昇腾MindSpeed RL的训推共卡和Resharding特性代码解析
昇腾MindSpeed RL的训推共卡和Resharding特性代码解析MindSpeed-RL仓库目前主推的部署方式为全共卡部署,即 Actor, Reference 等 worker 分时复用同一批机器资源,交替进行计算任务。 在全共卡配置中,为了节省显存,各个计算任务执行时只会将必要的数据加载到显存上,并在结束计算任务后,将加载的数据重新卸载到CPU侧的内存上。在大模型RL后训练过程中,模型
昇腾MindSpeed RL的训推共卡和Resharding特性代码解析
MindSpeed-RL仓库目前主推的部署方式为全共卡部署,即 Actor, Reference 等 worker 分时复用同一批机器资源,交替进行计算任务。 在全共卡配置中,为了节省显存,各个计算任务执行时只会将必要的数据加载到显存上,并在结束计算任务后,将加载的数据重新卸载到CPU侧的内存上。在大模型RL后训练过程中,模型训练全过程包含推理(生成)、前向计算、训练(前反向梯度更新)等多个阶段,且可能涉及待训模型(Actor)、参考模型(Reference)、评价模型或打分模型(Critic/Reward Model)。其中,待训模型(Actor)既要进行推理(生成),也需参与训练的前向计算及前反向梯度更新等过程,即训推并存,尤其在训练阶段模型权重采用megatron格式而推理阶段是vllm引擎以加速推理过程。因此,为支持各阶段最优并行策略的独立配置,达到尽量高的系统吞吐性能,同时避免多份模型权重对内存占用,MindSpeed-RL提出训推共卡的Resharding特性,实现模型在训练-推理不同阶段中采用不同并行策略时的权重在线重切分功能。下面对训推共卡和Resharding特性的代码实现做深入解读。
代码文件
mindspeed_rl/workers/resharding
|
resharding ├─__init__.py ├─megatron_off_loader.py # MegatronOffLoader相关实现 ├─megatron_sharding_manager.py # MegatronShardingManager相关实现 ├─memory_buffer.py # ModelWeightBuffer相关实现 ├─utils.py # 其他辅助工具 ├─vllm_weight_container.py # MegatronStyleVllmWeightContainer相关实现 ├─weight_adaptor.py # MegatronVLLMWeightAdaptor相关实现 |
mindspeed_rl/models/rollout/vllm_adapter
|
megatron_weight_loaders.py #用于定义训推转换时,vllm加载权重时的格式转换处理 |
核心模块
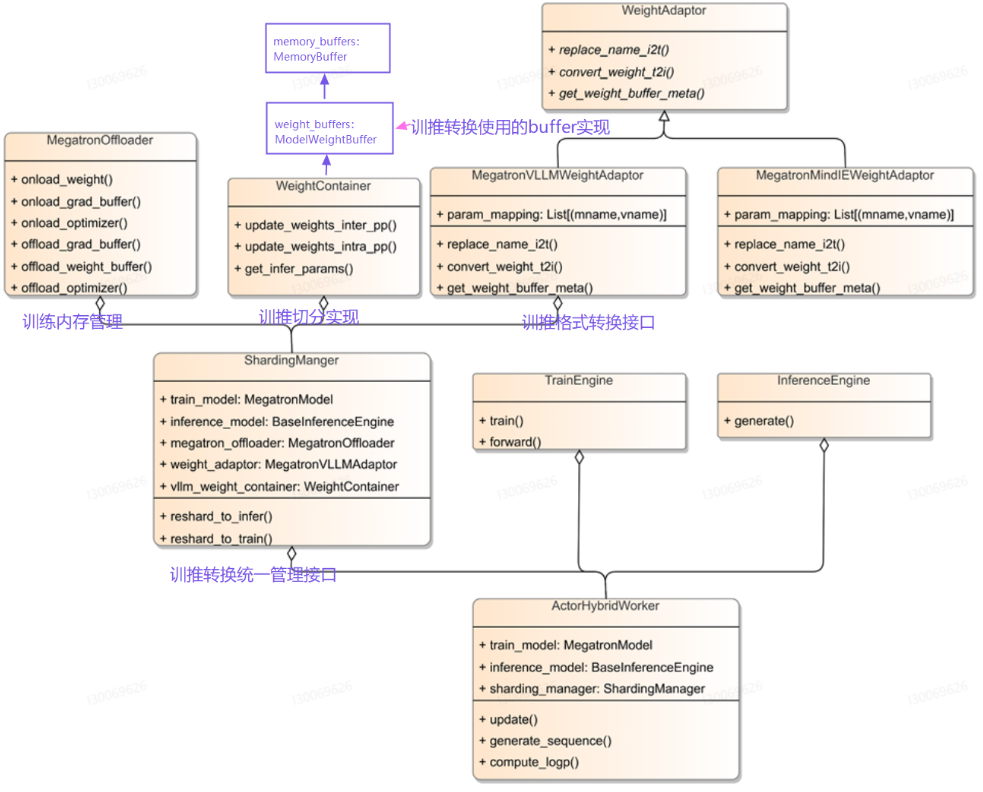
- MegatronShardingManager:
- 训练态、推理态转换的统一接口
- 完成训转推、推转训的在线权重重切分功能、内存调度等功能。
- 该模块与训推引擎解耦,支持Megatron、VLLM及其他训推引擎;
- MegatronOffLoader:
- 训练引擎内存管理模块
- 负责训练引擎中权重、优化器、梯度等内存管理调度。
- 可以通过实现不同Offloader支持不同训练引擎内存调度。
- MegatronStyleVllmWeightContainer:
- 完成训练和推理不同并行策略下权重的重切分、实现从训练态到推理态的重新切分;
- ModelWeightBuffer:
- MemoryBuffer统一管理,Buffer初始化、destroy、onload、offload等;
- 输入模型的state_dict,返回模型参数名称和对应memory_buffer的map
- MegatronVLLMWeightAdaptor:
- 实现训练引擎(Megatron)及推理引擎(vLLM)权重格式转换统一接口
- 通过实现不同WeightAdaptor可以支持不同模型及训推引擎。
|
class MegatronShardingManager: def __init__(.....): self.inference_engine = inference_engine self.optimizer = optimizer self.train_model = megatron_model weight_adaptor = get_weight_adaptor(self.inference_engine.\ model.__class__.__name__) #训推权重格式转换 self.weight_adaptor = weight_adaptor(model_config) #训推冲切分实现 self.vllm_weight_container = MegatronStyleVllmWeightContainer(......) self.optimizer_offload = optimizer_offload self.grad_offload = grad_offload self.train_param_offload = train_param_offload self.enable_validate = enable_validate self.inference_engine.offload_model_weights() #训练引擎内存管理模块 self.megatron_offloader = megatron_offloader |
重要接口
共卡机制主要调用接口
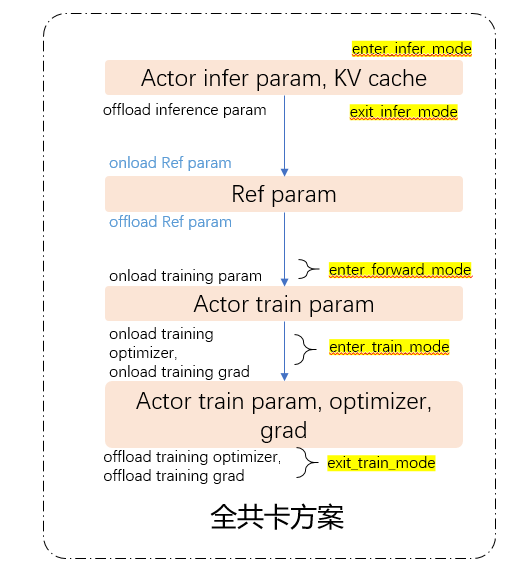
MegatronShardingManager
|
#mindspeed_rl/workers/resharding/megatron_sharding_manager.py class MegatronShardingManager:
def offload_infer_params(self): infer_weight_buffers = self.vllm_weight_container.weight_buffers for buffer in infer_weight_buffers: buffer.destroy()
def onload_infer_params(self): infer_weight_buffers = self.vllm_weight_container.weight_buffers for buffer in infer_weight_buffers: buffer.rebuild() def enter_infer_mode(self): ......
def exit_infer_mode(self): self.inference_engine.offload_model_weights() self.offload_infer_params()
def enter_forward_mode(self): .... self.megatron_offloader.onload_param()
def exit_forward_mode(self): ... self.megatron_offloader.offload_param()
def enter_train_mode(self): ... self.megatron_offloader.onload_param() ... self.megatron_offloader.onload_optimizer() ... self.megatron_offloader.onload_grad()
def exit_train_mode(self): ... self.megatron_offloader.offload_optimizer() ... self.megatron_offloader.offload_grad() |
MegtronOffLoader
|
#mindspeed_rl/workers/resharding/megatron_off_loader.py class MegatronOffLoader: def offload_grad(self): ... def onload_grad(self): ... def offload_optimizer(self): ... def onload_optimizer(self): ... def offload_param(self): ... def onload_param(self): ... |
训推转换处理
核心代码
mindspeed_rl/workers/resharding/megatron_sharding_manager.py
mindspeed_rl/models/rollout/vllm_adapter/megatron_weight_loaders.py
主要逻辑
训推转换主要逻辑
- 推理转训练:
- 加载训练参数、优化器加载、梯度
- 训练转推理:
- onload_infer_params:初始化memory_buffer
- vllm_weight_container.get_infer_params:做训练到推理的切分转换, 获取转换后的vllm权重state dict,但是还是megatron的格式
- inference_engine.sync_model_weights: 权重格式从megatron转换为vllm,并加载到vllm引擎
- megatron_offloader.offload_param: 训练参数卸载
|
#mindspeed_rl/workers/resharding/megatron_sharding_manager.py def enter_infer_mode(self): #初始化memory_buffer self.onload_infer_params() #获取转换后的vllm权重state dict,但是还是megatron的格式 infer_params = self.vllm_weight_container.get_infer_params() #训练参数卸载 if self.train_param_offload: self.megatron_offloader.offload_param() #权重格式从megatron转换为vllm,并加载到vllm引擎 self.inference_engine.sync_model_weights(infer_params, load_format='megatron') |
训推切分转换具体实现
主要通过vllm_weight_container.get_infer_params实现,做训练到推理的切分转换, 获取转换后的vllm权重state dict
|
#mindspeed_rl.workers.resharding.vllm_weight_container.MegatronStyleVllmWeightContainer.get_infer_params def get_infer_params(self): """ return the whole weight state dict for vllm, but in megatron style and names, needs megatron weight loader to further transfer for vllm """ #在一个pp stage内进行权重转换 self._update_weight_buffers_intra_pp() #同步PP组内素有PP rank的权重 self._update_weight_buffers_inter_pp() # 调整专家并行 if(self.moe_tp_extend_ep and self._infer_ep_size >= self._ep_size): self._update_weight_buffers_ep() self._send_receive_experts() #获取模型所有PP rank的参数 params = self._get_all_params() params = _build_infer_param_dict(params=params) return params |
权重格式从megatron转换为vllm,并加载到vllm引擎
sync_model_weights实现了权重格式从megatron转换为vllm,并加载到vllm引擎。
sync_model_weights调用了load_megatron_weights,load_megatron_weights中的model_weight_loader根据具体训练模型来选择,这里选择的是deepseek_megatron_weight_loader。下面是详细调用过程。
|
#mindspeed_rl.models.rollout.vllm_engine.VLLMInferEngine.sync_model_weights def sync_model_weights(self, params, load_format='megatron'): infer_parallel_config = InferParallelConfig(self.infer_tensor_parallel_size, self.infer_pipeline_parallel_size, self.infer_expert_parallel_size * \ self.infer_tensor_parallel_size) load_megatron_weights(params, self.model, infer_parallel_config, self.hf_config) if hasattr(self.model, 'model') and hasattr(self.model.model.layers[0].self_attn, "mla_attn"): self._process_mla() |
|
#mindspeed_rl.models.rollout.vllm_adapter.megatron_weight_loaders.load_megatron_weights def load_megatron_weights(actor_weights: Dict, vllm_model: nn.Module, infer_paralle_config: InferParallelConfig, hf_config: PretrainedConfig): model_weight_loader = _get_model_weight_loader(vllm_model.__class__.__name__) vllm_model = model_weight_loader(actor_weights, vllm_model, infer_paralle_config, hf_config) # NOTE(sgm) to reduce peak memory usage, we offload vllm model to cpu # after init, and we need this after sync model weights for in first iter. vllm_model = vllm_model.cuda() return vllm_model |
|
#mindspeed_rl.models.rollout.vllm_adapter.megatron_weight_loaders.deepseek_megatron_weight_loader def deepseek_megatron_weight_loader(actor_weights: Dict, vllm_model: nn.Module, infer_paralle_config: InferParallelConfig, hf_config: PretrainedConfig ) -> nn.Module: params_dict = dict(vllm_model.named_parameters()) for name, loaded_weight in actor_weights.items(): if "qkv" in name: split_dim = hf_config.q_lora_rank if hf_config.q_lora_rank else \ (hf_config.qk_nope_head_dim + hf_config.qk_rope_head_dim) * \ hf_config.num_attention_heads q_name = name.replace("qkv_proj", "q_a_proj" if hf_config.q_lora_rank else "q_proj") kv_name = name.replace("qkv_proj", "kv_a_proj_with_mqa") load_single_weight(params_dict, q_name, loaded_weight[:split_dim]) load_single_weight(params_dict, kv_name, loaded_weight[split_dim:]) continue if name not in params_dict.keys(): raise ValueError(f"unexpected key {name} in deepseek_megatron_weight_loader") if "mlp.experts.w13_weight" in name: loaded_weight.copy_(loaded_weight.view(hf_config.n_routed_experts // infer_paralle_config.infer_expert_parallel_size, hf_config.hidden_size, -1).transpose(2, 1).contiguous()) if "mlp.experts.w2_weight" in name: loaded_weight.copy_(loaded_weight.view(hf_config.n_routed_experts // infer_paralle_config.infer_expert_parallel_size, -1, hf_config.hidden_size).transpose(2, 1).contiguous()) load_single_weight(params_dict, name, loaded_weight) return vllm_model |
weight_buffers(vllm_weight_container.weight_buffers)初始化
MegatronShardingManager的enter_infer_mode(训转推流程)中调用了self.onload_infer_params,而self.onload_infer_params()对weight_buffers中每个buffer进行了buffer.rebuild,真正分配了buffer的内存空间。下面简单介绍一下,weight_buffers初始化,以及self.onload_infer_params的流程。
|
#mindspeed_rl.workers.resharding.megatron_sharding_manager.MegatronShardingManager.enter_infer_mode def enter_infer_mode(self): self.onload_infer_params() infer_params = self.vllm_weight_container.get_infer_params() if self.train_param_offload: self.megatron_offloader.offload_param() self.inference_engine.sync_model_weights(infer_params, load_format='megatron') |
|
#mindspeed_rl.workers.resharding.megatron_sharding_manager.MegatronShardingManager.onload_infer_params def onload_infer_params(self): infer_weight_buffers = self.vllm_weight_container.weight_buffers for buffer in infer_weight_buffers: buffer.rebuild() |
weight_buffers初始化
weight_buffers调用_init_weight_buffers进行初始化,实际上生成了一个memory_buffers列表,并没有真正分配内存空间
|
memory_buffers = [ModelWeightBuffer(model, weight_names, get_weight_buffer_meta) for weight_names in combined_names_per_pp] |
下面是调用顺序
_init_weight_buffers
|
#mindspeed_rl.workers.resharding.vllm_weight_container.MegatronStyleVllmWeightContainer._init_weight_buffers
def _init_weight_buffers(self): """ Build buffers from vllm state dict. Totally build train pp_size buffers, each buffer corresponds to a pack of megatron weight. Return a list of buffers, and a reference dict megatron_param_name->buffer. """ #获取每个pp内部的weights name vllm_names = list(dict(self.vllm_model.named_parameters()).keys()) if is_multimodal(): layers_num = [sum(num_layer_list) for num_layer_list in self._num_layer_list] else: layers_num = sum(self._num_layer_list) self.weight_names_per_pp = self.weight_adaptor.get_weight_names_per_pp(self._vpp_layer_list, \ vllm_names, layers_num, self._vpp_size, self._noop_layers) self.weight_buffers = build_model_weight_buffer(self.vllm_model, self.weight_names_per_pp, self.weight_adaptor.get_weight_buffer_meta) |
build_model_weight_buffer
|
#mindspeed_rl.workers.resharding.memory_buffer.build_model_weight_buffer def build_model_weight_buffer(model: nn.Module, names_per_pp: List[str], get_weight_buffer_meta): combined_names_per_pp = [[] for _ in names_per_pp] for pp_rank, vpp_stages in enumerate(names_per_pp): for weight_names_per_stage in vpp_stages: combined_names_per_pp[pp_rank].extend(weight_names_per_stage) memory_buffers = [ModelWeightBuffer(model, weight_names, get_weight_buffer_meta) for weight_names in combined_names_per_pp] return memory_buffers |
ModelWeightBuffer
|
#mindspeed_rl.workers.resharding.memory_buffer.ModelWeightBuffer class ModelWeightBuffer: """ A factory class that processes a model's state_dict and returns memory buffers for the model parameters. It also provides a mapping between model parameter names and their corresponding memory buffer view. """ def __init__(self, model: nn.Module, weight_names: List, get_weight_buffer_meta): self.model = model self.get_weight_buffer_meta = get_weight_buffer_meta self.weight_buffer_meta = self.get_weight_buffer_meta(self.model, weight_names) self.weight_names = list(self.weight_buffer_meta.keys()) self.memory_buffers = None |
onload_infer_params流程(分配缓存空间)
上一步初始化的weight_buffers,在这一步通过调用buffer.rebuild真正分配内存空间,分配内存空间时候,根据get_weight_buffer_meta(参考下一节介绍)获取的vllm key到megatron shape的映射关系(即buffer的结构)。下面是具体调用顺序
|
#mindspeed_rl.workers.resharding.megatron_sharding_manager.MegatronShardingManager.onload_infer_params def onload_infer_params(self): infer_weight_buffers = self.vllm_weight_container.weight_buffers for buffer in infer_weight_buffers: buffer.rebuild() |
ModelWeightBuffer.rebuild
|
#mindspeed_rl.workers.resharding.memory_buffer.ModelWeightBuffer.rebuild def rebuild(self): if self.memory_buffers is None: self.memory_buffers = build_memory_buffer(self.weight_buffer_meta) |
build_memory_buffer
|
def build_memory_buffer(weight_buffer_meta: Dict[str, Dict]) -> Dict[torch.dtype, MemoryBuffer]: """Build the memory buffer given weight_buffer_meta Args: weight_buffer_meta: contains mapping from name to a dictionary containing shape and dtype of the tensors Returns: a large memory buffer for each dtype that can hold all the tensors """ memory_buffers = {} total_numel_map = {} # map from dtype to the total numel for name, meta_info in sorted(weight_buffer_meta.items()): shape = meta_info['shape'] dtype = meta_info['dtype'] if not isinstance(shape, torch.Size): raise TypeError("Shape must be an instance of torch.Size") if not isinstance(dtype, torch.dtype): raise TypeError("dtype must be an instance of torch.dtype") if dtype not in total_numel_map: total_numel_map[dtype] = 0 total_numel_map[dtype] += calc_padded_numel(shape, dtype) for dtype, total_numel in total_numel_map.items(): # Create a buffer for each dtype with the total numel memory_buffers[dtype] = MemoryBuffer(total_numel, total_numel, dtype) # Now, insert each tensor's index and shape for later retrieval by name current_index_map = {} # This keeps track of the current memory index for each dtype for name, meta_info in sorted(weight_buffer_meta.items()): shape = meta_info['shape'] dtype = meta_info['dtype'] buffer = memory_buffers[dtype] tensor_size = calc_padded_numel(shape, dtype) start_index = current_index_map.get(dtype, 0) current_index_map[dtype] = start_index + tensor_size buffer.tensor_indices[name] = (start_index, shape) return memory_buffers |
MemoryBuffer
|
class MemoryBuffer: """ A memory buffer is a contiguous torch tensor that may combine multiple tensors sharing with the underlying memory. It must have a unique type to support this behavior. """ def __init__(self, numel: int, numel_padded: int, dtype: torch.dtype): self.numel = numel self.numel_padded = numel_padded self.dtype = dtype # Create a memory buffer with padding for alignment (e.g., 128-bit alignment) self.data = torch.zeros(self.numel_padded, dtype=self.dtype, device=torch.cuda.current_device(), requires_grad=False) # Stores the mapping of parameter names to their position in the buffer self.tensor_indices = {} |
模型转换映射关系定义
MindSpeed-RL一般不直接关心模型结构,一般情况下仅resharding与模型有关。
对于自定义模型,可以继承mindspeed_rl.workers.resharding.weight_adaptor.MegatronVLLMWeightAdaptor来实现自定义模型支持:
- 对于大多数模型而言只需要定义params_mapping来实现megatron key到vllm key之间的映射即可。
- 对于key无法一一映射的情况,可以进一步修改get_weight_buffer_meta。
- get_weight_buffer_meta以vllm model作为输入,返回vllm key到megatron shape的映射,为MemoryBuffer分配提供信息
- 在deepseek这个案例中,代码将kv proj和q proj合并。
- megatron key到vllm key之间无法一一映射
- vllm中key为kv_a_proj_with_mqa、q_a_proj
- 在训练时合并为qkv_proj(megtron格式)(因为后面要把megtron格式的weight放到buffer,所以qkv_proj需要遵照megtron格式)
- 在WEIGHT_ADAPTOR_REGISTRY中注册模型
|
#mindspeed_rl.workers.resharding.weight_adaptor.DeepSeekMVWeightAdaptor class DeepSeekMVWeightAdaptor(MegatronVLLMWeightAdaptor): def __init__(self, model_config): super(DeepSeekMVWeightAdaptor, self).__init__(model_config) #定义权重转换时候,哪些名字需要替换、删除 self.meta_info = {'replace': {'kv_a_proj_with_mqa': 'qkv_proj'}, 'delete': ['q_a_proj']} #实现megatron key到vllm key之间的映射 self.params_mapping = [ # (megatron core gpt model name, vllm model name) ("embedding.word_embeddings", "model.embed_tokens"), ("self_attention.linear_qkv", "self_attn.qkv_proj"), # q_a_proj, kv_a_proj_with_mqa ("self_attention.linear_proj", "self_attn.o_proj"), ...... ("self_attention.linear_qb", "self_attn.q_b_proj"), ("self_attention.linear_kvb", "self_attn.kv_b_proj"), ...... ] def get_weight_buffer_meta(self, model, valid_names=None): #以vllm model作为输入,返回vllm key到megatron shape的映射,为MemoryBuffer分配提供信息 #megatron key到vllm key之间无法一一映射,vllm中key为kv_a_proj_with_mqa、q_a_proj,在训练时合并为qkv_proj(megtron格式)(因为后面要把megtron格式的weight放到buffer,所以qkv_proj按照megtron格式) weight_buffer_meta = {} for name, param in sorted(model.named_parameters()): if valid_names and name not in valid_names: continue if 'kv_a_proj_with_mqa' in name: q_param = dict(model.named_parameters()).get(name.replace('kv_a_proj_with_mqa', 'q_a_proj')) qkv_param_shape = torch.cat([q_param, param], dim=0).shape qkv_name = name.replace('kv_a_proj_with_mqa', 'qkv_proj') weight_buffer_meta[qkv_name] = {'shape': qkv_param_shape, 'dtype': param.dtype} elif 'q_a_proj' in name: continue else: weight_buffer_meta[name] = {'shape': param.shape, 'dtype': param.dtype} return weight_buffer_meta #在WEIGHT_ADAPTOR_REGISTRY中注册模型 WEIGHT_ADAPTOR_REGISTRY = { "Qwen2ForCausalLM": QwenMVWeightAdaptor, "DeepseekV3ForCausalLM": DeepSeekMVWeightAdaptor, "DeepseekV2ForCausalLM": DeepSeekMVWeightAdaptor, } |
vllm加载权重时的格式转换处理
上面做的合并,在转换后需要对qkv再行拆分,mindspeed_rl/models/rollout/vllm_adapter/megatron_weight_loaders.py中可以定义vllm加载权重时的格式转换处理,将q和kv再行拆分。
|
#mindspeed_rl.models.rollout.vllm_adapter.megatron_weight_loaders.deepseek_megatron_weight_loader #定义vllm加载权重时的格式转换处理,此处将q和kv再行拆分 def deepseek_megatron_weight_loader(actor_weights: Dict, vllm_model: nn.Module, infer_paralle_config: InferParallelConfig, hf_config: PretrainedConfig ) -> nn.Module: params_dict = dict(vllm_model.named_parameters()) for name, loaded_weight in actor_weights.items(): if "qkv" in name: split_dim = hf_config.q_lora_rank if hf_config.q_lora_rank else \ (hf_config.qk_nope_head_dim + hf_config.qk_rope_head_dim) * \ hf_config.num_attention_heads q_name = name.replace("qkv_proj", "q_a_proj" if hf_config.q_lora_rank else "q_proj") kv_name = name.replace("qkv_proj", "kv_a_proj_with_mqa") load_single_weight(params_dict, q_name, loaded_weight[:split_dim]) load_single_weight(params_dict, kv_name, loaded_weight[split_dim:]) continue ...... return vllm_model |
参考示例
mindspeed_rl/workers/integrated_worker.py
mindspeed_rl/workers/actor_hybrid_worker.py
全共卡训推状态转换,可以参考上面代码中,以下方法的使用
|
generate_sequences compute_ref_log_prob compute_log_prob update |
|
#mindspeed_rl.workers.actor_hybrid_worker.ActorHybridWorkerBase.generate_sequences def generate_sequences(self): sharding_infer_interval = 0 ...... start_sharding_enter_infer = time.time() #进入推理模式 self.sharding_manager.enter_infer_mode() sharding_infer_interval = time.time() - start_sharding_enter_infer ...... #推理 self.generate_process(batch_data, index, pad_token_id) ...... start_sharding_exit_infer = time.time() #卸载推理参数 self.sharding_manager.exit_infer_mode() torch.cuda.empty_cache() sharding_infer_interval += (time.time() - start_sharding_exit_infer) ...... |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)