论文简读:Kwai Keye-VL-1.5 技术报告总结简版
Keye-VL-1.5,通过三项关键创新解决视频理解的根本挑战。首先,引入了一种新的慢速-快速视频编码策略,基于帧间相似性动态分配计算资源,在更高分辨率下处理具有显著视觉变化的关键帧(慢速路径),同时在较低分辨率下处理相对静态但时间覆盖范围更大的帧(快速路径)。其次,我们实施了渐进式四阶段预训练方法,系统地将模型的上下文长度从8K字扩展到128K字,从而支持更长视频和更复杂的视觉内容处理。第三,我

论文地址:https://ar5iv.labs.arxiv.org/html/2509.01563
github:https://github.com/Kwai-Keye/Keye
模型地址:https://huggingface.co/Kwai-Keye
开源时间:2025年9月7日
Keye-VL-1.5,通过三项关键创新解决视频理解的根本挑战。首先,引入了一种新的慢速-快速视频编码策略,基于帧间相似性动态分配计算资源,在更高分辨率下处理具有显著视觉变化的关键帧(慢速路径),同时在较低分辨率下处理相对静态但时间覆盖范围更大的帧(快速路径)。其次,我们实施了渐进式四阶段预训练方法,系统地将模型的上下文长度从8K字扩展到128K字,从而支持更长视频和更复杂的视觉内容处理。第三,我们开发了全面的培训后流程,重点关注推理增强和人类偏好对齐,包含五步思维链数据构建流程、基于GSPO的迭代强化学习,针对困难案例提供渐进式提示,以及对齐训练。
一、论文创新点
1. 模型结构
KwaiKeye-VL-1.5模型架构基于Qwen3-8B语言模型,并整合了源自开源SigLIP的视觉编码器。该模型支持SlowFast视频编码和原生动态分辨率,通过将图像分割为14x14的块序列来保持原始宽高比。随后,简单的 MLP 层对视觉标记进行映射和融合。模型采用3D RoPE技术对文本、图像和视频信息进行统一处理。
- 视觉编码器:基于SigLIP-400M-384-14初始化,融合1D插值与2D旋转位置编码(RoPE),采用NaViT打包与FlashAttention技术,支持原生动态分辨率处理,无需复杂图像拼接/分割操作。
- 跨模态投影层:随机初始化的MLP层,通过预训练阶段完成视觉特征与语言模型(Qwen3-8B)的对齐映射。
- 语言解码器:基于Qwen3-8B构建,引入3D RoPE实现文本、图像、视频信息的统一处理,支持128K超长上下文序列。
- Slow-Fast视频编码模块:双路径设计,通过补丁相似度函数(95%阈值)区分关键帧与静态帧,动态分配分辨率与时间覆盖资源。

2. 核心创新点
- 自适应视频编码:慢通道高分辨率处理视觉变化帧,快通道低分辨率覆盖静态帧,搭配时间戳令牌优化时序感知,解决空间分辨率与时间覆盖的权衡问题。
- 渐进式上下文扩展:预训练阶段从8K逐步扩展至128K令牌,结合 annealing 策略,确保长序列训练稳定性与能力迁移。
- 长链思维冷启动机制:五步法自动化构建高质量推理数据,融合OCR、数学等领域专家模型,快速提升复杂推理能力。
- 迭代式强化学习框架:采用GSPO算法,结合五级渐进式提示采样(概念→策略→工具→步骤→完整解决方案),高效利用难题样本优化模型。
- 三重奖励对齐系统:规则型(格式合规)、生成型(内容匹配)、模型型(人类偏好)奖励协同,提升指令遵循与用户体验。
二、训练过程
1. 数据处理过程
- 数据过滤:公开数据采用CLIP分数过滤(图像-文本对相似度≥0.9),低质量数据通过重描述重构;内部数据经人工标注与质量校验。
- 去重与去噪:图像级去重避免数据泄露,注入“陷阱问题”(非-existent/矛盾问题)减少文本先验依赖。
- 数据增强:多格式数据重构(如「图像+描述+问答」「图像+问答+描述」)、中文OCR数据合成(字体渲染、背景多样化)、视频帧级OCR标注与时序事件提取。
- 数据分配:128K上下文下,视频令牌占24%、图像占50%、文本占26%,平衡多模态能力。
2. 训练数据配置
- 数据规模:超1万亿令牌,涵盖六大核心类别:
- 图像描述数据:LAION、DataComp等公开数据+内部重描述数据,支持多轮问答扩展。
- OCR&VQA数据:Latex公式、手写文本、中文结构化文档等,含13类指令型OCR任务。
- 目标定位&计数数据:RefCoCo、VisualGenome等,支持中心点、边界框、多边形三种定位格式。
- 交错文本-图像数据:学术PDF、STEM结构化数据,保留文本-图像原始位置关系。
- 视频数据:开源数据集+快手内部短视频,含ASR对齐、帧重排、多视频匹配等任务。
- 纯文本数据:补充通用语义知识,保障LLM核心能力不退化。

3. 训练步骤
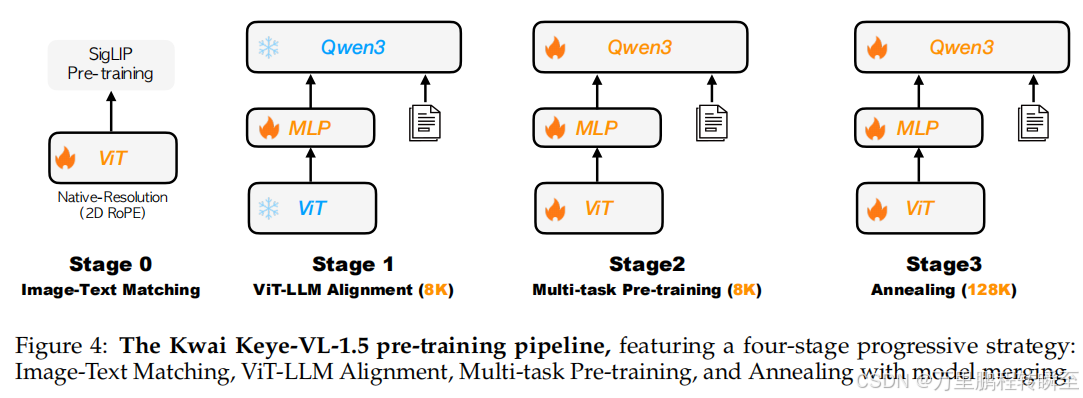
(1)预训练四阶段
- 阶段0(视觉编码器预训练):基于SigLIP损失函数优化,扩展动态分辨率适配能力,训练数据含500B令牌。
- 阶段1(跨模态对齐):冻结ViT与LLM参数,仅训练MLP投影层,建立视觉-语言特征映射。
- 阶段2(多任务预训练):解冻全参数,训练图像描述、OCR、定位等任务,提升基础视觉理解能力。
- 阶段3(退火与上下文扩展):扩展序列长度至128K,采用Zero-1优化与上下文并行策略,融合高-quality长模态数据。
(2)后训练三阶段
训练后的流程包含非推理阶段和推理阶段。非推理阶段由 SFT 和MPO训练组成。推理阶段包含三个关键步骤:CoT冷启动(构建五步构建流程生成高质量CoT冷启动数据集,并通过模型融合优化模型性能)、通用强化学习(我们专注于提升Keye-VL-1.5的推理能力,应用 GSPO 提出渐进式提示采样方法充分利用难题,迭代改进冷启动和通用强化学习模型)、以及对齐强化学习(通过奖励系统提升Keye-VL-1.5的指令遵循、格式遵循、偏好对齐和RAG能力,本阶段构建指令遵循数据、推理数据和RAG数据用于强化学习训练)。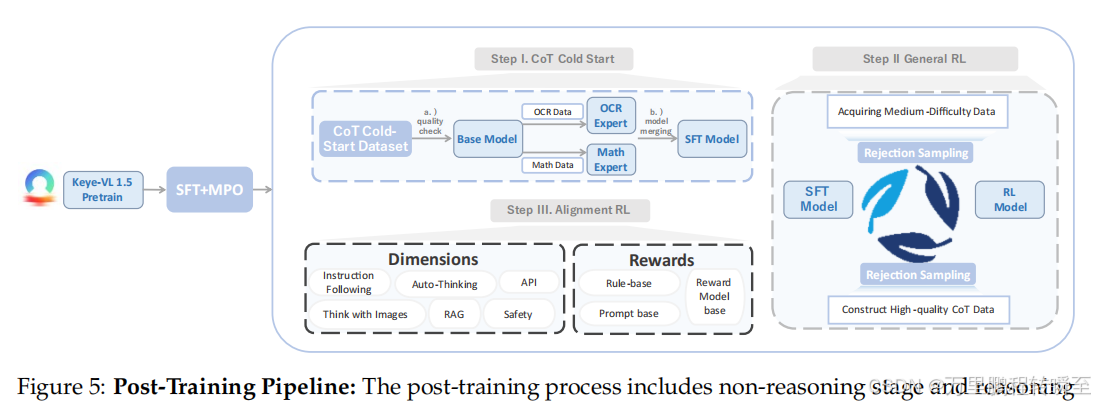
-
非推理阶段:SFT(750万+多模态QA样本)+ MPO(42万偏好样本),优化基础任务表现。
-
推理阶段:LongCoT冷启动(构建高质量推理数据+专家模型融合)→ 迭代式通用RL(GSPO算法+渐进式提示采样)。
基于五步自动化LongCoT数据生成流程的概述。该流程首先通过(a)使用多语言语言模型(MLLMs)从数据池和提示池中采样,生成思考过程和logit信息;随后(b)采用 MLLM 作为评判标准,通过分步评分评估结果和推理过程;(c)将数据分为三个质量等级(A:高质量,B:需人工审核的中等质量,C:低质量需舍弃);(d)对B类样本及疑似冗余的A类样本进行人工增强;(e)最终通过动态质量评分(1-5分制)的 MLLM 审查,确定最优数据利用策略。这种全面的方法确保了训练数据生成的可扩展性与质量控制。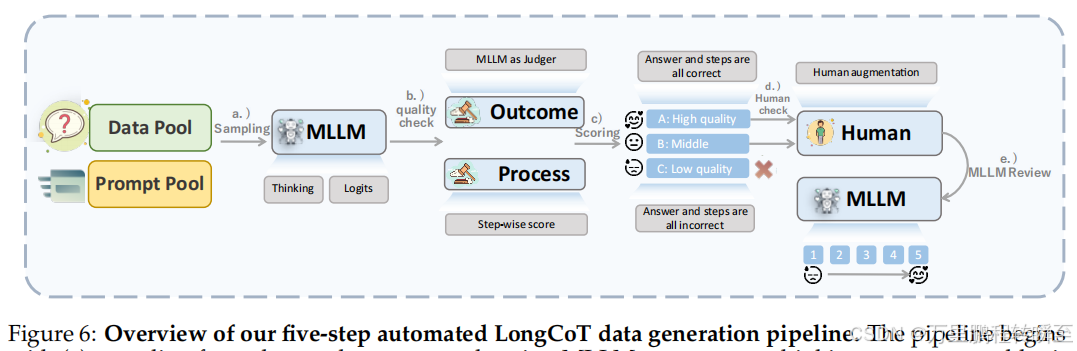
-
对齐阶段:对齐RL训练,优化指令遵循、格式合规、偏好对齐,采用三重奖励系统。
4. 消融实验
| 实验对象 | 核心结论 |
|---|---|
| SFT、MPO与LongCoT冷启动 | 增加SFT数据量提升推理与OCR能力;MPO偏好数据优化整体表现;LongCoT冷启动对数学推理提升最显著 |
| 专家模型与模型融合 | OCR专家模型平均得分83.65,融合后达84.51,显著提升TextVQA(83.40 vs 75.57)、ChartQA表现 |
| 对齐强化学习 | 较预览版,指令遵循任务平均提升4-6分,数学推理平均提升2-4分,Think/No-Think模式均有效 |
| 渐进式提示采样 | 无提示时难题错误率25.56%,Level 5提示错误率0.20%,Level 3(工具/公式)提示性价比最优 |
| 拒绝采样影响 | 迭代SFT-RL-(RFT-SFT)-(RFT-RL)策略,OpenCompass得分从75.32提升至76.33,数学基准平均提升1.87 |
三、核心性能表现(图表关键数据)
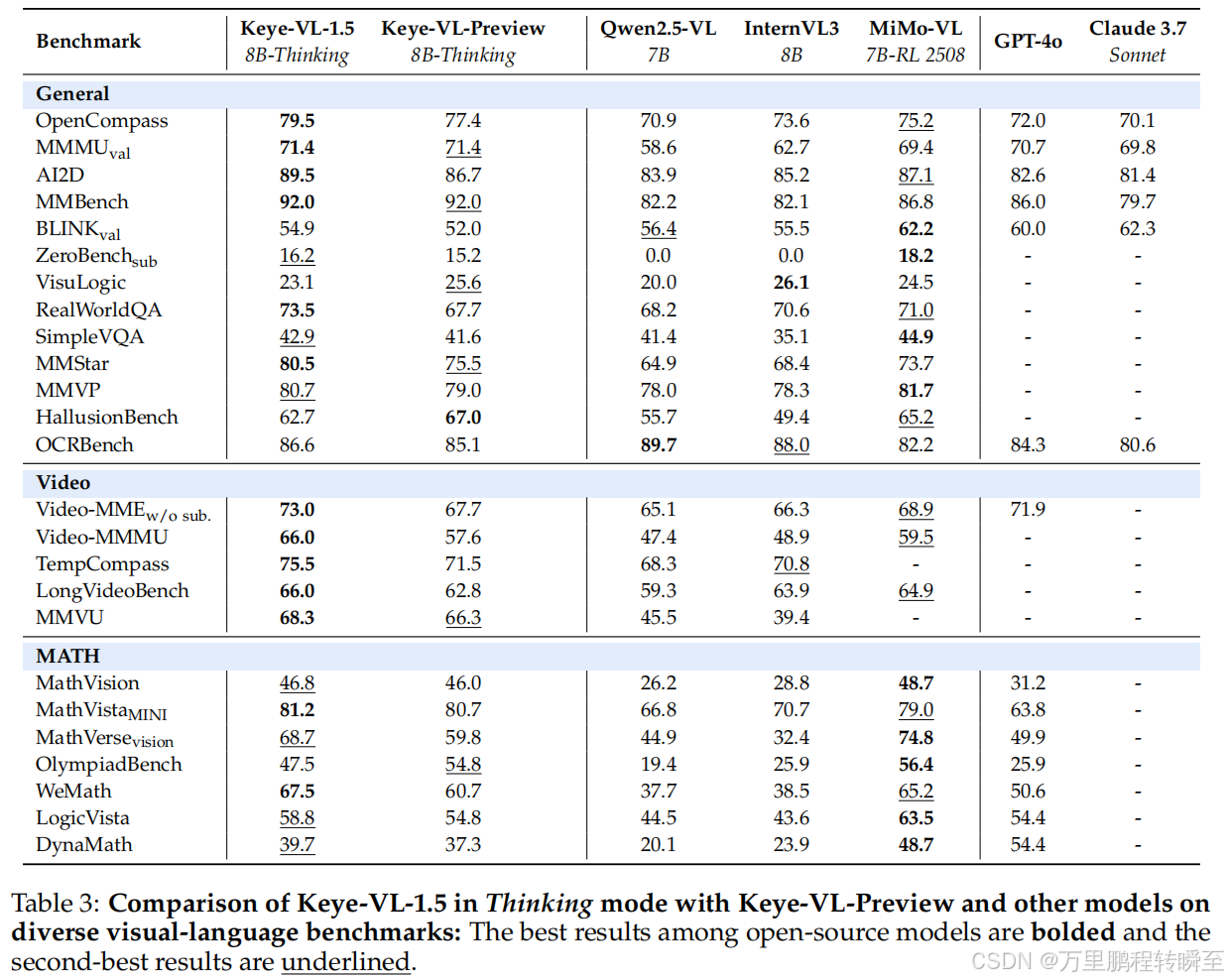
1. 公共基准测试(表3核心数据)
| 任务类别 | 基准名称 | Keye-VL-1.5 得分 | 对比模型(Qwen2.5-VL-7B) | 对比模型(MiMo-VL-7B-RL) |
|---|---|---|---|---|
| 通用多模态 | OpenCompass | 79.5 | 70.9 | 75.2 |
| 通用多模态 | MMMU(val) | 71.4 | 58.6 | 69.4 |
| 通用多模态 | MMBench | 92.0 | 82.2 | 86.8 |
| 通用多模态 | MMStar | 80.5 | 64.9 | 73.7 |
| 视频理解 | Video-MME(无子集) | 73.0 | 65.1 | 68.9 |
| 视频理解 | Video-MMMU | 66.0 | 47.4 | 59.5 |
| 视频理解 | TempCompass | 75.5 | 68.3 | - |
| 视频理解 | LongVideoBench | 66.0 | 59.3 | 64.9 |
| 数学推理 | MathVista(MINI) | 81.2 | 66.8 | 79.0 |
| 数学推理 | WeMath | 67.5 | 37.7 | 65.2 |
| OCR任务 | OCRBench | 86.6 | 89.7 | 82.2 |
2. 内部基准测试(表4、表5核心数据)
| 评估维度 | Keye-VL-1.5 得分 | MiMoVL-7B-RL-2508 得分 | 较Keye-VL-Preview 提升 |
|---|---|---|---|
| 综合得分 | 3.53 | 3.40 | +0.51 |
| 正确性 | 3.73 | 3.54 | +0.57 |
| 完整性 | 4.62 | 4.63 | +0.25 |
| 相关性 | 4.85 | 4.93 | +0.11 |
| 推理能力 | 3.81 | 3.56 | +1.00 |
| 时序信息理解 | 3.36 | 3.18 | +0.77 |
| 鲁棒性 | 4.29 | 3.46 | +0.41 |
| 领域专业性 | 3.68 | 3.68 | +0.91 |
3. 关键对比图表结论
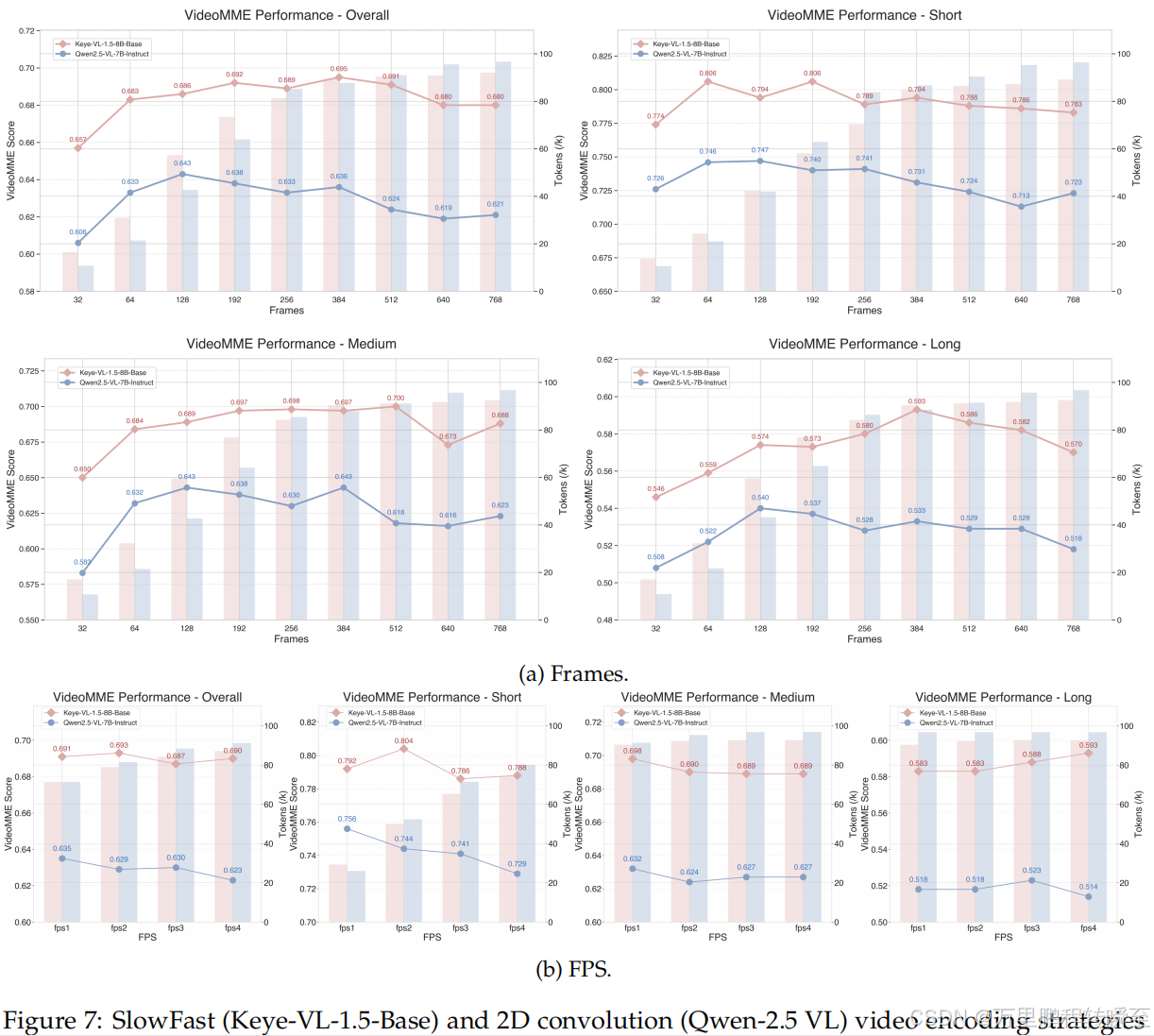
- 图7(VideoMME对比):Keye-VL-1.5在不同帧数(32-768)、FPS(1-4)和视频长度下表现更稳定,高帧数(≥384)时优势显著。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)