从底层到实战,金仓多模数据库 MongoDB 兼容的技术实力到底有多强?
“国产替代”已经不是新鲜话题了,现在国产数据库的竞争焦点,早就从“能不能兼容用”变成了“能不能靠融合定义新标准”。尤其是AI带火了多模态数据之后,MongoDB这种主流文档数据库的兼容方案,根本不是简单换个“平替”就行——关键要看厂商能不能搭起一个“多模融合底座”。
前言
“国产替代”已经不是新鲜话题了,现在国产数据库的竞争焦点,早就从“能不能兼容用”变成了“能不能靠融合定义新标准”。尤其是AI带火了多模态数据之后,MongoDB这种主流文档数据库的兼容方案,根本不是简单换个“平替”就行——关键要看厂商能不能搭起一个“多模融合底座”。
刚好,电科金仓最新技术发布会上提的“融合、AI、平台能力”三个关键词,正好回应了这个行业难题。它家多模数据库的MongoDB兼容能力,真不是抄个功能外壳那么简单,而是把企业级内核和文档模型深度融到了一起。今天咱们就从底层架构讲到实际落地,好好聊聊金仓这波技术到底硬不硬,看看它是怎么帮企业实现“不用改代码、性能不打折、合规全满足”的国产化升级的。

下面我们就从三个维度展开:先讲它的融合架构根基,再拆五大核心技术突破,最后看行业的实战效果。看完你就清楚,金仓这套方案到底能不能解决咱们实际迁移中的那些痛点。
文章目录
一、底层根基:真融合不是“拼积木”,而是从内核打通
市面上很多MongoDB兼容方案都走了弯路:要么用中间件转接,要么把多个产品拼在一起。这样做不仅慢,还会造成数据孤岛,运维起来要学好几套系统,特别麻烦。
金仓多模数据库的突破点,就是从架构上做到了“原生融合”——不是把文档功能当插件加上去,而是直接把文档模型深度集成到统一内核里。这也是电科金仓“融合数据库”理念的核心:打破不同数据类型、查询语法、运维体系的壁垒,搭一个能适配AI时代的统一数据底座。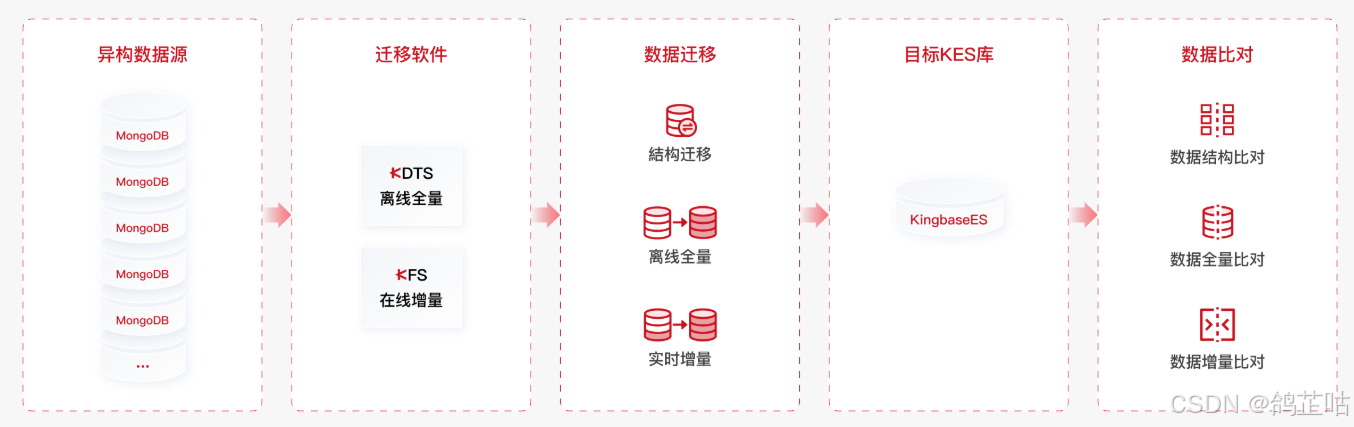
具体来说,这个底层架构靠“五个一体化”撑起来,每一点都直接解决了传统方案的痛点:
- 数据模型一体化:结构化数据(比如表格)、文档数据(比如MongoDB的JSON)、图数据、时序数据、向量数据,这五种主流数据类型都能原生支持,存在同一个引擎里,不用跨系统来回调;
- 语法兼容一体化:不仅能100%兼容MongoDB 5.0以上的通信协议和常用命令,连Oracle、MySQL的语法也能覆盖,写代码不用来回切换风格;
- 部署形态一体化:集中式、分布式、读写分离这些部署方式都支持,不管是核心业务系统还是边缘节点,都能适配;
- 开发运维一体化:靠统一的管控平台KEMCC,MongoDB兼容实例和其他数据库能在一个界面里监控、调优、自动修复,不用学多套运维工具;
- 应用场景一体化:既能扛住政务、金融这些传统核心业务,也能支撑语义检索、RAG问答这种AI原生场景。
简单说,这种架构从根上解决了问题:数据不用跨库同步,查询不用多引擎协同,运维不用学一堆系统,真正做到了1+1大于2的融合效果。
二、核心技术突破:五大关键能力,既要兼容更要超越
如果说融合架构是地基,那这五大核心技术就是承重墙。从多模数据查询到大文件存储,从企业级能力补全到索引优化,每一项都精准解决了企业迁移时的核心痛点——目标不只是“能兼容”,更是“比原生MongoDB更好用”。
2.1 多模数据统一查询:不用跨库折腾,效率直接翻倍
做企业业务的都知道,经常要同时查两种数据:比如用户基础信息(存在关系型数据库里)和用户行为日志(存在MongoDB里)。传统方案要跨两个库查,又慢又麻烦,维护成本还高。
金仓的解决思路很直接:通过“原生JSONB支持+多模查询优化器+向量化执行引擎”三重优化,让两种数据能无缝联动查询,不用再来回折腾。
核心亮点很实在:
- 内核原生优化了JSONB存储,既保留了JSON的灵活性,又能像二进制一样高效读写,找嵌套字段也精准;
- 多模查询优化器很智能,不管你写的是MongoDB的find/aggregate语法,还是SQL,它都能统一解析,自动找出最快的执行方式;
- 向量化执行引擎在批量查文档时优势明显,实测比原生MongoDB快30%以上。
给大家上一段实际能用的多模联合查询代码,一看就懂:
-- 关系表:用户基础信息
CREATE TABLE user_base (
user_id VARCHAR(36) PRIMARY KEY,
user_name VARCHAR(50),
status INT -- 1表示活跃用户
);
-- MongoDB兼容集合(自动映射为含JSONB字段的表)
CREATE TABLE user_behavior (
_id UUID PRIMARY KEY,
behavior_data JSONB, -- 存储用户行为的文档数据,比如{"user_id":"xxx","action":"login","login_time":"2024-07-01 10:00:00"}
create_time TIMESTAMP
);
-- 联合查询:获取近24小时活跃用户的最近登录行为
SELECT ub.user_name, ub.user_id, ubh.behavior_data->>'login_time' AS login_time
FROM user_base ub
JOIN user_behavior ubh ON ub.user_id = ubh.behavior_data->>'user_id'
WHERE ub.status = 1
AND ubh.behavior_data @> '{"action":"login"}' -- 筛选登录行为
AND ubh.create_time > NOW() - INTERVAL '24 hours';
实测效果很直观:在一个100万用户的行为分析项目里,用这套方案做跨数据模型查询,比原来“MongoDB+关系库”跨库查询快了65%,而且不用运维人员手动调优,优化器会自动避开全表扫描,省了不少事。
这里补充一段Python调用MongoDB驱动查询多模数据的代码,更贴近开发实际使用场景:
from pymongo import MongoClient
# 连接金仓多模数据库(兼容MongoDB协议)
client = MongoClient("mongodb://user:password@kingbase-host:27017/admin")
db = client.test_db
# 1. 用MongoDB语法查用户行为文档
behavior_cursor = db.user_behavior.find(
{"behavior_data.action": "login"},
{"behavior_data.user_id": 1, "behavior_data.login_time": 1, "_id": 0}
).limit(10)
# 2. 提取用户ID,关联查询关系表数据(这里直接用SQL更直观,金仓支持在驱动中执行SQL)
user_ids = [doc["behavior_data"]["user_id"] for doc in behavior_cursor]
user_info = db.runSQL(f"""
SELECT user_id, user_name FROM user_base
WHERE user_id IN ({','.join([f"'{uid}'" for uid in user_ids])})
""")
print("近24小时活跃用户登录信息:", user_info)
2.2 大对象存储:原生兼容GridFS,传大文件不卡顿
医疗影像、视频片段这些大文件,很多企业都会用MongoDB的GridFS协议存储。但这个协议兼容起来特别麻烦,而且原生存储性能有限,传大文件经常卡顿。
金仓的方案是“原生适配+分层存储+传输优化”三管齐下,让大对象从上传、存储到查询、删除,全流程都高效顺畅。
核心优势很明确:
- 完全兼容GridFS协议,应用端直接用MongoDB官方驱动就行,一行代码都不用改;
- 分层存储设计,文件的元数据存在JSONB里还建了索引,查起来很快,实际的大文件数据由专用引擎管理,支持按需加载和并行读写,不会拖慢整体性能;
- 支持断点续传和数据压缩,在带宽差的环境里,传输效率能提升40%。
下面是大对象常规操作的实战代码,比如医疗影像的上传下载:
import com.mongodb.client.MongoClients;
import com.mongodb.client.MongoDatabase;
import com.mongodb.client.gridfs.GridFSBuckets;
import com.mongodb.client.gridfs.GridFSBucket;
import com.mongodb.client.gridfs.model.GridFSUploadOptions;
import org.bson.Document;
import org.bson.types.ObjectId;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.OutputStream;
public class GridFSDemo {
public static void main(String[] args) {
// 1. 初始化MongoDB驱动(直接连接金仓兼容端口)
try (var mongoClient = MongoClients.create("mongodb://kingbase-host:27018/file_db")) {
MongoDatabase database = mongoClient.getDatabase("file_db");
GridFSBucket gridFSBucket = GridFSBuckets.create(database);
// 2. 上传大对象(医疗影像文件)
try (InputStream stream = new FileInputStream("medical_image.dcm")) {
ObjectId fileId = gridFSBucket.uploadFromStream(
"patient-123-image", // 文件名
stream,
new GridFSUploadOptions().metadata(new Document("patientId", "123")) // 附加患者ID元数据
);
System.out.println("文件上传完成,ID:" + fileId);
}
// 3. 下载大对象(根据文件名)
try (OutputStream stream = new FileOutputStream("downloaded_image.dcm")) {
gridFSBucket.downloadToStream("patient-123-image", stream);
System.out.println("文件下载完成");
}
// 4. 查询大对象元数据(根据患者ID筛选)
var files = gridFSBucket.find(new Document("metadata.patientId", "123"));
files.forEach(file -> {
System.out.println("文件名:" + file.getFilename() + ",大小:" + file.getLength() + "字节");
});
} catch (Exception e) {
e.printStackTrace();
}
}
}
2.3 企业级内核继承:补齐MongoDB的“短板”,核心场景能扛住
MongoDB在金融、政务这些核心场景里,短板特别明显:事务一致性差、高可用能力弱、安全性不足,根本满足不了行业要求。金仓的思路很简单:把自己多年打磨的企业级内核能力,直接嫁接到MongoDB兼容场景里,一次性把这些短板补上。
能继承的核心能力有这四点,都是企业最看重的:
-
强事务一致性:支持完整的ACID事务,还能兼容MongoDB的事务语法,跨文档操作也能保证原子性,不会出现数据错乱;
-
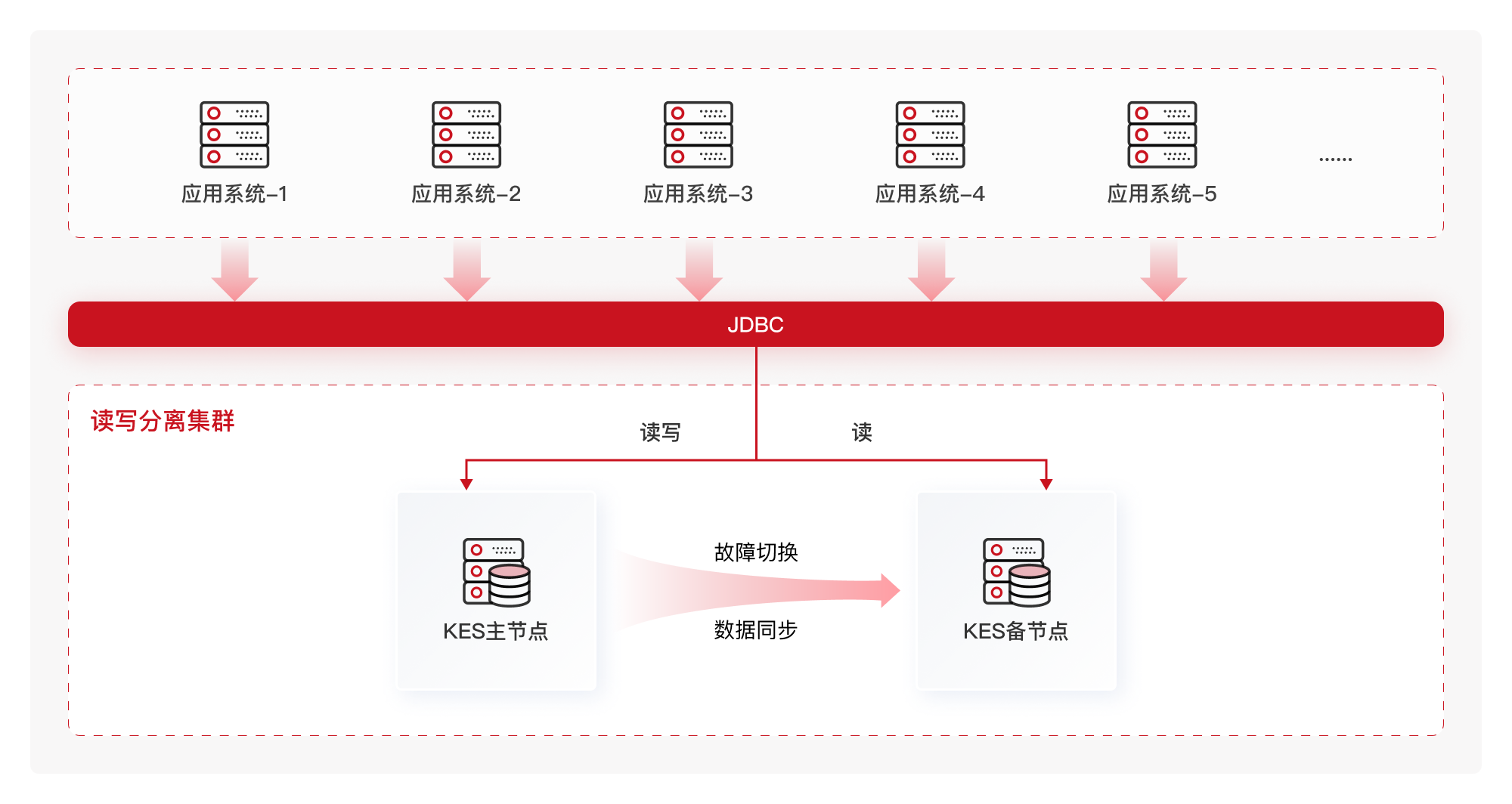
高可用保障:继承读写分离集群架构,故障时能秒级自动切换(切换时间不到8秒),数据零丢失,还支持同城双活、两地三中心这种高级容灾部署;
-
全链路安全:从访问控制、身份验证,到数据传输加密、存储加密,再到事后审计,一套防护体系全搞定,能满足等保三级要求;
-
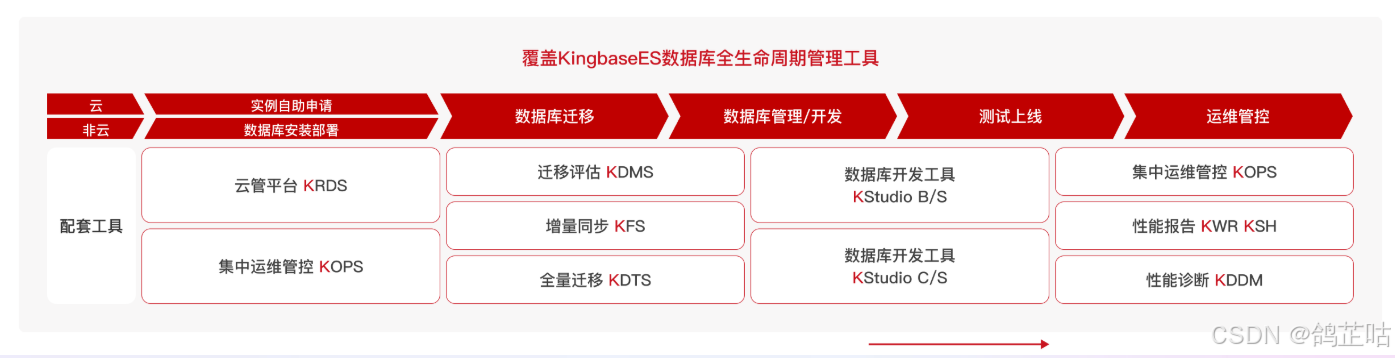
统一运维:靠KEMCC管控平台,多个数据库实例能在一个界面里监控、自动巡检、智能调优,不用单独维护。
比如电商场景里的“库存扣减+订单创建”,必须保证原子性,用金仓的跨文档事务代码就能轻松实现,和MongoDB语法完全一致:
// 兼容MongoDB事务语法,实现库存扣减与订单创建的原子性操作
const session = db.getMongo().startSession();
session.startTransaction();
try {
// 1. 扣减库存(文档1):确保库存充足才扣减
db.inventory.updateOne(
{ sku: "SPU-20240701", quantity: { $gte: 10 } }, // 商品SKU+库存≥10
{ $inc: { quantity: -10 } }, // 扣减10件库存
{ session: session }
);
// 2. 创建订单(文档2):库存扣减成功后创建订单
db.orders.insertOne(
{
orderId: "ORD-20240701-001",
sku: "SPU-20240701",
quantity: 10,
createTime: new Date()
},
{ session: session }
);
// 3. 事务提交:两步操作都成功才提交
session.commitTransaction();
print("事务执行成功,库存扣减+订单创建完成");
} catch (error) {
// 4. 事务回滚:任意一步失败则全回滚
session.abortTransaction();
print("事务执行失败,已回滚:", error);
} finally {
// 5. 结束会话
session.endSession();
}
2.4 灵活索引设计:查得快还不用手动调,全场景适配
数据库查得快不快,索引是关键。金仓在这方面考虑得很周全:一方面能直接复用MongoDB原来的索引,不用重新设计;另一方面还加了专用索引,能自动适配不同查询场景,保证每种场景都查得最快。
核心索引能力有三个亮点:1. 全兼容MongoDB原生索引:单字段、复合、地理空间、文本这些索引类型都支持,语法也完全一样,迁移过来直接用;2. 专用JSONB索引:针对嵌套文档查询,加了GIN和GiST两种专用索引,查嵌套字段时效率能提升25%-50%;3. 智能索引建议:能自动识别系统里的慢查询,推荐最优的索引创建方案,不用运维人员凭经验瞎折腾,也避免索引建多了影响写入性能。
下面是不同场景的索引创建代码,覆盖了大部分企业常用场景:
// 1. 兼容MongoDB单字段索引(查询用户ID时用)
db.user_behavior.createIndex({ "user_id": 1 }); // 1表示升序
// 2. 兼容MongoDB复合索引(同时查用户ID+行为类型时用,效率更高)
db.user_behavior.createIndex({ "user_id": 1, "action": 1 });
// 3. JSONB嵌套字段专用索引(查behavior_data里的address.city字段时用)
CREATE INDEX idx_behavior_city ON user_behavior USING GIN (behavior_data jsonb_path_ops);
// 4. 文本索引(全文检索场景用,比如查文章内容)
db.articles.createIndex({ "content": "text" });
// 5. 地理空间索引(LBS场景用,比如查附近的店铺)
db.stores.createIndex({ "location": "2dsphere" });
// 6. 查看索引使用情况(验证索引是否生效)
db.user_behavior.find({ "user_id": "123", "action": "login" }).explain("executionStats");
最省心的一点是,索引能自动适配查询场景:查嵌套字段就自动用GIN索引,做范围查询就切换到B-tree索引,搞全文检索就启用文本索引,全程不用人工干预,全场景都能保证性能最优。
2.5 国产化替代底气:不用改代码,性能合规双超越
企业做国产化替代,最关心的就是四点:成本低、风险小、性能好、全合规。金仓靠“零代码适配+全链路工具+性能合规双超越”,把这些诉求都满足了,让迁移过程顺顺利利。
核心优势很实在:
- 零代码迁移:完全兼容MongoDB的官方驱动,不管是Java的mongo-java-driver,还是Python的pymongo,都能直接用,只需要改一下数据库连接地址,业务代码一行都不用动,迁移成本直接降低80%;
- 全链路工具支撑:有KDTS数据迁移工具负责导全量历史数据,还有KFS工具同步增量数据,迁移后还能自动校验数据一致性,支持新旧系统同时运行,切换的时候只需要几分钟,业务完全不中断;
- 性能比原生还好:权威的YCSB基准测试显示,多数场景下性能比MongoDB 7.0还好,百万行数据全表更新比原生MongoDB快60%,高并发场景下,99%的请求响应延迟能降低34%;
- 合规完全达标:数据从存储到传输,全生命周期都有安全防护,能满足等保三级要求,彻底解决了原生MongoDB在合规上的短板。
三、金仓数据库实战:福建某地市电子证照系统
3.1 项目背景:电子证照系统数据管理的痛点
在政务数字化转型的大背景下,福建某地市的电子证照系统承担着为当地 500 余家单位提供证照共享服务的重任。该系统原先基于 MongoDB 构建,经过长期的运行,积累了 2TB 以上的海量证照数据,涵盖了营业执照、身份证、税务登记证等各类重要证照信息,日均 1000 + 并发(高峰期达 1000 + 连接数)。
3.2 迁移难点:原有架构的适配与风险
- 一是 JSON 存储与国产库表结构不兼容,易出现数据一致性风险;
- 二是高并发下亮证、跨部门调取等操作响应延迟高;
- 三是需在周末窗口期内完成 2TB 数据零丢失迁移,时间紧、风险大。
3.3 金仓解决方案:针对性技术落地
多模兼容实现零代码迁移:依托金仓多模特性,原生兼容 MongoDB 协议,仅改连接配置即可平替,无需修改业务代码,收敛技术栈成本。
读写分离突破并发瓶颈:主库承载写操作(证照签发、签章新增),从库承接高频读操作(亮证查询),并发承载提升至 1600 + 连接数;优化 “证照 - 企业信用码” 查询 SQL,响应延迟从 5 秒缩至 0.3 秒。
定制工具保障数据安全:基于金仓迁移工具定制开发,在窗口期内完成全量数据迁移,自动化校验 + 抽样 1000 份证照验证 OFD 匹配性,提前 2 小时完成,数据零丢失。
3.4 迁移价值:效率与安全的双重提升
- 性能提升:并发承载能力、响应速度显著优化,可稳定应对高峰期压力;
- 安全升级:提供访问控制、传输加密、审计等全链路安全防护,满足政务数据高安全要求;
- 政务价值:支撑 500 余家单位证照共享,稳定运行超 6 个月,为政务系统国产化提供可复制路径,助力 “数字政府” 与 “一网通办” 建设。
四、总结:从兼容到融合,国产数据库的新方向
金仓多模数据库的MongoDB兼容能力,早就不是“简单替代”了。它以融合架构为根基,靠五大核心技术解决了迁移中的各种痛点,再加上多个行业的实战验证,构建了一套“兼容+超越”的国产化升级方案。它不仅帮企业降低了迁移的成本和风险,还提供了能适配AI时代的多模数据管理能力,为数字化转型筑牢了数据底座。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 71
71 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)