LangGraph:从链式思维到代理思维的LLM开发范式革命!
LangGraph代表LLM应用开发从线性链式到代理思维的根本转变,通过引入"循环"概念使AI具备自我修正能力。其核心架构包含状态管理(State)、工作单元(Nodes)、决策中心(Conditional Edge)、持久化机制(Checkpointer)和分形扩展(Subgraph)。这一框架打破了传统流水线式开发限制,实现了AI的循环迭代思考,并支持时间旅行和人机协作,为构建复杂智能体系统提
LangGraph 不仅仅是 LangChain 的一个组件,它代表了 LLM 应用开发范式的一次根本性转变:从“链式思维(Chain)”向“代理思维(Agentic)”的跨越。
核心理念 - 打破线性的枷锁
在 LangChain 的早期,我们习惯构建 DAG(有向无环图),即“输入 -> A -> B -> 输出”。这就像工厂流水线,高效但死板。LangGraph 引入了“循环(Cycles)”。 人的思考不是线性的,而是循环往复的:思考 -> 尝试 -> 失败 -> 反思 -> 再尝试。LangGraph 通过将 LLM 应用建模为状态机,赋予了 AI 这种“循环迭代”的能力,AI 允许“回头看”,允许“自我修正”。
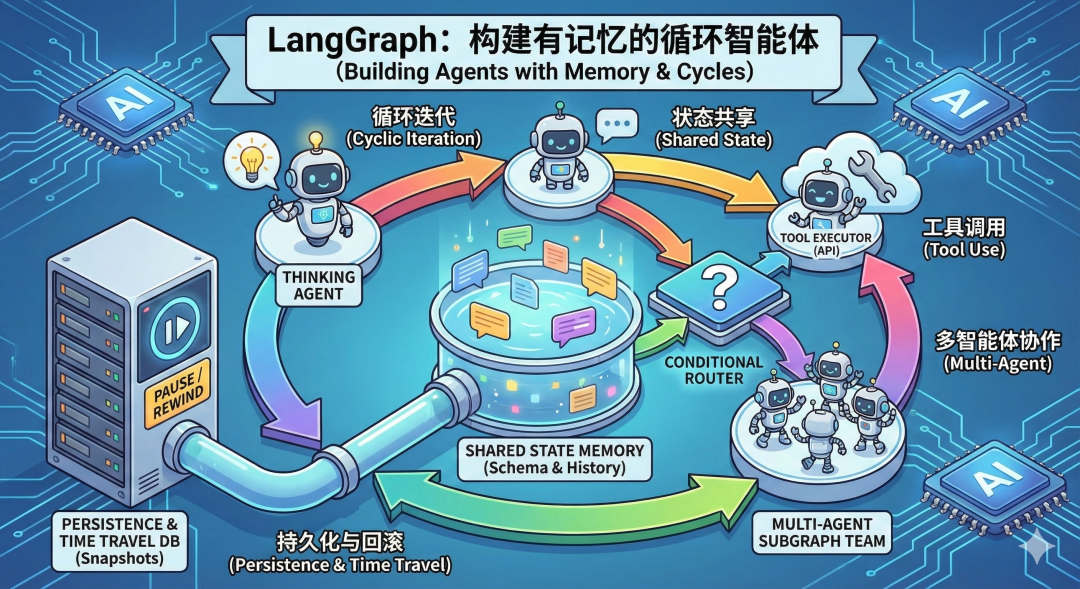
一、整体架构概览
LangGraph 的架构可以被拆解为三个核心层级。其设计哲学深受 Google Pregel的分布式图计算思想和 NetworkX的图结构接口设计影响。前者提供了“像顶点一样思考”的迭代并行计算范式,后者则启发了 LangGraph 在图结构化建模和 API 设计上的简洁性与灵活性。
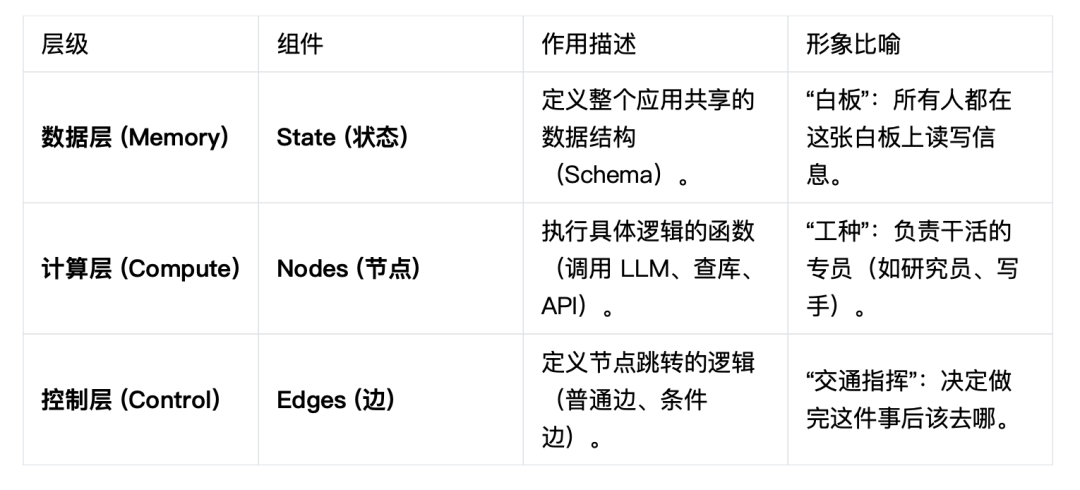
二、LangGraph核心组件
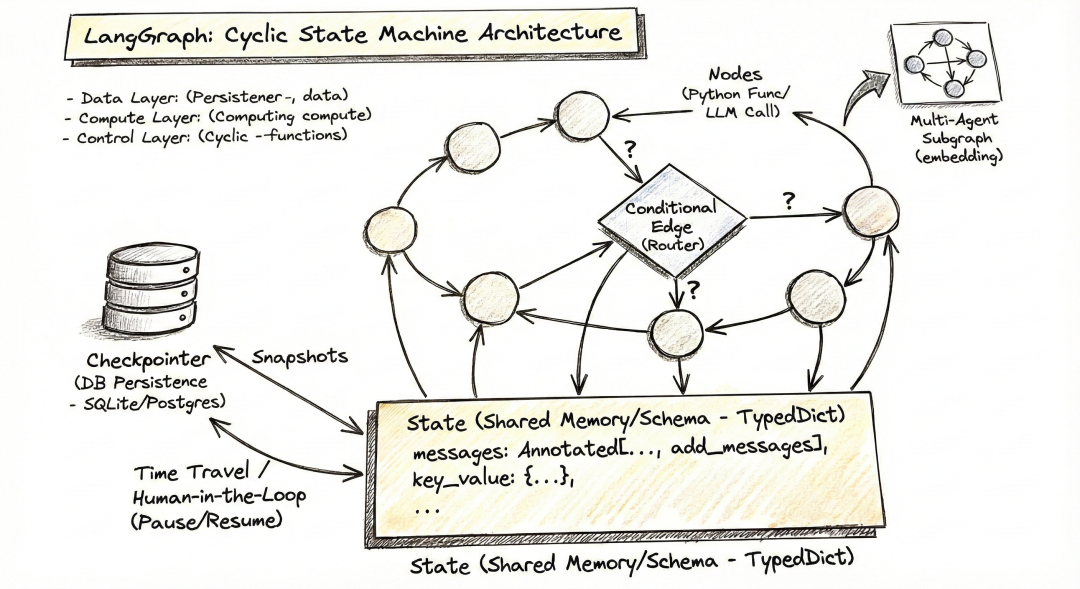
我们再看这个手绘架构图,可以对LangGraph 有一个更深入的理解,架构图生动地展示了 LangGraph **“循环(Cyclic)”**与 **“状态驱动(State-Driven)”**的核心本质。咱们进一步基于该图示对核心组件进行初步详解。
- 核心数据基座:State (底部的矩形框)
图示位置:位于底部,连接所有节点,被标注为 Shared Memory/Schema,可以理解为“全厂共享的白板”。
功能理解:
* 单一事实来源 (Single Source of Truth):无论是用户的初始输入、LLM 的思考过程,还是工具的返回结果,全部都要写在这个 State 里。
* Reducer 机制:注意图中 messages: Annotated[…, add_messages]。这代表了“增量更新”。当一个节点往 State 里写东西时,它不会清空白板,而是“追加”或“合并”信息。
- 工作单元:Nodes (圆圈)
图示位置:分布在圆环上的圆圈,标注为 Nodes。可以理解为“流水线上的工位”。
功能理解:
* 输入与输出:每个 Node 接收当前的 State,执行逻辑(比如调用 OpenAI API,或者查询数据库),然后返回一个 dict。这个 dict 就是要更新到白板上的新内容。
* 原子性:一个 Node 只专注做一件事(例如:agent_node 负责思考,tool_node 负责执行)。
- 决策中心:Conditional Edge (中心的菱形)
图示位置:圆环中心,标注为 Router 或 ?。理解为“车间调度员”。
功能理解:
* 动态路由:普通边(实线箭头)是固定的(做完 A 去 B),但条件边会检查 State 的内容。
* 逻辑示例:如果 LLM 的回复包含 tool_calls,调度员就指挥流程走向“工具节点”;如果 LLM 说 FINAL ANSWER,调度员就指挥流程走向“结束”。
- 时光机:Checkpointer (左侧的数据库圆柱)
图示位置:左侧,通过 Snapshots 箭头与 State 相连。理解为“游戏存档管理器”。
功能深度:
* 持久化 (Persistence):每当一个 Node 执行完,LangGraph 自动把 State 保存到数据库(SQLite/Postgres)。
* Thread ID:通过 thread_id,你可以随时“读档”,恢复之前的对话上下文。
* Time Travel:允许你回滚到之前的某个步骤,修改 State(比如修正错误的工具参数),然后重新运行。
- 分形扩展:Subgraph (右上角的小图)
图示位置:右上角,指向某个 Node。可以理解为“外包团队”。
功能深度:
* 封装:一个 Node 内部可以完全是另一个复杂的 LangGraph 图。主图不需要知道子图的细节,只需要看子图产出的最终 State。这是构建大规模多智能体系统的关键。
三、解构智能体的“大脑”与“记忆”
在传统的编程中,我们习惯把变量从函数 A 传给函数 B。但在 LangGraph 里,请忘掉“传递”,核心概念是“围观”。
- 全局白板 (State as a Whiteboard):
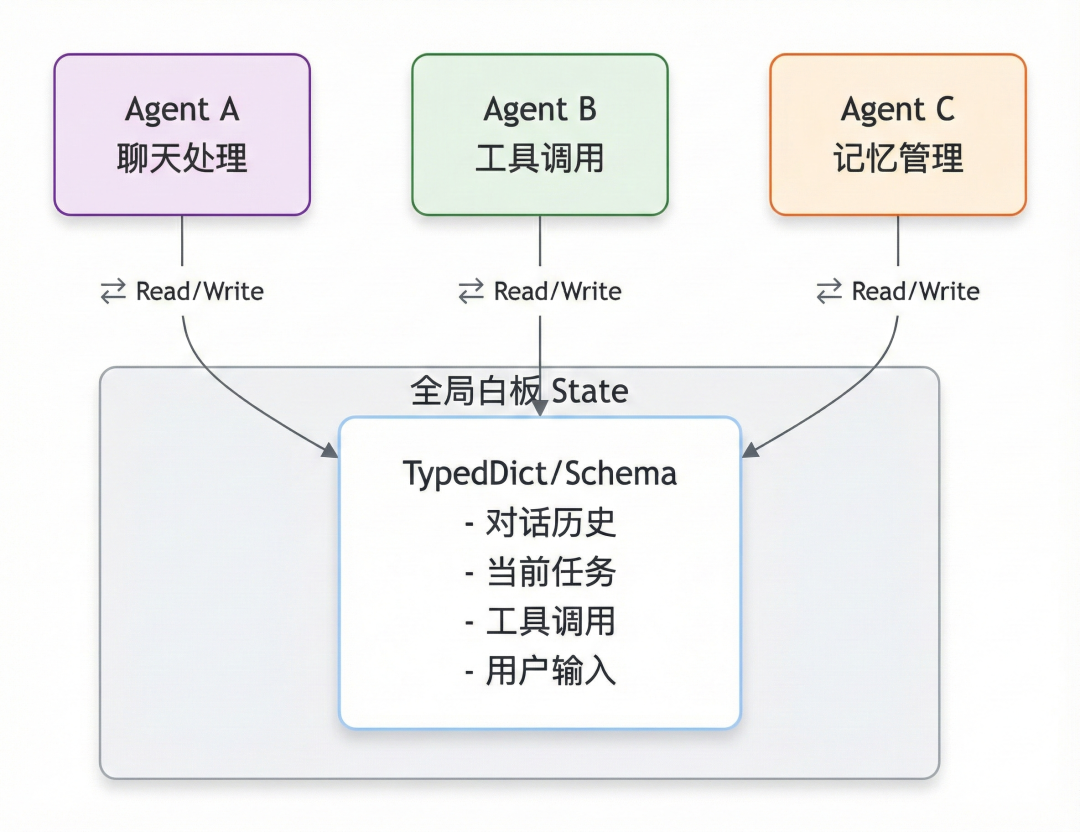
想象一个会议室,所有 Agent(节点)都围着一块巨大的白板(State)。
TypedDict/Schema就是这块白板的“格式规范”。比如规定左上角只能写“对话历史”,右下角只能写“当前任务”。没有任何节点能“私藏”信息,大家的一言一行(输入输出)都必须公开写在白板上。这也是为什么 LangGraph 能够轻松调试——看一眼白板,就知道当前发生了什么。
- 归约器 (Reducer):解决“多人同时写白板”的冲突
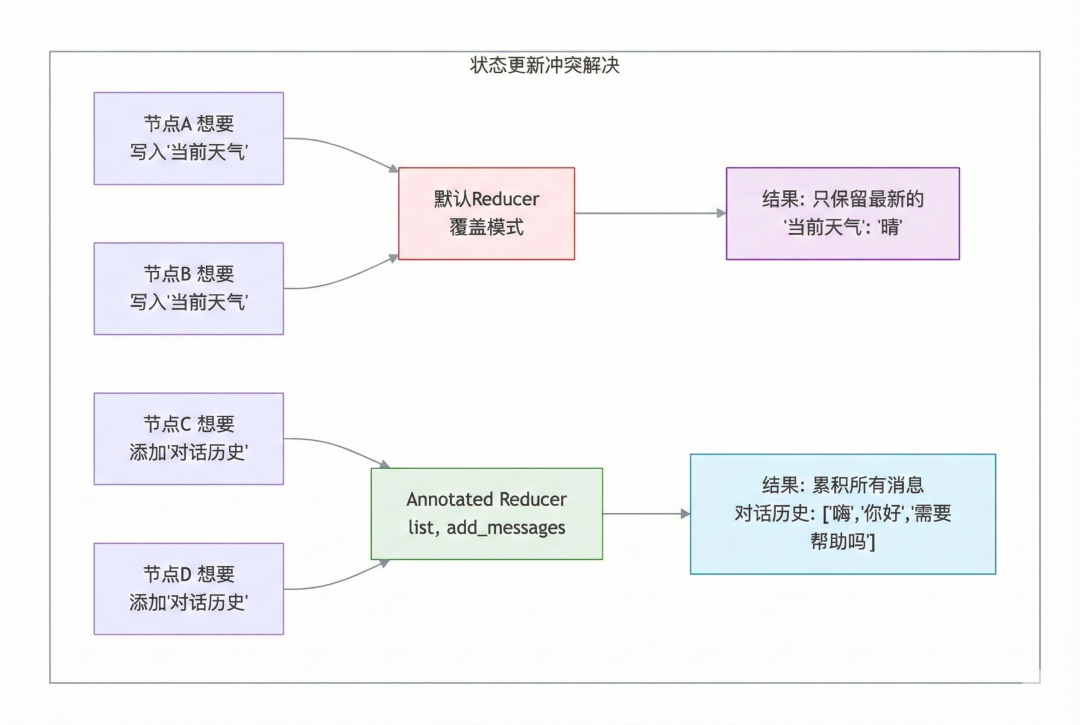
当两个节点同时想修改白板上的同一个区域,或者一个节点想往“聊天记录”里加一句话时,该怎么办?
-
默认行为(覆盖):就像擦黑板,新的把旧的擦掉,写上新的。这适合更新“当前天气”这种只需要最新值的字段。
-
Annotated 的魔法(追加):这是 LangGraph 的点睛之笔。通过
Annotated[list, add_messages],你告诉系统:“这个字段是记忆,不要擦掉旧的,把新的贴在后面。”
深度理解:这就是短期记忆的物理实现。没有这个机制,AI 聊两句就会“失忆”。
LangGraph 的运行逻辑,就是一群人在白板前轮流干活。
- 节点 (Nodes):只做增量更新的“懒人”:

每个节点就是一个 Python 函数,它看一眼白板(Input State),干点活,然后只回报它修改的那一点点内容。
深度细节:你不需要返回整块白板的数据(那太累了)。如果你只查了天气,就只返回 { “weather”: “Sunny” }。LangGraph 的后台引擎会自动把这条新数据合并(Merge)到全局白板上。这种“增量更新”的设计,让代码极其轻量。
- 边 (Edges):不仅是路线,更是决策:
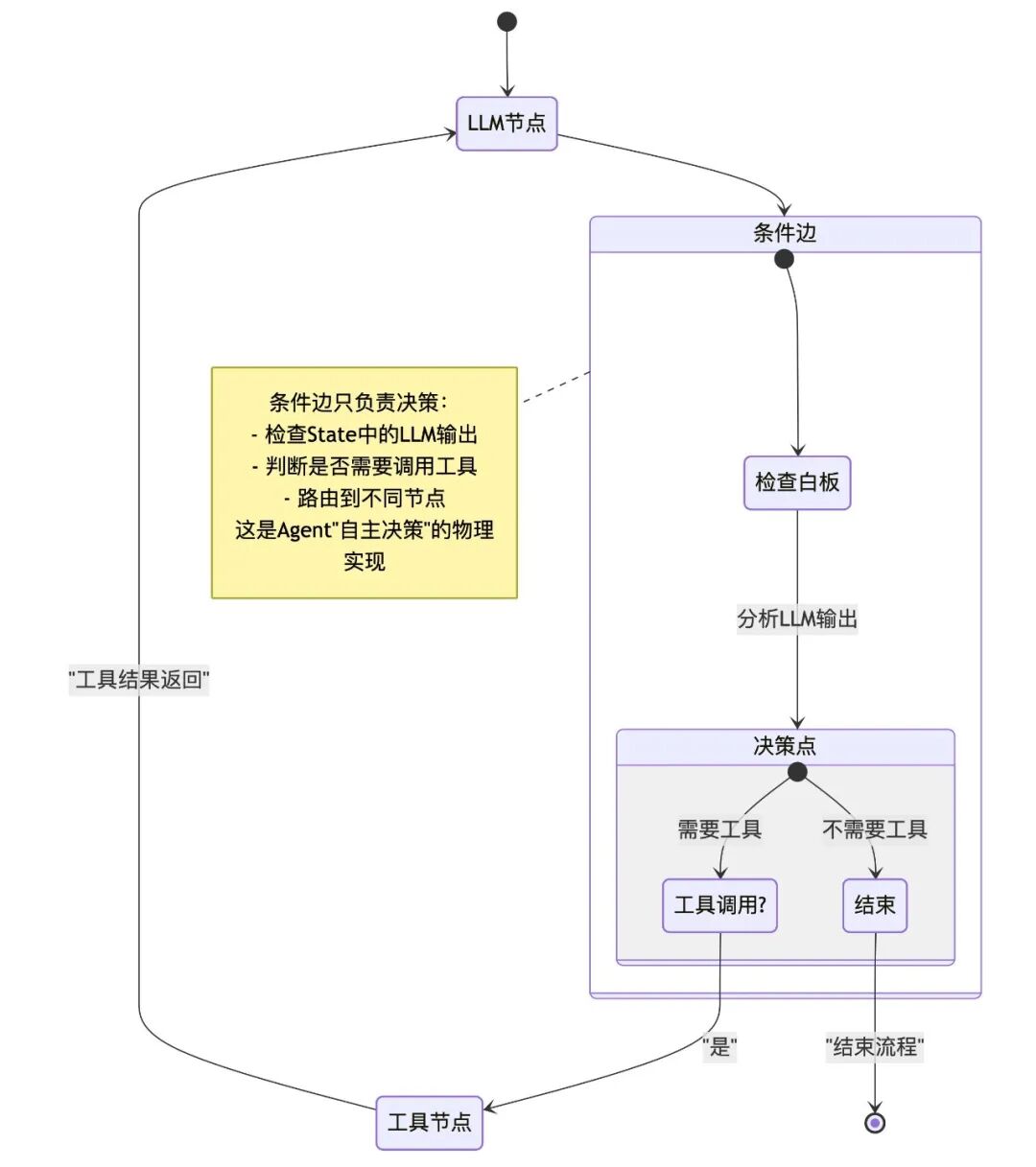
普通边 (NormalEdge):就像流水线传送带,A 做完必定传给 B,没有任何悬念。
条件边 (ConditionalEdge):这是智能的灵魂所在。它不干具体的活,而是充当“交通指挥官”。
它会盯着白板看:“哎,LLM 刚才说它需要用工具吗?如果需要,把流程切到 ToolNode;如果不需要,直接切到 END结束。”——这就是 Agent “自主决策”的物理发生地。
3. 持久化与“时间旅行”:给 AI 装上“存档”键 (Persistence)
这是 LangGraph 最让开发者感到“安心”的功能。它把 AI 从“阅后即焚”的瞬时计算,变成了“有历史、可回溯”的持久服务。
-
快照机制 (Checkpointer):
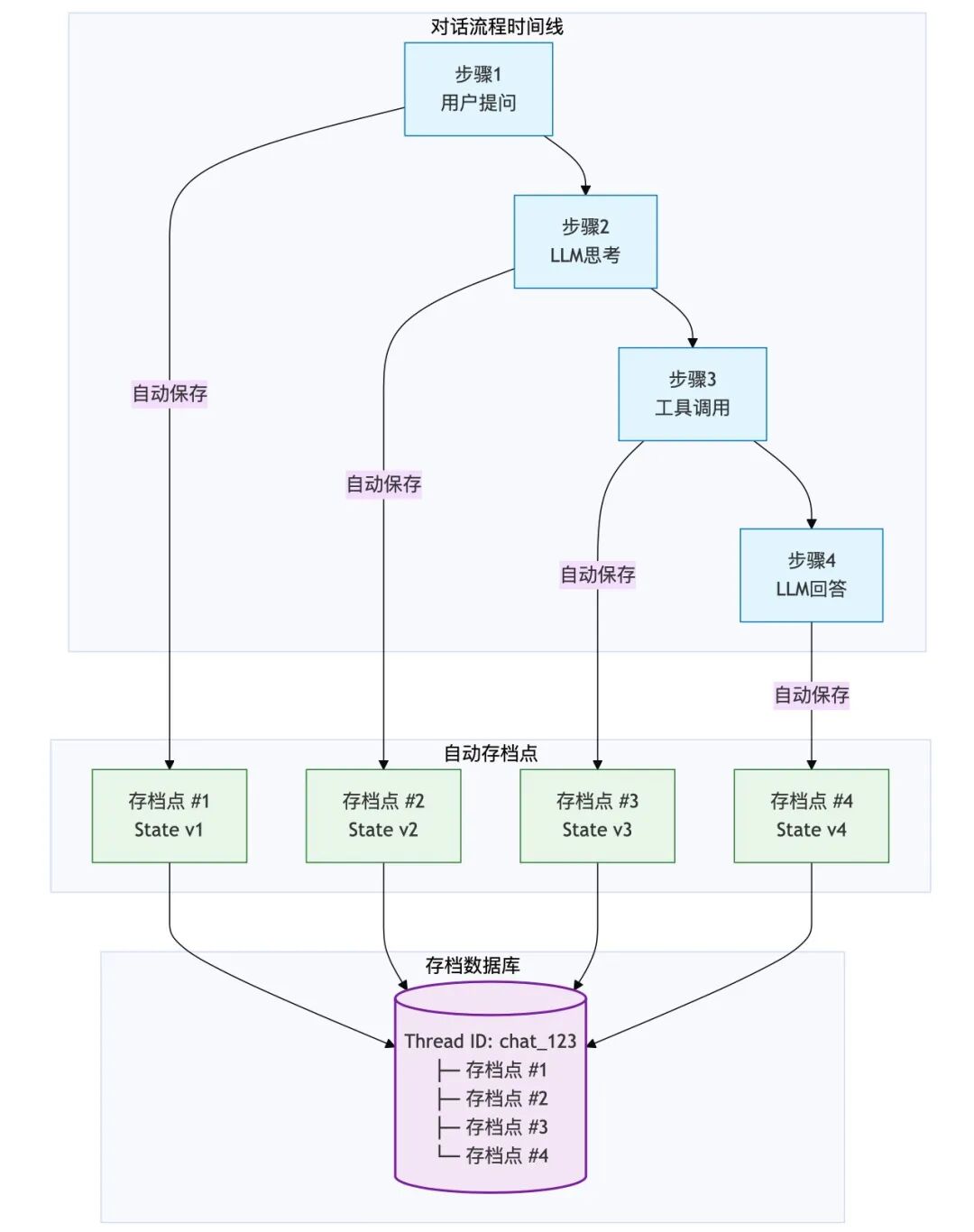
你可以把它理解为游戏的“自动存档”。图里的每一步操作(比如 LLM 刚说完话,或者工具刚查完数据),系统都会在后台默默地按一下 Save键。
它把当前的白板(State)冻结、打包,存进数据库(SQLite/Postgres)。
Thread ID:这就是你的**“存档栏位”**。只要拿着这个 ID,你随时可以读取这局游戏,从上次中断的地方继续玩。
- 人在环路 (Human-in-the-loop) 与 时间旅行
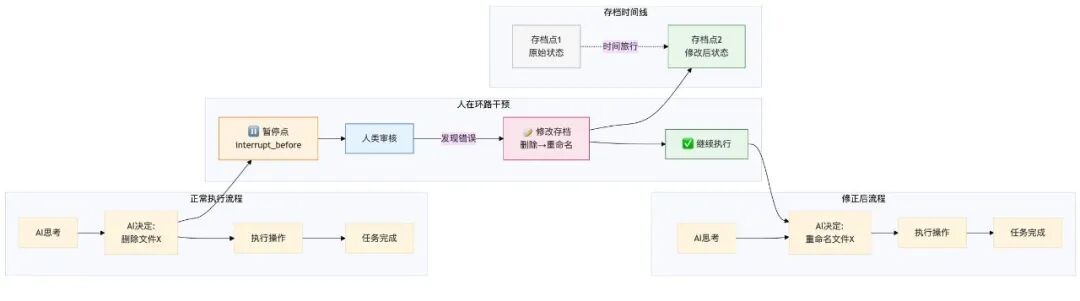
暂停键:设置 interrupt_before,就像告诉系统:“在执行这一步之前,先暂停,等我老板(人类)签字。”
上帝视角 (Time Travel):这是最酷的。假设 AI 打算调用工具删除文件,被你拦住了(暂停)。你发现它参数传错了。
在 LangGraph 中,你可以直接修改存档里的数据(比如把“删除”改成“重命名”),然后点“继续运行”。AI 会以为自己原本就是那么想的,继续执行修正后的任务。
价值:这不仅是容错,更是人机协作的最高境界——人类负责纠偏,AI 负责执行。
四、如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 10
10 0
0- 0



 已为社区贡献193条内容
已为社区贡献193条内容

所有评论(0)