LangChain4j 项目架构分析
LangChain4j是一个Java生态的LLM集成框架,采用模块化设计统一不同LLM提供商和向量数据库的接口。核心模块包括定义接口的langchain4j-core和提供实现的langchain4j主模块,以及50+集成模块(LLM、向量存储、文档处理等)。项目通过BOM管理版本,支持声明式编程的AI Services特性,简化多轮对话和RAG流程实现。优势在于接口统一、模块化设计和丰富集成,缺
LangChain4j 项目架构分析
请关注公众号【碳硅化合物AI】
概述
LangChain4j 是 Java 生态里的 LLM 集成框架,2023 年初启动,当时 Java 这边还没有成熟的 LLM 库。核心思路是统一 API,降低复杂度。
不同 LLM 提供商(OpenAI、Anthropic、Google 等)的 API 格式不同,向量数据库(Pinecone、Milvus、Chroma 等)的接口也不一样。切换提供商通常需要重写代码。LangChain4j 通过统一接口抽象,让切换只需改依赖,业务代码不变。
实际使用中,这种抽象带来的好处很明显:开发阶段可以用本地模型(Ollama)快速迭代,生产环境切换到 OpenAI 或 Azure,代码几乎不用改。向量存储也是,本地开发用 InMemoryEmbeddingStore,生产用 Pinecone 或 Milvus,接口完全一致。
模块结构
项目是 Maven 多模块,分层清晰:
langchain4j-core 是基础层,只定义接口,几乎无外部依赖(只有 Jackson、SLF4J)。定义了 ChatModel、EmbeddingStore、ChatMemory 等核心接口,以及 Document、ChatMessage 等数据模型。
langchain4j 是主模块,依赖 core,提供实现:AI Services(声明式接口)、文档加载/分割、记忆实现、RAG 组件等。
集成模块 有 50+ 个,分几类:
- LLM 集成:OpenAI、Anthropic、Google Gemini、Ollama、Azure OpenAI 等 20+ 个
- 向量存储:Pinecone、Milvus、Chroma、Qdrant、pgvector 等 30+ 个
- 文档处理:loaders(S3、Azure Blob、GitHub)、parsers(PDF、Word、Markdown)、transformers
- 其他:agentic(实验性)、mcp、easy-rag、http-client 抽象
这种设计的好处是:只引入需要的模块,不会拖一堆不必要的依赖。比如只用 OpenAI 和 Pinecone,就只引入这两个模块。
模块化架构
依赖关系图
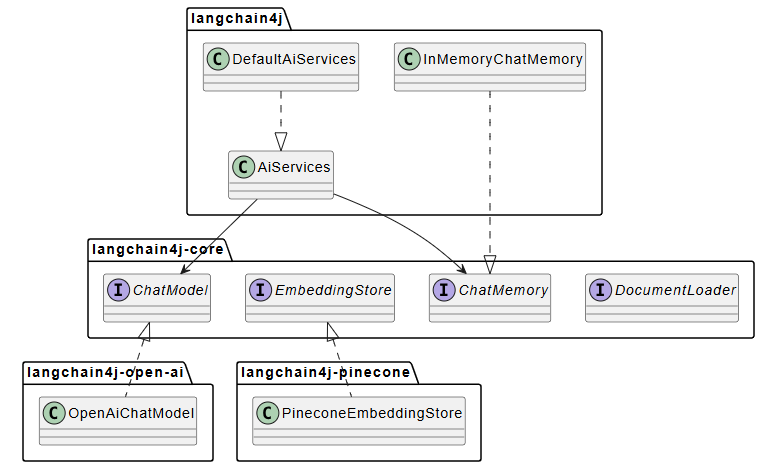
模块依赖层次
- 最底层:
langchain4j-core- 只定义接口,几乎无依赖 - 中间层:
langchain4j- 依赖 core,提供实现 - 集成层:各种
langchain4j-{provider}模块 - 依赖 core 或主模块,实现具体集成 - 聚合层:
langchain4j-aggregator- 聚合所有模块,用于构建整个项目
这种设计的好处是:
- 松耦合:每个集成模块可以独立使用
- 可替换:可以轻松切换不同的提供商
- 易测试:核心抽象可以独立测试
BOM(Bill of Materials)
项目提供了 langchain4j-bom 模块,用于统一管理所有模块的版本。使用 BOM 后,你只需要指定 BOM 版本,各个模块的版本会自动对齐:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-bom</artifactId>
<version>1.10.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
核心用法
AI Services 是框架的核心特性,用接口定义服务,框架自动生成实现(基于动态代理)。
// 定义接口
interface Assistant {
String chat(String userMessage);
}
// 创建服务实例
ChatModel model = OpenAiChatModel.builder()
.apiKey(System.getenv("OPENAI_API_KEY"))
.modelName(GPT_4_O_MINI)
.build();
Assistant assistant = AiServices.create(Assistant.class, model);
String answer = assistant.chat("Hello");
带记忆的多轮对话:
interface ChatBot {
@SystemMessage("You are a helpful assistant")
String chat(@MemoryId String userId, String userMessage);
}
ChatBot bot = AiServices.builder(ChatBot.class)
.chatModel(model)
.chatMemoryProvider(memoryId -> new InMemoryChatMemory(memoryId))
.build();
bot.chat("user1", "What's 2+2?"); // 4
bot.chat("user1", "What did I just ask?"); // 能记住之前的问题
RAG 流程:加载文档 → 分割 → 生成嵌入 → 存储 → 检索增强。
// 文档处理
DocumentLoader loader = new FileSystemDocumentLoader(Paths.get("docs"));
List<Document> docs = loader.load();
DocumentSplitter splitter = new DocumentByParagraphSplitter(300, 0);
List<TextSegment> segments = splitter.splitAll(docs);
// 嵌入和存储
EmbeddingModel embeddingModel = new AllMiniLmL6V2EmbeddingModel();
EmbeddingStore<TextSegment> store = new InMemoryEmbeddingStore<>();
for (TextSegment segment : segments) {
Embedding embedding = embeddingModel.embed(segment.text()).content();
store.add(embedding, segment);
}
// RAG 服务
interface RAGService {
String answer(String question);
}
RAGService service = AiServices.builder(RAGService.class)
.chatModel(model)
.contentRetriever(EmbeddingStoreContentRetriever.builder()
.embeddingStore(store)
.embeddingModel(embeddingModel)
.maxResults(3)
.build())
.build();
实际应用
常见场景:智能客服(带记忆)、文档问答(RAG)、内容生成、数据提取分类、Agent 系统(实验性)。
优缺点
优点:统一 API 易切换、声明式编程代码简洁、模块化按需引入、集成丰富(50+ 模块)、Java 原生。
缺点:项目较新生态还在发展、文档示例有限、动态代理有性能开销、学习曲线(特别是 RAG/Agent)、模块多需用 BOM 管理版本。
实际使用建议:开发阶段用本地模型(Ollama)快速迭代,生产环境再切换;向量存储本地用 InMemory,生产用 Pinecone/Milvus;高频调用场景注意性能,可能需要缓存或优化。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)