探索如何使用AI编程
第一次沟通没必要拘泥于细节,但是要让ai理解我们的目标。向AI表达“我是谁?我要做什么?,如果可以的话,尽量细化要做什么(分业务模块)。我们为一家计算机零部件制造企业建立一套采购系统,用于采购生产资料,以及公司运营所需的各类物品器材。整个系统所涉及的业务模块包括:- 供应商管理- 物料和品类管理- 组织架构和人员管理- 定价管理:已商定的某供应商的某种物料定价,暂不考虑折扣等功能- 合同管理:合同
零、前言
这是我一边学习trae的公开课一边写的心得体会。
如果你认为文章太长,只需重点关注各章节目录,以及不同颜色标注的内容。
大致了解每章要点,你就可以在需要的时候回顾它们。
我大量摘录了公开课中的内容(尤其是与ai交互的指令),我认为我需要重点学习的,是指挥ai工作的思路。即如何与它交互。
一、项目目标&架构规划
注意!作为一个规划者,保持克制!不要开始写代码!而是把问题沟通清楚!让你的下属知道该做什么!
-
我们要解决的业务问题是什么?
-
有哪些细节?
-
如何判定符合需求?
-
按照什么计划逐步完成?
阅读本章,你会发现,核心就在于:如何指挥产品经理、架构师、项目经理、测试经理为你工作。
注意!当他们提出了你认为可行的方案,你应该让他们整理为文档,这将方便后续的工作!(想想你的领导是如何让你规范地整理文档的?🤣)
本章结束后,你应该拿到了自己的设计文档、排期文档、测试文档。
现在,考验一下自己,是否能成为一个合格的指挥者吧~🤷♀️
1.1、让ai理解你的需求
1.1.1、需求概述
第一次沟通没必要拘泥于细节,但是要让ai理解我们的目标。
向AI表达“我是谁?我要做什么?”,如果可以的话,尽量细化要做什么(分业务模块)。
如:
我们为一家计算机零部件制造企业建立一套采购系统,用于采购生产资料,以及公司运营所需的各类物品器材。整个系统所涉及的业务模块包括:
- 供应商管理
- 物料和品类管理
- 组织架构和人员管理
- 定价管理:已商定的某供应商的某种物料定价,暂不考虑折扣等功能
- 合同管理:合同数据存放在系统中,并且支持导出为PDF文件
其中,合同部分需要支持一定程度的结构可扩展性,目前包含的合同类型包含:
- NDA保密协议:需要能够导出纯文本PDF
- 多物品采购合同:需要能够导出包含采购条目细节(名称,单价,数量,总价),以及整个合同内容的PDF
请协助给出产品文档。1.1.2、需求范围澄清
对ai输出的文档,我们要进行确认,如同一个leader与下属对齐方案一样,确认ai所想的内容与你一致。这一步至关重要!!如果不看好它,后续就不得不付出很多成本纠正它的代码。
比如ai设计了一套复杂的权限管理,我们要告诉它去除哪些部分:
我们这里的案例相对比较简单,需要对方案做简化,比如说,不需要做采购申请,单角色(采购员)登录,也不需要比价之类的业务特点,也不需要邮件通知。ai会根据你的要求进行修改。
除此之外,还有一些额外的信息需要补充:
- 业务边界:哪些系统已存在,不需要额外开发?哪些需要集成进来?
- 可扩展性:业务预期会在哪里进行扩展?
- 新的资产类型
- 新的业务流程
- 新的定价结构
- 性能标准:预期有多少人用?qps?业务量大吗?
1.1.3、文档留痕
完成上述工作,直到生成一份你认为满意的结果,要求ai把它输出为文档。作为后续开发和沟通的依据。这很重要!!避免ai在多轮对话后丢失上下文信息。
1.2、与ai讨论我们的技术架构
实际的业务系统是复杂的,因此架构上也会有复杂之处
1.2.1、边界条件的确认
对于一些可能出现功能复杂、性能要求高、扩展性要求高的部分,单独追问。
如:
那么,我们的合同模板是如何管理的?因为每种不同的合同,它对应的模板并不一样,需要单独管理,模板可以考虑用 HTML 模板代替,支持变量替换,数组迭代,条件表达式等等,但是需要单独管理起来。
请回答此问题之后,等待指令。这样ai就能帮助我们完善细节:
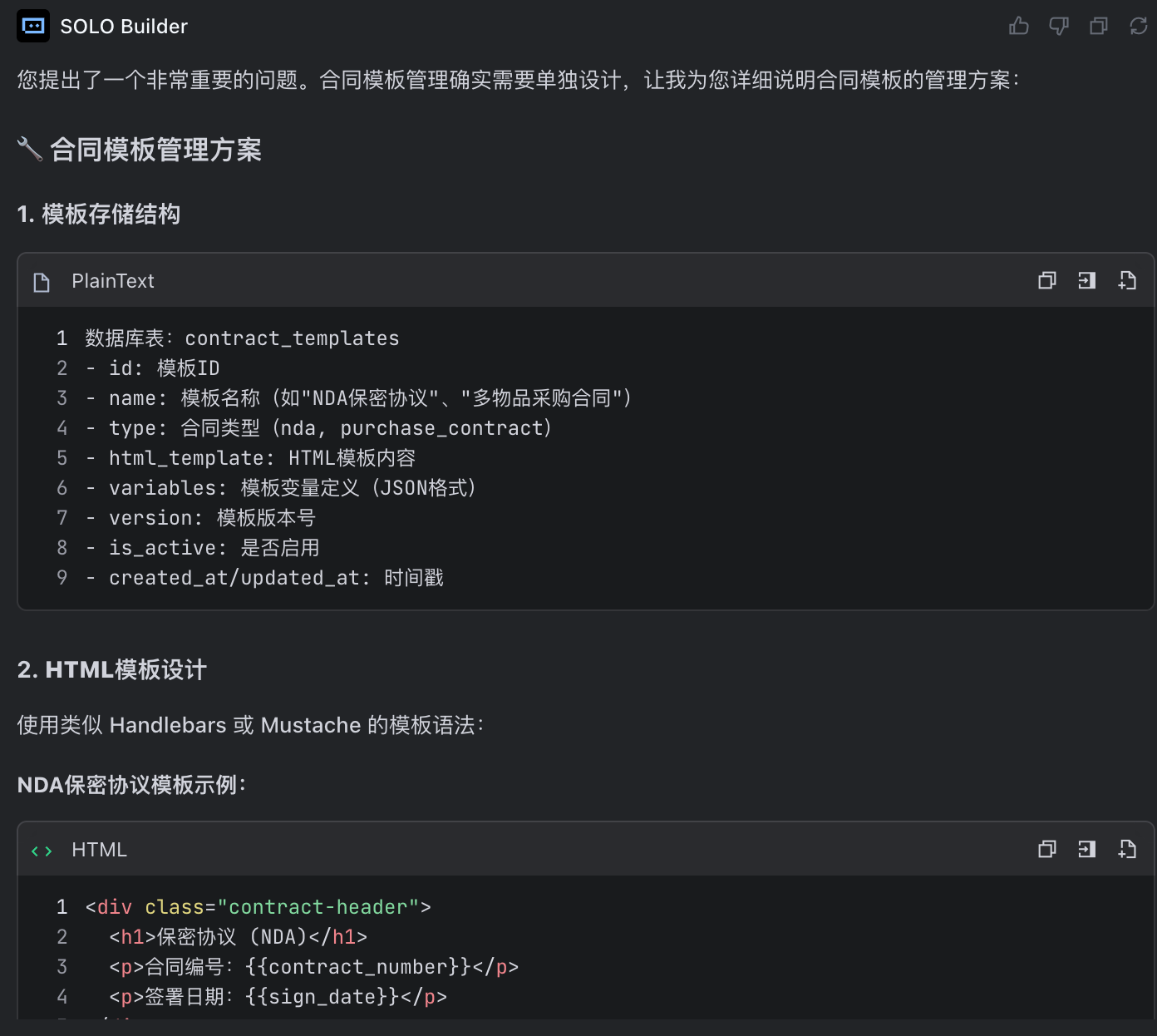
还是那句话:作为一个规划者,保持克制!不要开始写代码!而是把问题沟通清楚!让你的下属知道该做什么!
1.2.2、细节的确认
比如我们的业务模型关系图,务必仔细研究,这是整个系统的核心,需要确保它们之间的关系是符合业务状况的。
如:
技术方案里面,物料跟物料品类似乎没有建关联关系。ai修改后:
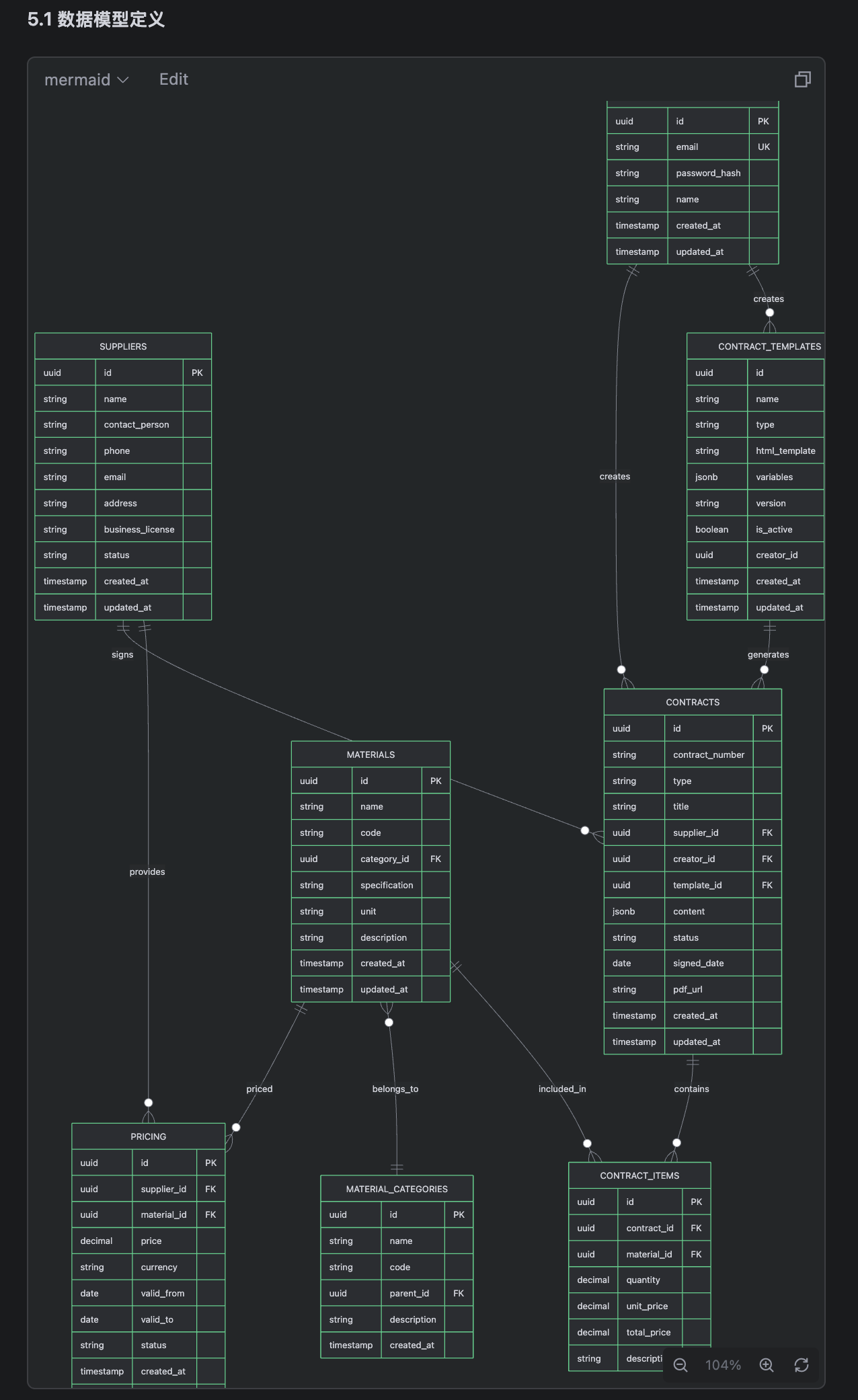
1.3、与ai讨论我们该如何施工
一个工程项目的施工节奏很重要,作为一个规划者,我们希望项目按照依赖关系逐步推进,并且使得其中一些部分可以并行开发。
如果你没有经验,可以先问问ai:
推荐的项目实施路径是什么?需要考虑依赖关系。AI 给出的结果不一定固定,也可以按照自己的判断,适当给出一点调整建议,注意调整之前,可以先询问 AI 是否合理。如果没有意外,我们做任何调整之前,最好都询问 AI 是否合理,这样反复推敲,得到相对更加可实施的方案。
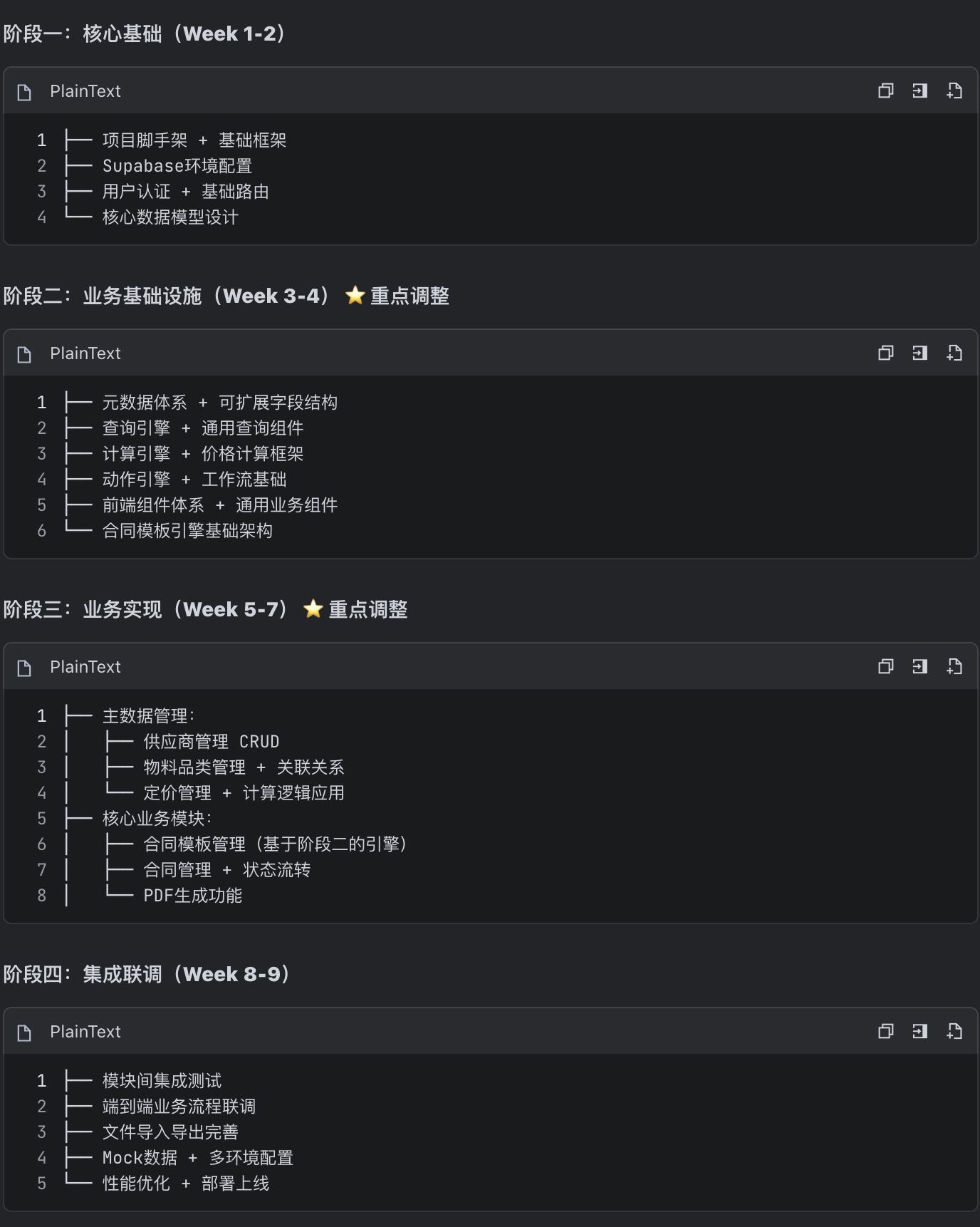
这里只是一个比较粗的方案,实际执行的时候我们还是再有机会调整。
1.4、与ai讨论我们的验收标准
根据需求,把希望的验收方式和验收流程给出来,初步得到这样的一个结果,也有对应的文档输出。

二、架构确认&初步开发
在施工前,我们要设置框架约定(想想你的领导是如何要求你按规范工作的😎),意义是用于保障行为一致性,使得不同模块成为一个整体。
本章结束后,你应该拿到了自己的项目结构文档(你也应该试试用ai为自己的老项目梳理对应的文档),也制定了一系列的rule让ai遵守。
2.1、项目脚手架&关键技术选型
2.1.1、多包结构
Trea推荐的项目代码结构是 mono-repo,在一个大的仓库中,用很多个小库来维护独立的功能。这样的好处主要是要强化模块之间的依赖关系,因为现在的 AI 有时候不擅长维护代码的依赖链路,经常写出反转的依赖关系,比如在基础框架中依赖业务模块,或者是上层模块中依赖底层包。
当我们建立比较严格的多包结构之后,跨目录的引用就不太容易被随意改成不正确的依赖关系,构建链路是有顺序的,很容易发现这类问题。
提示词:
当前项目是一个采购系统,已经进行了一些初始的文档规划:.trae/documents
现在需要基于 pnpm workspace 建立一套 mono repo 结构,以隔离不同职责的模块结构:
- log:统一的日志库,可以注入到不同的执行环境
- mock:针对业务数据进行的 mock 封装机制
- request:网络请求的封装,给前端组件用
- db: 对于 supabase 读写操作的接口封装,主要考虑查询
- env-config: 对于不同运行环境的封装,比如 supabase,在开发阶段使用本地的,到最后发布才使用线上的
- components 前端的组件库
- pdf
等等,还有业务的前后端。主要是列出合理的目录结构,并且建立依赖关系,不急于创建代码,着重给出整体的细节结构文档,明确说明每个模块职责。
请给出这个文档。你看,这里我会交代ai:参考前面生成的文档,且不要急于代码开发,继续给出细节文档。
得到的反馈,除了一篇文档之外,主要的总结如下:

2.1.2、模块与依赖关系
但是我们查看文档,发现了一些问题,主要是依赖关系方面存在一些导致。
注意,在依赖关系中,需要特别注意的是,公共技术模块不应当依赖业务模块。
还有技术选型上也有一些我们自己的偏好,所以给出反馈:
- 使用 vite 而不是 turbo
- http 请求要考虑包含 react hook 的机制,或者这里是否需要再次拆包?
- db 这里,要考虑把业务 repo 代码和 db 机制做隔离,是否需要做一些分拆?
- utils 为什么会依赖 types?types 是否需要拆分成 types 跟 contracts,一部分是业务无关的,一部分是业务前后端契约?或者你有其他建议吗?
另外,解释一下 env-config 是如何切换依赖项的?
这些沟通完,等待指令然后就可以让 AI 给出这些模块的依赖关系图,便于判断。
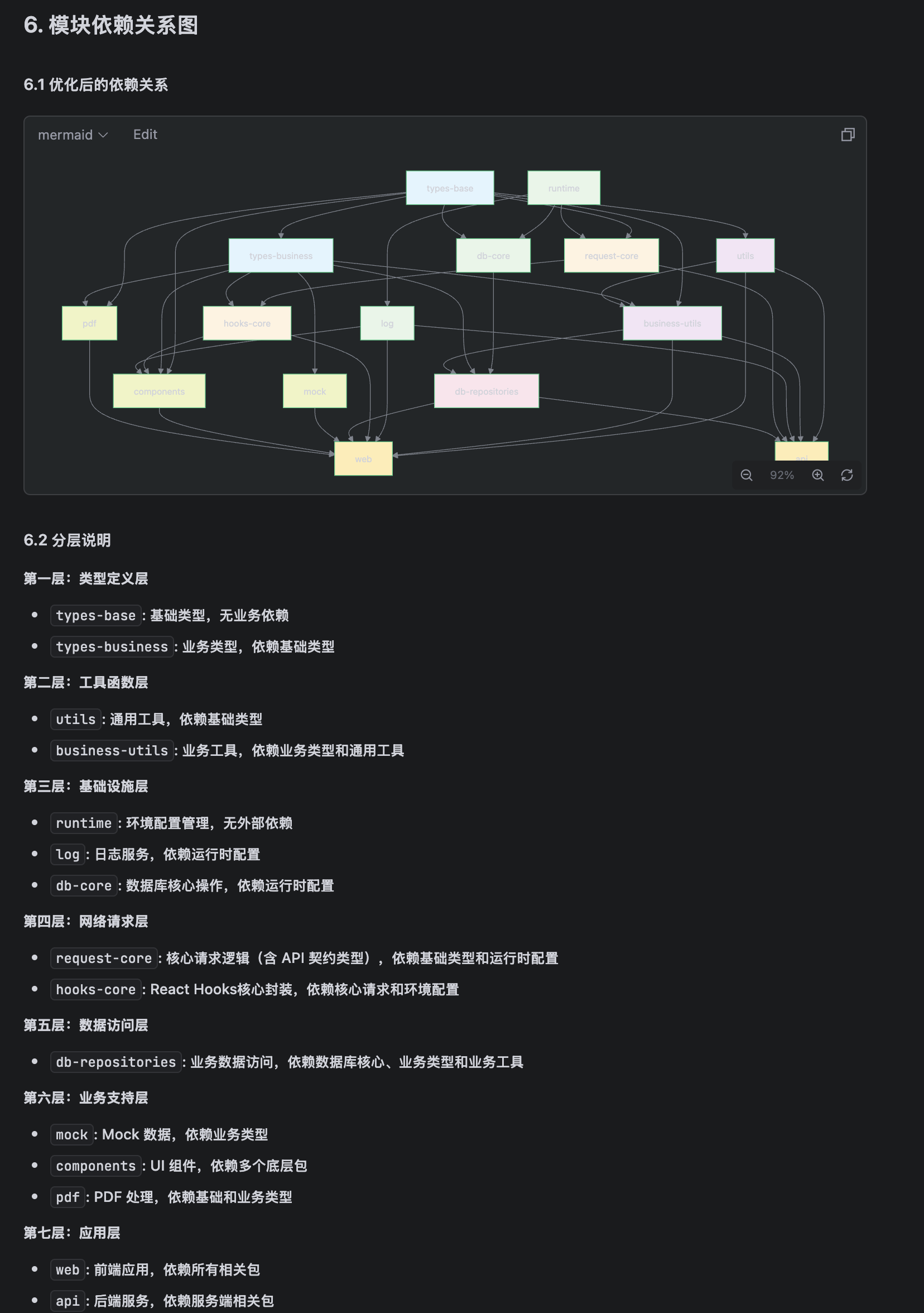
这方面只是一个参考,主要是看看有没有东西在特别不合理的位置就可以。
2.1.3、关键的技术选型
一般在关键技术选项这里,只需要把比较关键的偏好说出来(也就是你自己会的😂),比如说,希望采用什么数据库,什么前后端框架,什么部署环境等等,如果没有特殊偏好,也可以都让 AI 决定,它一般会选择比较流行的方案。
2.2、规则&指引
2.2.1、rule的编写
在 AI 编程时代,项目一般需要一些规则来作为约束条件。
比如:
-
使用严格的 TypeScript 来编写代码,每个库都配置尽可能严格的 lint 规则
-
每个功能点都需要包含完整的测试,功能开发完成之后,需要自行完成 lint 和测试
-
一切涉及架构准则和架构调整相关的事项,请详细阅读架构文档目录中的文档再作决定
这方面,我们如果自己写不出来,可以去网络上搜,或者直接让 AI 写:
接下来我们需要你协助生成一个项目中的规则文件,用于给 ide 提供代码风格约束,主要是给 ai agent 使用的。不用太长,大概十行左右。得到的输出是:
# AI Agent 代码风格规则
## 核心约束规则
1. **文件命名**: 使用 kebab-case,组件文件使用 PascalCase.tsx
2. **包引用**: 使用 `@vibe-purchase/` 前缀引用内部包,如
`@vibe-purchase/types-base`
3. **导入顺序**: 外部库 → 内部包 → 相对路径,用空行分隔
4. **组件命名**: React 组件使用 PascalCase,hooks 使用 use 前缀
5. **类型定义**: 接口使用 I 前缀,类型使用 T 前缀,枚举使用 E 前缀
6. **目录结构**: 遵循 monorepo 包结构,业务代码放在对应包中
7. **函数命名**: 使用 camelCase,纯函数优先,避免副作用
8. **常量命名**: 使用 UPPER_SNAKE_CASE,导出常量放在文件顶部
9. **错误处理**: 使用 Result 类型或 try-catch,避免静默失败
10. **注释规范**: 使用 JSDoc 格式,重点说明业务逻辑和复杂算法
我们把它配置到当前项目的规则中去。
这是个激动人心的步骤~
因为有了它们,你的ai就准备好结合之前的文档开始施工了~
在此之前,你已经与ai进行了多轮沟通,敲定了大多数细节,接下来是动工的时刻了!
如果读到这里你已经感到疲惫,建议休息一下,准备迎接后续的重点。
2.2.2、架构文档的统一管理
由于规则文件的大小有限,其他的一些设计说明,需要单独管理,目前的 AI 一般都有自行查阅文档的能力,所以,只需在规则文件中提到这方面就可以了。(但是这不能完全避免有些情况下,AI 不遵守架构规范,可以作一些事后检查)
2.3、基础模块的实现
让ai开始coding吧!~
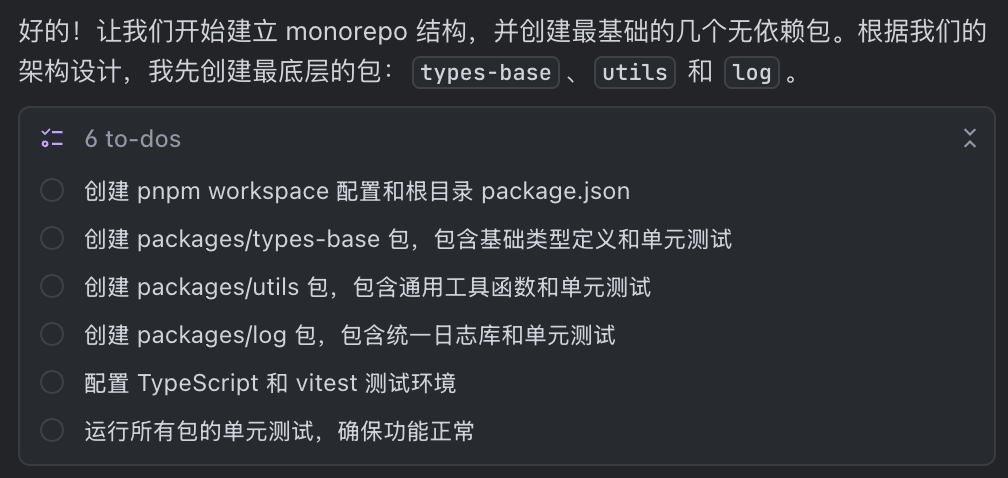
这样的话,我们先开始建立多包结构吧,第一阶段只关注建立包结构,并且,把最小的两三个没有依赖的包创建出来,并且编写足够的单元测试,使用 vitest 来测试。一个规划者怎么让ai为你coding呢?注意上面的指令,第一阶段,我们要它关注建立包结构。
于是 AI 开始执行,它挑选了其中几个最简单的,跟其他库没有关系的包出来实现。
我们这里再补充一些说明:
不要忘记: 我们为整个代码配置相对比较严格的 lint 规则。在真人项目中,我们往往不会把 lint 配置到最严格,因为对人的要求很高。但是 lint 严格是有助于 AI 把代码当场就写得规范的,所以我们选择这样做。
ai在coding后,为我们提供了一段总结:

注意这里,我再次反问它:
看看lint是不是都通过了结果它自测时候,发现还是很多问题,这是很常见的 AI 幻觉,我们在每一步,都尽量反问一下,让它再自我检查,确保:
-
lint 合格
-
类型检查合格
-
关键模块全部有测试,并且全部通过
最终,反复沟通等待之后,我们得到结果:

三、进一步的coding
基础的模块搭建好了,现在我们要进一步为项目添砖加瓦。但是从哪个模块开始施工呢?我们要ai给出它的思路。并与ai一起探讨其思路的可行性。注意!向它说清楚:只要方案,不要立即动手!
可以参考的指令如下:
当前,我们已经建立了一部分项目规划,完成了几个底层的基础设施包。
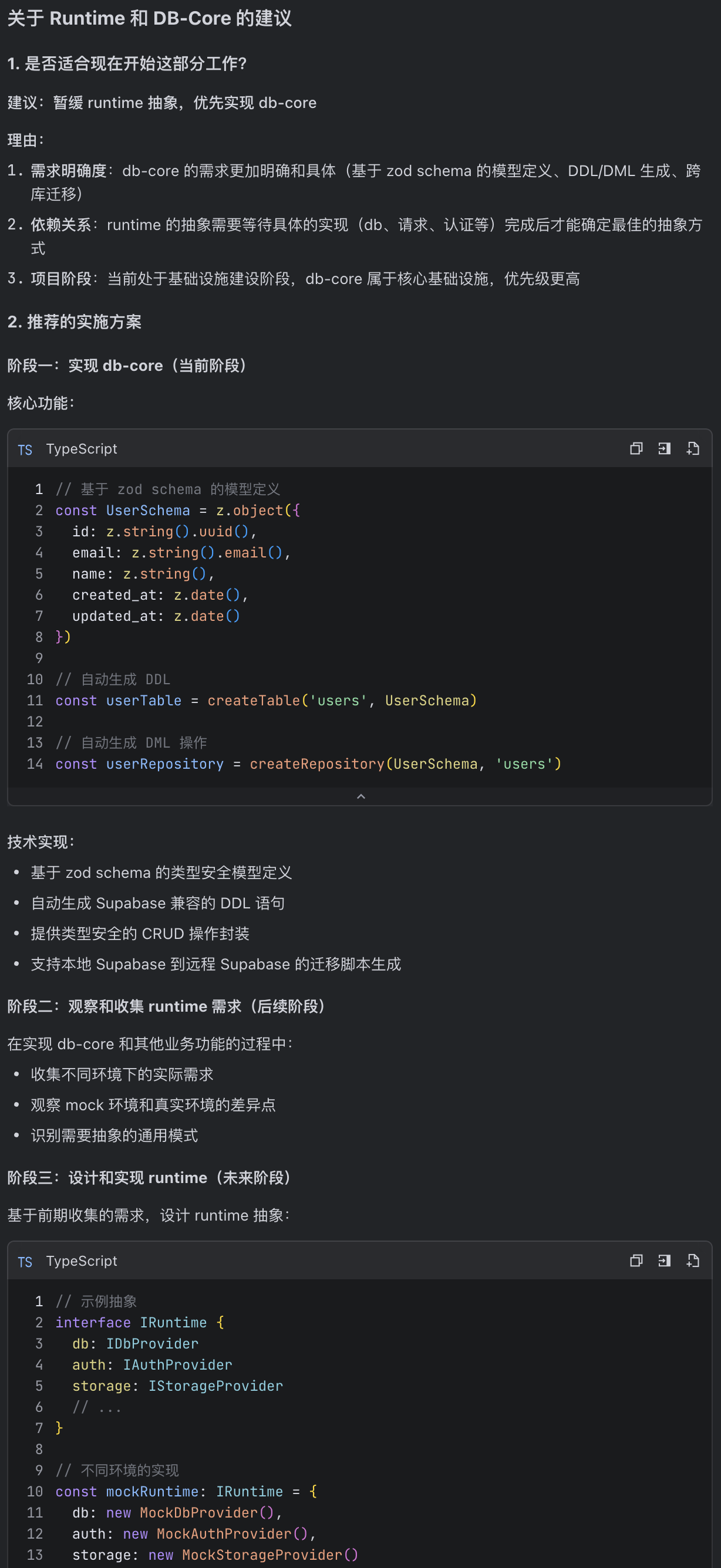
下一步,我们希望开始 runtime 和 db-core 的准备工作:
- runtime 主要是处理不同环境的统一抽象,比如说,我们可能会建立一个 mock 环境给前端使用,这个环境下,后端不会真正请求数据库,而是切换到专门的 mock 库来处理请求,而真实环境下会使用数据库。这个库主要侧重于对于不同环境的抽象,不处理具体的 mock 或者数据库操作等功能,然后我们将来会有不同的库来实现他它们。
- db-core 主要是对于非业务性 db 操作的统一封装,我们希望有一套基于 zod schema 的模型定义机制,然后,这套机制能够让我们生成 ddl 和 dml 操作,以及未来的跨库迁移,因为我们开发的时候在本地 supabase,但是将来上线之后,要整体切换到远程的 supabase。
我需要给出一个建议:是否应该先对 runtime 做一个抽象,然后实现一个 runtime 管理器,然后,等待 db、请求、认证等等库做完之后,再分别封装成不同的 runtime?
这部分请给出比较合理的方案,说明当前阶段是否适合开始这部分工作,以及详细的建议,并且等待下一步指令。得到的反馈是:
本章结束后,你主要应该理解,如何一步步指挥ai工作。
3.1、数据结构层
ai给我们的建议是先实现数据结构层,显然,这也符合我们日常的编码习惯。既然我们与ai达成了共识,就开始实践吧!
如何实践?当然是与ai继续探讨更多的细节~作为规划者,亲自动手coding永远是下策😎
3.1.1、架构探讨
接下来,我们跟 AI 进行一些这方面的探讨,希望它给出对于数据库访问层的技术设计,得到这么一些结果:
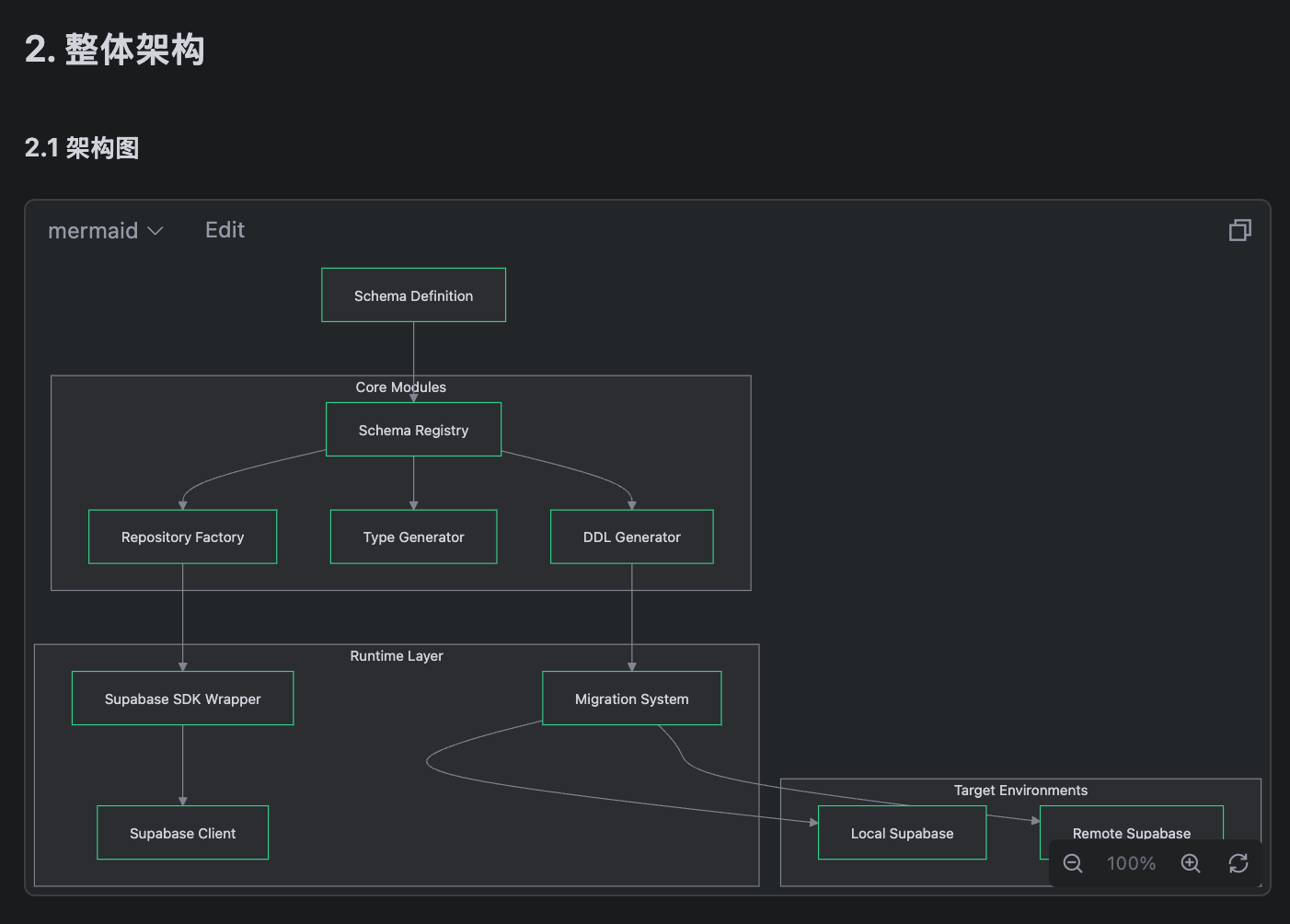

有些地方可能过度设计了,有些地方可能看不懂,这都是正常的,重点是不断地探讨方案细节。一旦达成了共识,记得让ai在项目文档中将结论记录下来。用人类的话说叫工作留痕,用ai的话说叫避免多轮会话后上下文丢失。
在这里,我们提出一些建议:
有一些东西不用做得太复杂,比如 query builder 之类,这方面可以对 supabase sdk 做简单封装就可以了,复用它的类型,这样如何?暂时忽略一些比较深度的内容,从最基本的功能做起,先迭代一次。3.3.2、开发过程
“如果有一些经验,可以在开发过程中注意观察,提出自己的建议,如果这方面不太擅长,也可以不用特别在意。”
上文是Trea公开课中的原文。引用这段话的意图是说明:即使完全不懂编程也可以指挥ai进行coding。所以不到万不得已,不要自己coding。
下面是一些与ai的对话。核心要点是:
- 用你的知识完善它的实现细节
- 常规性地要求它自测代码

注意,AI 经常不正确地进行总结,需要经常要求它再验证一遍,往往可以发现尚未解决的问题。另外,每个库开发完成的时候,可以顺便把当前项目的所有测试都运行一遍,防止把其他已经稳定的模块改出问题。
3.2、网络请求
下面我们要实现的是网络请求,之所以实现它,原因和数据层一样,它对其他模块的依赖不多。
3.2.1、架构探讨
还是老套路:任何coding的前置工作都是与ai进行讨论。
接下来,我们考虑进行网络请求库的开发,之前预先规划过这方面的内容:
采购系统Monorepo项目结构文档.md 678-724
请看一下有没有什么要调整的?另外,如果我们需要给前端提供合适的 react hook,这部分应该如何处理,跟当前的 request 放在一起,还是在别的地方单独做?
以你的判断,这个库在整个应用架构中的位置是什么?是前后端之间,还是后端也会用到?
请给出比较详细的思考。注意上面对ai的请求,我们应该在与ai沟通的时候,让它查阅我们之前的文档。围绕之前讨论好的内容进行开发。
如果发生了变化,我们也要及时更新文档:
把当前的这些思考,更新到我们架构文档的合适位置,主要可能是架构文档,还有 monorepo 的这篇包结构文档。
另外,也可以单独再写一篇,把整个架构细节放在里面,然后,总体方案里面只是概要提及,这些都由你来控制。3.2.2、开发过程
开发的过程没什么可说的,和数据结构层类似:
- 监督ai在开发过程中不要跑偏。
- 开发完一个模块要编写单测验证。也可以让ai把老的单测再跑一遍,以防影响了老功能。
四、多环境的统一抽象
企业级的工程项目是存在环境隔离的。测试、预发、生产各不相同。
本章结束后,你应该了解如何用ai实现环境的隔离。
4.1、多环境架构
4.1.1、方案探讨
经典环节,总是在探讨🐱🏍(动嘴皮子就是指挥人干活的本质)。
首先我们需要确定,整体存在几个环境,分别用来做什么,主要的特征是什么,流转关系是什么?
细节可以让 AI 来思考,我们只需要提出要求:
当前我们的项目已经拥有了一部分文档,并且产出了质量比较可靠的一些底层包:packages
接下来,我们想要对运行环境作一个抽象:
我们假设一个系统需要建立多种不同的执行环境:mock, dev, prod
不同环境,有不同的网络连接和数据库配置,上层应用可以很便捷地切换这些环境,在调试、本地开发和正式部署之间切换,并且,我们也可以考虑多环境之间的迁移,比如数据库 ddl 等等。
这方面请考虑一下是否可行,给出一定的分析,并且结合我们当前规划的包结构,给出一个架构图,能够表明不同环境下的调用关系。AI 产生了一个文档,摘抄其关键部分如下:

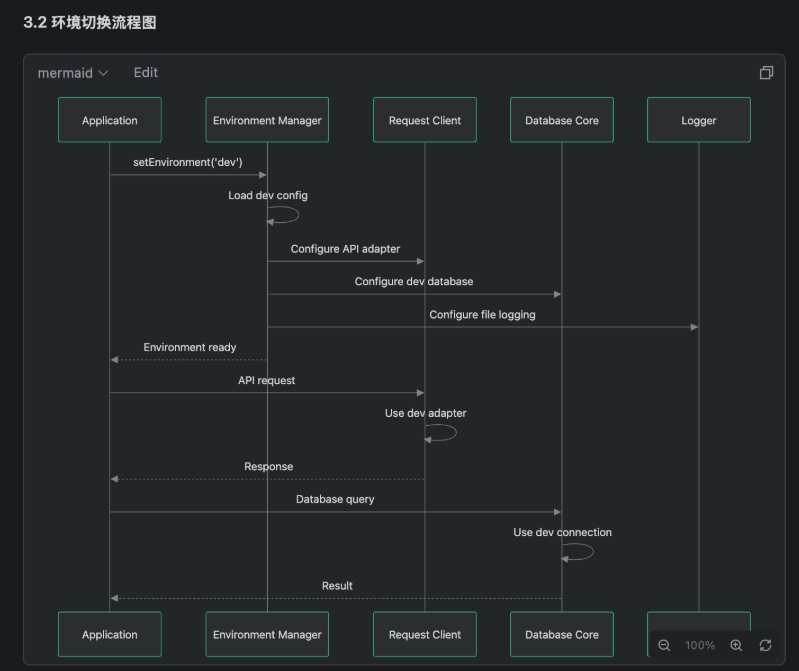
我们可以追问一些问题:
前后端各自对于多环境切换的代码,到时候放在它们各自的库中,是这样吗?AI 指出我的判断有误,给我作了合理的澄清:

进一步追问:
这样的话是可以的,所以你要改动四个包:
- 创建 env-config
- 修改 request, db-core, log
是吗?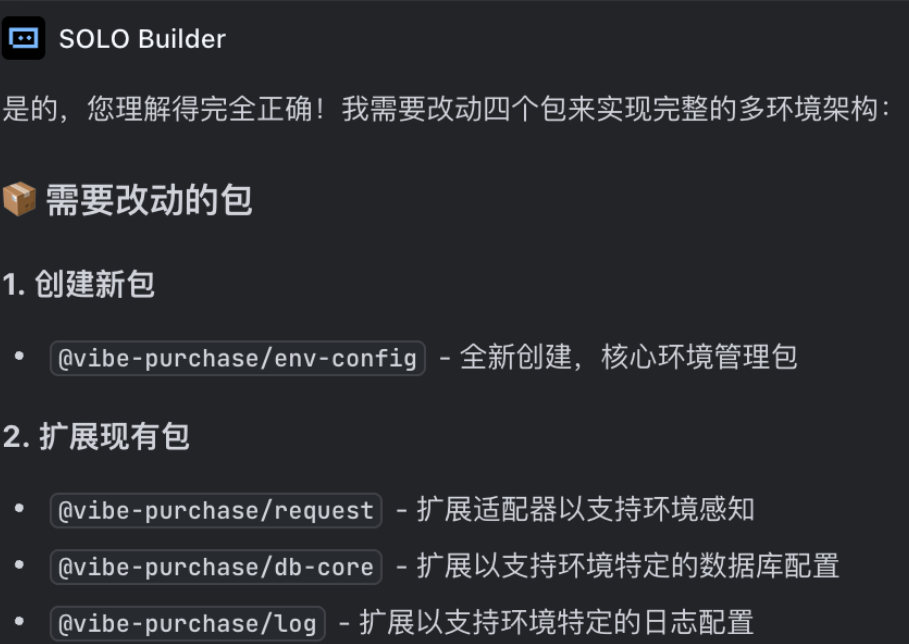
4.2.2、开发过程
执行之前,我们最好让 AI 给出打算产生的代码结构,以便进一步确认:
我觉得是可行的,接下来我们来开发这个多环境的包吧,开发之前,能不能先把你打算建立的文件结构发在对话里,我看一下是不是想要的接下来,就是常规的写代码,自测等等,反复执行,检查检测。最终,我们得到了完整的开发结果。
五、模型&元数据体系
业务建模是整个业务的根基。
一般来说,我们通过“模型”来表达业务实体,但是模型这个词有很多语义,比如说,它表达的是存储结构呢?还是业务领域的概念呢,还是某种传输结构的描述?
在比较简单的业务中,它们可以用相同的结构来表达,这些对于结构的描述,就是元数据。
本章结束后,你应该了解如何让ai帮你定义业务模型。
5.1、模型定义
5.1.1、方案探讨
接下来,我们把一些考虑跟 AI 表达出来,让它协助产生下一步的规划:
我们当前已经产生了许多文档,并且完成了这些模块的开发,接下来,考虑建立几个部分:
- 业务建模
- 建立为前端的业务组件开发,建立合适的 mock 环境
对于建模,我们有一个想法:
之前我们在 db 和前端 hook 库里面,分别定义了不同形态的结构,对于当前这个应用,由于不存在一些字段映射需求,所以考虑把这两层东西的作一些共享,所以我们需要考虑以什么方式定义业务模型。
我们会把业务模型定义在 model 包里,但是具体形式需要你来给出方案,它需要能够同时支持建立数据库结构,又能够作为网络请求的类型基准,其 schema 还要能够支撑基本的业务校验。
然后,在此基础上,mock 环境应该如何建立,也可以考虑一下。为了简化,mock 可以只适用于前端,所以可能能够把某种模拟数据的机制注入 hooks 就可以,比如使用 faker.js。
我们希望先探讨比较粗略的方案,暂时不展开太细它给出的答复摘要如下:

这里我们提出了一个意见:
注意到我们把 generator 也放在 models 包,这个我有不同意见,我们期望作更彻底的依赖分离,把工具层面的东西,跟定义分开,因为,model 这个部分可能会被各种地方引用,比如前端 hook,后端路由,数据库等等,工具生成器混合在这个包里面,有些不太好。
请给出与之相关的包结构的设计,以及各包的职责和依赖关系,注意,不需要展开包的文件内容,作一个初步展开,供沟通注意,AI 不太擅长作依赖关系的管理,这方面需要注意关注,多让它画图,从图上更容易看出问题。
它立刻认识到问题,并且给出改进方案:

我们追问一个问题:
那么,如果我们要对应用中的业务模型进行定义,它们又是如何组织的?它给出了一个答案:
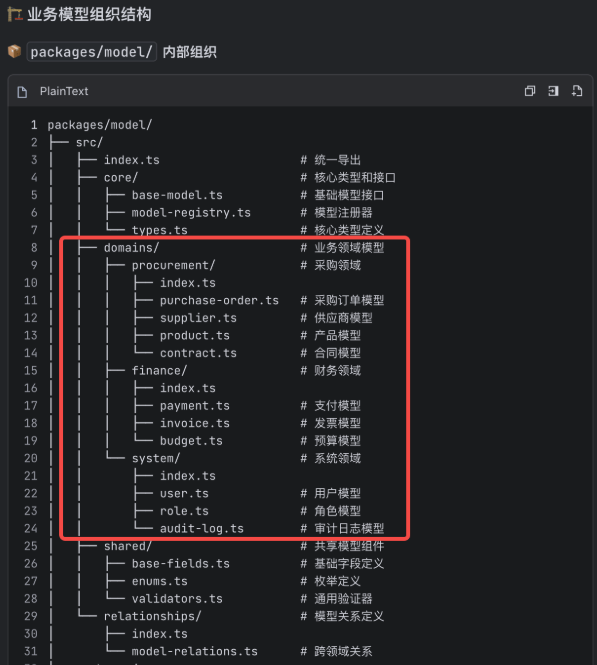
这意味着,业务模型跟模型机制放在一个包里了,这会导致有一些包的依赖关系出现问题,我们必须把这个问题继续探讨下去:
注意到你把业务模型的定义,跟模型这个机制的定义放在一个包里面了,这样可能依赖顺序是有一些问题的,请重新考虑这部分,并且尝试画出以上涉及的这些包的依赖关系图。
- model
- db-core
- env
- hooks-core
- hooks-business
- mock
此外,对于每个业务模型的mock数据定义,放在什么位置?再次调整,这次比较合理了,我们选择接受。

注意不要忘记把讨论结果记录下来
5.1.2、开发过程
接下来可以启动开发了。

注意到了吗?这里ai是按照《Model包与Mock环境实施方案》文档来进行开发的。这就是我强调了很多遍的,文档的重要性。
5.2、如何建立Mock数据
5.2.1、行为规范
在与 AI 协作的过程中,有一个问题需要很注意:AI 非常倾向于使用 mock 数据来临时完成任务,比如说,实际上根本不提交数据到后端或者写入数据库,直接在内存修改了之后就返回。 因此,我们需要制订一套流程用于阻止这种行为。我们的对策是:
-
主动设计并且制定整个项目的 mock 数据使用机制
-
并且在项目规则中,要求除了这种机制,禁止使用其他任何 mock 数据
5.2.2、具体措施
那么,如何建立 mock 机制呢?我们可以指定一下比较粗的要求:
需要能够根据每个不同的模型,建立模拟的读写机制
-
接口与正常的数据请求兼容
-
增删查改都要包含
-
数据格式按照 schema 来产生
-
尤其需要注意关联实体的处理
这样,再给它指定几种示例实体,比如,物料、物料品类、供应商、价格等等,供其在编写完代码之后,自测使用,基本上就可以了。
所以,结合前面的部分,我们可以很便利地在业务模型库里面把这些东西定义出来。
八、用ai做一个需求
为什么直接到第八章了呢?因为六、七两章是用ai实现一些前端组件。我看的不仔细。感兴趣的可以自己去搜搜看。
本章我们要实现一个功能点:在采购管理系统中,存在一些需要根据模板与数据合成 PDF 的需求。
这些都是很常见的业务功能,我们可以专门针对这个功能模块,单独开发一套包含前后端的工具包。
本节,我们设计的功能主要是为了认识到,如何把这么一个“代入模板”的业务功能抽象为业务链路,然后,再对链路中的步骤进行梳理,得到几个按照不同程度可以复用的库。
需要注意的是,在 AI 时代,我们的重点还是关注整个链路,给 AI 提出合理的测试要求,并且观测这些需求的测试结果,直到完成为止。
8.1、PDF 的生成与导出
8.1.1、流程与模块分析
从业务视角,合同 PDF 的导出经过以下步骤:
-
根据主键,获取对应的合同数据(比如,购买办公桌椅的多物品采购合同,包含购买细节)
-
基于这个合同的类型,获取对应的模板数据(多物品采购合同模板,但是没有具体的内容)
-
将合同数据与模板合成(这次买了多少,什么价格,都填充到模板里)
-
合成数据生成 PDF
所以,这里就可以得到需要进行技术设计的内容:
-
哪些内容需要做成库,供业务项目调用?(设计一个库的时候,先把数据的获取部分排除,只关注固定输入输出,不关心需要结合运行环境的读写部分)
-
如何定义合同模板?需要支持:
-
内容填充:需要标记出待填充的字段
-
条件判断:需要支持条件表达式
-
迭代器:需要支持迭代列表数据,比如购买了多项物品,需要展示成表格
-
-
如何验证结果?
-
设计几个场景来测试,并且观察结果
-
NDA 保密协议
-
单物品采购:一个主合同只包含一项物品的采购,计算逻辑简单
-
多物品采购:一个主合同包含多项物品采购,并且存在汇总逻辑
-
-
我们把这些需求告诉 AI,让它来判断,然后进行一些比较简单的沟通:
当前我们在做一个采购系统,已经有文档规划,并且产生了部分合格的代码包
接下来,我们考虑把另外一个预先考虑过的模块:基于模板的PDF库 实现出来,这部分,我们在之前的概要文档中有一部分描述:
采购系统Monorepo项目结构文档.md 1080-1134
接下来我们想要对这个包做比较详细的分析,期望它成为一个业务无感的模块,请你对这些已有的信息进行详细解读思考。可以得到一些关键结论:

注意到这个方案里,给出了两种 pdf 生成机制,这是比较奇怪的,因为我们其实只需要一种,所以需要询问原因。
react-pdf 跟 puppeteer 这些是同一个技术路径吗,还是说,这里存在多种不同的技术路径?AI 给出的答复是:
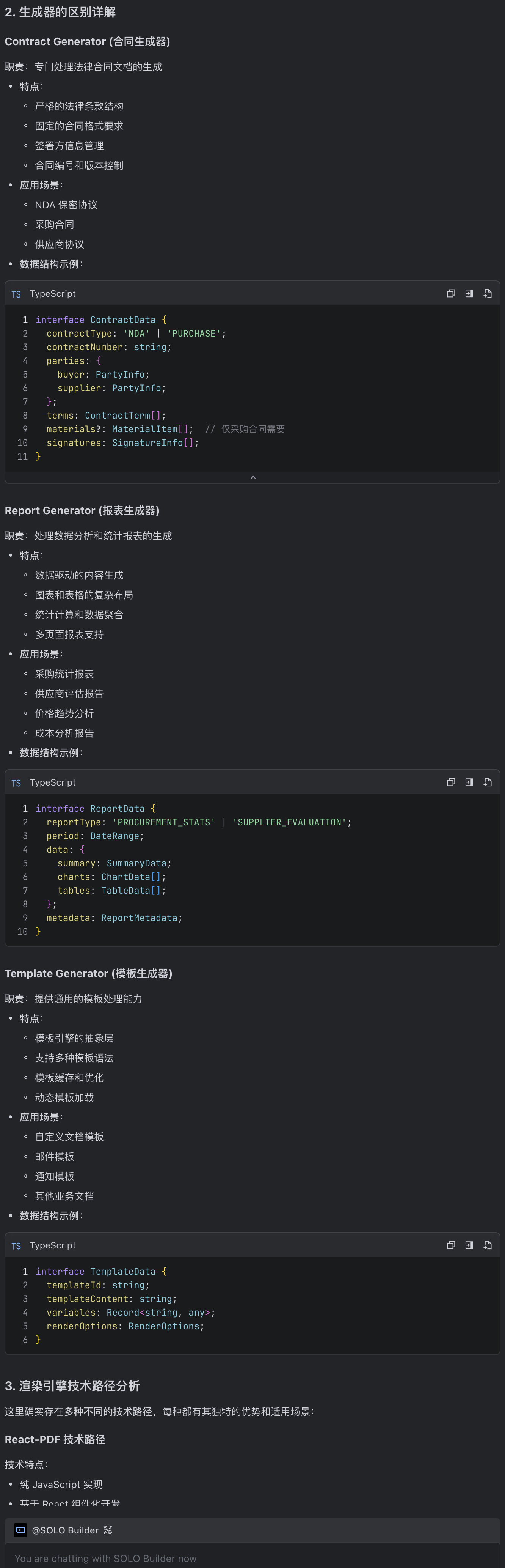
这明显不合理,因为我们只要生成合同,所以立刻澄清了。
我们并没有提到合同之外的 pdf 生成场景,请给出最直接的路径。
具体每种合同的结构,会在业务调用的时候传入,大致是这样:
- schema: zod 形态表达的合同 schema
- data,匹配于这种合同 schema 的合同数据
- template,对应这种合同的模板
除此之外还有什么需要考虑的?AI 立刻简化了技术方案,接下来我们就没有疑问了。
8.1.2、技术实现与结果检查
具体的开发部分,基本可以完全交给 AI 完成,我们只需要来关注验收的环节。
对于给出的业务案例,要求 AI 设计模板和测试数据,并且联合起来运行,产生结果文件。
最终,针对格式等等,可以继续提要求,直到完成为止,在这里的沟通,我们需要注意一些事项:
-
提醒 AI:模板中需要包含样式,每个模板的样式不一定相同
-
需要提前做一些数据格式转换方面的工作,比如数字、金额、时间的输出格式,这部分正好之前已经设计过
九、业务后端的实现
接下来,我们可以进行业务后端开发了。一般来说,后端开发都要建立分层概念,这里面通常有很多种方法论,我们这里选一种比较简单的,分两层:
-
数据仓储:针对每个业务实体,基于数据库,提供它的数据读写
-
API:提供 HTTP 接口,给前端调用
这是个比较简单的例子,实际的企业项目当然不可能只有两层。
这两层,我们打算使用两个库来实现。需要注意的是,我们之前进行过业务模型的定义,所以这里可以设计一些机制,把它们的定义使用起来。
整体沟通一下:
接下来,我们打算开发后端部分,这里面重点需要考虑几个部分:
至少需要两个库
- 一个处理 api,给前端提供响应
- 一个处理 business-repository 负责数据读写
需要重点注意的:两个部分都应该设计合理的上下文结构,支持可注入日志、环境等信息,这些在我们已有的其他包里存在了。
然后,注意 model 包,我们的 repository 和 api 库都应该读取它的 ModelRegistry,建立一个通用机制,基于它们产生 api,同时也允许自己用特有的逻辑来覆盖它们。
请先做详细的思考,给出合理的后端设计文档,我们不太倾向于做一个代码生成机制,而是希望做一种类似代理的机制,然后动态根据 model registry 做后续的响应。
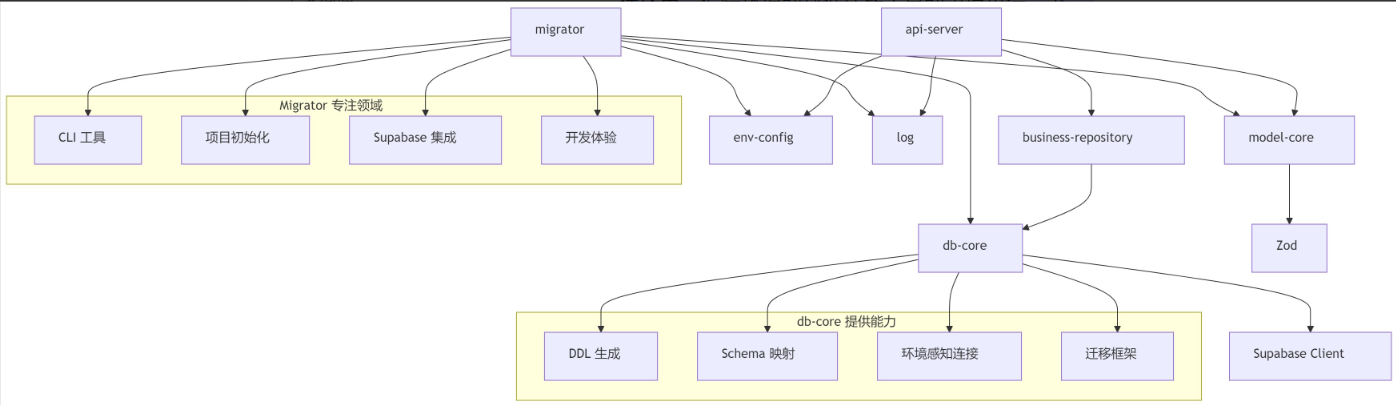
对于本地开发环境,我们需要自己通过 cli 建立 supabase,根据已经定义的模型,基于 db-core 来连接和访问它,创建表结构等等。这个过程需要考虑,我们可能会在某个 migrator 包里面去做。在这里,把跨环境的数据迁移工具的事情也提一下。
最终得到一个模块关系:
9.1、数据仓储
9.1.1、需求沟通
目标:
9.1.2、开发
准备开发测试时候,发现 AI 产生的都是 mock 测试,没有连接真实的数据库,所以补了提问:

接下来,我们又需要提醒,之前的多环境的上下文机制,有没有用起来?
直到做完。
9.2、API
9.2.1、需求沟通

看一下这篇文档中的 api-server 部分:.trae/documents/采购系统后端架构设计文档.md
我们打算启动开发,首先检查它的依赖项是否都具备了,当前我们已经有很多包了,它底层的 business-repository 也有了,接下来就是针对他们,进行一个动态 api 路由的设计。
我们根据 model registry 的内容,动态代理 api 路由到指定的模型配置上,针对这个模型配置生成合理的接口,并且在底层适配到相应的 business-repository 接口。9.2.2、开发
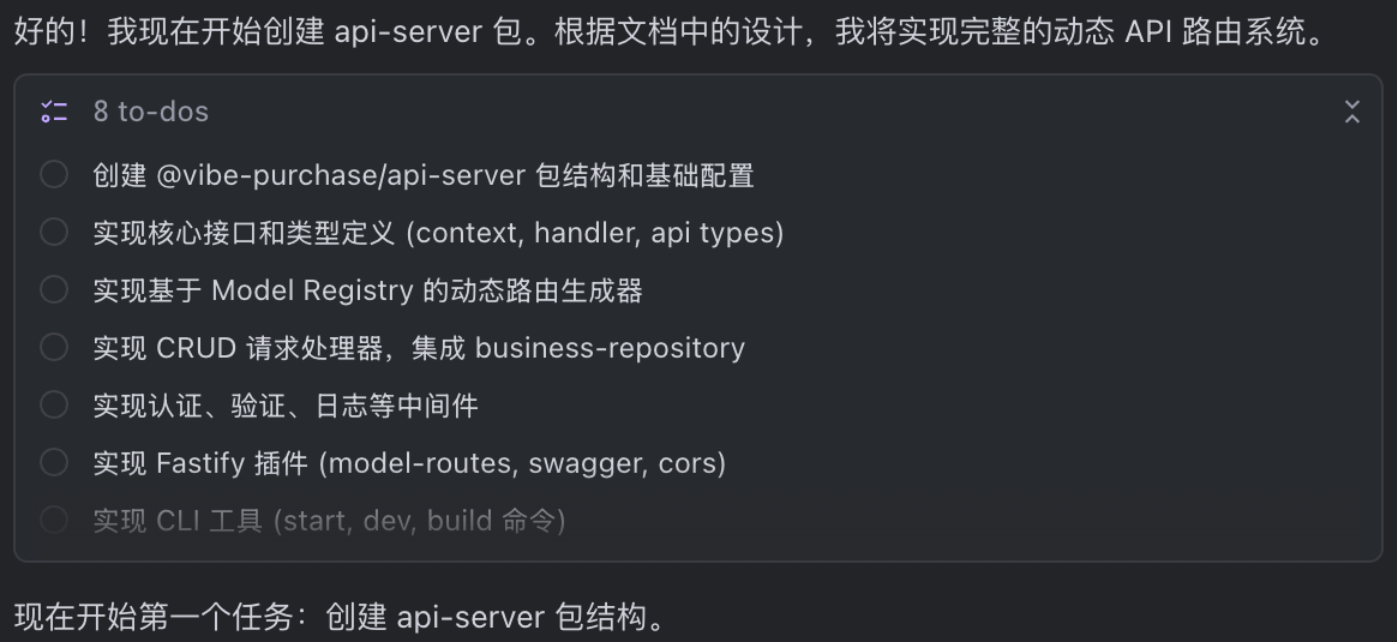
注意:API 库一定要做集成测试,通过数据仓储,连接真实的数据库,而不是 mock 数据库。
有可能 AI 给出总结的时候,还是有问题,可以反复询问:
-
是否真的完成了
-
连接的是本地数据库
-
是通过 repository-business 库连接的
-
两个库的集成测试都是完好的
-
类型也是全部修好的
9.2.3、在线的接口文档
传统开发模式下,后端完成开发任务之后,需要发布接口文档给前端或者客户端调用。在这里,我们也可以要求 AI 把后端做到这个程度。
具体可以这样沟通:
需要把 api-server 库的所有 api 全部产生 swagger 文档收到这个请求之后,AI 一般就会继续工作,直到最后启动一个服务,打开一个比较简单的页面,里面展示了当前开发完成的所有接口,包含名称、参数、返回结果等等,可以直接调用。
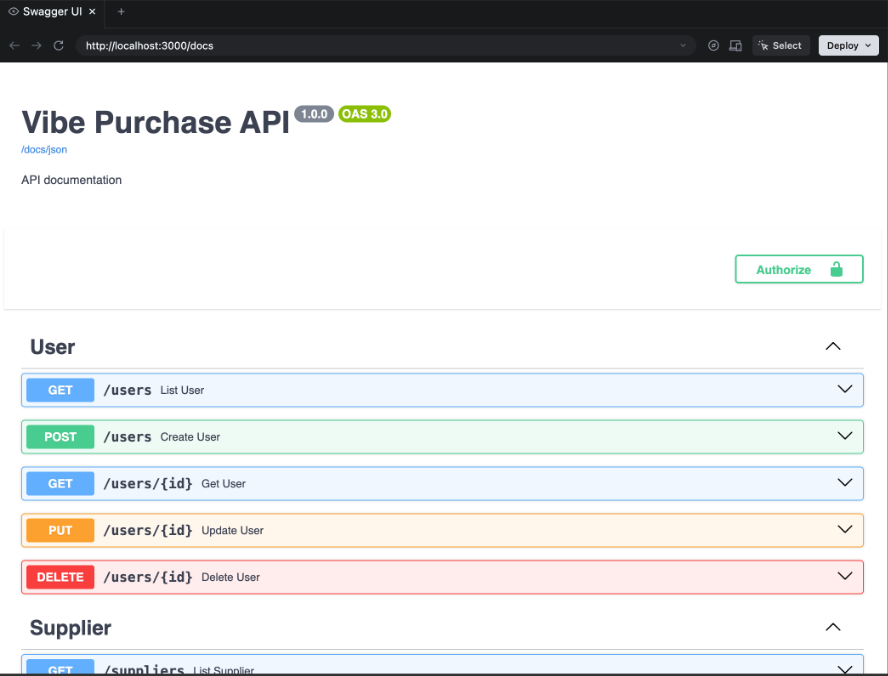
到这一步,就可以说明后端能够进入联调状态了。
十、后记
通过本次的学习,我认为:ai编程中,沟通、文档的沉淀、制定规范是重中之重。
在上面提到的流程里,主要的规划实际上是人在规划,比如,项目结构为什么要建成这样?为什么要划分这么一些库?库的内容为什么要这样组织?开发和调试过程为什么是这样的?
目前 AI 其实不太擅长这个领域,它自主规划很难考虑到业务扩展性之类的问题。
多 agent
我们在这个教程里,选择了直接使用 Trae 内置的 solo builder 或者 builder 来做任务,因此,AI 在执行任务的时候,完全是以通用角色的视角来执行任务,所以,每一块,相对缺少前置知识。如果我们想要让每个阶段更专业一些,可以采用多 agent 的方式。
所谓多 agent,就是创建多个不同的虚拟角色,每个角色有不同的技能和前置知识设定,下面是一些样例:
架构师
你是一名资深软件架构师,现在你负责进行软件的架构工作。你的侧重点主要是:业务软件的模型建立,流程梳理,并且考虑整个系统的边界情况,创建合理的,可执行的架构指引,让团队的其他角色能够细化执行。后端开发
你是一名资深后端开发工程师,你擅长 NodeJS 的各类框架,熟悉常见的后端知识。你的侧重点主要是:关注业务需求,理解架构文档,选取合适的技术栈,充分考虑可扩展性,并且编写良好的代码。你的所有代码都需要是严谨的,而且有详细的测试。前端开发
你是一名资深前端工程师,你有深刻的组件化思想,在业务开发过程中,懂得合理抽取业务组件,并且提前把它们固化起来备用。跟后端对接时,你需要重点关注业务模型和业务接口。在开发业务页面的时候,充分理解业务,理解页面和组件之间的组织关系。
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)