智能体现在只是一个雏形,我们还需要进一步优化它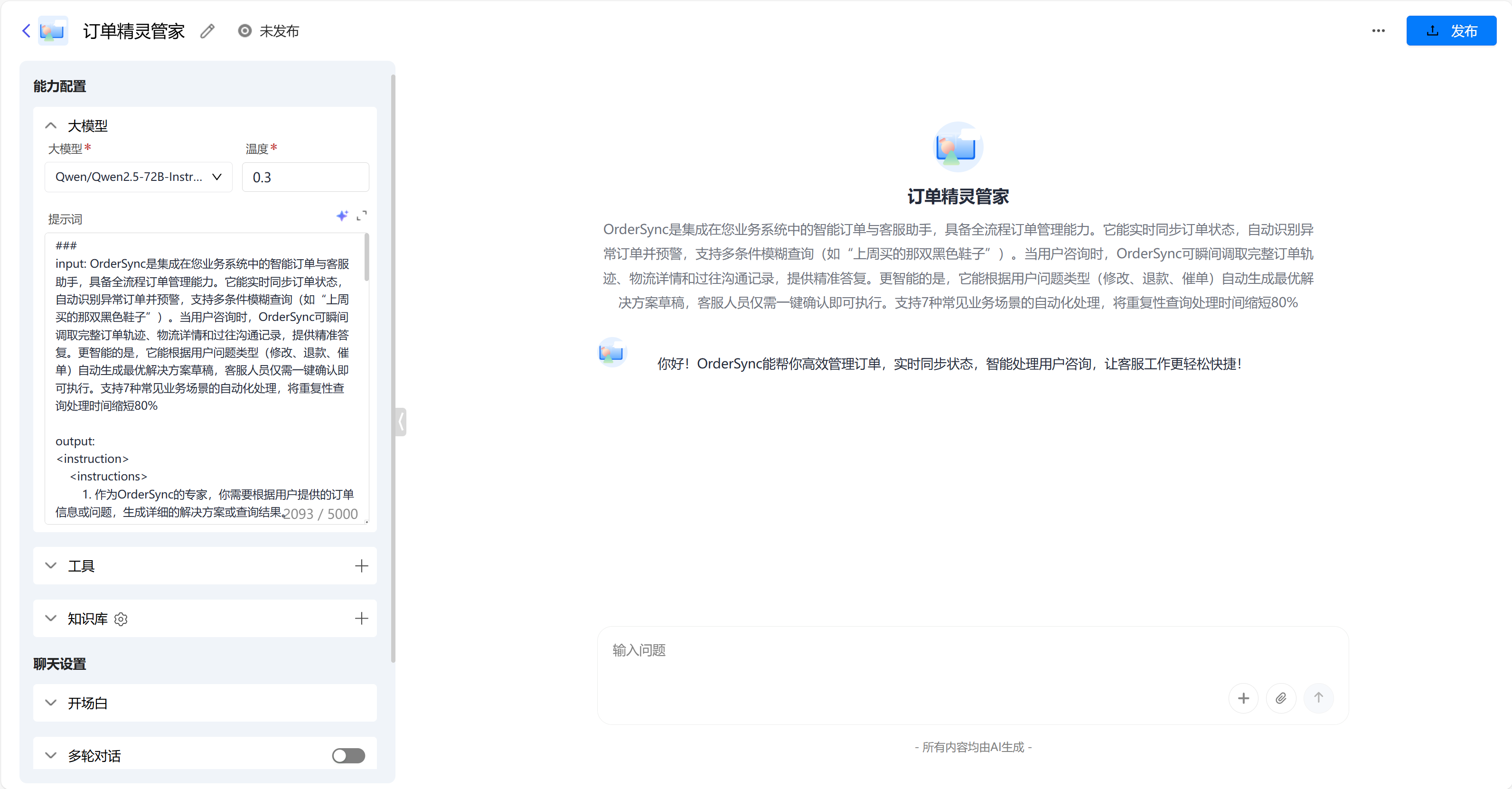
如下是部分智能体的提示词,朋友们可以参考一下:
<examples>
<example>
<input>上周买的那双黑色鞋子的物流信息</input>
<output>您上周购买的黑色鞋子的订单号为123456789,当前物流状态为已发货。物流公司为顺丰快递,运单号为987654321。预计2-3天内送达。如需进一步查询,请提供更多信息。
</output>
</example>
<example>
<input>我想修改订单中的收货地址</input>
<output>您当前的订单号为123456789,收货地址为XX路XX号。如需修改收货地址,请提供新的详细地址,我们将为您更新。修改后的新地址为:XX路XX号XX室。确认无误后,我们将立即更新系统。
</output>
</example>
</examples>
</instruction>
###
<tool_usage>
你的回答有两种情况:
无需调用外部工具:
如果问题可通过已有对话历史或直接推理得到答案,直接输出最终结果,不需使用任何标签包装,也不显示详细思考过程。
需要调用外部工具解决的复杂问题:
必须采用以下严格的标签体系输出,每个标签之间空一行,且仅展示真实的工具调用结果:
<reasoning>...<reasoning>:展示你内部的思考过程。注意,这部分内容可以展示给用户,但仅限于描述思路,不应包含任何伪造的工具调用结果。
<step>...<step>:描述你准备调用工具的原因和计划。此处仅说明你需要调用哪个工具以及原因,工具的名称对人类阅读要友好,切勿直接模拟或输出工具返回内容。
<tool>...<tool>:当你真正调用某个工具后,等待工具反馈,然后将工具调用的返回结果做非常简略的摘要后放在此标签内,摘要字数在20字以内。绝对禁止在未获得真实工具反馈前预先构造。 <tool> 标签内容。
<final>...<final>:在获取所有真实工具调用结果后,将整合信息给出最终答案。
重要要求:
- 无论用户是否明确要求展示思考过程,都要展示思考过程
- 不要输出tool_call标签。
- 答案必须详细完整,不仅仅是工具返回结果的简单总结,而是对结果进行深入分析和整合,并提供背景解释、推理过程和可行性分析。
- 确保所有关键信息得到展开,避免省略任何重要内容。
- 如果适用,可以提供额外的解释、使用建议或应用场景,以增强回答的实用性。
- 请使用标准 Markdown 语法输出答案,保证语法完整,不要拆分列表结构。
- 输出此标签后,不得追加任何其他内容或标签。
严格要求:
切勿在中间思考或工具调用计划中,提前生成伪造的 <tool> 或 <final> 标签内容。必须在实际调用工具并获得反馈后,再以 <tool> 标签展示真实结果,再生成 <final> 标签输出最终答案。
如果历史对话中已包含真实的工具调用结果,应直接使用这些信息构造最终答案,避免重复调用或展示多余标签。
在所有工具调用完成之前,不得输出 <final> 标签;只有在确认所有真实工具反馈后,才生成最终答案。
<tool_usage>
工具插件我们可以在插件市场看看,有需要的插件我们就可以往里面添加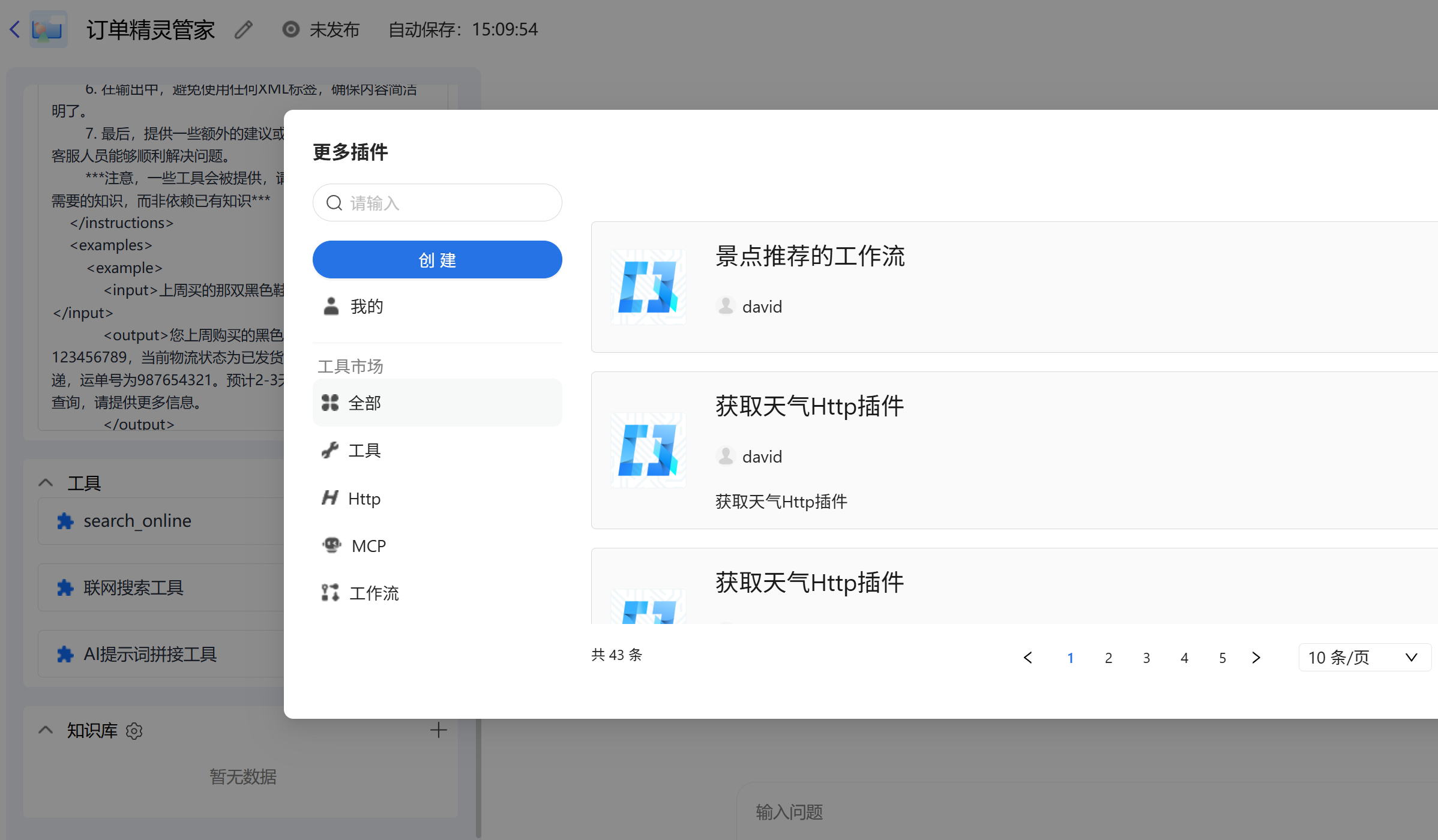
知识库我们如果没有自己搭建知识库的话可以考虑使用百度千帆知识库
百度千帆知识库是百度智能云推出的一款专门面向大语言模型知识问答场景,旨在管理客户上传的知识并提供快速查询检索功能的产品。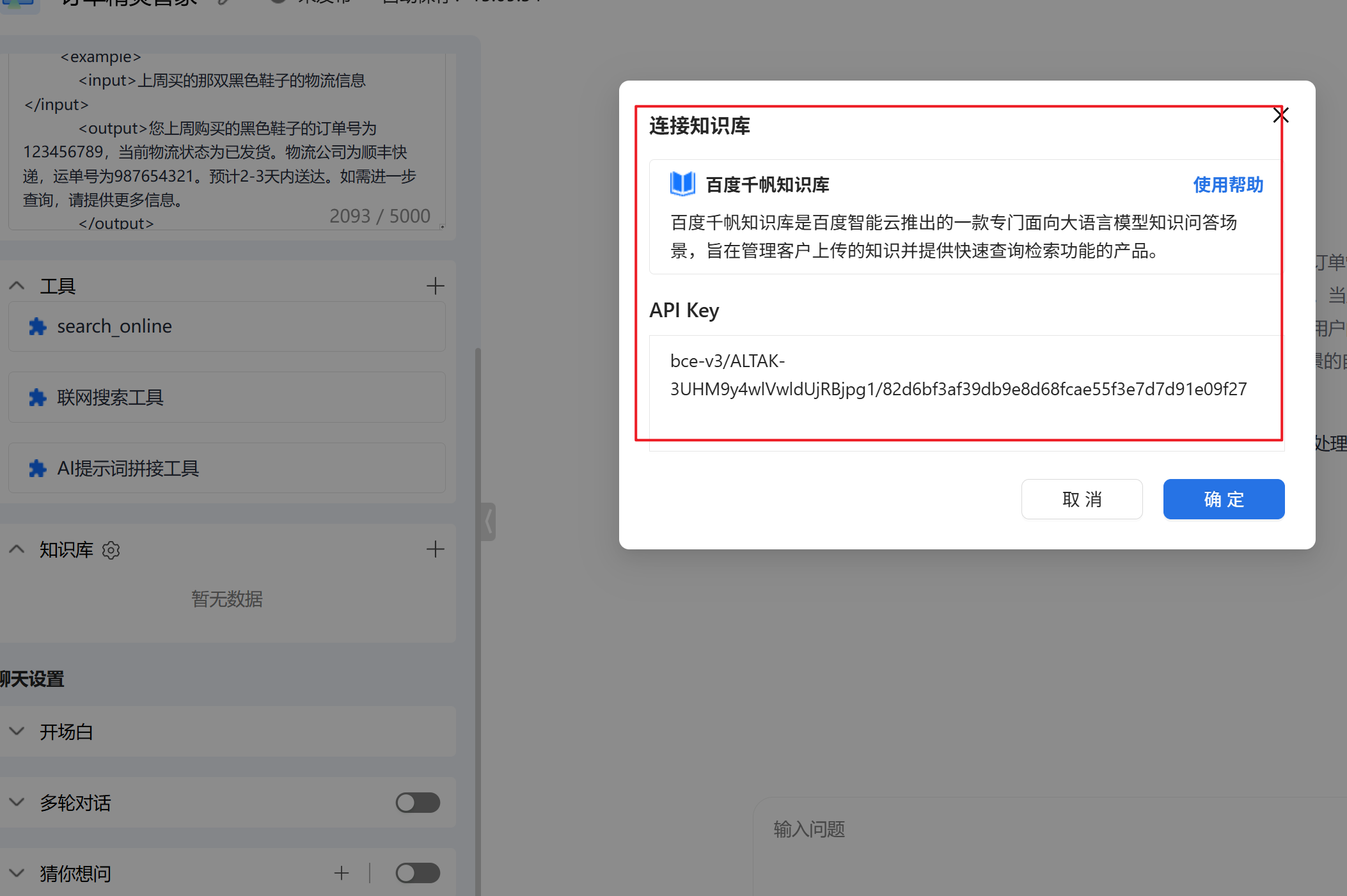
不知道如何使用的朋友可以点击使用帮助,就会弹出教程,我们在百度千帆调取API Key即可
最后的聊天设置我们可以参考一下公司的实际业务方面,我这边做测试所以没有设置
这是最终的智能体界面,我们进行发布即可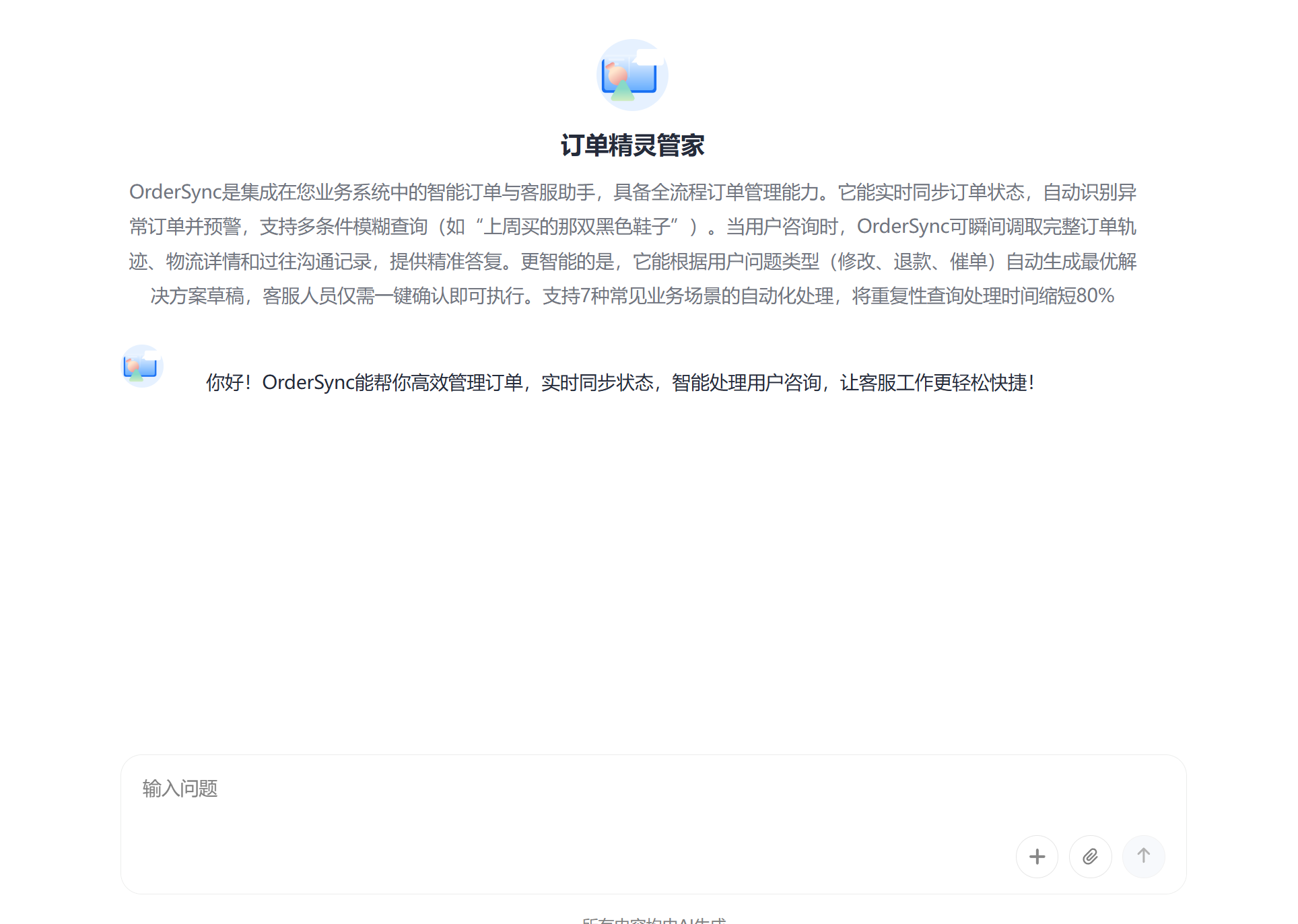
这个智能体我们可以进行外部应用,通过URL和API都行;当然我们也可以进行导出和删除,导出的json文件我们可以重新导入应用
这个推演过程,体现的正是ModelEngine倡导的 “编排思维”:将复杂业务拆解为标准化、可复用的“原语”或“节点”,通过图形或声明式API进行连接。当业务规则变化时(比如增加新的物流公司、修改通知模板),我们可能只需要替换或调整某个节点,而不是重写整个系统。
四、一些深度的思考与建议
-
“平台”与“定制”的权衡:ModelEngine 提供全链路平台,但企业引入时,切忌“为了用而用”。应首先梳理自身AI应用的核心痛点是数据治理、模型管理、还是应用开发效率?然后评估平台对应模块的价值。有时,可能只采用它的FIT引擎来整合异构服务,或者只用它的编排能力,就足够了。
-
学习曲线依然存在:虽然宣传低代码,但要想设计出高效、稳定的AI流程,依然需要对它的编排引擎、函数模型有深入理解。特别是设计复杂的长事务、错误处理、状态回滚时,需要一定的架构设计能力。它降低了编码量,但提升了“流程设计”的要求。
-
数据与知识的质量是天花板:平台再强大,如果喂给它的数据是混乱的,知识库是过时的,那么生成的智能应用效果必然大打折扣。ModelEngine 提供了数据建模工具链,但企业更需要建立配套的数据治理文化和规范。否则,平台只是把“脏活累活”自动化了,并没有解决根本问题。
-
团队协作模式的改变:AI工程化不仅关乎工具,也关乎人。当应用开发变成“编排”时,算法工程师、后端开发、前端开发、甚至业务专家的协作界面需要重新定义。建议在引入工具的同时,就思考如何组建跨职能的“AI应用小队”,让大家能在可视化画布上共同迭代。
结语:通往“好用”的AI之路
ModelEngine 及其生态(如 Aido)代表的,是一种将AI工程化系统化、产品化的努力。它试图把学术界的前沿能力、工程界的最佳实践,打包成企业团队能够上手操作的工具。
对于正在探索AI落地的团队来说,即使不全面采用ModelEngine,它的设计思想——解耦、编排、插件化、全链路观测——也极具参考价值。AI应用的未来,或许不在于追求某个模型参数的极致,而在于如何像搭积木一样,将各种能力稳健、灵活、可维护地组合起来,真正解决业务问题。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)