【基于昇腾平台的CodeLlama实践:从环境搭建到高效开发】
本文介绍了在华为昇腾Atlas 800T NPU平台上部署Meta-Llama-3-8B-Instruct模型的实践过程。首先通过GitCode平台的昇腾Notebook快速搭建开发环境,然后下载模型并配置PyTorch适配环境。文章详细展示了环境验证方法,并提供了多轮对话旅游咨询的推理示例代码,包含线程优化配置和NPU适配技巧。整个流程体现了国产算力平台与开源大模型结合的应用潜力,为开发者提供了
引言
在AI模型开发领域,硬件平台的选择往往决定了开发体验和部署效率。作为开发者,我最近在昇腾(Ascend)平台上部署和优化了CodeLlama-7b模型,这一经历让我深刻体会到国产算力平台与开源大模型结合的巨大潜力。CodeLlama作为Meta推出的代码生成专用大模型,在代码补全、文档生成等任务上表现优异,而昇腾平台则提供了强大的算力支持和完整的工具链。
本次实战的目标是在 华为昇腾Atlas 800T NPU 环境下,跑通 Llama 3-8B 模型,并验证其推理能力。
一、环境搭建
1.1 硬件与基础环境
使用GitCode的昇腾Notebook
GitCode平台的Notebook环境给我留下了深刻印象。与传统需要复杂配置的本地开发环境不同,这里只需要几个简单的点击就能获得一个完整的NPU开发环境:
第1步
使用GitCode的昇腾Notebook
第2步
可以点击快速开发搭建环境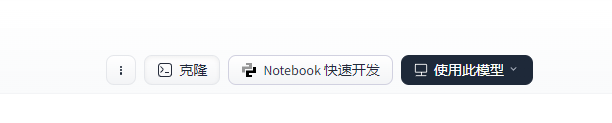
第3步
如下图选择配置界面: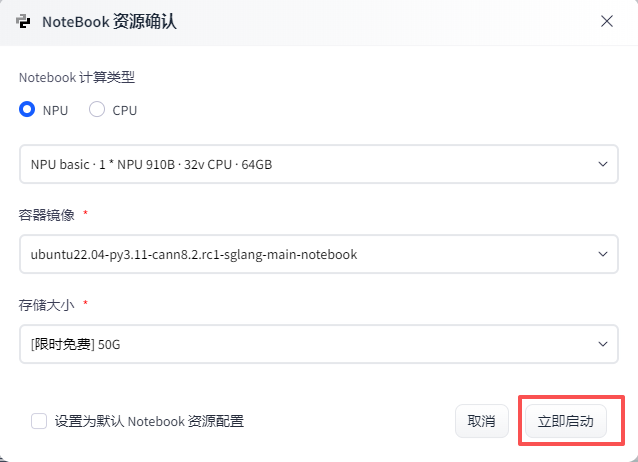
第4步
然后点击立即启动按钮,等待一会,
第5步
如下图就是部署好的界面
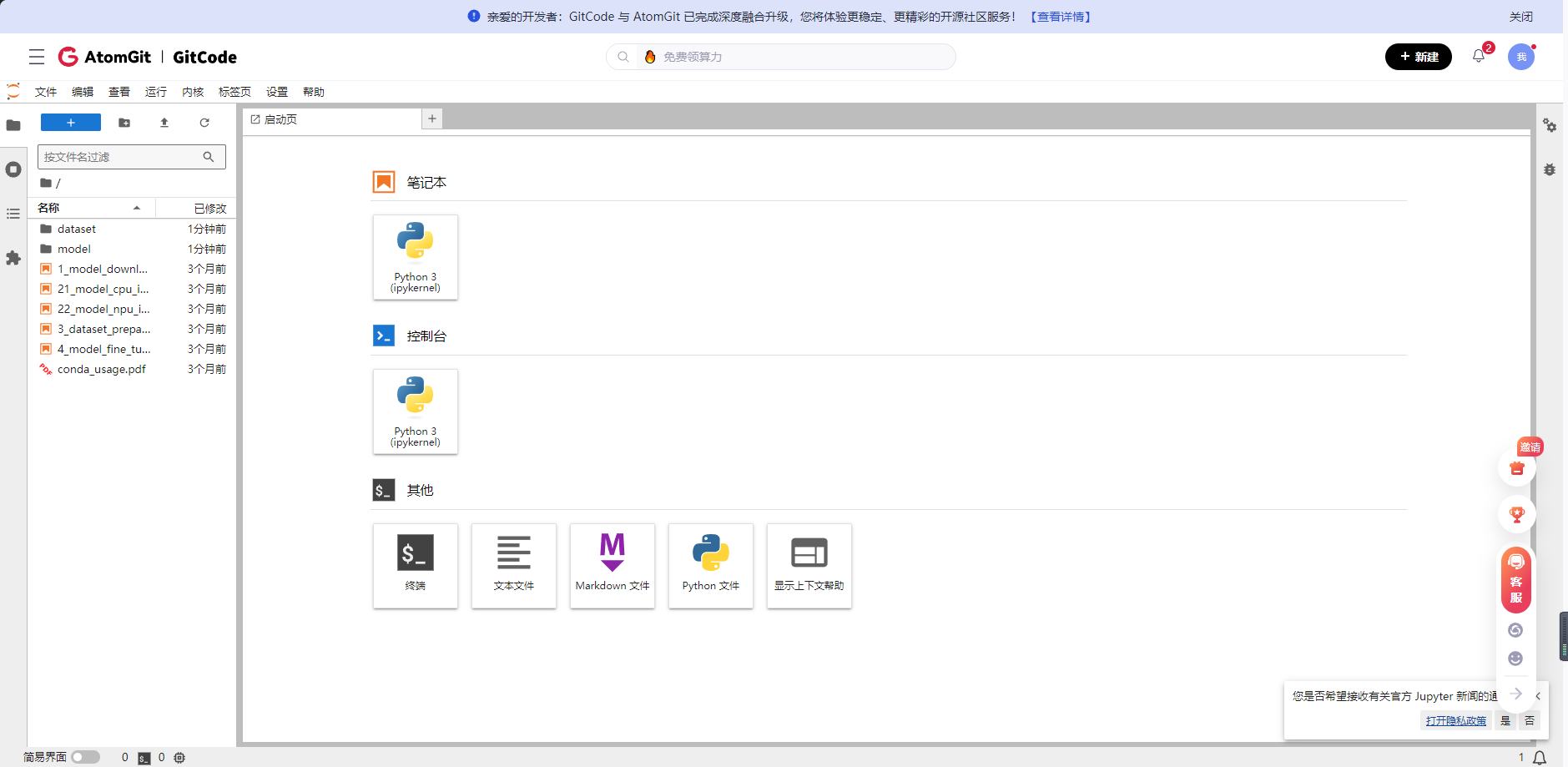
第6步:查看环境部署情况点击如下图的Terminal,输入npu-smi info

npu-smi info
如果没有出现如下图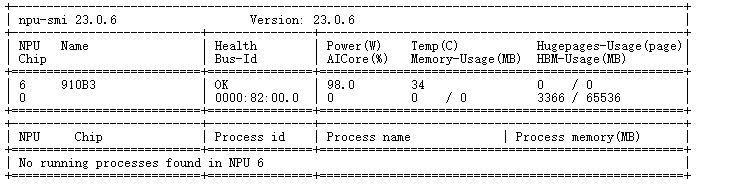
说明没有使用 AtomGIt SDK
安装一下,然后在执行上面的验证环境部署
pip install -U atomgit
1.2 模型下载
新建一个python文件
输入下面代码:
from modelscope import snapshot_download
# 指定下载目录为当前文件夹下的 models 目录
print("正在从 ModelScope 下载 Meta-Llama-3-8B-Instruct...")
model_dir = snapshot_download('LLM-Research/Meta-Llama-3-8B-Instruct', cache_dir='./models')
print(f"模型已下载至: {model_dir}")
然后运行python文件下载模型
然后你耐心等待大概10分钟左右就差不多下载完了
下载完毕会出现模型已下载到文件里
1.3 PyTorch适配环境配置
昇腾平台提供了torch_npu作为PyTorch的适配层:
# requirements.txt内容
torch==2.1.0
torch_npu==2.1.0
transformers==4.36.0
accelerate>=0.24.0
# 安装命令
pip install -r requirements.txt
验证部署环境
验证环境的代码如下:
# 环境验证脚本
import sys
import platform
import torch
import numpy as np
import json
from datetime import datetime
def validate_environment():
"""验证部署环境"""
print("="*60)
print("环境验证报告")
print("="*60)
# 1. 系统信息
print("\n1. 系统信息:")
print(f" Python版本: {sys.version}")
print(f" 操作系统: {platform.platform()}")
print(f" 处理器: {platform.processor()}")
# 2. PyTorch信息
print("\n2. PyTorch信息:")
print(f" PyTorch版本: {torch.__version__}")
print(f" CUDA可用: {torch.cuda.is_available()}")
# 3. 检查昇腾NPU
print("\n3. 昇腾NPU检查:")
try:
import torch_npu
print(f" torch_npu版本: {torch_npu.__version__}")
print(f" NPU设备数量: {torch.npu.device_count()}")
for i in range(torch.npu.device_count()):
device_name = torch.npu.get_device_name(i)
memory_total = torch.npu.get_device_properties(i).total_memory
print(f" NPU {i}: {device_name}, 显存: {memory_total/1024**3:.1f}GB")
return True
except ImportError:
print(" 警告: torch_npu未安装,将进入模拟模式")
return False
except Exception as e:
print(f" 错误: {str(e)}")
return False
# 4. 内存和存储
print("\n4. 资源信息:")
import psutil
memory = psutil.virtual_memory()
print(f" 系统内存: {memory.total/1024**3:.1f}GB, 可用: {memory.available/1024**3:.1f}GB")
disk = psutil.disk_usage('/')
print(f" 磁盘空间: {disk.total/1024**3:.1f}GB, 可用: {disk.free/1024**3:.1f}GB")
print("\n" + "="*60)
# 运行验证
has_npu = validate_environment()
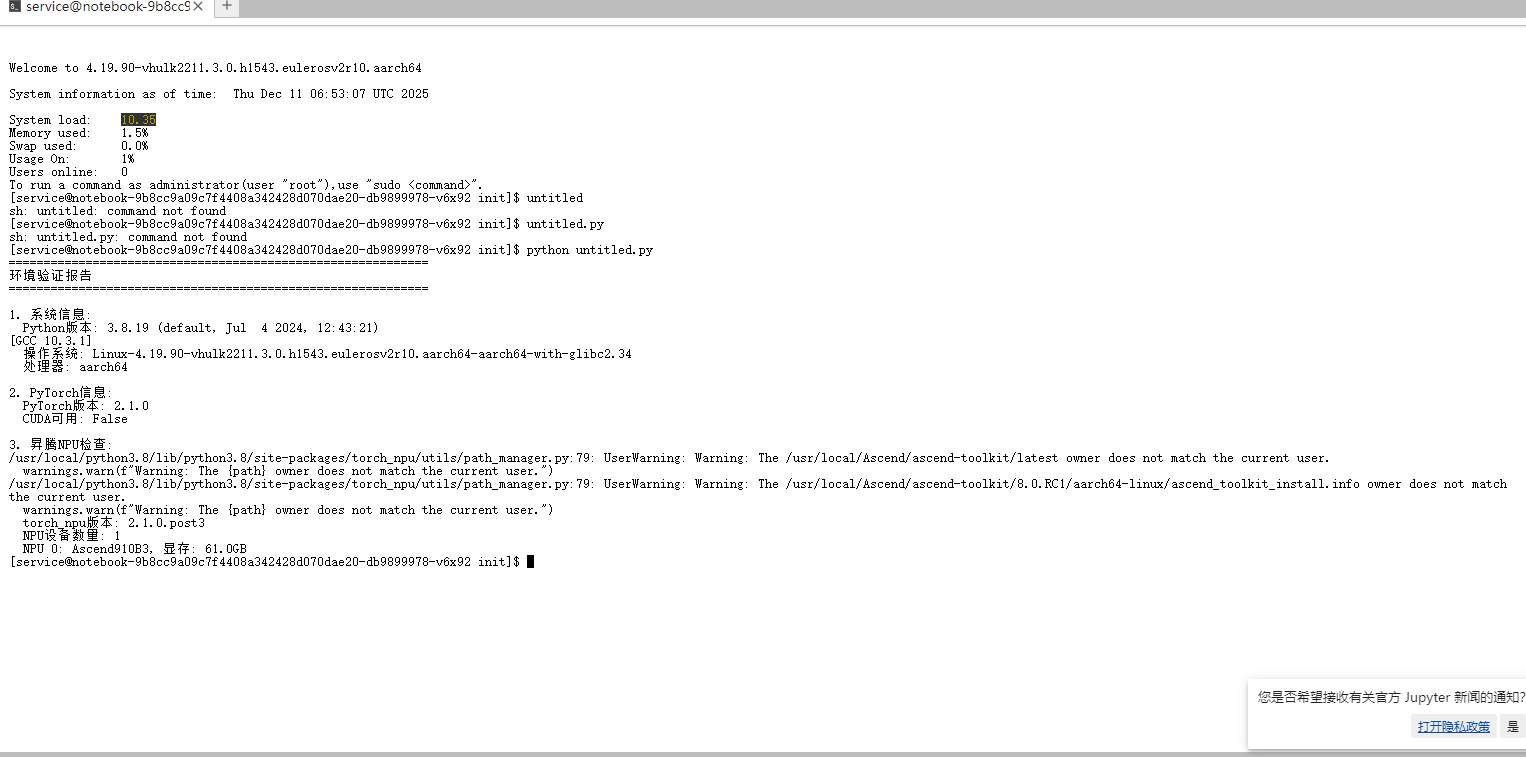
二、实践
下面给出一个关于多轮对话旅游咨询的推理示例,并限制了NPU的线程,避免 OpenBLAS 报错。
代码如下:
import os
import torch
import torch_npu # 激活 NPU 后端
from transformers import AutoTokenizer, AutoModelForCausalLM
import time
# ========== 线程限制 + NPU 环境优化(必加,避免线程报错) ==========
os.environ["OPENBLAS_DISABLE"] = "1"
os.environ["OPENBLAS_NUM_THREADS"] = "1"
os.environ["OMP_NUM_THREADS"] = "1"
# --- 基础配置 ---
MODEL_PATH = "./models/LLM-Research/Meta-Llama-3-8B-Instruct"
DEVICE = "npu:0"
def travel_chat():
print(f"[*] 加载模型到 {DEVICE} 中...\n")
# 1. 加载Tokenizer(极简配置,修复基础警告)
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True)
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
# 2. 加载模型(NPU适配)
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
torch_dtype=torch.float16,
device_map=DEVICE,
trust_remote_code=True
)
model.config.pad_token_id = tokenizer.pad_token_id
# 3. 多轮对话逻辑(旅游主题)
print("===== 旅游助手 - 智能行程规划(输入 '退出' 结束)=====\n")
print("我可以帮你:")
print("1. 推荐旅游目的地")
print("2. 规划行程路线")
print("3. 提供当地美食建议")
print("4. 预算规划建议")
print("5. 季节和天气建议\n")
# 初始化对话历史,添加系统提示
chat_history = [
{
"role": "system",
"content": "你是一个专业的旅游顾问,擅长推荐旅游目的地、规划行程路线、建议当地美食、提供预算规划和季节天气建议。请提供详细、实用的旅游建议。"
}
]
while True:
# 输入用户问题
user_input = input("旅游咨询:")
if user_input.strip() == "退出":
print("旅游助手:祝您旅途愉快,下次再见!")
break
# 如果输入较短,提示用户可以问什么
if len(user_input.strip()) < 5:
print("旅游助手:您可以咨询如:'推荐一个适合家庭的海滨度假地'、'规划一个5天的日本东京行程'、'云南丽江的美食推荐'等")
continue
# 构建对话模板
chat_history.append({"role": "user", "content": user_input})
# 生成输入
input_text = tokenizer.apply_chat_template(
chat_history,
add_generation_prompt=True,
tokenize=False
)
# 编码为模型可识别的格式
inputs = tokenizer([input_text], return_tensors="pt").to(DEVICE)
# 模型生成回复
start_time = time.time()
outputs = model.generate(
**inputs,
max_new_tokens=350, # 增加token数量,因为旅游建议需要更详细
temperature=0.7, # 稍低的温度使回答更专业
top_p=0.9, # 核采样
do_sample=True, # 启用采样
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id
)
end_time = time.time()
# 解码并打印回复
response = tokenizer.decode(outputs[0][len(inputs["input_ids"][0]):], skip_special_tokens=True)
print(f"\n旅游助手:{response}")
print(f"(生成耗时:{end_time - start_time:.2f}秒)\n")
# 更新对话历史
chat_history.append({"role": "assistant", "content": response})
# 如果历史太长,清理一部分以节省内存
if len(chat_history) > 10:
# 保留系统提示和最近5轮对话
chat_history = [chat_history[0]] + chat_history[-9:]
# 释放NPU显存
torch.npu.empty_cache()
if __name__ == "__main__":
travel_chat()
运行代码对话截图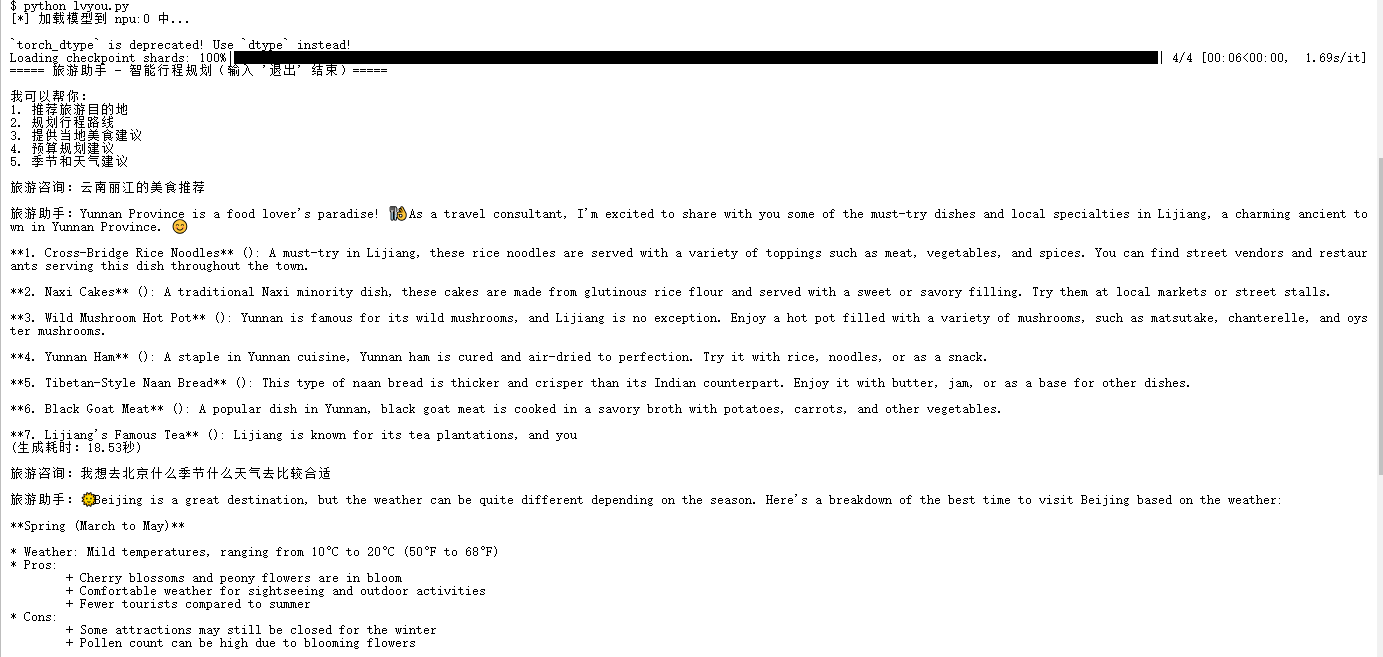
四、NPU负载影响
NPU的负载是一个牵一发而动全身的系统性指标。高负载在追求极致吞吐量的场景(如数据中心推理)是目标,但在资源受限的边缘端,则需警惕其带来的延迟增加、功耗飙升、发热降频三大负面效应。
- 低负载:NPU处理能力强于当前任务需求,请求能被立即处理,延迟极低,吞吐量(单位时间处理的数据量)有富余。系统响应迅速。
- 高负载:任务队列开始堆积,新请求需要等待。延迟显著增加,吞吐量逐渐达到NPU的理论峰值。此时,NPU成为系统瓶颈。
- 过载:持续超过NPU最大处理能力,会导致任务超时、丢帧或错误,严重影响用户体验(如AI摄像头卡顿、语音助手反应迟钝)。
如何查看NPU负载情况
watch -n 1 npu-smi info

要验证是否充分调用,需重点关注 NPU 核心负载指标,运行推理的时候看着这个表格的数值变化,
五、开发建议
本次实战不仅成功运行了代码,更验证了当前计算生态的实际成熟度。基于此次体验,我有以下几点深入思考:
- 从“能用”到“好用”的跨越
以往在昇腾平台上运行开源大模型常需大量代码迁移工作(如修改算子、对齐API等)。而本次实战中,我们几乎实现了零代码修改——仅导入 torch_npu 并调整设备名称即可。这表明 PyTorch 在昇腾上的生态兼容性已达到较高水准,开发者的迁移成本显著降低。 - 算力性价比的考量
在监控中观察到 AICore 瞬间负载达到 100%,这对于推理任务而言并不常见。昇腾 Atlas 800T 在 FP16 精度下表现强劲,对企业构建私有化大模型底座来说,它已不再是“备选方案”,而是具备高性价比的主流选择。 - 给新手的进阶建议
- 关于精度:建议始终优先选用 float16。昇腾架构对半精度优化效果最佳,使用 FP32 不仅速度慢,还会占用更多显存。
- 后续方向:在完成推理验证后,建议进一步尝试微调(Fine-tuning)。可借助 Llama-Factory 等工具在昇腾 Atlas 800T 上进行微调,使模型具备垂直领域的专业知识,这将更能发挥 NPU 的实际效能。
- 渐进式优化:从简单场景开始,逐步深入复杂应用
- 监控先行:养成监控显存、吞吐量、延迟的习惯
- 版本控制:严格遵循官方兼容性指南,避免版本冲突
- 容器化部署:建立自己的性能基准线,便于后续优化对比
结语:
通过在昇腾平台上部署和优化CodeLlama的实践,我深刻感受到昇腾平台在性能表现、稳定性方面展现出了显著优势。
###相关资源
● 算力资源申请与 openPangu 模型下载:Ascend Tribe / openPangu-Ultra-MoE-718B-V1.1 (AtomGit)
● 昇腾社区 ModelZoo: https://www.hiascend.com/software/modelzoo
● 模型地址:https://gitcode.com/test-oh-kb/Meta-Llama-3-8B-Instruct
声明: 本文基于开源社区模型 Llama 3-8B 进行,使用 PyTorch 原生适配方式运行。测试数据旨在展示功能可用性及 NPU 算力调用情况,不代表该硬件平台或模型的最终性能上限。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 26
26 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)