AI人工智能-提示工程(中)-第十一周(小白)
定义:一门“优化提示词 + 掌握LLM交互技能”的学科,核心是让大语言模型更好地适配你的任务不同角色的价值研究人员:强化 LLM 的推理、问答能力;开发人员:对接 LLM 与工具,落地工程化应用;普通用户:提高 LLM 输出的安全性、准确性,甚至用专业知识增强 LLM 能力(比如给 LLM 补充医学知识,让它做更精准的健康建议)。
一、基本介绍
这部分是基础,核心是理解“语言模型的本质”和“提示工程的价值”,帮你建立底层认知。
1.语言模型(LLM)的核心逻辑

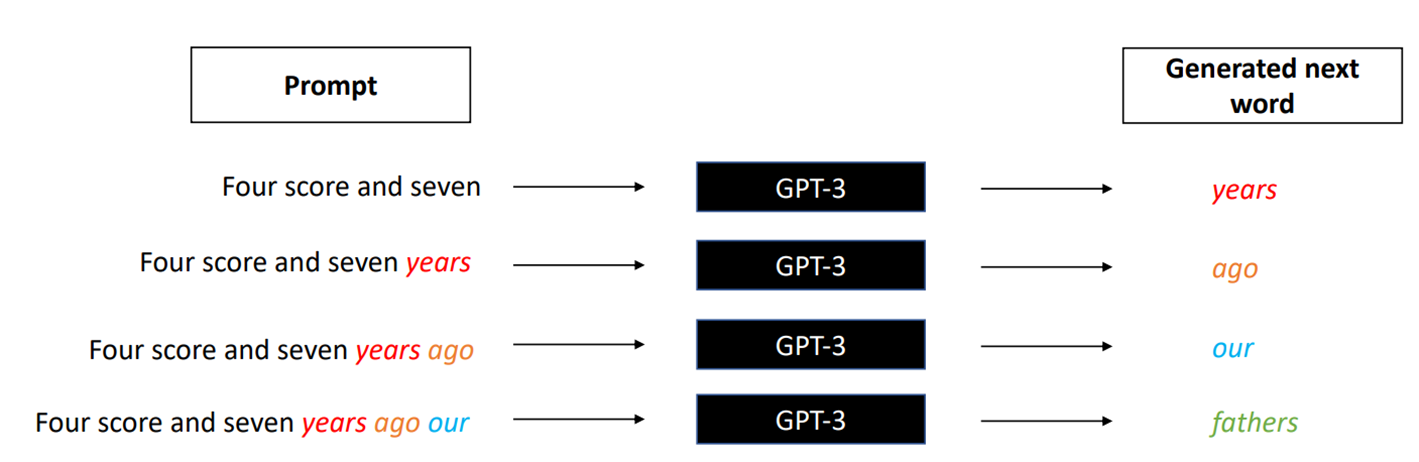
- 核心原理:语言模型是“基于上文预测下一个字的概率分布”——比如输入“The cat sat on the”,模型会计算“mat” “fridge”等词的出现概率,再按概率选下一个词
- 生成过程:迭代预测 + 拼接文本——比如“Four score and seven”->预测下一个词“years”->再基于“Four score and seven years”预测“ago”,逐步生成完成文本。
2.语言模型的3个关键特征
正因为模型有这些特征,单纯输入问题可能得不到满意结果,才需要“提示工程”来优化:
- 黑盒:你不知道模型内部怎么计算概率、选词,只能通过“输入(提示词)”控制输出
- 相似输入
相似输出:比如问“怎么学英语”和“英语学习方法”,模型可能给出差异很大的答案
- 相同输入也可能不同结果:因为模型有随机性,同一提示词可能生成多个版本
3.提示工程的定义与价值
- 定义:一门“优化提示词 + 掌握LLM交互技能”的学科,核心是让大语言模型更好地适配你的任务
- 不同角色的价值
研究人员:强化 LLM 的推理、问答能力;
开发人员:对接 LLM 与工具,落地工程化应用;
普通用户:提高 LLM 输出的安全性、准确性,甚至用专业知识增强 LLM 能力(比如给 LLM 补充医学知识,让它做更精准的健康建议)。
4.使用LLM的3个注意事项
- 安全问题:第三方接口会把你的输入发送到对方服务器——如果输入敏感数据,可能泄露
- 可信度问题:模型会“一本正经的胡说八道”——因为生成结果有随机性,且能生成“逻辑通顺但事实错误”的文本
- 时效性与专业性:
- 离线 LLM(未联网)的知识上限是 “训练数据截止时间”(比如 GPT-3.5 截止 2021 年 9 月),无法回答最新信息(如 2024 年的科技新闻);
- 细分领域(如你的深度学习细分方向、小众技术)的回答质量,取决于训练数据的数量和质量 —— 可能不如专业手册精准。
二、应用场景:“能做什么”和“该做什么”
1.LLM的核心能力边界
一句话总结:与“文本相关”且“有公开资料支撑”的任务,LL没机会都能做,具体分5大类
| 类别 | 核心场景(你可能用到的) |
|---|---|
| 写作与沟通 | 技术文档撰写、代码注释、论文润色、翻译(如英文论文转中文)、文本总结(如总结学术文献) |
| 学习与教育 | 数据分析(如实验数据解读)、编程教学(如调试代码)、学术研究(如文献综述辅助)、数学 / 物理公式推导 |
| 职业与个人发展 | 简历优化(如突出深度学习项目)、面试技巧(如 AI 岗面试模拟)、技术报告撰写、行业动态总结 |
| 日常生活与健康管理 | 旅行规划、时间管理(如科研任务分配) |
| 工作效率提升 | 任务管理(如科研项目拆解)、会议纪要生成、代码调试、工具推荐(如深度学习辅助工具) |
2. 关键原则:适合 vs 不适合的场景(避坑核心)
适合用提示工程的场景(优先尝试)
- 你 “能完成但费时间” 的任务 —— 比如手动整理 100 篇文献的核心观点(LLM + 提示词可快速总结);
- 你 “没完整思路但能判断结果正确性” 的任务 —— 比如你懂深度学习,但想不出 “如何向非技术人员解释 Transformer”,可以让 LLM 生成多个版本,你筛选修改;
- 纯创意型任务(无正确性要求)—— 比如给科研项目起名字、设计技术分享的开场白。
不建议用的场景(坚决避开)
- 你 “不熟悉且要求 100% 准确” 的领域 —— 比如你不懂医学,却用 LLM 查病因(可能出错);
- 复杂计算任务 —— 比如矩阵运算、深度学习模型的梯度计算(LLM 容易算错,不如用 Python 代码或 Mathematica);
- 大量数据处理 —— 比如处理 10 万条实验数据(LLM 有输入长度限制,不如用 Pandas、TensorFlow)。
三、使用技巧:核心中的核心,学会“怎么用”
1.模型参数设置:控制输出的“随机性”和“重复性”
| 参数 | 作用 | 适用场景 | 不适用场景 |
|---|---|---|---|
| Temperature(温度) | 控制随机性:值越大(0.7-1.0),输出越发散;值越小(0.1-0.3),输出越固定 | 创意型任务(如头脑风暴、写文案) | 事实型任务(如查定义、学术问答) |
| Top P(核采样) | 和 Temperature 功能类似,值越大(0.9-1.0)随机性越强,越小(0.1-0.3)越固定 | 辅助 Temperature 微调(一般不同时调) | - |
| Frequency Penalty(频率惩罚) | 控制重复:值越大(0.5-1.0),越不容易重复已出现的词 / 句子 | 长文本生成(如写论文、技术文档) | 短文本(如单句问答) |
举例:你想让 LLM 生成 “深度学习项目的创新点”(创意任务),可以设 Temperature=0.8;想让 LLM 解释 “CNN 的卷积操作”(事实任务),设 Temperature=0.2。
2. 提示词设计的核心技巧(直接套用)
(1)避免模糊,明确需求 + 背景
- 反面例子(模糊):“我是小学生,怎么提高英语成绩”(LLM 只能给通用答案);
- 正面例子(明确):“我是一名深度学习方向的研究生,英语词汇还行,但学术论文写作时逻辑不清晰,如何在 1 个月内提升?”(LLM 会针对性给 “学术写作逻辑” 建议)。
你的应用:比如让 LLM 帮你调试代码,不要只说 “这段代码有问题”,要补充背景:“我用 PyTorch 写了一个 CNN 模型,训练时 loss 不下降,代码如下(贴代码),数据是 MNIST 数据集,麻烦帮我找问题”。
(2)设定 “角色”:让 LLM 更贴合你的需求
分两种角色设定,效果翻倍:
- 设定你自己的角色:比如 “我是深度学习初学者,你用通俗的语言解释 Transformer”“我是 AI 公司面试官,你模拟面试通义千问相关岗位”;
- 设定 LLM 的角色:比如 “你是资深 PyTorch 工程师,帮我优化这段代码的效率”“你是顶会审稿人,帮我评审这篇论文的创新点和不足”。
(3)提供 “背景 + 示例”:Few-shot 学习(关键技巧)
LLM 擅长 “模仿示例”,如果任务复杂,直接给示例比写长篇指令更有效
案例 1:文本分类(如学术文献情感倾向、论文主题分类)
任务:请根据论文摘要的主题,分为“深度学习”“机器学习”“强化学习”三类。
示例1:
文本:“本文提出一种基于Transformer的预训练模型,在自然语言处理任务上取得SOTA效果”
分类结果:深度学习
示例2:
文本:“本文用随机森林算法处理医疗数据,准确率达到85%”
分类结果:机器学习
示例3:
文本:“本文设计了一种基于DQN的智能体,在游戏环境中实现自主避障”
分类结果:强化学习
请对以下文本分类:
文本1:“本文通过Q-Learning优化机器人路径规划,实验证明鲁棒性提升20%”
文本2:“本文用CNN提取图像特征,结合注意力机制优化分类效果”
案例 2:命名实体识别(如提取文献中的 “模型名”“数据集名”)
任务:从学术文本中识别“模型名”“数据集名”“评价指标”三类实体。
示例1: 文本:“在CIFAR-10数据集上,ResNet-50的准确率达到92%,F1分数为0.91”
识别结果:
- 模型名:ResNet-50
- 数据集名:CIFAR-10
- 评价指标:准确率、F1分数
请对以下文本识别:
文本:“本文在MNIST数据集上测试ViT模型,召回率达到98%,耗时比CNN减少30%”
案例 3:文本匹配(如判断用户需求与产品是否匹配,可用于找论文、工具)
任务:判断“用户需求”与“论文主题”是否匹配(匹配指论文能解决需求核心问题)。
示例1:
用户需求:“寻找提升CNN图像分类准确率的方法”
论文主题:“基于注意力机制的CNN优化,在ImageNet上准确率提升5%”
匹配结果:匹配
示例2:
用户需求:“寻找提升CNN图像分类准确率的方法”
论文主题:“基于CNN的文本分类模型,在IMDB数据集上F1提升3%”
匹配结果:不匹配(论文是文本分类,需求是图像分类)
(4)其他实用技巧
- 合理用分隔符:用
、"""、<text>等符号包裹输入内容,帮模型区分“指令”和“数据”——比如“总结以下文献摘要:[摘要内容]```”; - 给模型 “拒识出口”:避免模型瞎猜 —— 比如 “如果文本中没有提到数据集名,输出‘未找到’”;
- 要求结构化输出:让结果更易处理 —— 比如 “用 JSON 格式输出识别结果,键为‘模型名’‘数据集名’”;
- 拆解复杂任务:把多步任务拆成单步,比如 “先翻译这段英文摘要,再总结核心观点,最后列出关键词”。
3. 提示词的结构化模板(直接抄)
模板 1:Role-Task-Format(角色 - 任务 - 格式)
角色:你是资深深度学习工程师,熟悉PyTorch框架和计算机视觉任务。
任务:帮我优化这段CNN模型的代码,提升训练速度,同时保证准确率不下降。
格式:输出“原代码问题→优化方案→优化后代码”三部分,优化方案需说明原理。
模板 2:Task-Action-Goal(任务 - 动作 - 目标)
任务:评估我设计的Transformer微调方案的合理性。
动作:1. 分析方案的数据集选择、超参数设置、训练策略;2. 指出潜在问题;3. 给出改进建议。
目标:让微调方案在文本分类任务上的F1分数提升至少3%。
模板 3:Context-Action-Result-Example(环境 - 行动 - 结果 - 例子)
环境:我在做一个基于GAN的图像生成项目,数据集是CelebA,目前生成图像模糊。
行动:帮我分析模糊的可能原因,给出3个具体的优化措施,每个措施附代码片段。
结果:生成图像的清晰度(PSNR指标)提升至少10%。
例子:比如“增加生成器的网络深度→代码片段:[示例代码]”。
4. 高级技巧:Function Call(插件 / 工具调用)
这部分是提示工程的进阶应用,核心是让 LLM “调用外部工具”,解决自身局限性(如时效性、复杂计算),适合你后续落地项目。
核心逻辑
LLM 相当于 “大脑”,插件 / 工具相当于 “手脚”——LLM 负责理解需求、判断该调用哪个工具,工具负责完成具体任务(如查天气、算数据、查最新文献)。
案例(旅游场景改编为你的科研场景)
你需要处理我的科研相关问题,可调用以下工具:
- get_latest_paper:查最新论文(需关键词、发表时间)
- calculate_metric:计算模型评价指标(需输入预测值、真实值、指标类型)
- recommend_tool:推荐深度学习工具(需任务类型、框架)
规则:
1. 按问题匹配工具:查论文用get_latest_paper,算指标用calculate_metric,找工具用recommend_tool;
2. 工具参数必须完整,缺失则追问(如没说论文关键词,问“请问你要查哪个方向的论文?”)。
用户问题:“我想找2024年发表的、关于扩散模型在图像生成的顶会论文,另外帮我计算一下我模型的F1分数(预测值:[列表],真实值:[列表]),再推荐一个PyTorch框架下的扩散模型训练工具。”
输出结果(模型自动调用工具)
<function_calls>[
{"name": "get_latest_paper", "parameters": {"关键词": "扩散模型 图像生成", "发表时间": "2024", "期刊类型": "顶会"}},
{"name": "calculate_metric", "parameters": {"预测值": [列表], "真实值": [列表], "指标类型": "F1"}},
{"name": "recommend_tool", "parameters": {"任务类型": "扩散模型训练", "框架": "PyTorch"}} ]
</function_calls>

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)