Python基础知识的总结(4)
刚刚上述的都是内置模块,而自定义模块通过自己定义一个python文件,然后在需要执行的代码中导入首先需要创建一个自定义文件,.py为后缀:在自定义文件中创建我们需要的代码:import f1效果如下:这就是自定义模块的用法if __name__ == '__main__':测试代码效果与上题一样包是将模块组织到一起,并放在一个文件夹中,在文件夹下创建了一个__init__.py的文件,而这个文件夹
目录
from 模块名 import * / from 模块名 import 功能名
一、模块
(1)模块的含义
Python模块就是一个Python文件,以.py结尾,包含了Python对象和语句,可以定义函数,类和变量,可以包含可执行的代码
(2)模块的分类和导入
模块通常分为:内置模块和自定义模块
导入方式:
import 模块名
import 模块名 as 别名
from 模块名 import *
from 模块名 import 功能名
import 模块名
导入模块名,代码:
import math print(math.sqrt(4))引入math模块,sqrt()求的是数的平方根
效果如下:
也可以引用多个:
import math,random print(math.sqrt(9)) print(random.randint(1,10))randint()是生成两数之间的随机数
效果如下:


import 模块名 as 别名
通过as关键字导入别名
代码:
import math as m print(m.sqrt(4))就是用别名代替模块名进入程序使用
from 模块名 import * / from 模块名 import 功能名
那么有了import导入模块,为什么还要这种方式:
import代表导入某个或多个模块的所有功能,而有时候我们希望只导入模块中的某些方法,而不是全部,这时候就建议使用这个方法
from 模块名 import * 就是导入这个模块所有功能 == import 模块名from 模块名 import 功能名代码:from math import sqrt print(sqrt(4))这样使用时可以直接使用功能而不需要先引用模块
(3)模块拓展:time模块中的time()方法
time()是用于返回当前秒数的,一般被称为时间戳
代码:
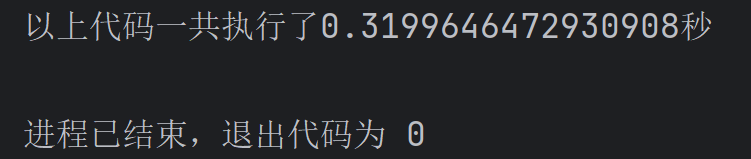
import time start = time.time() list1 = [i for i in range(10000000)] end = time.time() print(f'以上代码一共执行了{end - start}秒')效果如下:
(4)自定义模块
刚刚上述的都是内置模块,而自定义模块通过自己定义一个python文件,然后在需要执行的代码中导入
首先需要创建一个自定义文件,.py为后缀:
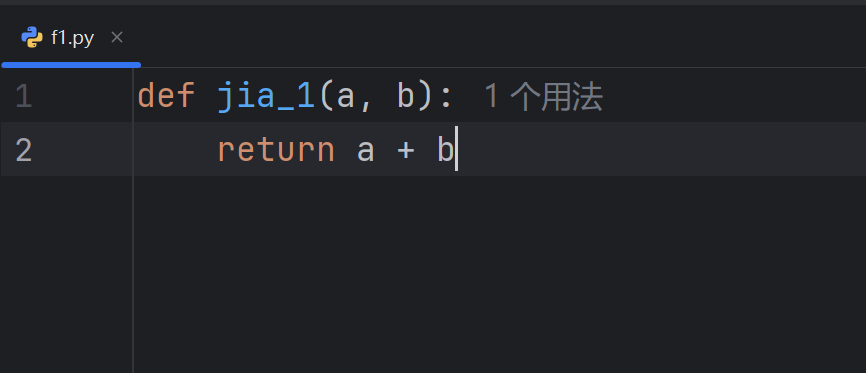
在自定义文件中创建我们需要的代码:
在执行代码中使用,代码:
import f1 print(f1.jia_1(1,2))效果如下:
这就是自定义模块的用法

__name__测试自定义模块功能
用法:if __name__ == '__main__':测试代码
代码:
def jia_1(a, b): return a + b if __name__ == '__main__': print(jia_1(1, 2))效果与上题一样
模块命名的注意事项
需要注意的是,在命名时尽量不要取内置模块的名称,和变量不要取关键字的名称是一个道理
__file__魔术变量可以查看模块引用的顺序
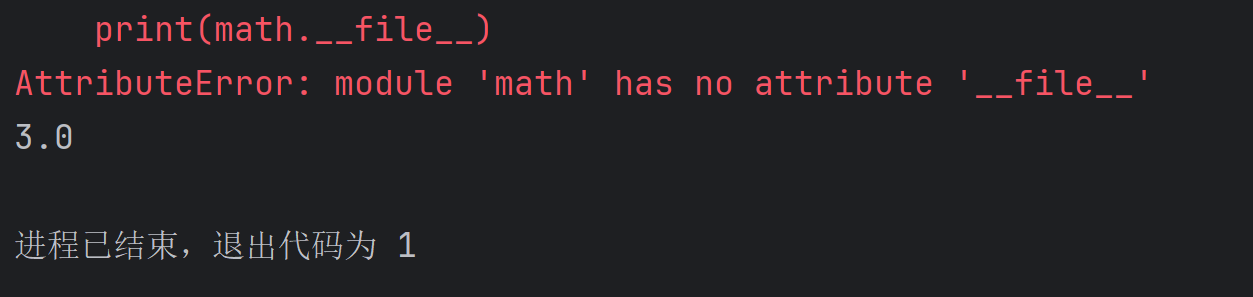
首先创建了一个math.py的自定义文件,然后输入代码:
import math print(math.sqrt(9)) print(math.__file__)发现先报错然后再执行sqrt()方法:
二、Package包
(1)什么是包
包是将模块组织到一起,并放在一个文件夹中,在文件夹下创建了一个__init__.py的文件,而这个文件夹就是包,也叫工具包
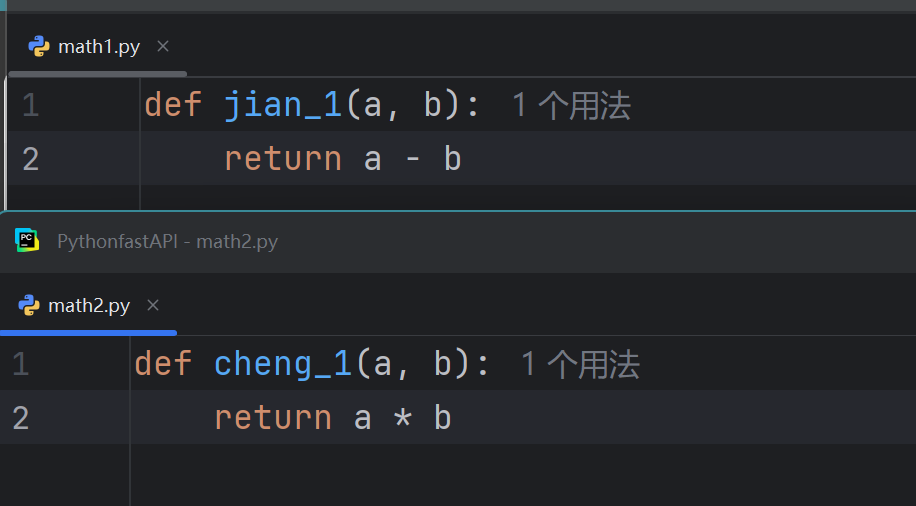
举个例子:首先创建一个名为f2的包,在其中创建两个自定义文件
在两个文件中分别写入:
引用时要遵照import 包名.模块名
调用时要遵照包名.模块名.方法名
代码:
import f2.math1 import f2.math2 num1 = f2.math1.jian_1(1, 2) print(num1) num2 = f2.math2.cheng_1(1, 2) print(num2)效果如下:

(2)包调用时的多种用法
也可以通过from 包名 import *导入包中的所有模块
调用时使用模块名.方法名
代码:
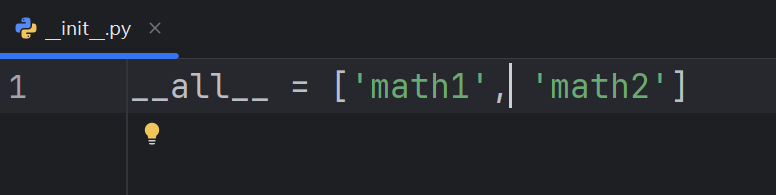
from f2 import * num1 = math1.jian_1(1, 2) print(num1)注意,这种方法使用有条件,需要在__init__.py文件中用__all__魔术变量控制导入模块才能使用:
效果如下:
而这种方法只对这个形式有效

这部分说了很多魔术变量,后面会统一说明
三、Python文件操作
(1)什么是文件
为了方便数据的管理和检索,在内存中长久保存数据,这才引入了文件的概念
文件分为文本文件、视频文件、音频文件、图像文件、可执行文件等多种类别
文件操作一般为创建文件、打开文件、文件读写、文件备份
(2)文件的基本操作
其实关于文件的操作在学习RPA时已经有所使用,这里就简单说明
文件打开
open()函数打开一个已经存在的文件或者创建一个新文件
代码:
f = open(name,mode)这返回的是一个file文件对象,这个代码当然不是能直接使用的,name是指你指定的文件名字,一般以字符串形式,也可以是文件所在具体路径;而mode则是指打开文件模式,后面会讲到,现在只需要知道:r -- 只读;w -- 写入;a -- 追加
文件路径
文件路径分为绝对路径和相对路径
绝对路径一般从盘符开始,一级一级向下找,不可越级
现在要求访问c盘下Python文件夹的python.txt文件:
f = open("C:\Python\python.txt", "r")绝对路径一旦路径固定,文件迁移会很麻烦,所以在日常使用操作时我们都用相对路径
相对路径只需要访问文件与代码在一个目录中用 ./文件名称 或直接写文件名称:
f = open("python.txt", "r")注意的是,如果你是希望创建一个文件,r记得改成w,在目录中如果不存在这个文件是没法读的
如果访问的是该代码的上级目录,可以通过 ../ 访问上层路径
文件写入和关闭
write()写入内容
代码:
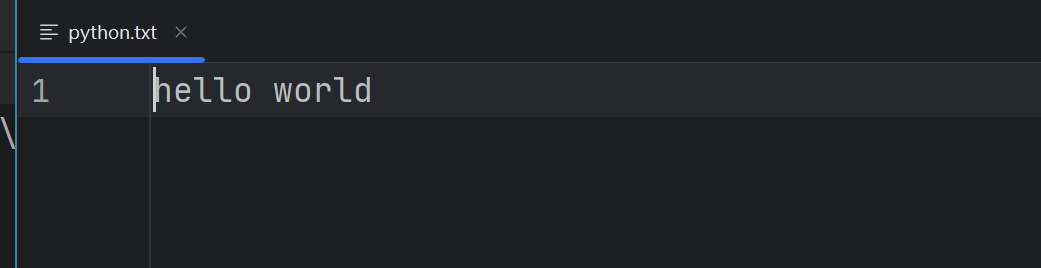
f.write("hello world")效果图如下:
close()关闭文件
代码:
f.close()当写入的内容出现中文乱码,使用encoding=‘utf-8’纠正格式
代码:
f = open("python.txt", "w", encoding="utf-8") f.write("hello world") f.close()
文件的读取
read(size)用于读取文件内容
代码:
f.read() f.read(1024)上一个是读取全部内容,下一个是读取1024字符长度的文件内容,字母或数字
readlines()方法可以读取文本类型数据,按照行的方式一次性读取文件内容,返回的是一个列表
文件操作的mode模式
除了最基础的 r -- 只读;w -- 写入;a -- 追加r+、w+、a+:代加号,功能全,既能读,又能写rb、wb、ab:代b的字符,代表以二进制的形式对其进行操作,适合读取文本或二进制格式文件,如图片、音频、视频等格式rb+、wb+、ab+:代加号,功能全,既能读,又能写(与+的区别于指针指向不同)
文件备份的案例
要求输入当前目录下任意文件名,完成对该文件的备份功能
代码:
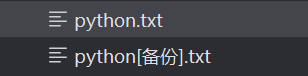
old_name = input('请输入要备份的文件名:') index = old_name.rfind('.') if index > 0: new_name = old_name[:index] + '[备份]' + old_name[index:] old_f = open(old_name, 'rb') new_f = open(new_name, 'wb') while True: data = old_f.read(1024) if len(data) == 0: break new_f.write(data) old_f.close() new_f.close() else: print('请输入正确的文件名')rfind()是通过寻找文件名的.作为下标,通过index判断文件是否有.,有才继续运行
len(data) == 0是判断读取文件内容是否完毕,读完再退出语句并写入新文件
效果图:
(3)文件夹的基本操作
Python中要进行文件夹操作需要用到os模块
import os os.函数名rename(旧文件名,新文件名) -- 对文件进行重命名
remove(要删除的文件名) -- 对文件进行删除
import os os.rename('python.txt', 'python1.txt') os.remove('python[备份].txt')效果如下:
前
后
相关操作
mkdir(新文件夹名称) -- 创建一个指定名称的文件夹
getcwd() -- 获取当前目录的名称
chdir(切换后的目录名称) -- 切换目录
listdir(目标目录) -- 获取指定目录下的文件信息,返回是一个列表
listdir(目标目录) -- 用于删除一个指定名称的空文件夹
删除操作(2)-- 注意慎用:
import shutil shutil.rmtree('要删除的文件路径')如果你删除的文件中内部包括很多文件夹,它会一级一级递归全部删掉然后才会删除文件夹本身
四、Python异常
(1)什么是异常
异常是程序运行时检测到错误然后返回错误提示
举个例子:
f = open('python.txt', 'r')运行台返回了
的错误信息,这就是异常,这是因为找不到python.txt文件导致的异常

(2)捕获异常并输出
常规捕获
基本语法:
try: 可能会发生错误的代码 except: 出现异常就执行的代码举个例子:
try: f = open('python.txt', 'r') except FileNotFoundError: print('文件不存在')效果如下:
这样文件就不会报错了而是返回错误原因的信息
而很多错误我们不知道类型,所以通常用except Exception as e:
try: f = open('python.txt', 'r') except Exception as e: print(e)效果如下:
通过了解错误信息重新改动代码,这比直接查看错误信息要简洁明了


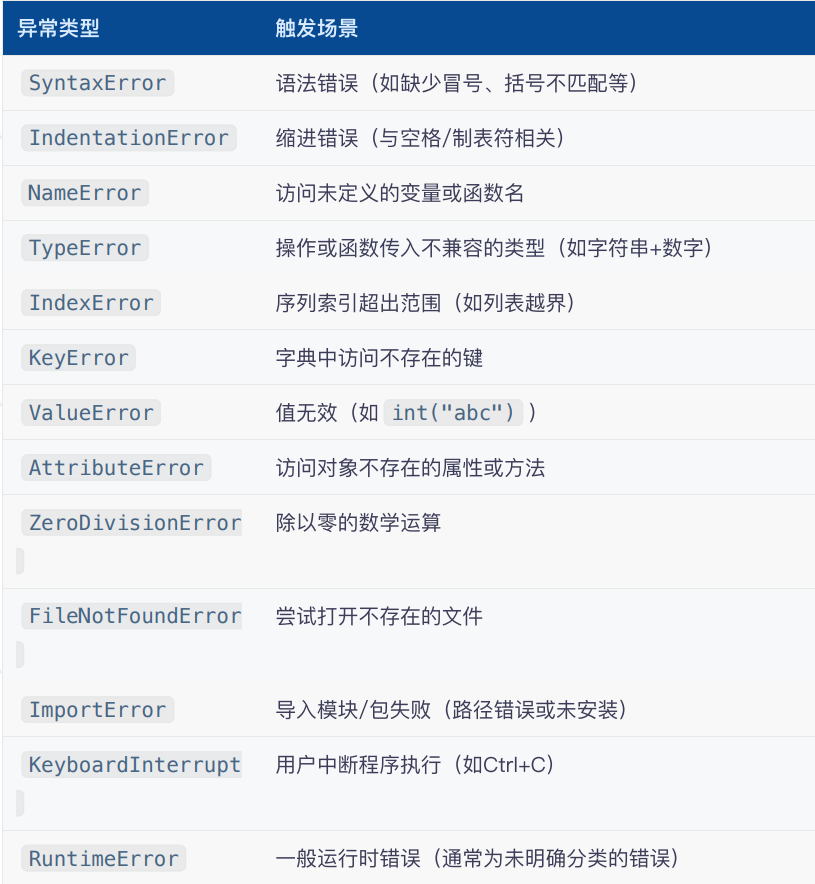
常见异常类型
记住几个自己能够记住的,简单的足以
异常捕获的else语句
else语句就是当没有异常时才会执行的语句
try: print(1) except Exception as e: print(e) else: print("没有发现异常")
异常捕获的finally语句
finally是无论有无异常都会执行的代码
try: print(1) except Exception as e: print(e) else: print("没有发现异常") finally: print("无论有没有异常, 这行代码都会执行")

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)