综合实践—融合大模型的论文知识图谱问答系统设计
数据集来源于Web of Science核心合集数据库,通过定向爬取的方式获取,共包含1000篇学术论文。论文主要分布于统计学、计算机科学与数据科学等相关研究领域,具有较强的学科代表性和交叉性。字段名含义说明paper_ID论文唯一标识,用于知识图谱中论文节点的主键url论文在 Web of Science 中的原始访问链接title论文标题publisher论文发表期刊或出版商名称DOI数字对象
随着学术文献数量的快速增长,传统基于关键词的文献检索方式在应对复杂语义查询、多维条件筛选及关联关系分析等方面逐渐显现出局限性。如何对大规模论文数据进行结构化组织,并实现高效、灵活的智能查询,成为学术信息管理与分析中的重要问题。知识图谱通过将实体及其关系进行显式建模,能够有效表达论文之间及其元数据之间的语义关联,为学术数据的深度挖掘与智能检索提供了新的解决思路。
本实验以学术论文数据为研究对象,构建论文知识图谱,并分别基于 Neo4j 和 TuGraph 两种图数据库平台完成图模型设计、数据导入与查询验证。在此基础上,引入大语言模型,将用户的自然语言问题自动转换为 Cypher 查询语句,实现面向普通用户的论文智能问答系统。
一、数据集介绍
1. 数据来源
数据集来源于Web of Science核心合集数据库,通过定向爬取的方式获取,共包含1000篇学术论文。论文主要分布于统计学、计算机科学与数据科学等相关研究领域,具有较强的学科代表性和交叉性。
数据集包含以下字段:
|
字段名 |
含义说明 |
|
paper_ID |
论文唯一标识,用于知识图谱中论文节点的主键 |
|
url |
论文在 Web of Science 中的原始访问链接 |
|
title |
论文标题 |
|
publisher |
论文发表期刊或出版商名称 |
|
DOI |
数字对象唯一标识符(Digital Object Identifier) |
|
abstract |
论文摘要内容 |
|
keywords |
论文关键词,反映研究主题与方向 |
|
citations |
论文被引次数 |
|
reference_num |
论文参考文献数量 |
|
year |
论文发表年份 |
|
author |
论文作者信息 |
|
institutions |
作者所属机构信息 |
该数据集可用于构建论文查询知识图谱和对话系统,适用于论文关联分析、研究主题挖掘以及学术影响力分析等应用场景。
2. 数据预处理
在数据预处理阶段,实验对原始数据进行了字段清洗与规范化处理,包括缺失值检查、字段类型统一以及实体去重等操作,以保证后续知识图谱构建的准确性和一致性。
运行脚本paper_clean.py:
import pandas as pd
import ast
import re
# 1. 读取数据
df = pd.read_csv("paper_sample_1000.csv")
print("原始数据量:", df.shape)
# 2. 去重
# 优先使用 DOI,其次 paper_ID
df = df.drop_duplicates(subset=["DOI"], keep="first")
df = df.drop_duplicates(subset=["paper_ID"], keep="first")
# 3. 缺失值处理
text_cols = [
"title", "publisher", "DOI", "abstract",
"keywords", "author", "institutions"
]
for col in text_cols:
df[col] = df[col].fillna("")
num_cols = ["citations", "reference_num", "year"]
for col in num_cols:
df[col] = pd.to_numeric(df[col], errors="coerce").fillna(0).astype(int)
# 4. 文本清洗函数
def clean_text(text):
text = str(text)
text = re.sub(r"\s+", " ", text) # 多空格合并
text = text.strip()
return text
df["title"] = df["title"].apply(clean_text)
df["abstract"] = df["abstract"].apply(clean_text)
df["publisher"] = df["publisher"].apply(clean_text)
# 5. 关键词清洗
# 原始格式:['xxx', 'yyy', ...]
def clean_list_field(x):
try:
if isinstance(x, str) and x.startswith("["):
items = ast.literal_eval(x)
items = [i.strip() for i in items if i and i != "[Not available]"]
return ";".join(sorted(set(items)))
else:
return ""
except:
return ""
df["keywords"] = df["keywords"].apply(clean_list_field)
# 6. 作者字段清洗
df["author"] = df["author"].apply(lambda x: clean_text(x.replace("@", ";")))
# 7. 机构字段清洗
df["institutions"] = df["institutions"].apply(clean_list_field)
# 8. 年份合理性约束
df = df[(df["year"] >= 1900) & (df["year"] <= 2025)]
# 9. 最终字段顺序整理
final_cols = [
"paper_ID", "title", "year", "publisher", "DOI",
"abstract", "keywords", "author", "institutions",
"citations", "reference_num", "url"
]
df = df[final_cols]
print("清洗后数据量:", df.shape)
# 10. 保存清洗后的数据
df.to_csv("paper_kg_cleaned.csv", index=False, encoding="utf-8-sig")
print("数据清洗完成,已保存为 paper_kg_cleaned.csv")
清洗后的数据剩余980篇论文,将其转换为适合图数据库导入的格式,并分别导入 Neo4j 与 TuGraph 平台,用于对比不同图数据库在数据建模、查询能力及系统集成方面的表现。
3. 数据描述性分析
运行代码 data_analyze.py 查看清洗后数据基本情况:
import pandas as pd
# 1. 读取清洗后的数据
df = pd.read_csv("paper_kg_cleaned.csv")
print("========== 数据集基本规模 ==========")
print(f"论文总数:{df.shape[0]}")
print(f"字段数量:{df.shape[1]}")
# 2. 年份分布
print("\n========== 发表年份分布 ==========")
print(df["year"].describe())
print(df["year"].value_counts().sort_index().head(10))
# 3. 被引次数统计
print("\n========== 被引次数统计 ==========")
print(df["citations"].describe())
# 4. 参考文献数量统计
print("\n========== 参考文献数量统计 ==========")
print(df["reference_num"].describe())
# 5. 期刊 / 出版商分布(Top 10)
print("\n========== 主要出版期刊(Top 10) ==========")
print(df["publisher"].value_counts().head(10))
# 6. 关键词统计(Top 10)
print("\n========== 高频关键词(Top 10) ==========")
keywords_series = (
df["keywords"]
.dropna()
.str.split(";")
.explode()
.str.strip()
)
print(keywords_series.value_counts().head(10))
# 7. 作者数量统计(每篇论文)
print("\n========== 每篇论文作者数量统计 ==========")
df["author_count"] = df["author"].fillna("").apply(
lambda x: len([a for a in x.split(";") if a.strip() != ""])
)
print(df["author_count"].describe())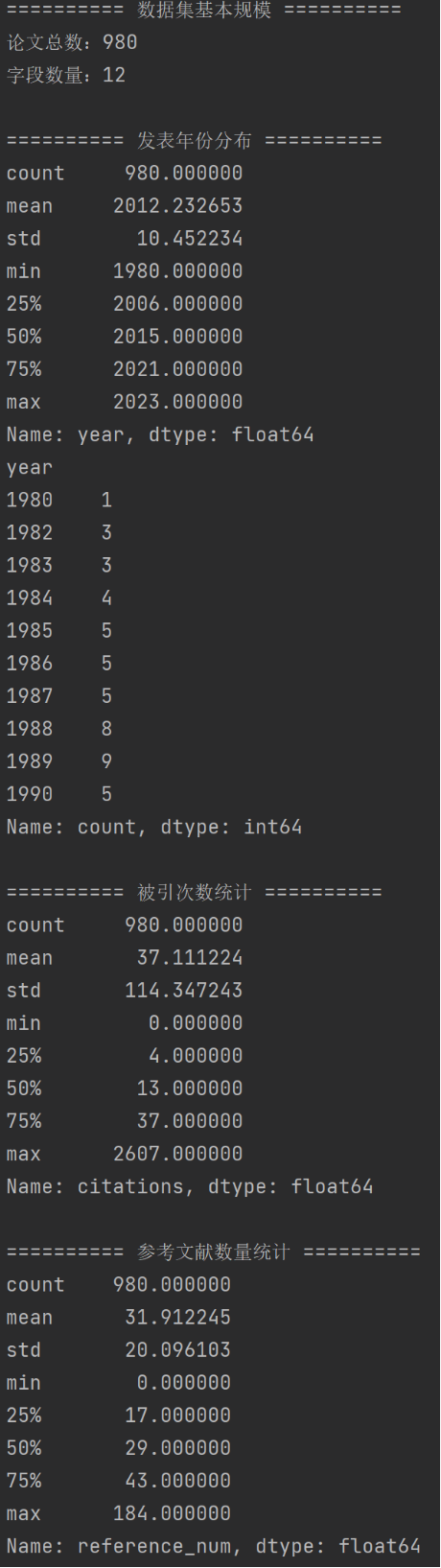
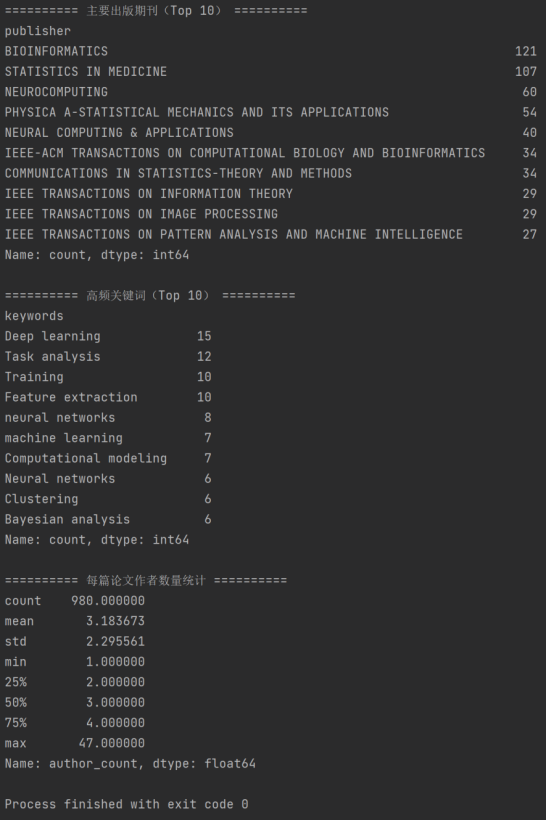
根据以上运行结果,可得出数据集具有以下特征:
① 数据规模适中、结构完整:
数据集共包含 980 篇论文、12 个字段,规模适中、信息维度较为全面,既能够支撑知识图谱中多实体、多关系的构建,又便于后续查询和对话系统的实现。
② 时间跨度大、覆盖长期研究成果:
从论文发表年份来看,数据集中论文的发表时间跨度较大,最早可追溯至 1980 年,最新论文发表于 2023 年,覆盖了四十余年的研究成果,能够反映研究主题的长期演进趋势。
③ 论文整体偏向近十余年发表:
论文发表年份的中位数为 2015 年,约一半论文集中在 2006 年之后,说明数据集整体偏向近年来的研究成果,具有较强的现实参考价值。
④ 被引次数分布不均、头部效应明显:
论文被引次数差异较大,平均被引次数为 37 次,但中位数仅为 13 次,少数高被引论文显著拉高整体均值,符合学术论文引用的典型分布特征。
⑤ 参考文献数量处于合理区间:
每篇论文平均引用参考文献约 32 篇,大多数论文集中在 17 至 43 篇之间,表明论文在研究深度和文献覆盖范围上整体较为均衡。
⑥ 期刊分布相对集中、研究领域明确:
论文主要发表于 Bioinformatics、Statistics in Medicine、Neurocomputing 等期刊,说明数据集在统计分析、机器学习和计算方法等方向具有较强的集中性。
二、基于neo4j平台实现完整的知识图谱对话系统
1. 启动并登录 Neo4j 图形化界面
启动docker,用powershell指令进入windows命令行,输入docker images,查看是否有名字叫docker.1ms.run/library/neo4j的镜像。
命令行输入:
docker run --publish=7475:7474 --publish=7688:7687 `--volume="//c/Users/zhang/Desktop/专业综合实践/data:/data" `--volume="//c/Users/zhang/Desktop/专业综合实践/import:/import" `docker.1ms.run/library/neo4j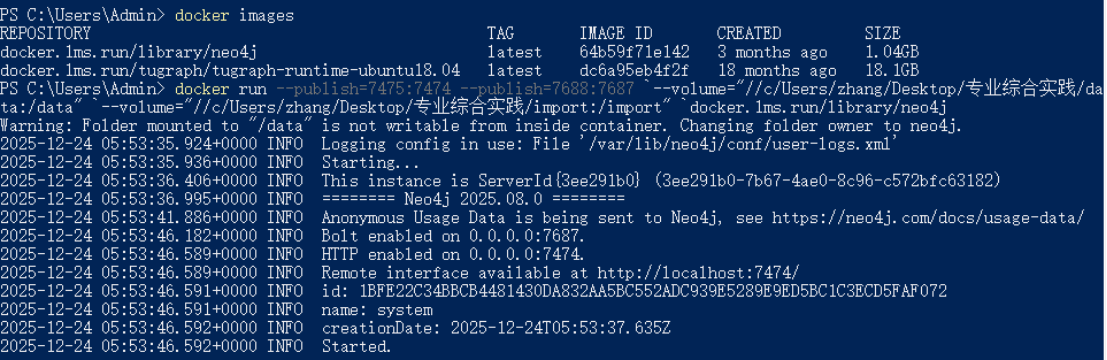
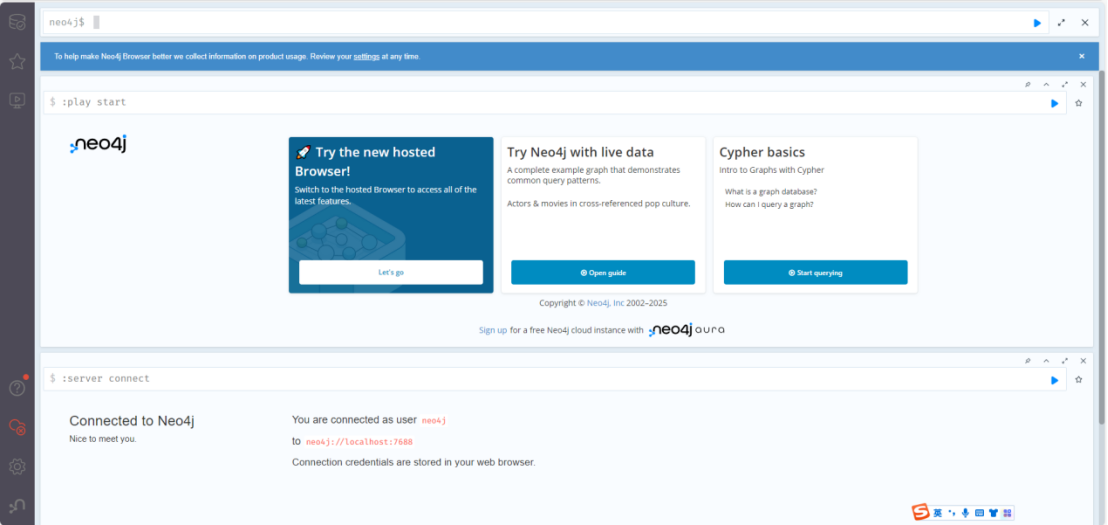
打开浏览器,在浏览器地址栏输入:localhost:7475
输入用户名和密码,进入图形化操作界面
2. 知识图谱模式设计(Schema 设计)
(1)节点类型设计
根据论文数据集字段结构,实验中主要设计了以下节点类型:
-
Paper:论文实体,核心节点
-
关键属性:paper_ID、title、year、publisher 等
-
-
Author:作者实体
-
Keyword:关键词实体
-
Publisher / Journal:期刊实体
-
Reference:参考文献相关实体(如被引用论文或引用数量)
其中,Paper 节点作为知识图谱的中心节点,与作者、关键词、期刊等实体建立多种关联关系。
(2)关系类型设计
围绕论文实体,主要构建如下关系类型:
-
(Paper)-[:HAS_AUTHOR]->(Author) -
(Paper)-[:HAS_KEYWORD]->(Keyword) -
(Paper)-[:PUBLISHED_IN]->(Publisher) -
(Paper)-[:HAS_REFERENCE]->(Reference) -
(Paper)-[:HAS_YEAR]->(Year)
上述关系能够较完整地描述论文的基本学术属性,并支持后续多维查询需求。
3. Neo4j 数据导入
在桌面上新建文件夹“专业综合实践”,将数据集放在import文件夹下。
代码:neo4j_import.py
#!/usr/bin/env python3
# coding: utf-8
from py2neo import Graph, Node
import pandas as pd
import os
class PaperGraph:
def __init__(self):
# 数据路径
desktop = os.path.join(os.path.expanduser('~'), 'Desktop')
self.data_path = os.path.join(
desktop, '专业综合实践/import/paper_kg_cleaned.csv'
)
# Neo4j 连接
self.graph = Graph(
"bolt://localhost:7688",
auth=("neo4j", "rxt0413zC")
)
def read_file(self):
"""
读取 CSV 文件
"""
df = pd.read_csv(self.data_path)
print(f"数据集加载完成,总共 {df.shape[0]} 条记录")
return df
def clear_graph(self):
"""
可选:清空数据库
"""
self.graph.run("MATCH (n) DETACH DELETE n")
print("图数据库已清空")
def create_paper_nodes(self, batch_size=50):
"""
创建 Paper 节点,支持批量事务提交,处理缺失值和类型
"""
df = self.read_file()
total = df.shape[0]
count = 0
tx = self.graph.begin() # 开启事务
for _, row in df.iterrows():
# 类型处理
try:
year = int(row["year"]) if pd.notna(row["year"]) else None
except:
year = None
try:
citations = int(row["citations"]) if pd.notna(row["citations"]) else 0
except:
citations = 0
try:
reference_num = int(row["reference_num"]) if pd.notna(row["reference_num"]) else 0
except:
reference_num = 0
# 创建节点
node = Node(
"Paper",
paper_ID=row.get("paper_ID", ""),
title=row.get("title", ""),
year=year,
publisher=row.get("publisher", ""),
DOI=row.get("DOI", ""),
abstract=row.get("abstract", ""),
keywords=row.get("keywords", ""),
author=row.get("author", ""),
institutions=row.get("institutions", ""),
citations=citations,
reference_num=reference_num,
url=row.get("url", "")
)
tx.create(node)
count += 1
# 批量提交
if count % batch_size == 0 or count == total:
tx.commit()
tx = self.graph.begin()
print(f"已创建 {count}/{total} 个 Paper 节点")
print("所有 Paper 节点创建完成!")
if __name__ == "__main__":
handler = PaperGraph()
# 如果需要重建图,先清空数据库
# handler.clear_graph()
# 创建 Paper 节点
handler.create_paper_nodes(batch_size=50)
在 Neo4j Browser 中用 Cypher 语句验证数据是否成功导入:
(1)查询25篇论文:
MATCH (p:Paper)
RETURN p
LIMIT 25;
(2)查询某一篇论文的详细信息:
MATCH (p:Paper {paper_ID: "paper_218049"})
RETURN p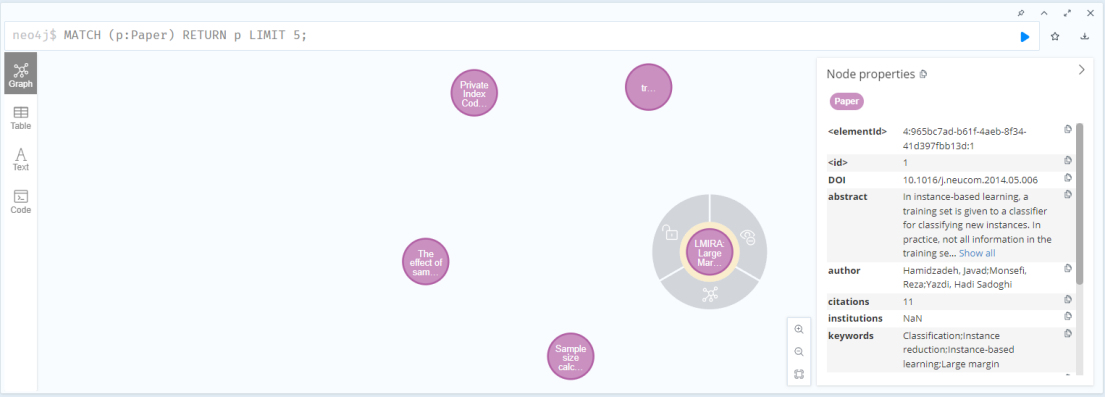
(3)查询某一年发表的全部论文:
MATCH (p:Paper)
WHERE p.year = 2020
RETURN p.paper_ID, p.title, p.author, p.publisher
ORDER BY p.title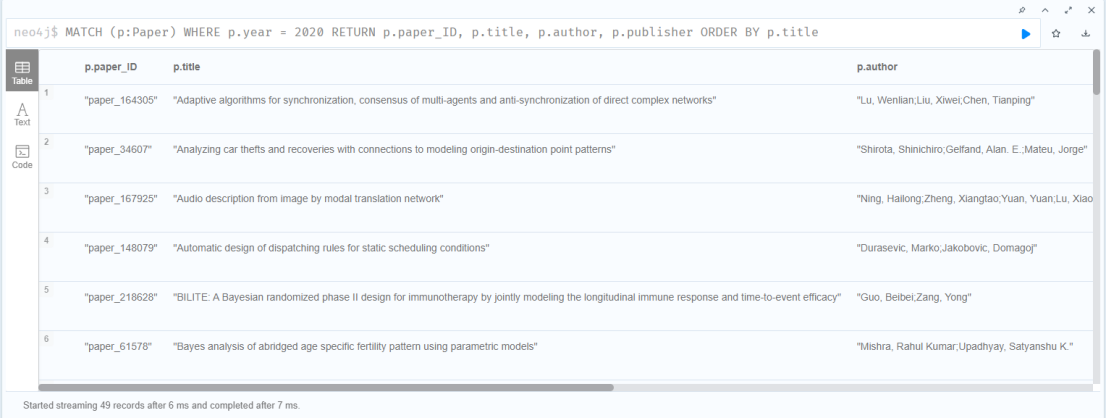
(4)查询某作者的论文:
MATCH (p:Paper)
WHERE p.author CONTAINS "Dehbi, Hakim-Moulay"
RETURN p.paper_ID, p.title, p.year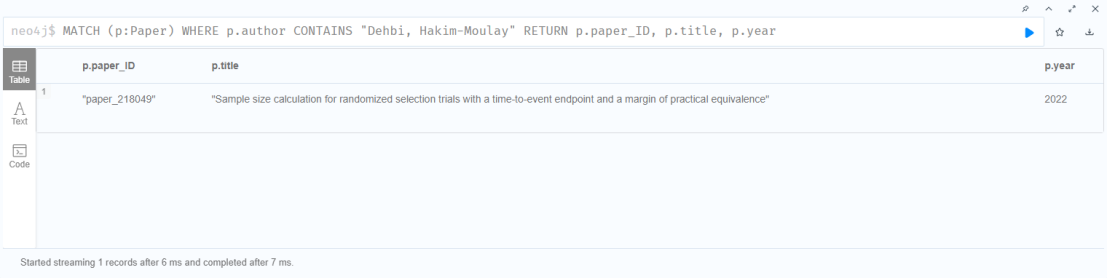
4. 导入大模型进行 Cypher 查询
为提升论文知识图谱对话系统对自然语言问题的理解能力,本实验进一步引入大模型,实现由自然语言到 Cypher 查询语句的自动生成。系统通过精心设计的提示词(Prompt),将论文知识图谱的节点类型、关系结构及可用查询模板明确约束在大模型的生成范围内,使模型能够在理解用户问题语义的基础上,输出结构正确、可执行的 Cypher 查询语句。
运行Neo4j_cypher.py:
# ==================== coding: utf-8 ====================
from langchain_openai import ChatOpenAI
from langchain_community.graphs import Neo4jGraph
from langchain_community.chains.graph_qa.cypher import GraphCypherQAChain
import os
from dotenv import load_dotenv
# ==================== 1. 环境和密钥 ====================
load_dotenv()
if not os.environ.get("DASHSCOPE_API_KEY"):
os.environ["DASHSCOPE_API_KEY"] = input("请输入 DashScope API-Key: ").strip()
os.environ["OPENAI_API_KEY"] = os.environ["DASHSCOPE_API_KEY"]
# ==================== 2. 连接 Neo4j ====================
graph = Neo4jGraph(
url="bolt://localhost:7688",
username="neo4j",
password="rxt0413zC",
refresh_schema=False # 关闭自动 schema 推断
)
# ==================== 3. 手动设置 Paper 节点 Schema ====================
graph.schema = """
Node properties are the following:
Paper {
paper_ID: STRING,
title: STRING,
year: INTEGER,
publisher: STRING,
DOI: STRING,
abstract: STRING,
keywords: STRING,
author: STRING,
institutions: STRING,
citations: INTEGER,
reference_num: INTEGER,
url: STRING
}
Relationships:
(None)
"""
print("Paper Schema 已手动设置完成")
# ==================== 4. 初始化 LLM + GraphCypherQAChain ====================
llm = ChatOpenAI(
model="qwen-plus",
temperature=0,
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# 关键改动:return_direct=True 保证直接返回 Neo4j 查询结果
chain = GraphCypherQAChain.from_llm(
llm=llm,
graph=graph,
verbose=True, # 打印生成的 Cypher
allow_dangerous_requests=True,
return_direct=True # 直接返回查询结果,不让 LLM 判断是否知道
)
# ==================== 5. 测试查询问题 ====================
questions = [
"数据库中一共有多少篇论文?",
"列举一篇2023年发表的论文",
"有哪些论文发表于2020年?"
]
print("\n开始测试:自然语言 → Cypher → 查询结果\n")
for i, q in enumerate(questions, 1):
print(f"\n问题 {i}:{q}")
result = chain.invoke({"query": q})
# result['result'] 返回的是 Neo4j 查询结果列表
if isinstance(result['result'], list) and result['result']:
# 统一提取 title(如果有)或者直接显示字典
titles = []
for r in result['result']:
# Paper 节点一般包含 title 或 paper_ID
if 'p.title' in r:
titles.append(r['p.title'])
elif 'p.paper_ID' in r:
titles.append(r['p.paper_ID'])
else:
titles.append(str(r))
print("查询结果:", titles)
else:
print("查询结果为空或无法提取")在具体实现中,大模型仅负责根据用户输入生成 Cypher 查询,不直接参与数据存储与计算过程;生成的查询语句由程序调用图数据库执行,并将返回结果再次转换为自然语言反馈给用户。


5. 使用大模型实现用户对话系统交互
在完成论文知识图谱构建及 Cypher 查询能力封装的基础上,本实验进一步引入大模型,实现面向用户的自然语言对话交互功能。系统整体采用“用户输入 → 大模型理解 → 图数据库查询 → 结果反馈”的交互流程,使用户无需掌握图数据库或查询语言,即可通过自然语言完成对论文知识的检索与探索。
运行脚本Neo4j_bot.py:
#!/usr/bin/env python3
# coding: utf-8
from langchain_openai import ChatOpenAI
from langchain_community.graphs import Neo4jGraph
from langchain_community.chains.graph_qa.cypher import GraphCypherQAChain
import os
from dotenv import load_dotenv
# ==================== 环境变量与 API Key ====================
load_dotenv()
if not os.environ.get('DASHSCOPE_API_KEY'):
os.environ['DASHSCOPE_API_KEY'] = input("请粘贴你的 DashScope API-Key: ").strip()
os.environ["OPENAI_API_KEY"] = os.environ["DASHSCOPE_API_KEY"]
# ==================== 连接 Neo4j ====================
graph = Neo4jGraph(
url="bolt://localhost:7688", # 注意端口号与你 Neo4j Bolt 端口一致
username="neo4j",
password="rxt0413zC",
refresh_schema=False # 禁用自动 schema
)
# ==================== 手动 Schema(可帮助 LLM 理解节点属性) ====================
graph.schema = """
Node properties:
Paper {paper_ID: STRING, title: STRING, year: INTEGER, publisher: STRING, DOI: STRING, abstract: STRING, keywords: STRING, author: STRING, institutions: STRING, citations: INTEGER, reference_num: INTEGER, url: STRING}
Institution {name: STRING}
Relationships:
(:Paper)-[:CITES]->(:Paper)
(:Paper)-[:AFFILIATED_WITH]->(:Institution)
"""
# ==================== 初始化大模型 ====================
llm = ChatOpenAI(
model="qwen-plus",
temperature=0,
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# ==================== 创建 GraphCypherQAChain ====================
chain = GraphCypherQAChain.from_llm(
llm=llm,
graph=graph,
verbose=True,
allow_dangerous_requests=True
)
# ==================== 对话交互函数 ====================
def interactive_chat():
print("\n欢迎使用论文知识图谱问答系统!输入 '退出' 或 'exit' 来结束对话。\n")
while True:
user_input = input("你: ").strip()
if user_input.lower() in ["退出", "exit"]:
print("已退出问答系统。")
break
if not user_input:
continue
try:
result = chain.invoke({"query": user_input})
print("系统:", result.get("result", "抱歉,我未找到答案。"))
except Exception as e:
print("系统: 查询出错", e)
# ==================== 启动交互 ====================
if __name__ == "__main__":
interactive_chat()具体而言,当用户输入查询问题后,系统首先将原始自然语言问题输入大模型,由模型对用户意图进行语义理解,并在预设的图谱结构和查询模板约束下,生成对应的 Cypher 查询语句。随后,系统自动调用 Neo4j 或 TuGraph 图数据库执行该查询,并对返回的结构化结果进行整理与筛选。最后,系统将查询结果以简洁、可读的自然语言形式反馈给用户,完成一次完整的问答交互。
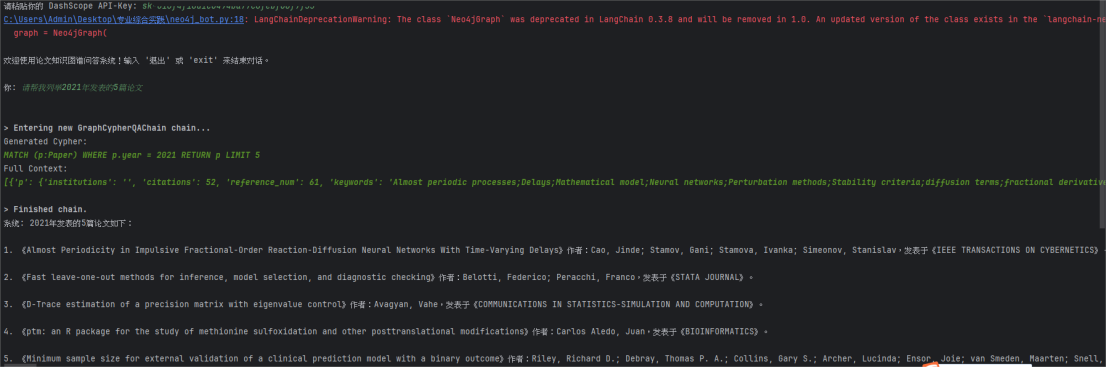
对话系统测试:


三、基于TuGraph平台实现完整的知识图谱对话系统
1. 启动并登录 TuGraph 图形化界面
启动 docker,命令行运行:
docker run -d -v D:\rxt:/mnt -p 7070:7070 -p 7687:7687 docker.1ms.run/tugraph/tugraph-runtime-ubuntu18.04 lgraph_server
打开浏览器,在浏览器地址栏输入:localhost:7070
输入用户名和密码,进入图形化操作界面
2. TuGraph 图模型设计与构建
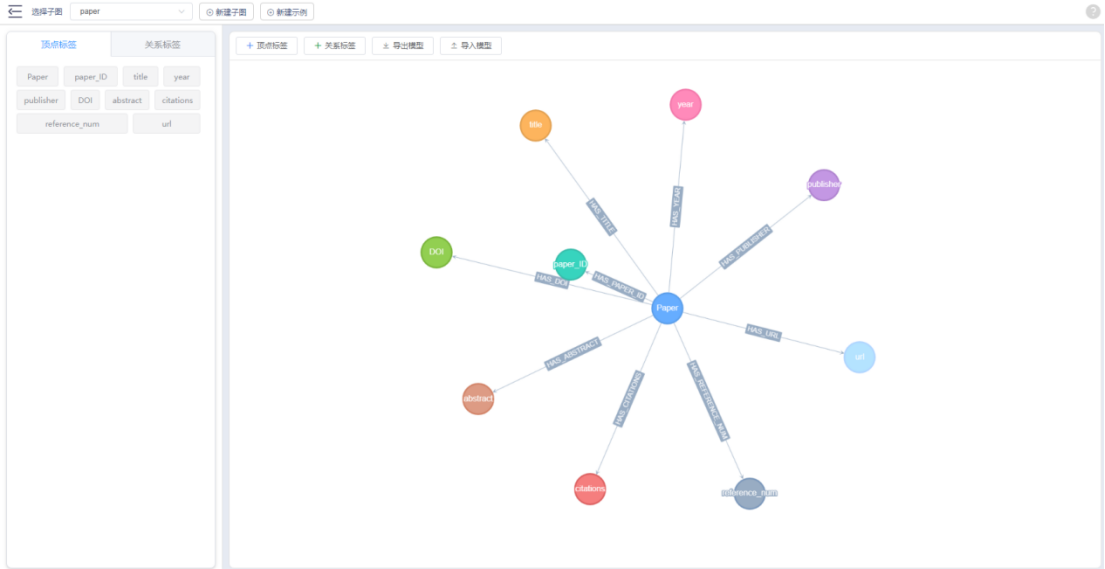
(1)节点类型设计
创建以下节点类型,每个节点通过唯一标识进行索引:
-
Paper:论文核心节点,标识为paper_ID -
Title:论文标题 -
Year:发表年份 -
Publisher:期刊名称 -
DOI:论文 DOI 信息 -
Abstract:论文摘要 -
Citations:被引次数 -
Reference_num:参考文献数量 -
URL:论文链接
(2)关系类型设计
所有节点都通过与 Paper 节点的单向关系进行连接:
-
Paper→Title(HAS_TITLE) -
Paper→Year(HAS_YEAR) -
Paper→Publisher(HAS_PUBLISHER) -
Paper→DOI(HAS_DOI) -
Paper→Abstract(HAS_ABSTRACT) -
Paper→Citations(HAS_CITATIONS) -
Paper→Reference_num(HAS_REFERENCE_NUM) -
Paper→URL(HAS_URL)
创建图模型:运行write_conf.py生成.json文件
#!/usr/bin/env python3
# coding: utf-8
import pandas as pd
import json
# 输出 JSON 文件
output_file = "paper_graph_model_simple.json"
# CSV 文件路径
csv_path = "./paper_kg_cleaned.csv"
# 读取 CSV
df = pd.read_csv(csv_path, encoding='utf-8')
# 定义节点字段
field_nodes = [
"paper_ID", "title", "year", "publisher", "DOI", "abstract",
"citations", "reference_num", "url"
]
# 定义边字段
edge_nodes = field_nodes.copy() # Paper -> 各字段节点
# 构造 schema JSON
schema_list = []
# Paper 节点
schema_list.append({
"label": "Paper",
"type": "VERTEX",
"properties": [{"name": "name", "type": "STRING", "optional": False, "unique": True, "index": True}],
"primary": "name"
})
# 字段节点
for field in field_nodes:
schema_list.append({
"label": field,
"type": "VERTEX",
"properties": [{"name": "name", "type": "STRING", "optional": False, "unique": True, "index": True}],
"primary": "name"
})
# 边
for field in edge_nodes:
schema_list.append({
"label": f"HAS_{field.upper()}",
"type": "EDGE",
"properties": [],
"constraints": [["Paper", field]]
})
# 生成最终 JSON
graph_json = {"schema": schema_list}
# 写入文件
with open(output_file, "w", encoding="utf-8") as f:
json.dump(graph_json, f, indent=4, ensure_ascii=False)
print(f"TuGraph 模型 JSON 已生成: {output_file}")
最终生成paper_graph_model_simple.json文件如图所示:
导入图模型:
3. TuGraph 数据导入
首先运行 write_V_E.py 脚本,将论文数据集 paper_kg_cleaned.csv 中每条论文记录拆分为:
-
Paper 节点:以 paper_ID 作为唯一标识。
-
字段节点:如 title、year、publisher、DOI、abstract、citations、reference_num、url 等。
-
关系边:从 paper 节点指向各字段节点,命名为 HAS_<字段名>,如 HAS_TITLE、HAS_YEAR 等。
#!/usr/bin/env python3
# coding: utf-8
import pandas as pd
import os
# 论文数据 CSV
df = pd.read_csv('./paper_kg_cleaned.csv', encoding='utf-8')
# 节点字段(顶点标签)
node_name_list = [
"paper_ID", "title", "year", "publisher", "DOI", "abstract",
"citations", "reference_num", "url"
]
# 边标签(Paper -> 字段节点)
edge_name_list = [f"HAS_{x.upper()}" for x in node_name_list]
# 输出目录
path = './output'
if not os.path.exists(path):
os.makedirs(path)
# 节点和边文件路径
node_filenames = [os.path.join(path, f"{name}.csv") for name in node_name_list]
edge_filenames = [os.path.join(path, f"{name}.csv") for name in edge_name_list]
# 清空已有文件
for f in node_filenames + edge_filenames + [os.path.join(path, "Paper.csv")]:
open(f, 'w', encoding='utf-8').close()
# 遍历每行论文数据
for idx, row in df.iterrows():
paper_name = str(row['paper_ID']).strip() # Paper 节点唯一标识
# 写入 Paper 节点
with open(os.path.join(path, "Paper.csv"), 'a', encoding='utf-8') as f:
print(paper_name, file=f)
# 循环生成字段节点及边
for k, field in enumerate(node_name_list):
cell_value = str(row[field]).strip()
if cell_value == "" or cell_value.lower() == "nan":
continue
# 多值字段用空格分割(如 keywords、author)
values = cell_value.split() if field in ['author', 'institutions', 'keywords'] else [cell_value]
for val in values:
val = val.strip()
if not val:
continue
# 写入节点
with open(node_filenames[k], 'a', encoding='utf-8') as f_node:
print(val, file=f_node)
# 写入边
with open(edge_filenames[k], 'a', encoding='utf-8') as f_edge:
print(f"{paper_name},{val}", file=f_edge)
print("拆分完成,节点和边 CSV 已生成在 ./output 文件夹")
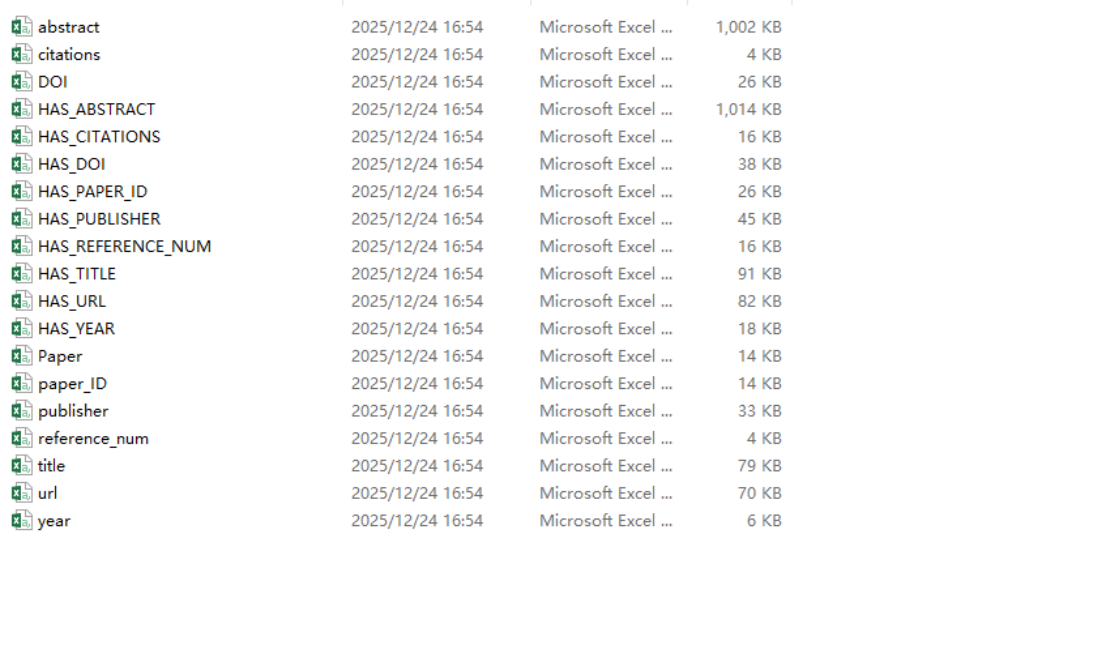
导入数据:
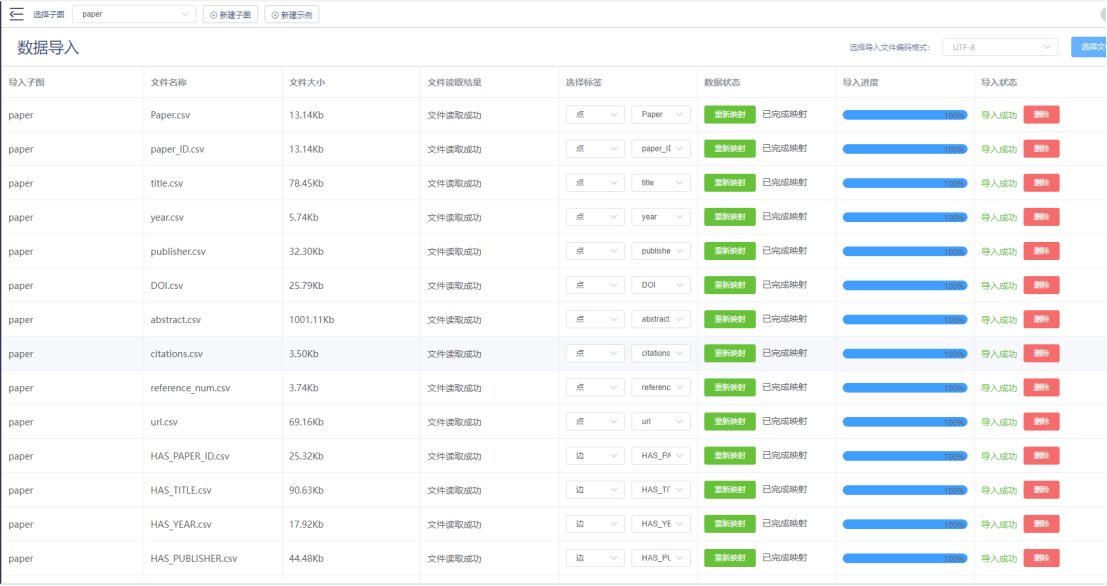
在 TuGraph Browser 中用 Cypher 语句验证数据是否成功导入:
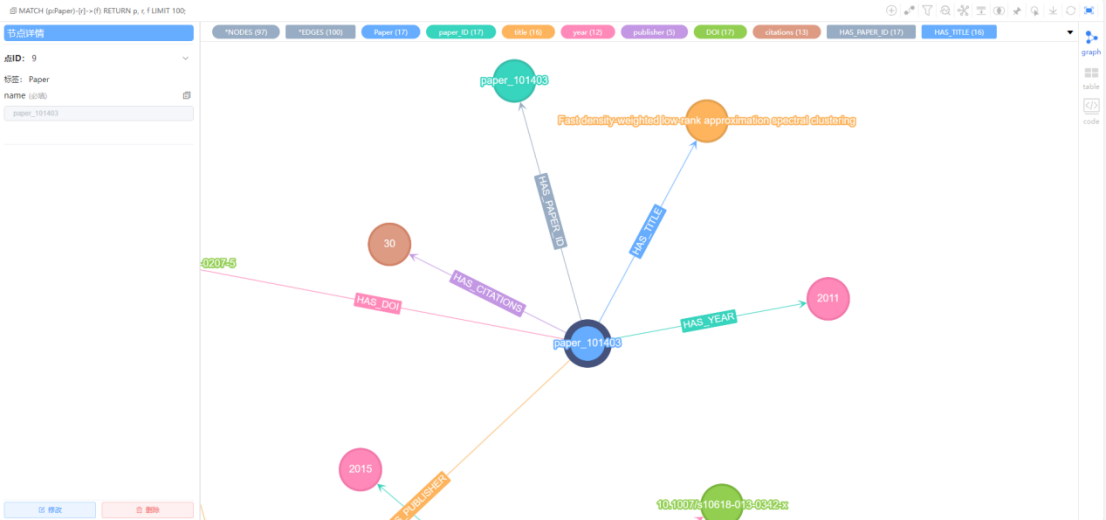
(1)随机查看100篇论文及其字段节点:
MATCH (p:Paper)-[r]->(f)
RETURN p, r, f
LIMIT 100;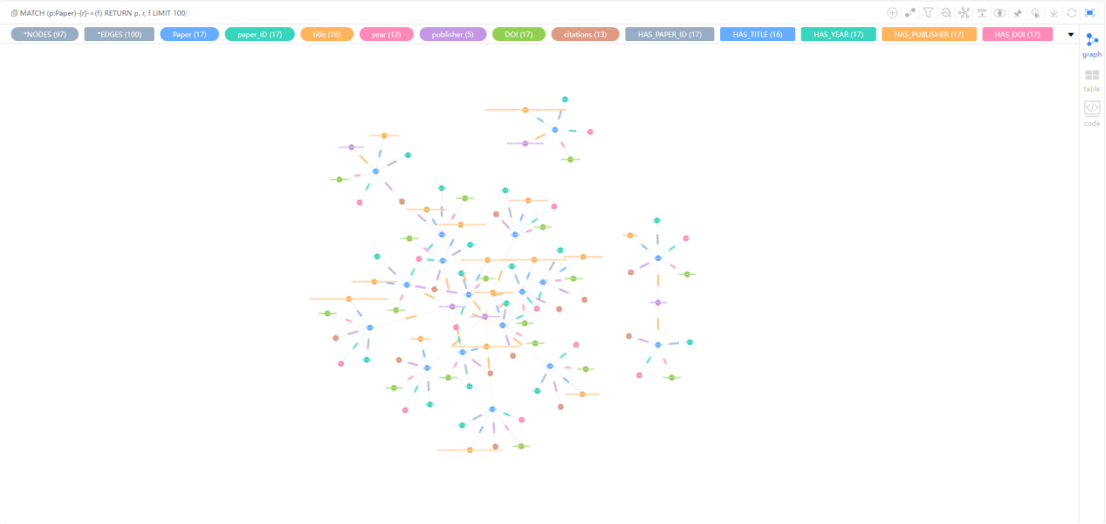
(2)查询前10篇论文标题:
MATCH (p:Paper)-[:HAS_TITLE]->(t:title)
RETURN p.paper_ID, t.name
LIMIT 10;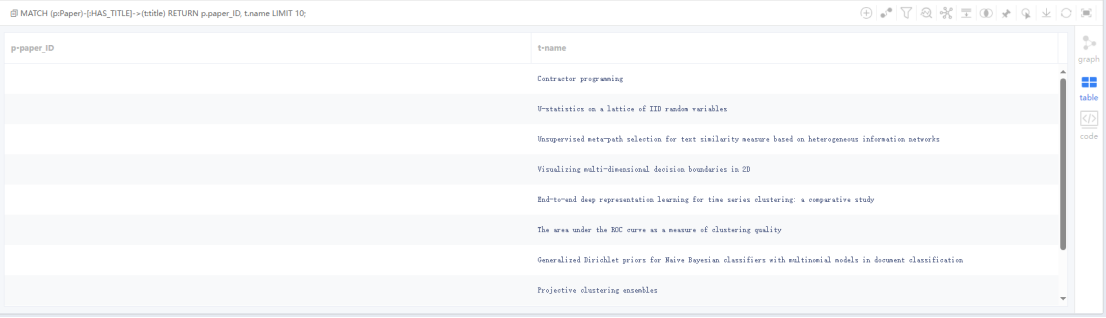
4. 引入大模型进行 Cypher 查询
在传统的图数据库查询中,用户需要熟悉 Cypher 语法才能获取所需信息。为了降低使用门槛,本实验在 TuGraph 平台引入大模型(LLM),实现自然语言问题到 Cypher 查询的自动转换。
运行脚本 tugraph_cypher.py:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from neo4j import GraphDatabase
import os
from dotenv import load_dotenv
# ==================== 1. 密钥 ====================
load_dotenv()
if not os.environ.get("DASHSCOPE_API_KEY"):
os.environ["DASHSCOPE_API_KEY"] = input("请输入 DashScope API Key: ").strip()
os.environ["OPENAI_API_KEY"] = os.environ["DASHSCOPE_API_KEY"]
# ==================== 2. 连接 TuGraph ====================
driver = GraphDatabase.driver(
"bolt://localhost:7687",
auth=("admin", "73@TuGraph")
)
def run_cypher(cypher: str):
with driver.session(database="paper") as session:
return session.run(cypher).data()
# ==================== 3. LLM ====================
llm = ChatOpenAI(
model="qwen-plus",
temperature=0,
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# ==================== 4. Prompt ====================
prompt = ChatPromptTemplate.from_messages([
(
"system",
"""
你是 TuGraph 图数据库专家,需要将中文问题转换为可执行的 Cypher 查询。
严格遵守以下规则:
【数据库 Schema】
节点:
- Paper
- title
- author
- year
- publisher
- DOI
- abstract
- citations
- reference_num
- url
关系:
- (Paper)-[:HAS_TITLE]->(title)
- (Paper)-[:HAS_AUTHOR]->(author)
- (Paper)-[:HAS_YEAR]->(year)
- (Paper)-[:HAS_PUBLISHER]->(publisher)
- (Paper)-[:HAS_DOI]->(DOI)
- (Paper)-[:HAS_ABSTRACT]->(abstract)
- (Paper)-[:HAS_CITATIONS]->(citations)
- (Paper)-[:HAS_REFERENCE]->(reference_num)
- (Paper)-[:HAS_URL]->(url)
【生成规则】
1. 只能使用上面节点和关系,不允许创造新标签或字段。
2. 使用 MATCH ... RETURN ... LIMIT 10 形式。
3. 占位符只用双引号 ""。
4. 每次只生成一条 Cypher。
5. 不输出解释、不要加 markdown。
【模板示例】:
1. 查询部分论文列表:
MATCH (p:Paper)-[:HAS_TITLE]->(t:title)
RETURN p.paper_ID, t.name
LIMIT 10;
2. 查询某论文标题:
MATCH (p:Paper)-[:HAS_TITLE]->(t:title)
WHERE p.paper_ID = "X"
RETURN t.name
LIMIT 1;
3. 查询某论文作者:
MATCH (p:Paper)-[:HAS_AUTHOR]->(a:author)
WHERE p.paper_ID = "X"
RETURN a.name
LIMIT 10;
4. 查询某年份的论文:
MATCH (p:Paper)-[:HAS_YEAR]->(y:year)
WHERE y.name = "2020"
RETURN p.paper_ID, p.title
LIMIT 10;
"""
),
("human", "{question}")
])
chain = prompt | llm
# ==================== 5. 测试 ====================
questions = [
"给我几篇论文的标题",
"帮我介绍一下标题为 U-statistics on a lattice of IID random variables 的论文",
"有几篇论文是2020年发表的?"
]
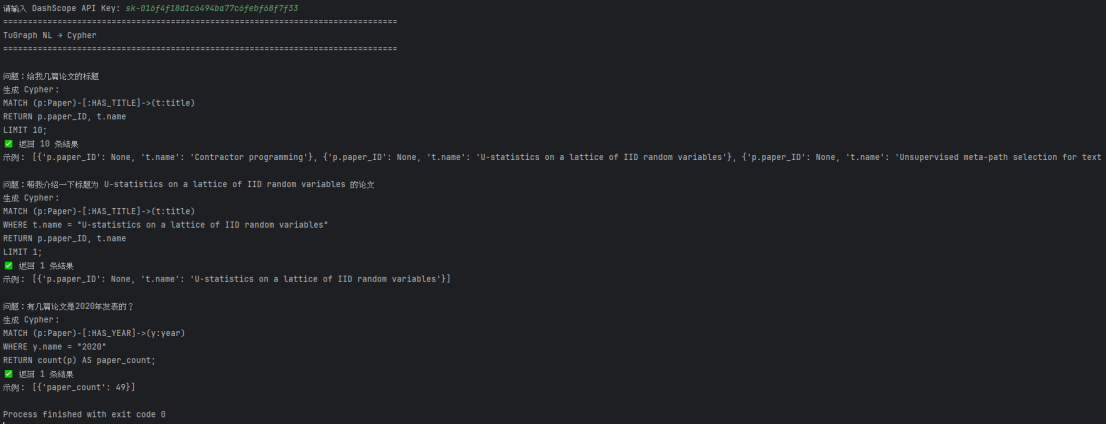
print("=" * 80)
print("TuGraph NL → Cypher")
print("=" * 80)
for q in questions:
print(f"\n问题:{q}")
cypher = chain.invoke({"question": q}).content.strip()
print("生成 Cypher:")
print(cypher)
try:
data = run_cypher(cypher)
print(f"✅ 返回 {len(data)} 条结果")
if data:
print("示例:", data[:3])
except Exception as e:
print("❌ 执行失败:", e)大模型自动生成的 Cypher 可直接在 TuGraph 上执行,返回结构化查询结果,实现自然语言到知识图谱的高效映射。
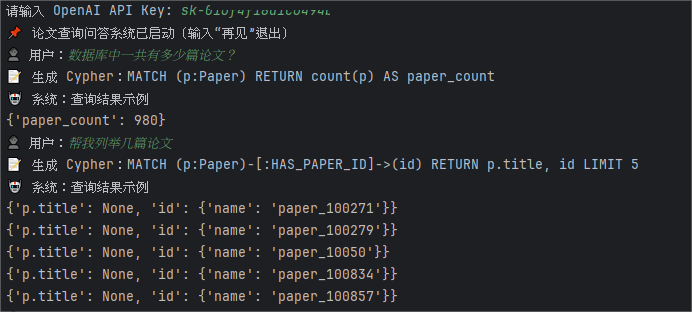
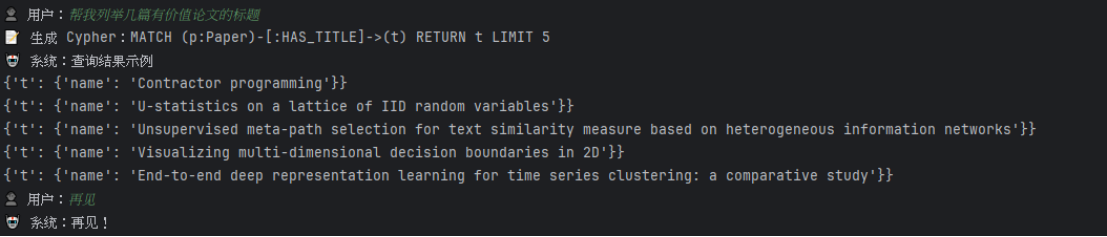
5. 使用大模型实现用户对话系统交互
在完成 Cypher 查询自动化后,进一步构建了基于大模型的用户对话系统,实现交互式知识图谱问答,对话流程为:用户输入自然语言问题 → 大模型解析问题类型 → 自动生成 Cypher → 执行查询 → 返回结果给用户。
运行脚本 tugraph_bot.py:
# coding=utf-8
from neo4j import GraphDatabase
import pandas as pd
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from dotenv import load_dotenv
import os
class PaperChatbot:
def __init__(self):
# ------------------ 1. 连接 TuGraph ------------------
self.driver = GraphDatabase.driver(
"bolt://localhost:7687",
auth=("admin", "73@TuGraph")
)
# ------------------ 2. 加载论文列表 ------------------
df = pd.read_csv("paper_kg_cleaned.csv", encoding="utf-8")
self.paper_list = list(df["title"].dropna())
# ------------------ 3. 初始化大模型 ------------------
load_dotenv()
if not os.environ.get("OPENAI_API_KEY"):
os.environ["OPENAI_API_KEY"] = input("请输入 OpenAI API Key: ").strip()
self.llm = ChatOpenAI(
model="qwen-plus",
temperature=0,
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# ------------------ 4. Prompt 模板 ------------------
self.prompt_template = ChatPromptTemplate.from_messages([
("system", """
你是图数据库专家,将用户提出的中文学术问题转换为可执行的 Cypher 查询。
只能使用以下节点和关系:
节点:
- Paper
- paper_ID
- title
- year
- publisher
- DOI
- abstract
- citations
- reference_num
- url
关系:
(Paper)-[:HAS_PAPER_ID]->(paper_ID)
(Paper)-[:HAS_TITLE]->(title)
(Paper)-[:HAS_YEAR]->(year)
(Paper)-[:HAS_PUBLISHER]->(publisher)
(Paper)-[:HAS_DOI]->(DOI)
(Paper)-[:HAS_ABSTRACT]->(abstract)
(Paper)-[:HAS_CITATIONS]->(citations)
(Paper)-[:HAS_REFERENCE_NUM]->(reference_num)
(Paper)-[:HAS_URL]->(url)
要求:
1. 输出一条 Cypher 查询。
2. MATCH 开头,RETURN 结尾。
3. 不输出解释或其他文字。
4. 如果问题无法匹配节点或关系,返回:
MATCH (p:Paper) RETURN p.paper_ID LIMIT 5
"""),
("human", "{question}")
])
# ------------------ 5. 执行 Cypher ------------------
def run_cypher(self, cypher):
with self.driver.session(database="default") as session:
try:
data = session.run(cypher).data()
return data
except Exception as e:
return f"执行失败:{e}"
# ------------------ 6. 对话逻辑 ------------------
def run(self):
print("📌 论文查询问答系统已启动(输入“再见”退出)")
while True:
user_input = input("👤 用户:")
if user_input.lower() == "再见":
print("🤖 系统:再见!")
break
# 使用大模型生成 Cypher
prompt_input = {"question": user_input}
cypher_result = self.prompt_template | self.llm
cypher_query = cypher_result.invoke(prompt_input).content.strip()
print(f"📝 生成 Cypher:{cypher_query}")
# 执行查询
results = self.run_cypher(cypher_query)
if isinstance(results, str):
print("🤖 系统:", results)
elif not results:
print("🤖 系统:暂无查询结果")
else:
print("🤖 系统:查询结果示例")
for r in results[:5]:
print(r)
if __name__ == "__main__":
bot = PaperChatbot()
bot.run()
结合大模型的自然语言理解能力与 TuGraph 的高效图查询能力,实现了“零编程”访问论文知识图谱的能力,提升了知识获取效率和用户体验。
对话系统测试:


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)