YOLOv11 改进 - Mamba | 集成Mamba-YOLO(AAAI 2025),Mamba-YOLOv11-B 替换骨干,破解全局依赖建模难题,实现高效实时检测
前言
本文介绍Mamba YOLO,为图片物体识别提供了“又快又准”的新方案。传统CNN架构运行快但难以捕捉远距离关联物体,Transformer架构精度高但计算量呈平方级增长,而SSM虽计算量为线性级且能抓全局关联,但用于图片识别时细节定位不准。为此,Mamba YOLO做了三项关键优化:引入ODMamba骨干网络,解决自注意力的二次复杂度问题,且无需预训练;设计ODMamba宏观结构确定最佳阶段比例和缩放大小;采用多分支结构的RG块建模通道维度,解决SSM在序列建模中的不足。在COCO数据集测试中,其小版本推理时间达1.5毫秒,mAP提高7.5%。
文章目录: YOLOv11改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLOv11改进专栏
介绍

摘要
在深度学习技术的快速发展推动下,YOLO系列为实时目标检测器设立了新的基准。此外,基于Transformer的结构已成为该领域最强大的解决方案,大大扩展了模型的感受野并实现了显著的性能提升。然而,这种改进是有代价的,因为自注意力机制的二次复杂度增加了模型的计算负担。为解决这一问题,我们提出了一种简单而有效的基线方法,称为Mamba YOLO。我们的贡献如下:
-
我们提出在ODMamba骨干网络中引入状态空间模型(SSM),以线性复杂度解决自注意力的二次复杂度问题。与其他基于Transformer和SSM的方法不同,ODMamba易于训练,不需要预训练。
-
针对实时性要求,我们设计了ODMamba的宏观结构,确定了最佳阶段比例和缩放大小。
-
我们设计了采用多分支结构的RG块来建模通道维度,这解决了SSM在序列建模中可能存在的限制,如感受野不足和图像定位能力弱等问题。这种设计更准确且显著地捕捉了局部图像依赖关系。
在公开的COCO基准数据集上进行的广泛实验表明,与先前的方法相比,Mamba YOLO实现了最先进的性能。具体来说,Mamba YOLO的微型版本在单个4090 GPU上实现了1.5毫秒的推理时间,mAP提高了7.5%。PyTorch代码可在以下链接获取:https://github.com/HZAIZJNU/Mamba-YOLO
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
Mamba YOLO,简单说就是给“识别图片里物体”的技术搞了个“又快又准”的新方案,解决了之前同类模型的痛点。
1. 为啥要搞这个新模型?
之前做“图片物体识别”(比如识别照片里的车、人、动物)的模型有两个大问题,有点“鱼和熊掌不可兼得”:
- 一类是老款CNN架构(比如早期YOLO):跑起来快,但只能关注图片局部,对“远距离关联的物体”(比如左上角和右下角的两只猫)捕捉不好,容易漏判或误判;
- 另一类是Transformer架构:能看清全局关联,精度高,但计算量是“平方级”的——图片越大、内容越复杂,计算量就暴涨,跑起来特别慢,没法满足“实时识别”(比如监控抓拍、自动驾驶)的需求。
后来出现了一种叫“SSM(状态空间模型)”的技术(比如Mamba架构),计算量是“线性级”的(图片变大,计算量稳步增加,不暴涨),还能抓全局关联,但它原本是用来处理文字的,直接套在图片识别上就“水土不服”——对图片的细节定位不准,也不会利用图片的多通道信息。
所以研究者就想:把SSM和YOLO结合,搞个“取长补短”的新模型,既快又准。
2. 新模型厉害在哪?(3个核心设计)
为了让SSM适配图片识别,研究者做了3个关键优化,相当于给模型“量身定制”了装备:
- 装备1:ODMamba骨干网络:把SSM改成了适合图片检测的结构,不用像Transformer那样先在超大数据集上“预热训练”(省了很多时间和资源),计算量还是线性的,解决了“慢”的问题;
- 装备2:RG Block(残差门控模块):SSM擅长看全局,但看不清局部细节(比如物体的边角、纹理),这个模块就像“双摄像头”——一个分支抓全局特征,一个分支抓局部细节,还能通过“筛选机制”留下有用信息,让物体定位更准;
- 装备3:Vision Clue Merge(视觉线索融合):之前的模型缩小图片尺寸时,容易丢很多关键细节(比如小物体的轮廓),这个设计能在缩小图片的同时,保住更多视觉信息,帮模型更好地识别物体。
另外还做了个贴心设计:搞了“小(Tiny)、中(Base)、大(Large)”三个版本——手机端用小版本(省电快),服务器端用大版本(精度高),适配不同场景。
3. 实际测试效果咋样?(真·又快又准)
在公开的COCO数据集(相当于图片识别的“高考”)上测试,结果很亮眼:
- 小版本(Mamba YOLO-T):在单块4090显卡上,1.5毫秒就能处理一张图(比眨眼睛快多了),精度比同级别其他模型高7.5%左右,而且需要的参数少了近一半(更轻量化);
- 中版本(Mamba YOLO-B):和同参数的模型比,精度高3.7%,跑起来还快1.8毫秒;
- 大版本(Mamba YOLO-L):和当前最顶尖的模型比,精度差不多甚至更高,但参数更少、跑起来更快,而且图片越大,优势越明显(其他模型图片变大后会变慢,它还是稳步高效)。
更厉害的是,在复杂场景下(比如物体重叠多、背景乱、有遮挡),它也能准确识别,比其他模型表现更稳。
4. 总结一下
Mamba YOLO是第一个把Mamba(SSM架构)用到“实时物体识别”的模型,核心就是“让文字领域的高效技术适配图片任务”。它不用复杂的预热训练,还能灵活适配不同设备,既解决了老模型“慢”或“不准”的问题,又填补了SSM在图片检测上的空白,给监控、自动驾驶、手机拍照识别等需要“又快又准”的场景,提供了一个更好的选择。
安装依赖
windows 安装环境比较复杂,建议使用linux
🚀🚀🚀 或者私信我给你提供现成的环境!!!!!!!!!!!!!
安装causal-conv1d和mamba-ssm
pip install causal-conv1d mamba-ssm>=1.2.0
解决报错:若有
RuntimeError: Expected u.is_cuda() to be true, but got false. (Could this error message be improved? If so, please report an enhancement request to PyTorch.)
在 "ultralytics-main/ultralytics/nn/tasks.py" 文件中,定位到 class DetectionModel(BaseModel): 下的以下代码行:
m.stride = torch.tensor([s / x.shape[-2] for x in _forward(torch.zeros(1, ch, s, s))]) # forward
将其替换为下列代码,即可完美解决该问题:
try:
m.stride = torch.tensor([s / x.shape[-2] for x in _forward(torch.zeros(1, ch, s, s))]) # forward on CPU
except RuntimeError:
try:
self.model.to(torch.device('cuda'))
m.stride = torch.tensor([s / x.shape[-2] for x in _forward(
torch.zeros(1, ch, s, s).to(torch.device('cuda')))]) # forward on CUDA
except RuntimeError as error:
raise error
YOLO11引入代码
在根目录下的ultralytics/nn/目录,新建一个 backbone目录,然后新建一个以 mamba_yolo为文件名的py文件, 把代码拷贝进去。
import torch
import math
from functools import partial
from typing import Callable, Any
import torch.nn as nn
from einops import rearrange, repeat
from timm.models.layers import DropPath
DropPath.__repr__ = lambda self: f"timm.DropPath({self.drop_prob})"
try:
import selective_scan_cuda_core
import selective_scan_cuda_oflex
import selective_scan_cuda_ndstate
import selective_scan_cuda_nrow
import selective_scan_cuda
except:
pass
try:
"sscore acts the same as mamba_ssm"
import selective_scan_cuda_core
except Exception as e:
print(e, flush=True)
"you should install mamba_ssm to use this"
SSMODE = "mamba_ssm"
import selective_scan_cuda
# from mamba_ssm.ops.selective_scan_interface import selective_scan_fn, selective_scan_ref
class LayerNorm2d(nn.Module):
def __init__(self, normalized_shape, eps=1e-6, elementwise_affine=True):
super().__init__()
self.norm = nn.LayerNorm(normalized_shape, eps, elementwise_affine)
def forward(self, x):
x = rearrange(x, 'b c h w -> b h w c').contiguous()
x = self.norm(x)
x = rearrange(x, 'b h w c -> b c h w').contiguous()
return x
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
# Cross Scan
class CrossScan(torch.autograd.Function):
@staticmethod
def forward(ctx, x: torch.Tensor):
B, C, H, W = x.shape
ctx.shape = (B, C, H, W)
xs = x.new_empty((B, 4, C, H * W))
xs[:, 0] = x.flatten(2, 3)
xs[:, 1] = x.transpose(dim0=2, dim1=3).flatten(2, 3)
xs[:, 2:4] = torch.flip(xs[:, 0:2], dims=[-1])
return xs
@staticmethod
def backward(ctx, ys: torch.Tensor):
# out: (b, k, d, l)
B, C, H, W = ctx.shape
L = H * W
ys = ys[:, 0:2] + ys[:, 2:4].flip(dims=[-1]).view(B, 2, -1, L)
y = ys[:, 0] + ys[:, 1].view(B, -1, W, H).transpose(dim0=2, dim1=3).contiguous().view(B, -1, L)
return y.view(B, -1, H, W)
class CrossMerge(torch.autograd.Function):
@staticmethod
def forward(ctx, ys: torch.Tensor):
B, K, D, H, W = ys.shape
ctx.shape = (H, W)
ys = ys.view(B, K, D, -1)
ys = ys[:, 0:2] + ys[:, 2:4].flip(dims=[-1]).view(B, 2, D, -1)
y = ys[:, 0] + ys[:, 1].view(B, -1, W, H).transpose(dim0=2, dim1=3).contiguous().view(B, D, -1)
return y
@staticmethod
def backward(ctx, x: torch.Tensor):
# B, D, L = x.shape
# out: (b, k, d, l)
H, W = ctx.shape
B, C, L = x.shape
xs = x.new_empty((B, 4, C, L))
xs[:, 0] = x
xs[:, 1] = x.view(B, C, H, W).transpose(dim0=2, dim1=3).flatten(2, 3)
xs[:, 2:4] = torch.flip(xs[:, 0:2], dims=[-1])
xs = xs.view(B, 4, C, H, W)
return xs, None, None
# cross selective scan ===============================
class SelectiveScanCore(torch.autograd.Function):
# comment all checks if inside cross_selective_scan
@staticmethod
@torch.cuda.amp.custom_fwd
def forward(ctx, u, delta, A, B, C, D=None, delta_bias=None, delta_softplus=False, nrows=1, backnrows=1,
oflex=True):
# all in float
if u.stride(-1) != 1:
u = u.contiguous()
if delta.stride(-1) != 1:
delta = delta.contiguous()
if D is not None and D.stride(-1) != 1:
D = D.contiguous()
if B.stride(-1) != 1:
B = B.contiguous()
if C.stride(-1) != 1:
C = C.contiguous()
if B.dim() == 3:
B = B.unsqueeze(dim=1)
ctx.squeeze_B = True
if C.dim() == 3:
C = C.unsqueeze(dim=1)
ctx.squeeze_C = True
ctx.delta_softplus = delta_softplus
ctx.backnrows = backnrows
out, x, *rest = selective_scan_cuda_core.fwd(u, delta, A, B, C, D, delta_bias, delta_softplus, 1)
ctx.save_for_backward(u, delta, A, B, C, D, delta_bias, x)
return out
@staticmethod
@torch.cuda.amp.custom_bwd
def backward(ctx, dout, *args):
u, delta, A, B, C, D, delta_bias, x = ctx.saved_tensors
if dout.stride(-1) != 1:
dout = dout.contiguous()
du, ddelta, dA, dB, dC, dD, ddelta_bias, *rest = selective_scan_cuda_core.bwd(
u, delta, A, B, C, D, delta_bias, dout, x, ctx.delta_softplus, 1
)
return (du, ddelta, dA, dB, dC, dD, ddelta_bias, None, None, None, None)
def cross_selective_scan(
x: torch.Tensor = None,
x_proj_weight: torch.Tensor = None,
x_proj_bias: torch.Tensor = None,
dt_projs_weight: torch.Tensor = None,
dt_projs_bias: torch.Tensor = None,
A_logs: torch.Tensor = None,
Ds: torch.Tensor = None,
out_norm: torch.nn.Module = None,
out_norm_shape="v0",
nrows=-1, # for SelectiveScanNRow
backnrows=-1, # for SelectiveScanNRow
delta_softplus=True,
to_dtype=True,
force_fp32=False, # False if ssoflex
ssoflex=True,
SelectiveScan=None,
scan_mode_type='default'
):
# out_norm: whatever fits (B, L, C); LayerNorm; Sigmoid; Softmax(dim=1);...
B, D, H, W = x.shape
D, N = A_logs.shape
K, D, R = dt_projs_weight.shape
L = H * W
def selective_scan(u, delta, A, B, C, D=None, delta_bias=None, delta_softplus=True):
return SelectiveScan.apply(u, delta, A, B, C, D, delta_bias, delta_softplus, nrows, backnrows, ssoflex)
xs = CrossScan.apply(x)
x_dbl = torch.einsum("b k d l, k c d -> b k c l", xs, x_proj_weight)
if x_proj_bias is not None:
x_dbl = x_dbl + x_proj_bias.view(1, K, -1, 1)
dts, Bs, Cs = torch.split(x_dbl, [R, N, N], dim=2)
dts = torch.einsum("b k r l, k d r -> b k d l", dts, dt_projs_weight)
xs = xs.view(B, -1, L)
dts = dts.contiguous().view(B, -1, L)
# HiPPO matrix
As = -torch.exp(A_logs.to(torch.float)) # (k * c, d_state)
Bs = Bs.contiguous()
Cs = Cs.contiguous()
Ds = Ds.to(torch.float) # (K * c)
delta_bias = dt_projs_bias.view(-1).to(torch.float)
if force_fp32:
xs = xs.to(torch.float)
dts = dts.to(torch.float)
Bs = Bs.to(torch.float)
Cs = Cs.to(torch.float)
ys: torch.Tensor = selective_scan(
xs, dts, As, Bs, Cs, Ds, delta_bias, delta_softplus
).view(B, K, -1, H, W)
y: torch.Tensor = CrossMerge.apply(ys)
if out_norm_shape in ["v1"]: # (B, C, H, W)
y = out_norm(y.view(B, -1, H, W)).permute(0, 2, 3, 1) # (B, H, W, C)
else: # (B, L, C)
y = y.transpose(dim0=1, dim1=2).contiguous() # (B, L, C)
y = out_norm(y).view(B, H, W, -1)
return (y.to(x.dtype) if to_dtype else y)
class SS2D(nn.Module):
def __init__(
self,
# basic dims ===========
d_model=96,
d_state=16,
ssm_ratio=2.0,
ssm_rank_ratio=2.0,
dt_rank="auto",
act_layer=nn.SiLU,
# dwconv ===============
d_conv=3, # < 2 means no conv
conv_bias=True,
# ======================
dropout=0.0,
bias=False,
# ======================
forward_type="v2",
**kwargs,
):
"""
ssm_rank_ratio would be used in the future...
"""
factory_kwargs = {"device": None, "dtype": None}
super().__init__()
d_expand = int(ssm_ratio * d_model)
d_inner = int(min(ssm_rank_ratio, ssm_ratio) * d_model) if ssm_rank_ratio > 0 else d_expand
self.dt_rank = math.ceil(d_model / 16) if dt_rank == "auto" else dt_rank
self.d_state = math.ceil(d_model / 6) if d_state == "auto" else d_state # 20240109
self.d_conv = d_conv
self.K = 4
# tags for forward_type ==============================
def checkpostfix(tag, value):
ret = value[-len(tag):] == tag
if ret:
value = value[:-len(tag)]
return ret, value
self.disable_force32, forward_type = checkpostfix("no32", forward_type)
self.disable_z, forward_type = checkpostfix("noz", forward_type)
self.disable_z_act, forward_type = checkpostfix("nozact", forward_type)
self.out_norm = nn.LayerNorm(d_inner)
# forward_type debug =======================================
FORWARD_TYPES = dict(
v2=partial(self.forward_corev2, force_fp32=None, SelectiveScan=SelectiveScanCore),
)
self.forward_core = FORWARD_TYPES.get(forward_type, FORWARD_TYPES.get("v2", None))
# in proj =======================================
d_proj = d_expand if self.disable_z else (d_expand * 2)
self.in_proj = nn.Conv2d(d_model, d_proj, kernel_size=1, stride=1, groups=1, bias=bias, **factory_kwargs)
self.act: nn.Module = nn.GELU()
# conv =======================================
if self.d_conv > 1:
self.conv2d = nn.Conv2d(
in_channels=d_expand,
out_channels=d_expand,
groups=d_expand,
bias=conv_bias,
kernel_size=d_conv,
padding=(d_conv - 1) // 2,
**factory_kwargs,
)
# rank ratio =====================================
self.ssm_low_rank = False
if d_inner < d_expand:
self.ssm_low_rank = True
self.in_rank = nn.Conv2d(d_expand, d_inner, kernel_size=1, bias=False, **factory_kwargs)
self.out_rank = nn.Linear(d_inner, d_expand, bias=False, **factory_kwargs)
# x proj ============================
self.x_proj = [
nn.Linear(d_inner, (self.dt_rank + self.d_state * 2), bias=False,
**factory_kwargs)
for _ in range(self.K)
]
self.x_proj_weight = nn.Parameter(torch.stack([t.weight for t in self.x_proj], dim=0)) # (K, N, inner)
del self.x_proj
# out proj =======================================
self.out_proj = nn.Conv2d(d_expand, d_model, kernel_size=1, stride=1, bias=bias, **factory_kwargs)
self.dropout = nn.Dropout(dropout) if dropout > 0. else nn.Identity()
# simple init dt_projs, A_logs, Ds
self.Ds = nn.Parameter(torch.ones((self.K * d_inner)))
self.A_logs = nn.Parameter(
torch.zeros((self.K * d_inner, self.d_state))) # A == -A_logs.exp() < 0; # 0 < exp(A * dt) < 1
self.dt_projs_weight = nn.Parameter(torch.randn((self.K, d_inner, self.dt_rank)))
self.dt_projs_bias = nn.Parameter(torch.randn((self.K, d_inner)))
@staticmethod
def dt_init(dt_rank, d_inner, dt_scale=1.0, dt_init="random", dt_min=0.001, dt_max=0.1, dt_init_floor=1e-4,
**factory_kwargs):
dt_proj = nn.Linear(dt_rank, d_inner, bias=True, **factory_kwargs)
# Initialize special dt projection to preserve variance at initialization
dt_init_std = dt_rank ** -0.5 * dt_scale
if dt_init == "constant":
nn.init.constant_(dt_proj.weight, dt_init_std)
elif dt_init == "random":
nn.init.uniform_(dt_proj.weight, -dt_init_std, dt_init_std)
else:
raise NotImplementedError
# Initialize dt bias so that F.softplus(dt_bias) is between dt_min and dt_max
dt = torch.exp(
torch.rand(d_inner, **factory_kwargs) * (math.log(dt_max) - math.log(dt_min))
+ math.log(dt_min)
).clamp(min=dt_init_floor)
# Inverse of softplus: https://github.com/pytorch/pytorch/issues/72759
inv_dt = dt + torch.log(-torch.expm1(-dt))
with torch.no_grad():
dt_proj.bias.copy_(inv_dt)
# Our initialization would set all Linear.bias to zero, need to mark this one as _no_reinit
# dt_proj.bias._no_reinit = True
return dt_proj
@staticmethod
def A_log_init(d_state, d_inner, copies=-1, device=None, merge=True):
# S4D real initialization
A = repeat(
torch.arange(1, d_state + 1, dtype=torch.float32, device=device),
"n -> d n",
d=d_inner,
).contiguous()
A_log = torch.log(A) # Keep A_log in fp32
if copies > 0:
A_log = repeat(A_log, "d n -> r d n", r=copies)
if merge:
A_log = A_log.flatten(0, 1)
A_log = nn.Parameter(A_log)
A_log._no_weight_decay = True
return A_log
@staticmethod
def D_init(d_inner, copies=-1, device=None, merge=True):
# D "skip" parameter
D = torch.ones(d_inner, device=device)
if copies > 0:
D = repeat(D, "n1 -> r n1", r=copies)
if merge:
D = D.flatten(0, 1)
D = nn.Parameter(D) # Keep in fp32
D._no_weight_decay = True
return D
def forward_corev2(self, x: torch.Tensor, channel_first=False, SelectiveScan=SelectiveScanCore,
cross_selective_scan=cross_selective_scan, force_fp32=None):
force_fp32 = (self.training and (not self.disable_force32)) if force_fp32 is None else force_fp32
if not channel_first:
x = x.permute(0, 3, 1, 2).contiguous()
if self.ssm_low_rank:
x = self.in_rank(x)
x = cross_selective_scan(
x, self.x_proj_weight, None, self.dt_projs_weight, self.dt_projs_bias,
self.A_logs, self.Ds,
out_norm=getattr(self, "out_norm", None),
out_norm_shape=getattr(self, "out_norm_shape", "v0"),
delta_softplus=True, force_fp32=force_fp32,
SelectiveScan=SelectiveScan, ssoflex=self.training, # output fp32
)
if self.ssm_low_rank:
x = self.out_rank(x)
return x
def forward(self, x: torch.Tensor, **kwargs):
x = self.in_proj(x)
if not self.disable_z:
x, z = x.chunk(2, dim=1) # (b, d, h, w)
if not self.disable_z_act:
z1 = self.act(z)
if self.d_conv > 0:
x = self.conv2d(x) # (b, d, h, w)
x = self.act(x)
y = self.forward_core(x, channel_first=(self.d_conv > 1))
y = y.permute(0, 3, 1, 2).contiguous()
if not self.disable_z:
y = y * z1
out = self.dropout(self.out_proj(y))
return out
class RGBlock(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.,
channels_first=False):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
hidden_features = int(2 * hidden_features / 3)
self.fc1 = nn.Conv2d(in_features, hidden_features * 2, kernel_size=1)
self.dwconv = nn.Conv2d(hidden_features, hidden_features, kernel_size=3, stride=1, padding=1, bias=True,
groups=hidden_features)
self.act = act_layer()
self.fc2 = nn.Conv2d(hidden_features, out_features, kernel_size=1)
self.drop = nn.Dropout(drop)
def forward(self, x):
x, v = self.fc1(x).chunk(2, dim=1)
x = self.act(self.dwconv(x) + x) * v
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class LSBlock(nn.Module):
def __init__(self, in_features, hidden_features=None, act_layer=nn.GELU, drop=0):
super().__init__()
self.fc1 = nn.Conv2d(in_features, hidden_features, kernel_size=3, padding=3 // 2, groups=hidden_features)
self.norm = nn.BatchNorm2d(hidden_features)
self.fc2 = nn.Conv2d(hidden_features, hidden_features, kernel_size=1, padding=0)
self.act = act_layer()
self.fc3 = nn.Conv2d(hidden_features, in_features, kernel_size=1, padding=0)
self.drop = nn.Dropout(drop)
def forward(self, x):
input = x
x = self.fc1(x)
x = self.norm(x)
x = self.fc2(x)
x = self.act(x)
x = self.fc3(x)
x = input + self.drop(x)
return x
class XSSBlock(nn.Module):
def __init__(
self,
in_channels: int = 0,
hidden_dim: int = 0,
n: int = 1,
mlp_ratio=4.0,
drop_path: float = 0,
norm_layer: Callable[..., torch.nn.Module] = partial(LayerNorm2d, eps=1e-6),
# =============================
ssm_d_state: int = 16,
ssm_ratio=2.0,
ssm_rank_ratio=2.0,
ssm_dt_rank: Any = "auto",
ssm_act_layer=nn.SiLU,
ssm_conv: int = 3,
ssm_conv_bias=True,
ssm_drop_rate: float = 0,
ssm_init="v0",
forward_type="v2",
# =============================
mlp_act_layer=nn.GELU,
mlp_drop_rate: float = 0.0,
# =============================
use_checkpoint: bool = False,
post_norm: bool = False,
**kwargs,
):
super().__init__()
self.in_proj = nn.Sequential(
nn.Conv2d(in_channels, hidden_dim, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.SiLU()
) if in_channels != hidden_dim else nn.Identity()
self.hidden_dim = hidden_dim
# ==========SSM============================
self.norm = norm_layer(hidden_dim)
self.ss2d = nn.Sequential(*(SS2D(d_model=self.hidden_dim,
d_state=ssm_d_state,
ssm_ratio=ssm_ratio,
ssm_rank_ratio=ssm_rank_ratio,
dt_rank=ssm_dt_rank,
act_layer=ssm_act_layer,
d_conv=ssm_conv,
conv_bias=ssm_conv_bias,
dropout=ssm_drop_rate, ) for _ in range(n)))
self.drop_path = DropPath(drop_path)
self.lsblock = LSBlock(hidden_dim, hidden_dim)
self.mlp_branch = mlp_ratio > 0
if self.mlp_branch:
self.norm2 = norm_layer(hidden_dim)
mlp_hidden_dim = int(hidden_dim * mlp_ratio)
self.mlp = RGBlock(in_features=hidden_dim, hidden_features=mlp_hidden_dim, act_layer=mlp_act_layer,
drop=mlp_drop_rate)
def forward(self, input):
input = self.in_proj(input)
# ====================
X1 = self.lsblock(input)
input = input + self.drop_path(self.ss2d(self.norm(X1)))
# ===================
if self.mlp_branch:
input = input + self.drop_path(self.mlp(self.norm2(input)))
return input
class VSSBlock(nn.Module):
def __init__(
self,
in_channels: int = 0,
hidden_dim: int = 0,
drop_path: float = 0,
norm_layer: Callable[..., torch.nn.Module] = partial(LayerNorm2d, eps=1e-6),
# =============================
ssm_d_state: int = 16,
ssm_ratio=2.0,
ssm_rank_ratio=2.0,
ssm_dt_rank: Any = "auto",
ssm_act_layer=nn.SiLU,
ssm_conv: int = 3,
ssm_conv_bias=True,
ssm_drop_rate: float = 0,
ssm_init="v0",
forward_type="v2",
# =============================
mlp_ratio=4.0,
mlp_act_layer=nn.GELU,
mlp_drop_rate: float = 0.0,
# =============================
use_checkpoint: bool = False,
post_norm: bool = False,
**kwargs,
):
super().__init__()
self.ssm_branch = ssm_ratio > 0
self.mlp_branch = mlp_ratio > 0
self.use_checkpoint = use_checkpoint
self.post_norm = post_norm
# proj
self.proj_conv = nn.Sequential(
nn.Conv2d(in_channels, hidden_dim, kernel_size=1, stride=1, padding=0, bias=True),
nn.BatchNorm2d(hidden_dim),
nn.SiLU()
)
if self.ssm_branch:
self.norm = norm_layer(hidden_dim)
self.op = SS2D(
d_model=hidden_dim,
d_state=ssm_d_state,
ssm_ratio=ssm_ratio,
ssm_rank_ratio=ssm_rank_ratio,
dt_rank=ssm_dt_rank,
act_layer=ssm_act_layer,
# ==========================
d_conv=ssm_conv,
conv_bias=ssm_conv_bias,
# ==========================
dropout=ssm_drop_rate,
# bias=False,
# ==========================
# dt_min=0.001,
# dt_max=0.1,
# dt_init="random",
# dt_scale="random",
# dt_init_floor=1e-4,
initialize=ssm_init,
# ==========================
forward_type=forward_type,
)
self.drop_path = DropPath(drop_path)
self.lsblock = LSBlock(hidden_dim, hidden_dim)
if self.mlp_branch:
self.norm2 = norm_layer(hidden_dim)
mlp_hidden_dim = int(hidden_dim * mlp_ratio)
self.mlp = RGBlock(in_features=hidden_dim, hidden_features=mlp_hidden_dim, act_layer=mlp_act_layer,
drop=mlp_drop_rate, channels_first=False)
def forward(self, input: torch.Tensor):
input = self.proj_conv(input)
X1 = self.lsblock(input)
x = input + self.drop_path(self.op(self.norm(X1)))
if self.mlp_branch:
x = x + self.drop_path(self.mlp(self.norm2(x))) # FFN
return x
class SimpleStem(nn.Module):
def __init__(self, inp, embed_dim, ks=3):
super().__init__()
self.hidden_dims = embed_dim // 2
self.conv = nn.Sequential(
nn.Conv2d(inp, self.hidden_dims, kernel_size=ks, stride=2, padding=autopad(ks, d=1), bias=False),
nn.BatchNorm2d(self.hidden_dims),
nn.GELU(),
nn.Conv2d(self.hidden_dims, embed_dim, kernel_size=ks, stride=2, padding=autopad(ks, d=1), bias=False),
nn.BatchNorm2d(embed_dim),
nn.SiLU(),
)
def forward(self, x):
return self.conv(x)
class VisionClueMerge(nn.Module):
def __init__(self, dim, out_dim):
super().__init__()
self.hidden = int(dim * 4)
self.pw_linear = nn.Sequential(
nn.Conv2d(self.hidden, out_dim, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(out_dim),
nn.SiLU()
)
def forward(self, x):
y = torch.cat([
x[..., ::2, ::2],
x[..., 1::2, ::2],
x[..., ::2, 1::2],
x[..., 1::2, 1::2]
], dim=1)
return self.pw_linear(y)
注册
在ultralytics/nn/tasks.py中进行如下操作:
步骤1:
from ultralytics.nn.backbone.mamba_yolo import VSSBlock_YOLO, SimpleStem, VisionClueMerge, XSSBlock
步骤2
修改def parse_model(d, ch, verbose=True):
VSSBlock, SimpleStem, VisionClueMerge, XSSBlock

配置Mamba-YOLO-B.yaml
ultralytics/cfg/models/11/Mamba-YOLO-B.yaml
nc: 80 # number of classes
scales: # [depth, width, max_channels]
B: [0.33, 0.50, 1024] # Mamba-YOLOv8-B summary: 21.8M parameters, 49.7 GFLOPs
# Mamba-YOLO backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, SimpleStem, [128, 3]] # 0-P2/4
- [-1, 3, VSSBlock, [128]] # 1
- [-1, 1, VisionClueMerge, [256]] # 2 p3/8
- [-1, 3, VSSBlock, [256]] # 3
- [-1, 1, VisionClueMerge, [512]] # 4 p4/16
- [-1, 9, VSSBlock, [512]] # 5
- [-1, 1, VisionClueMerge, [1024]] # 6 p5/32
- [-1, 3, VSSBlock, [1024]] # 7
- [-1, 1, SPPF, [1024, 5]] # 8
# Mamba-YOLO PAFPN
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 5], 1, Concat, [1]] # cat backbone P4
- [-1, 3, XSSBlock, [512]] # 11
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 3], 1, Concat, [1]] # cat backbone P3
- [-1, 3, XSSBlock, [256]] # 14 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 11], 1, Concat, [1]] # cat head P4
- [-1, 3, XSSBlock, [512]] # 17 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 8], 1, Concat, [1]] # cat head P5
- [-1, 3, XSSBlock, [1024]] # 20 (P5/32-large)
- [[14, 17, 20], 1, Detect, [nc]] # Detect(P3, P4, P5)
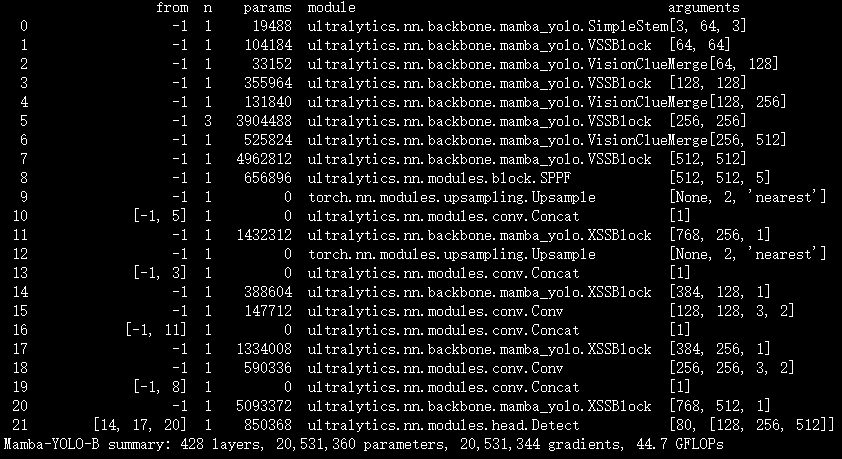
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('/root/ultralytics-main/ultralytics/cfg/models/11/Mamba-YOLO-B.yaml')
# 修改为自己的数据集地址
model.train(data='/root/ultralytics-main/ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='SGD',
amp=True,
project='runs/train',
name='Mamba-YOLO-B',
)
结果

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)