RAG相关知识总结,适合新手全方位搞懂!
本文探讨了AI开发框架选型与RAG技术应用。在技术架构方面,介绍了Dify、LangChain和SpringAI三大框架特点,其中SpringAI基于Java生态,支持多种大模型接入。重点解析了RAG(检索增强生成)技术:通过将外部知识库向量化存储,结合用户问题检索相关信息,可有效避免AI幻觉问题。详细阐述了RAG的工作流程,包括文档分块、向量检索、知识图谱应用等关键技术环节,并强调了提示词设计对
一、技术架构选型
- AI框架有Dify、LangChain、SpringAI等,Dify是低代码AI应用开发平台,适合快速搭建;LangChain是基于Python的AI应用开发框架;SpringAI是Java与Spring生态的生成式人工智能框架,使Java语言通过SpringAI框架与大模型进行聊天对话,并且SpringAI倡导"一套接口,多种实现",一套代码针对各种模型,通过更改配置文件中各个大模型供应商的key即可。
- SpringAI构建在SpringBoot 3及以上,SpringBoot 3系列要求最低Java版本是JDK17,JDK是开发、编译、运行Java的核心工具包。
二、RAG相关知识拓展
2.1 什么是向量?
Embedding 是一种将文本(也可扩展至图像、视频)转换成数字向量的技术,这些向量表示了输入内容在语义空间中的位置,能够反映它们之间的相似度——向量距离越近,内容越相似。
为什么一定要向量存储?
因为LLM(大模型) 理解文本的方式,就是将文本转换为高维空间中的点——即向量。语义相似的文本,其语义在空间中的距离越相近。
2.2 为什么需要RAG?
当去问AI一些问题的时候,如果这个知识是模型在训练时是没有涉及到的,这个时候AI就会出现幻觉(看似合理但实则错误或虚构的信息)。
所以想要避免AI出现幻觉就需要让AI知道相关的知识。
检索增强生产 (RAG) 技术其核心价值在于,它以一种成本效益高且灵活的方式,为LLM连接了一个可实时更新的"外部知识库",从而提升AI应用的可靠性、时效性和专业性。
2.3 什么是RAG?
RAG (Retrieval-Augmented Generation) 检索增强生成。是一种结合 信息检索 和 文本生成 的大模型技术框架。它的核心思想是在 生成答案之前,先从外部知识库检索相关信息,结合Prompt提示词作为上下文,给到大模型来让模型生成更加准确、可控的回答。
2.4 RAG工作原理
首先,将外部提供的文档进行切分,切分成chunks,对每个块进行向量化,存入向量数据库中。其次将用户的问题转化为向量存入到向量数据库中,将用户的问题与知识库进行相似性检索,例如余弦相似度进行相似性检索,将检索到的内容结合Prompt提示词一起扔给大模型,由大模型给出更精确的回答。
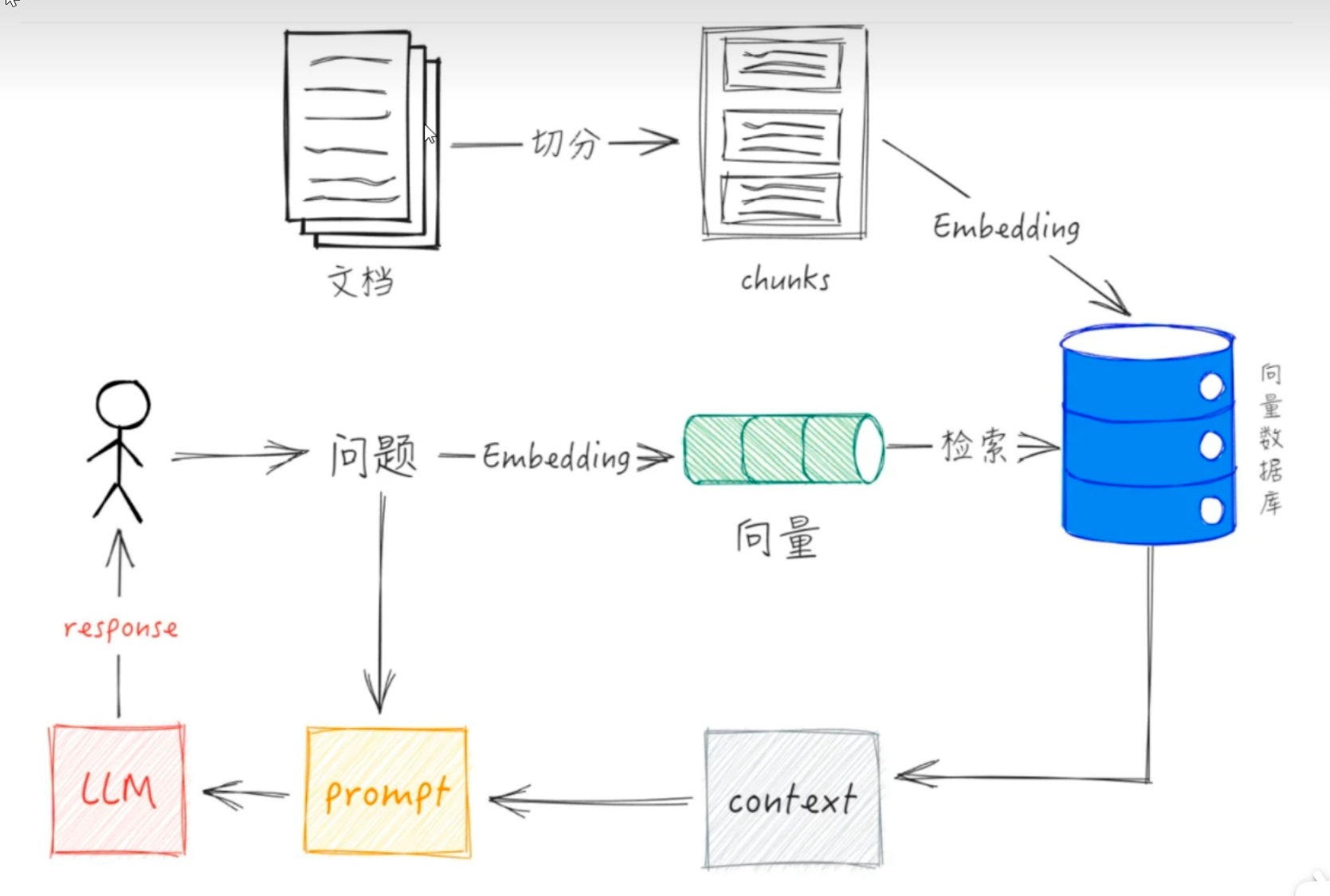
2.4.1 为什么分块?
- 大模型限制:输入长度是有限的
- 检索精度:避免检索到不想关的信息,提高检索精度
- 语义聚焦:不同模块需要独立分析和评估
2.4.2 分块方法
- 固定大小分块:按固定字数分割(200~500字符);——可能会导致语义不完整。
- 按句子或段落分块:使块的大小不均匀。
注意:最好的分块方法是让用户根据文档类型自行选择分块方法(没有一种分块方法能满足不同类型的文档)。
2.4.3 检索器
检索器:是指具体执行检索操作的技术或工具,即"用什么工具去捞"。
检索的内容在很大程度上直接决定了生成的质量,因此检索对于RAG至关重要,常用的检索方法有:
| 检索方法 | 核心原理 | 擅长解决的问题 | 优点 |
| 关键词搜索 | 词汇匹配 | 事实查找 | 简单高效、精确可控 |
| 向量检索 | 语义相似度 | 意图匹配 | 强大语义理解,发现潜在关联 |
| 知识图谱查询 | 关系与结构 | 关系推理 | 精准关联推理,可解释性极强,高效处理复杂查询 |
2.4.4 检索策略
检索策略:是指如何组织和使用一个或多个检索器来更有效地完成整个检索过程。即"怎么捞更聪明"。
- 迭代式检索:分多步走,逐步逼近答案。
- 自适应检索:智能切换,用对工具。路由决策机制。
2.4.3中的检索器都是单一检索有局限,混合检索 也叫融合检索,同时使用多种检索方式,然后将多种检索结果进行融合,得到最终的检索结果。充分利用多种检索方式的优势,弥补各种检索方式的不足。
2.4.5 RAG的三个关键问题
1. 检索什么:检索粒度可以是token、短语、chunk、段落或者知识图谱。
2. 什么时候检索:智能判定检索——自适应检索
3. 如何利用检索到的信息:上下文构建与提示工程
2.5 知识图谱 Knowledge Graph
定义:结构化语义知识库,通过图结构(节点-实体,边-关系)描述现实世界实体、概念及关联。
优点:
- 解决"数据孤岛"和"语义缺失"问题:
- 传统方式:数据存储在多个独立的表或文档中,缺乏联系。例如,一个表存员工信息,一个表存项目信息,但"谁参与了哪个项目"这种关系可能没有明确显示。
- 知识图谱:直接将实体和关系连接起来,明确表达了"A与B有何关系",让机器能"理解"数据背后的语义。
- 解决复杂关联查询的效率问题:
- 传统方式:多表联查,复杂且效率低。
- 知识图谱:多跳关联查询是其天然优势。沿着图的关系边遍历即可。
- 让机器具备"常识"和"推理"能力
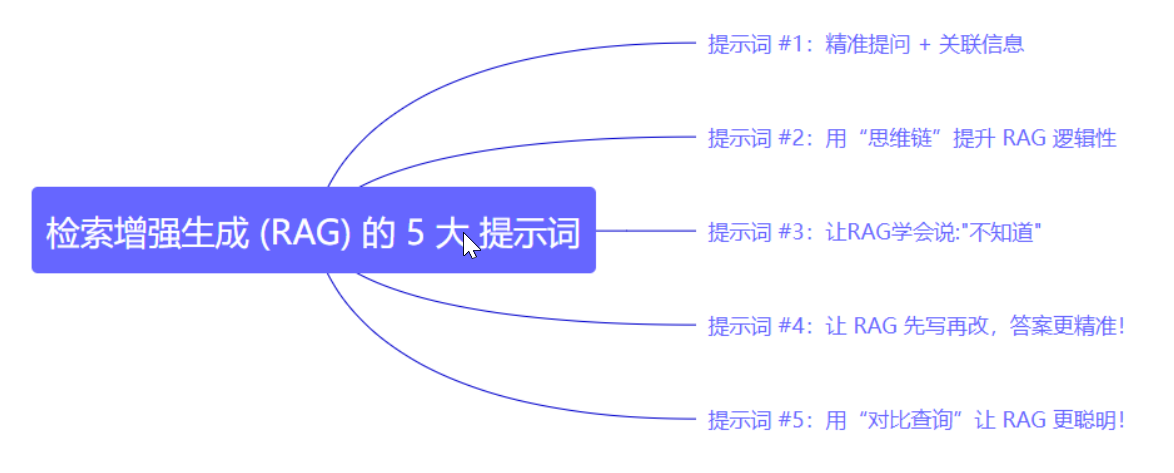
2.6 RAG提示词设计
2.6.1 什么是RAG提示词?
提示词是引导大模型利用知识库信息进行文本生成的关键因素。这需要一些技巧,比如如何组织上下文、如何要求模型避免幻觉、如何让模型在无法回答时说明等等。
2.6.2 为什么提示词对RAG这么重要?
跟RAG交流的方式,直接决定了它的回答质量。关乎于怎么让RAG给出更精准、可靠的答案。
想让RAG真的靠谱,提示词里得精准传达3件事:
- 检索到的信息怎么用:RAG不能只是拿到数据,还得理解怎么整合进回答里。
- 用户的具体需求是什么:RAG不能靠猜,需要明确告诉它方向。
- 推理逻辑怎么走:RAG需要知道该怎么组织信息,避免胡编乱造。
2.7 ChatMemory 聊天记忆
大模型是无状态的,不会自动保留先前对话信息。SpringAI中的ChatMemory主要用于管理对话上下文,可以将最近N次对话上下文信息保存在内存或者外部数据库中。默认N为20。
后期会继续更新新内容~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)