【AI量化投研】- Modeling(四, 意外之喜)
@[TOC](【AI量化投研】- Modeling(四, 意外之喜))
背景
训练一直没有实际的效果,一方面准备好重来,要站在巨人的肩膀上做事,不再像无头苍蝇那样乱撞. 另一方面,原来的研究也不是毫无用处.发现,虽然损失函数长得很猥琐, 也不怎么收敛,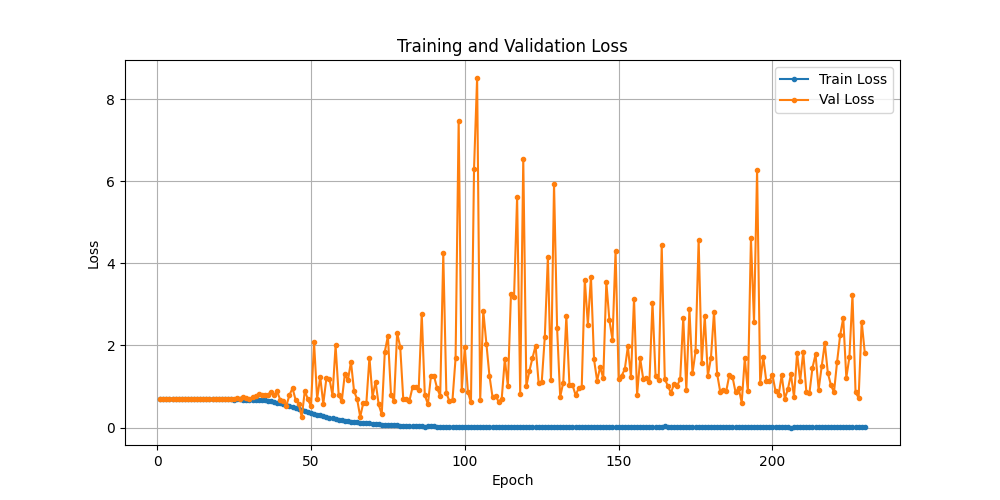
但出现一些很神奇的结果:
精确度49.57%,召回率63.42%,
精确度58.92%,召回率43.01%,
精确度66.86%,召回率36.73%,
精确度70.77%,召回率21.66%,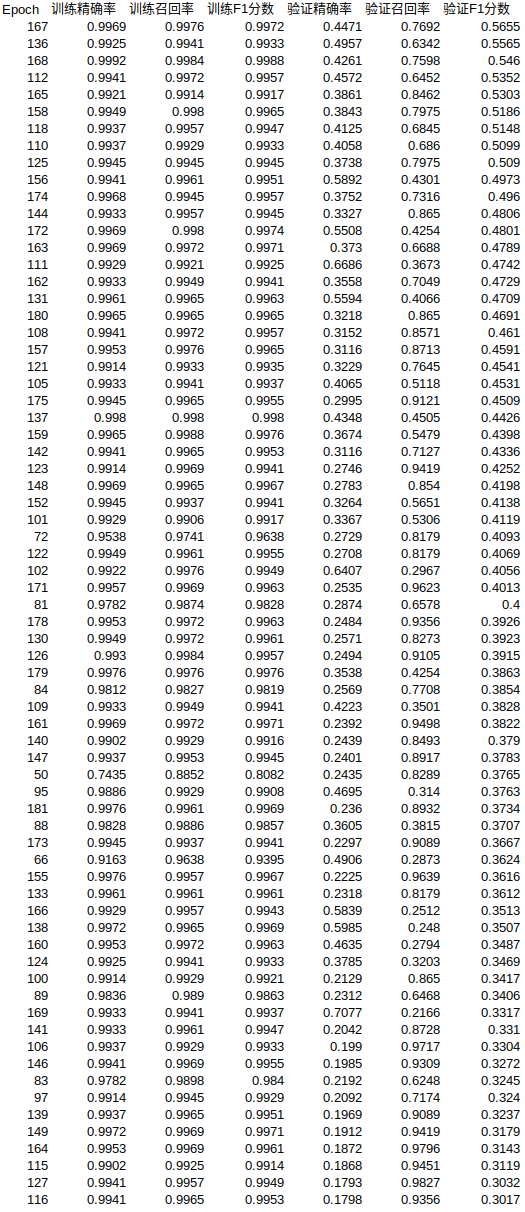
相当炸列了! 生财有道了! 说明:
- 误打误撞拿到了一个有潜力的模型训练模式(虽然输入特征缺陷很大);
- F1 分值 与 我们要的方向已经比较接近了, (除了尚未融入盈亏比信息, 但其实融入盈亏比信息并无必要,因损失可通过策略止损获得缩小,只要胜率高已是胜利!);
- 目前训练的一个要点是: 在样本分布不均衡的条件下, 正负样本权重差异设置, 是一个走钢丝的精细平衡过程,找到一个特别的点很重要;
- 损失函数的猥琐, 尚不能代表模型训练的失败, 不过,它的不稳定,可能会导致样本外的表现动荡,尚需实证;
不过:
6. 模型没保存好;
7. 损失寻优的方向与需要的方向不对头(但这次来看, 貌似如果以 F1 为方向搜索寻优能得到好结果,如何将F1 融入损失函数?);
8. 数据本身只有32000+,总样本量实际上是10W左右,因此,目前的结果仍然只处于测试阶段.
尝试 损失函数 融入盈亏比
计算盈亏比并融入损失函数不同类样本权重中.
@staticmethod
def create_adaptive_loss(dataset, loss_type='focal_weighted'):
if isinstance(dataset, Subset):
labels = [dataset.dataset.binary_labels[i] for i in dataset.indices]
returns = [dataset.dataset.returns[i] for i in dataset.indices]
else:
labels = dataset.binary_labels
returns = dataset.returns
pos_count = sum(1 for label in labels if label == 1)
neg_count = sum(1 for label in labels if label == 0)
total = len(labels)
print(f"📊 类别分布统计:")
print(f" 正样本: {pos_count} ({pos_count / total * 100:.1f}%)")
print(f" 负样本: {neg_count} ({neg_count / total * 100:.1f}%)")
# 计算平均盈亏比
pos_returns = [r for r, label in zip(returns, labels) if label == 1 and r != 0]
neg_returns = [abs(r) for r, label in zip(returns, labels) if label == 0 and r != 0] # 亏损取绝对值
avg_win = np.mean(pos_returns) if pos_returns else 0.0
avg_loss = np.mean(neg_returns) if neg_returns else 1.0
profit_loss_ratio = avg_win / avg_loss if avg_loss != 0 else 1.0
print(f" 平均盈利: {avg_win:.4f}, 平均亏损: {avg_loss:.4f}, 盈亏比: {profit_loss_ratio:.4f}")
if loss_type == 'focal_weighted':
class_weights = torch.tensor([1.0, profit_loss_ratio], dtype=torch.float32).to(device)
print(f" Focal Loss 类别权重: 负样本=1.00, 正样本={profit_loss_ratio:.2f}")
return FocalLoss(alpha=class_weights, gamma=2.0)
else:
print(" 使用标准交叉熵损失")
return nn.CrossEntropyLoss()
启动训练
============================================================
🚀 开始二分类模型训练
============================================================
正在扫描所有 .zst 文件...
100%|██████████| 32950/32950 [26:05<00:00, 21.05it/s]
📊 数据集统计:
✓ 有效文件: 32950 个
✗ 损坏文件: 0 个
📈 标签0(跌): 29767 个 (90.3%)
📈 标签1(涨): 3183 个 (9.7%)
📊 划分训练集、验证集和测试集...
- 训练集大小: 23804
- 验证集大小: 4202
- 测试集大小: 4944
🔄 创建数据加载器...
- 训练批次/epoch: 383
- 验证批次/epoch: 263
- 测试批次/epoch: 309
创建二分类模型...
✅ 不平衡批采样器创建完成:
- 批次数量: 383
- 每批大小: 16
- 每批正样本: 6 个 (38.2%)
- 每批负样本: 10 个
✅ 二分类模型创建完成:
- 输入通道: 64
- 输出类别: 2 (二分类)
⚙️ 配置训练参数...
============================================================
🔥 开始训练循环
============================================================
Epoch 001/2000: 0%| | 0/383 [00:00<?, ?it/s]📊 类别分布统计:
正样本: 2299 (9.7%)
负样本: 21505 (90.3%)
平均盈利: 2.6044, 平均亏损: 0.3049, 盈亏比: 8.5424
Focal Loss 类别权重: 负样本=1.00, 正样本=8.54
虽然逻辑上头头是道,落实到实际,也只是正负样本加权不一样. 这个之前做过, 都会导致"训练-验证"损失曲线反走, 而事实也验证确实如此.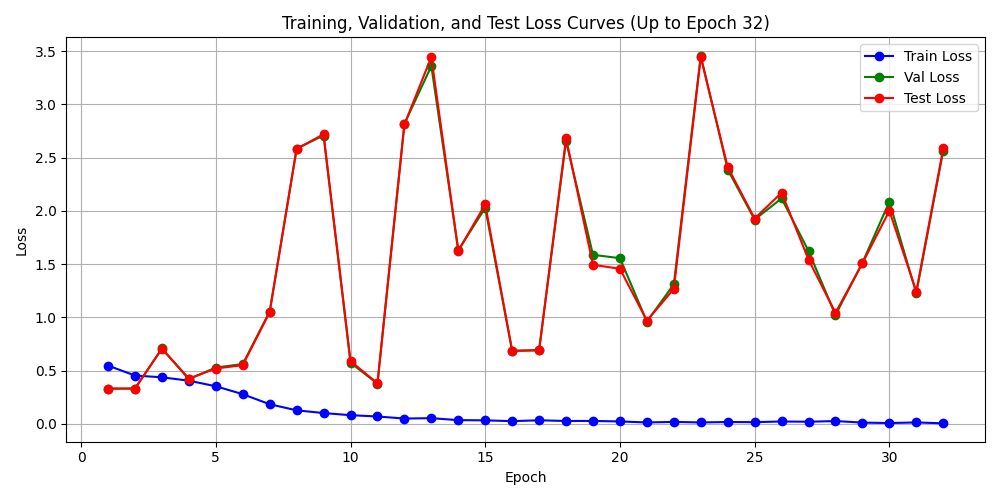
从结果来看, 确实反走得比较严重:
训练损失降低到0.0221,验证损失不减反增,精确度15%上不去.
📊 Epoch 026 结果:
训练损失: 0.0221 | 验证损失: 2.1168 | 测试损失: 2.1701
训练精确率: 0.9870 | 验证精确率: 0.1599 | 测试精确率: 0.1564
训练召回率: 0.9939 | 验证召回率: 0.9384 | 测试召回率: 0.9435
训练F1分数: 0.9905 | 验证F1分数: 0.2733 | 测试F1分数: 0.2684
训练期望值: 2.5668 | 验证期望值: 0.1486 | 测试期望值: 0.1739
训练准确率: 99.2820 | 验证准确率: 51.7849 | 测试准确率: 50.2629
而且,反思下来,按盈亏比加权的思想是有意义的,但盈亏比这个数值加权就没有必然坚实的逻辑基础了. 所以,按之前的参数调整经验,应把数值设置在1.6:1附近. 但是之前训练时候的收敛情况并不乐观: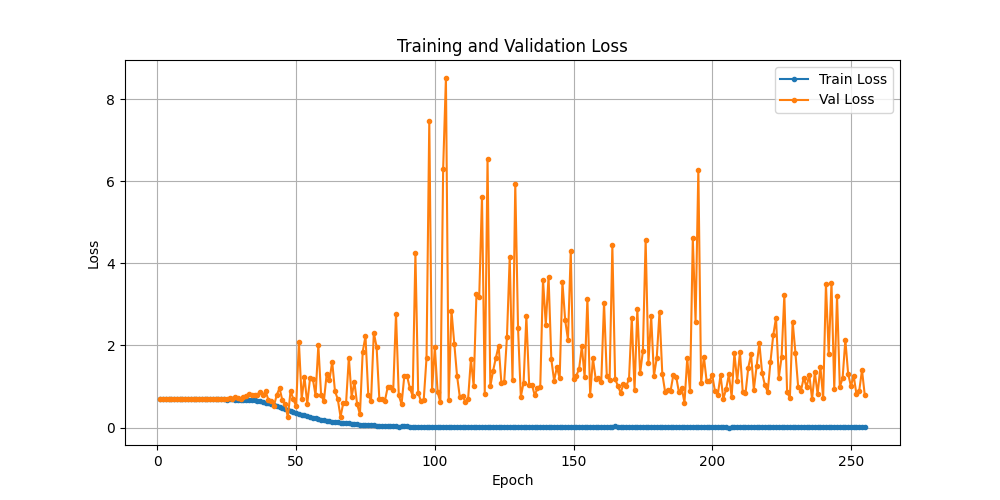
验证集损失, 只是没有放飞自我而已,有所收敛但收敛不多,训练损失收敛得倒是不错, 正负样本权值差越大,验证集越放飞自我,这是历史经验,因此,还需要往小里试.降低到1.3:1,兼顾F1 和 损失函数.
avg_win = 1.3 # np.mean(pos_returns) if pos_returns else 0.0
avg_loss = 1 # np.mean(neg_returns) if neg_returns else 1.0
修改后并未尝试训练.
尝试 损失函数 融入F1 Score
直接让损失函数优化F1分数是一个很有价值的方向,尤其是在正负样本不平衡的分类任务中。传统的交叉熵损失并不直接优化F1分数,这会导致模型训练目标与最终评估指标不一致。以下是几种将F1分数融入损失函数的主流方法。
💡 直接近似法:软化F1的计算
核心思路是让不可微的F1分数变得可微,从而能够进行梯度下降。
Dice Loss
其思路是将F1分数(Dice系数)中的“整数计数”(如TP, FP)替换为模型预测的概率值(即软化),形成一个连续可微的近似版本。公式如下:
DL = 1 - (2 * sum(y_true * y_pred) + smooth) / (sum(y_true²) + sum(y_pred²) + smooth)
其中 y_true是真实标签,y_pred是预测概率。这个损失函数直接优化的是F1的软近似,因此在F1指标上通常有良好表现。
按此思路建模,建模条件如下:
📂 加载数据集...
正在扫描所有 .zst 文件...
100%|██████████| 75400/75400 [34:46<00:00, 36.13it/s]
📊 数据集统计:
✓ 有效文件: 75400 个
✗ 损坏文件: 0 个
📈 标签0(跌): 68971 个 (91.5%)
📈 标签1(涨): 6429 个 (8.5%)
📊 划分训练集、验证集和测试集...
- 训练集大小: 54475
- 验证集大小: 9614
- 测试集大小: 11311
🔄 创建数据加载器...
✅ 不平衡批采样器创建完成:
- 批次数量: 774
- 每批大小: 16
- 每批正样本: 6 个 (38.2%)
- 每批负样本: 10 个
- 训练批次/epoch: 774
- 验证批次/epoch: 601
- 测试批次/epoch: 707
🧠 创建二分类模型...
✅ 二分类模型创建完成:
- 输入通道: 64
- 输出类别: 2 (二分类)
首轮训练结果
Epoch 001/2000: 100%|██████████| 774/774 [12:37<00:00, 1.02it/s, loss=0.4672, acc=39.15%]
📉 损失曲线图已保存至: plots/losses_20251228_133025_epoch_1.png
📊 Epoch 001 结果:
训练损失: 0.498371 | 验证损失: 0.922578 | 测试损失: 0.922555
训练准确率: 39.15% | 验证准确率: 8.53% | 测试准确率: 8.53%
训练精确率: 0.3758 | 验证精确率: 0.0853 | 测试精确率: 0.0853
训练召回率: 0.9419 | 验证召回率: 1.0000 | 测试召回率: 1.0000
训练F1分数: 0.5372 | 验证F1分数: 0.1572 | 测试F1分数: 0.1572
训练期望值: 0.7976 | 验证期望值: 0.0045 | 测试期望值: 0.0089
训练31轮后的结果图,放弃 样本加权 交叉熵, 虽是以近似F1损失为优化目标, 陷入了这种无效学习的死局.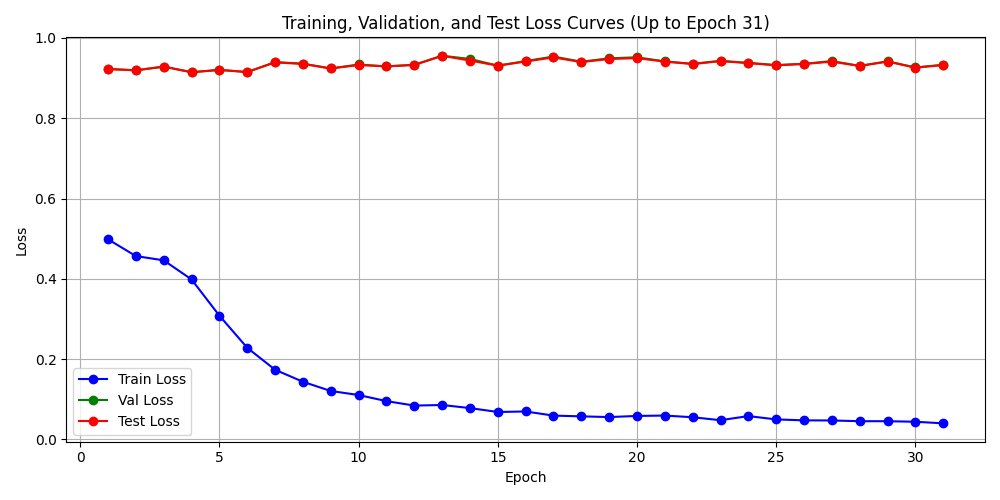
F1 Score Loss
另一种直接的软化方式,其目标是直接最大化F1分数:
# TensorFlow/Keras 示例
def f1_loss(y_true, y_pred):
tp = K.sum(y_true * y_pred, axis=0)
fp = K.sum((1 - y_true) * y_pred, axis=0)
fn = K.sum(y_true * (1 - y_pred), axis=0)
precision = tp / (tp + fp + K.epsilon())
recall = tp / (tp + fn + K.epsilon())
f1 = 2 * precision * recall / (precision + recall + K.epsilon())
return 1 - K.mean(f1) # 最小化 1 - F1
🔄 间接优化法:改进交叉熵
这类方法不直接计算F1,而是通过调整交叉熵损失,使其优化方向与提升F1一致。
Focal Loss
通过降低模型已能很好分类的样本(通常是大量的简单负样本)对损失的贡献,让模型更专注于难以分类的样本,这有助于提升召回率,进而可能优化F1。其核心是一个调制因子 (1 - p_t)^gamma。
# PyTorch 示例
class FocalLoss(nn.Module):
def __init__(self, gamma=2.0):
super().__init__()
self.gamma = gamma
def forward(self, logits, targets):
ce_loss = F.cross_entropy(logits, targets, reduction='none')
p_t = torch.exp(-ce_loss)
focal_loss = ((1 - p_t) ** self.gamma) * ce_loss
return focal_loss.mean()
加权交叉熵(Weighted Cross-Entropy)
为少数类样本的损失分配更高的权重,缓解类别不平衡问题,这也是提升F1的常见策略。权重可以固定,也可以根据每个批次的样本分布动态计算(自适应权重)。
💡+🔄 : 软化F1 + 加权交叉熵 相结合
将软化F1分数与加权交叉熵结合,结合了两种方法的优势,能更直接地引导模型优化关心的F1指标,同时保持训练过程的稳定。
结合一 - 复合损失
下面是一个具体的方案。创建一个复合损失函数(Composite Loss),让软化F1分数和加权交叉熵协同工作。
import torch
import torch.nn as nn
import torch.nn.functional as F
class CompositeF1CrossEntropyLoss(nn.Module):
"""
结合软化F1损失与加权交叉熵的复合损失函数
目标:同时优化分类准确性和F1分数,特别适用于不平衡数据
"""
def __init__(self, alpha=0.5, beta=0.5, class_weights=None, epsilon=1e-7):
"""
Args:
alpha: 软化F1损失的权重
beta: 加权交叉熵损失的权重 (alpha + beta 通常为1)
class_weights: 各类别的权重张量,用于处理类别不平衡
epsilon: 平滑项,防止除零
"""
super().__init__()
self.alpha = alpha
self.beta = beta
self.epsilon = epsilon
self.class_weights = class_weights
# 初始化加权交叉熵损失
if class_weights is not None:
self.cross_entropy = nn.CrossEntropyLoss(
weight=class_weights, reduction='mean'
)
else:
self.cross_entropy = nn.CrossEntropyLoss(reduction='mean')
def soft_f1_loss(self, y_pred, y_true):
"""
计算软化F1损失(基于Dice Loss思想)
使用概率值而非硬标签,使得损失函数可微
"""
# 将真实标签转换为one-hot编码
y_true_oh = F.one_hot(y_true, num_classes=y_pred.size(1)).float()
# 对预测值应用softmax
y_pred_softmax = F.softmax(y_pred, dim=1)
# 计算真正例、假正例、假负例的软化版本
tp = (y_true_oh * y_pred_softmax).sum(dim=0)
fp = ((1 - y_true_oh) * y_pred_softmax).sum(dim=0)
fn = (y_true_oh * (1 - y_pred_softmax)).sum(dim=0)
# 计算软化精确率和召回率
precision = tp / (tp + fp + self.epsilon)
recall = tp / (tp + fn + self.epsilon)
# 计算软化F1分数
soft_f1 = 2 * (precision * recall) / (precision + recall + self.epsilon)
# 返回平均F1损失(最小化1-F1)
return 1 - soft_f1.mean()
def forward(self, y_pred, y_true):
# 计算软化F1损失
f1_loss = self.soft_f1_loss(y_pred, y_true)
# 计算加权交叉熵损失
ce_loss = self.cross_entropy(y_pred, y_true)
# 组合损失
composite_loss = self.alpha * f1_loss + self.beta * ce_loss
return composite_loss, f1_loss, ce_loss
为了使复合损失函数达到最佳效果,建议采用以下训练策略:
渐进式训练
def get_training_schedule(total_epochs=100):
"""
制定渐进式训练计划
前期:侧重交叉熵,稳定收敛
后期:侧重F1损失,优化目标指标
"""
schedule = {
'phase1': {'epochs': int(0.3 * total_epochs), 'alpha': 0.3, 'beta': 0.7},
'phase2': {'epochs': int(0.5 * total_epochs), 'alpha': 0.5, 'beta': 0.5},
'phase3': {'epochs': int(0.2 * total_epochs), 'alpha': 0.7, 'beta': 0.3}
}
return schedule
关键参数初始化
# 根据类别不平衡程度设置权重
def calculate_class_weights(labels):
"""计算类别权重,处理不平衡数据"""
class_counts = torch.bincount(labels)
total_samples = len(labels)
class_weights = total_samples / (len(class_counts) * class_counts.float())
return class_weights
# 初始化损失函数
class_weights = calculate_class_weights(training_labels)
loss_fn = CompositeF1CrossEntropyLoss(
alpha=0.5,
beta=0.5,
class_weights=class_weights
)
结合二 - 动态权重调整策略
固定权重可能不是最优的。可以参考基于奖惩机制的动态权重方法,让模型在训练过程中自动调整两个损失的比重.
class AdaptiveCompositeLoss(nn.Module):
"""
自适应权重的复合损失函数
根据训练阶段动态调整F1损失和交叉熵损失的权重
"""
def __init__(self, total_epochs, initial_alpha=0.3):
super().__init__()
self.total_epochs = total_epochs
self.initial_alpha = initial_alpha
def forward(self, y_pred, y_true, current_epoch):
# 动态调整权重:前期侧重CE稳定训练,后期侧重F1优化
# 随着训练进行,逐渐增加F1损失的权重
alpha = self.initial_alpha + (1 - self.initial_alpha) * (current_epoch / self.total_epochs)
beta = 1 - alpha
# 计算各项损失
base_loss_fn = CompositeF1CrossEntropyLoss()
total_loss, f1_loss, ce_loss = base_loss_fn(y_pred, y_true)
# 应用动态权重
adaptive_loss = alpha * f1_loss + beta * ce_loss
return adaptive_loss, f1_loss, ce_loss, alpha, beta
结合小结
优势
目标一致性
训练稳定性
不平衡适应性
灵活可调
说明
软化F1损失确保模型直接优化你关心的F1指标
交叉熵损失提供良好的梯度信号,防止训练震荡
加权机制和F1优化共同应对类别不平衡问题
动态权重机制让模型在不同训练阶段有不同侧重
预期效果
相比单一损失函数,这种组合通常能在验证集上获得更高的F1分数,同时保持较好的准确率。特别是在数据不平衡的场景下,对少数类的识别能力会有明显提升。这种复合损失函数的设计思路,本质上是让交叉熵负责"夯实基础",而软化F1负责"冲刺高分",两者协同工作,共同推动模型向既准确又均衡的方向发展。
尝试修改特征输入
标的为y轴,日期为X轴, 单特征构建1个平面,所有要输入的特征就全部输入在多通道特征平面中. 通过卷积网络多层次特征图去发现远距离相关.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)