【必学收藏】Agentic RAG实战:从零构建智能检索增强生成系统
本文介绍了Agentic RAG技术,通过查询重写、多路召回、质量评估等优化传统RAG系统的检索-生成链路。作者详细展示了基于Agentic RAG的原型系统实现,包括查询重写、智能检索、条件分支决策等关键流程,通过本地检索与网络搜索结合,显著提高查询准确性和鲁棒性,为企业落地RAG系统提供了可行的实践方案。
RAG(Retrieval-Augmented Generation,检索增强生成)是一种将 检索技术与 生成式 AI结合的技术框架。
其核心流程包括:
- 存储阶段:对输入文档进行清洗、分块等预处理,并存入知识库;
- 查询阶段:接收查询请求后,通过检索系统获取候选结果,再交由生成式 AI 处理,输出逻辑性更强、可读性更好的答复。
在实际应用中,单纯的 RAG 系统往往存在 查询质量不高、手段单一、鲁棒性不足等问题。于是,业内逐渐探索出结合 Agent 思路的 Agentic RAG实践,用来提升 RAG 系统的查询质量与效率。
Agentic RAG 的核心是引入 查询重写、多路召回、路由决策、质量评估、多步重查等操作,对整个检索-生成链路进行优化。在不引入额外新技术的前提下,仅通过对输入问题与检索策略的智能化控制,就能显著增强查询系统的鲁棒性与准确性。
可以说,Agentic RAG 是 RAG 与 Agent 结合的最佳实践,不仅能指导 RAG 系统的开发,也能对已有 RAG 应用流程设计提供参考。
本文结合我近期完成的 Agentic RAG 实践项目,分享其中的 Agent 设计思路、关键流程和部分代码实现,帮助大家对这类系统架构有一个整体认识。
一、项目目标
结合近半年业内出现的 Agentic RAG 的最佳实践,开发一个 Agent + RAG 原型系统,完成基于知识库的查询任务。
目标拆解如下:
1. 查询前:对用户输入进行 查询重写,优化问题质量(关键词提取、规范表述、信息补全)。
2. 查询中:采用 多路召回策略(关键词、向量、融合排序),提高命中率与相关性。
3. 查询后:对候选结果进行 质量评估;若结果不足,再触发互联网搜索。
4. 结果生成:将查询结果交由 LLM 理解与重组,生成 语义完整、逻辑性更高、可读性更强的最终回复。
二、关键技术选型
- Agent Framework
主流的 Agent 开发框架有 ADK与 LangChain。二者均能胜任本项目需求。
ADK 的优势是功能完备、代码简洁,即便不依赖 Google Cloud 生态也能独立运行。
我本次实践选用 ADK作为开发框架。
- Agent 流程控制
项目既有顺序执行逻辑,又涉及动态决策,因此:
SequentialAgent(顺序执行)与 ParallelAgent(并行执行)都不合适;
单纯交由 LLM 驱动的 LLMAgent可能产生幻觉,执行不稳定;
只有支持自定义流程的 Custom Agent才能满足要求。
While the standard Workflow Agents (SequentialAgent, LoopAgent, ParallelAgent) cover common orchestration patterns, you’ll need a Custom agent when your requirements include:
Conditional Logic
Complex State Management
External Integrations
Dynamic Agent Selection
https://google.github.io/adk-docs/agents/custom-agents/#what-is-a-custom-agent
- 数据源
《中华人民共和国个人信息保护法》,按行切分作为知识库内容。
《中华人民共和国个人信息保护法》第一条规定,为了保护个人信息权益,规范个人信息处理活动,促进个人信息合理利用,根据宪法,制定本法。《中华人民共和国个人信息保护法》第二条规定,自然人的个人信息受法律保护,任何组织、个人不得侵害自然人的个人信息权益。《中华人民共和国个人信息保护法》第三条规定,在中华人民共和国境内处理自然人个人信息的活动,适用本法。在中华人民共和国境外处理中华人民共和国境内自然人个人信息的活动,有下列情形之一的,也适用本法:(一)以向境内自然人提供产品或者服务为目的;(二)分析、评估境内自然人的行为;(三)法律、行政法规规定的其他情形。《中华人民共和国个人信息保护法》第四条规定,个人信息是以电子或者其他方式记录的与已识别或者可识别的自然人有关的各种信息,不包括匿名化处理后的信息。个人信息的处理包括个人信息的收集、存储、使用、加工、传输、提供、公开、删除等。《中华人民共和国个人信息保护法》第五条规定,处理个人信息应当遵循合法、正当、必要和诚信原则,不得通过误导、欺诈、胁迫等方式处理个人信息。
- 存储方案
向量化模型:BGE-M3
检索引擎:FAISS
持久化:Pickle
为更好的展示 Agentic RAG 流程,项目未采用 RAG SaaS 服务或向量数据库。
- 查询重写
模型:DeepSeek
- 多路召回(智能检索)
关键词召回:jieba + BM25
向量召回:BGE-M3
融合排序:RRF + Cross-Encoder
- 质量评估
模型:DeepSeek
- 互联网搜索
工具:SerpAPI
- 结果整合与优化
模型:DeepSeek
三、关键流程
- 查询流程如下:
用户查询 → 查询重写 → 智能检索 → 质量评估 → 条件分支决策 ↓ PASS ──→ 直接答案生成 ↓ FAIL ──→ 网络搜索 → 结果融合 → 最终答案生成
### 工作流程详解#### 阶段1: 查询重写 (`QueryRewriterAgent`)- 分析用户查询的法律领域和复杂度- 提取核心法律概念和关键词- 规范法律术语表述,生成多个查询变体#### 阶段2: 智能检索 (`LocalRetriever`)- **查询类型分析**:自动识别精确查询、语义查询或混合查询- **多路径检索**: - 向量搜索(BGE-M3嵌入模型) - 关键词搜索(基于jieba分词) - RRF融合(Reciprocal Rank Fusion)- **Cross-Encoder重排序**:精确优化检索结果排序#### 阶段3: 质量评估 (`QualityEvaluatorAgent`)- **4维度评估**:相关性、完整性、准确性、覆盖面(各10分)- **80%阈值判断**:总分≥32分为PASS,否则为FAIL- **详细分析**:提供质量分析报告和改进建议#### 阶段4: 条件分支决策 (`ConditionalWorkflowAgent`)- **直接路径**(质量≥80%):基于本地检索结果直接生成专业法律咨询- **补救路径**(质量<80%): 1. 触发SerpAPI网络搜索 2. 融合本地和网络搜索结果 3. 生成综合性法律建议(确保用户始终获得回复)
- 核心类如下:
### 核心组件#### 检索层- **LocalRetriever**: 智能多路径检索引擎 - BGE-M3嵌入模型 + FAISS向量索引 - jieba中文分词 + 关键词检索 - RRF融合算法 + Cross-Encoder重排序 - 查询类型自动识别(精确/语义/混合)#### Agent层- **QueryRewriterAgent**: 查询优化和关键词提取- **QualityEvaluatorAgent**: 4维度质量评估(相关性、完整性、准确性、覆盖面)- **AnswerGeneratorAgent**: 基于质量阈值的智能答案生成- **WebSearchAgent**: SerpAPI网络搜索补救机制#### 工作流控制层- **ConditionalWorkflowAgent**: 条件分支工作流控制器 - 智能路径选择逻辑 - 质量评估结果解析 - 网络搜索触发机制 - 结果融合和最终答案生成
- 项目结构如下:
agentic_rag/├── agentic_rag/ # 核心包│ ├── __init__.py # ADK导出接口│ ├── agent.py # 条件分支工作流Agent(主入口)│ ├── retriever.py # 智能多路径检索器│ ├── query_rewriter.py # 查询重写Agent│ ├── quality_evaluator.py # 质量评估Agent│ ├── answer_generator.py # 答案生成Agent│ ├── web_search.py # SerpAPI网络搜索Agent│ └── config.py # 配置管理├── data/ # 数据目录│ ├── vectors.index # FAISS向量索引│ ├── texts.pkl # 文本数据│ └── metadatas.pkl # 元数据├── chinese_law.txt # 法律条文数据源├── init_index.py # 索引初始化脚本├── clean_index.py # 索引清理脚本├── download_models.py # 模型下载脚本├── requirements.txt # 依赖包```
四、关键代码
- 主Agent
1)初始化
class ConditionalWorkflowAgent(BaseAgent): """ 条件工作流Agent - 实现带有条件分支的法律RAG工作流
工作流程: 1. 查询重写 2. 本地检索 3. 质量评估 4. 条件分支: - 质量达标 → 直接生成答案 - 质量不达标 → 触发互联网搜索 → 生成增强答案 """
def __init__(self, name: str = "ConditionalWorkflowAgent", description: str = "支持条件分支的智能法律咨询工作流", **kwargs):
# 初始化所有子Agent query_rewriter = query_rewriter_agent retrieval_agent = get_retrieval_agent() quality_evaluator = quality_evaluator_agent answer_generator = answer_generator_agent web_search_agent_instance = web_search_agent
# 构建sub_agents列表 sub_agents = [ query_rewriter, retrieval_agent, quality_evaluator, answer_generator, web_search_agent_instance ]
super().__init__( name=name, description=description, sub_agents=sub_agents, **kwargs )
- 自定义工作流
1)初始化
@override async def _run_async_impl( self, ctx: InvocationContext ) -> AsyncGenerator[Event, None]: """执行条件工作流的核心逻辑"""
2)自定义流程
try: # 阶段1: 查询重写 logger.info(f"[{self.name}] 阶段1: 执行查询重写...") async for event in self.query_rewriter.run_async(ctx): logger.debug(f"[{self.name}] 查询重写事件: {event.model_dump_json(indent=2, exclude_none=True)}") yield event
rewritten_query = ctx.session.state.get("rewritten_query", "") if not rewritten_query: logger.error(f"[{self.name}] 查询重写失败,中止工作流") return
logger.info(f"[{self.name}] 查询重写完成: {rewritten_query}")
# 阶段2: 本地检索 logger.info(f"[{self.name}] 阶段2: 执行本地检索...") async for event in self.retrieval_agent.run_async(ctx): logger.debug(f"[{self.name}] 检索事件: {event.model_dump_json(indent=2, exclude_none=True)}") yield event
retrieval_results = ctx.session.state.get("retrieval_results", []) if not retrieval_results: logger.error(f"[{self.name}] 本地检索失败,中止工作流") return
logger.info(f"[{self.name}] 本地检索完成,获得 {len(retrieval_results)} 个结果")
# 阶段3: 质量评估 logger.info(f"[{self.name}] 阶段3: 执行质量评估...") async for event in self.quality_evaluator.run_async(ctx): logger.debug(f"[{self.name}] 质量评估事件: {event.model_dump_json(indent=2, exclude_none=True)}") yield event
# 解析质量评估结果 quality_evaluation = ctx.session.state.get("quality_evaluation", "") quality_score, quality_passed = self._parse_quality_evaluation(quality_evaluation)
# 将解析结果存储到session state中 ctx.session.state["quality_score"] = quality_score ctx.session.state["quality_passed"] = quality_passed
logger.info(f"[{self.name}] 质量评估完成: 分数={quality_score}, 通过={quality_passed}")
# 阶段4: 条件分支决策 # 使用quality_passed作为主要判断依据,它已经基于80%阈值进行了判断 if quality_passed: # 直接路径:质量达标,直接生成答案 logger.info(f"[{self.name}] 选择直接路径: 质量达标,直接生成答案")
# 设置空的网络搜索结果,确保模板变量存在 ctx.session.state["web_search_results"] = "无网络搜索结果"
async for event in self.answer_generator.run_async(ctx): logger.debug(f"[{self.name}] 答案生成事件: {event.model_dump_json(indent=2, exclude_none=True)}") yield event
# 确保有最终答案 - answer_generator的output_key是"final_answer" final_answer = ctx.session.state.get("final_answer", "") if final_answer: logger.info(f"[{self.name}] 直接路径完成,生成最终答案") else: ctx.session.state["final_answer"] = "抱歉,无法生成满意的答案。" logger.warning(f"[{self.name}] 直接路径答案生成失败,使用默认回复")
else: # 补救路径:质量不达标,触发互联网搜索 logger.info(f"[{self.name}] 选择补救路径: 质量不达标,触发互联网搜索")
# 4a. 执行网络搜索 logger.info(f"[{self.name}] 阶段4a: 执行网络搜索...") async for event in self.web_search_agent.run_async(ctx): logger.debug(f"[{self.name}] 网络搜索事件: {event.model_dump_json(indent=2, exclude_none=True)}") yield event
web_results = ctx.session.state.get("web_search_results", []) logger.info(f"[{self.name}] 网络搜索完成,获得 {len(web_results)} 个结果")
# 4b. 直接使用增强答案Agent处理本地+网络结果 logger.info(f"[{self.name}] 阶段4b: 使用本地和网络结果生成最终答案...")
# 设置双数据源输入供answer_generator使用 ctx.session.state["web_search_results"] = web_results if web_results else "无网络搜索结果"
# 使用answer_generator处理本地+网络结果 async for event in self.answer_generator.run_async(ctx): logger.debug(f"[{self.name}] 答案生成事件: {event.model_dump_json(indent=2, exclude_none=True)}") yield event
# 确保有最终答案 if not ctx.session.state.get("final_answer"): ctx.session.state["final_answer"] = "基于现有信息,我尽力为您提供法律建议,但建议您咨询专业律师获取更准确的意见。" logger.warning(f"[{self.name}] 答案生成失败,使用默认回复") else: logger.info(f"[{self.name}] 补救路径完成,生成最终答案")
logger.info(f"[{self.name}] 条件分支工作流执行完成")
- 查询重写
此项目中的查询重写依赖LLM实现。
# 查询重写Agentquery_rewriter_agent = LlmAgent( name="QueryRewriterAgent", model=LiteLlm(model="deepseek/deepseek-chat"), instruction="""你是查询重写专家。优化用户的法律查询,提高检索效果。重写策略:1. 提取核心法律概念和关键词2. 规范法律术语表述3. 补充相关法律领域信息4. 生成多个查询变体以提高召回率输出格式:**优化后的查询**主查询:[优化后的主要查询]备选查询:- [变体1]- [变体2]- [变体3]**关键词提取**- 法律领域:[领域]- 核心概念:[概念1, 概念2, ...]- 法条类型:[实体法/程序法/...]""", description="重写和优化用户查询以提高检索效果", output_key="rewritten_query", generate_content_config=types.GenerateContentConfig( temperature=0.1, top_p=0.8, max_output_tokens=1024, ))

- 多路召回(智能检索)
1)关键词召回:jieba + BM25
BM25参数:
def keyword_search(self, query: str, top_k: int = 10, k1: float = 1.5, b: float = 0.75) -> List[Dict[str, Any]]: """ BM25关键词搜索
Args: query: 查询文本 top_k: 返回结果数量 k1: BM25参数k1 b: BM25参数b
Returns: 搜索结果列表 """
使用jieba分词(中文友好):
# 对查询进行相同的分词和过滤处理 query_tokens = list(jieba.cut(query, cut_all=False))
BM25公式:
# BM25公式 numerator = tf * (k1 + 1) denominator = tf + k1 * (1 - b + b * doc_length / self.avg_doc_length) score += idf * numerator / denominator
结果排序:
# 按分数排序 scores.sort(key=lambda x: x[1], reverse=True)
2)向量召回:BGE-M3
# 生成查询向量 query_vector = self.embedding_model.encode([query], normalize_embeddings=True) query_vector = np.array(query_vector).astype('float32')
# FAISS搜索 scores, indices = self.index.search(query_vector, top_k) # 构建结果 results = [] for score, idx in zip(scores[0], indices[0]): if idx < len(self.texts): results.append({ 'text': self.texts[idx], 'metadata': self.metadatas[idx], 'score': float(score), 'index': int(idx) # 添加索引字段以便融合时匹配 })
3)融合排序:RRF + Cross-Encoder
# 按融合分数排序 sorted_docs = sorted(doc_scores.items(), key=lambda x: x[1], reverse=True) # 构建最终结果 final_results = [] for i, (doc_id, fused_score) in enumerate(sorted_docs[:top_k]): info = doc_info[doc_id] result = { 'text': info['text'], 'metadata': info['metadata'], 'score': fused_score, 'vector_score': info['vector_score'], 'keyword_score': info['keyword_score'], 'index': info['index'], 'search_type': 'hybrid' }
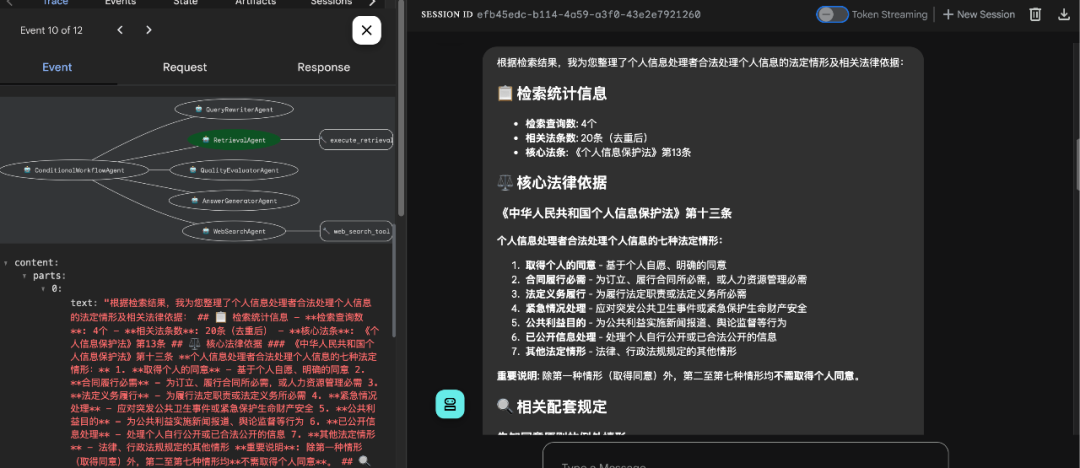
- 质量评估
使用LLM进行质量评估。
# 质量评估Agent(含80%阈值判断)quality_evaluator_agent = LlmAgent( name="QualityEvaluatorAgent", model=LiteLlm(model="deepseek/deepseek-chat"), instruction="""你是检索质量评估专家。评估检索结果质量并进行阈值判断。**检索结果:**{retrieval_results}**评估维度(每项10分):**1. **相关性**:检索结果与用户查询的匹配程度2. **完整性**:是否包含足够信息回答用户问题3. **准确性**:法律条文的准确性和权威性4. **覆盖面**:结果的多样性和全面性**评估标准:**- 9-10分:优秀,完全满足要求- 7-8分:良好,基本满足要求- 5-6分:一般,部分满足要求- 3-4分:较差,勉强相关- 1-2分:很差,基本不相关- 0分:完全不相关或无结果**输出格式:**## 质量评估报告**评分详情:**- 相关性:[X]/10分 - [评估理由]- 完整性:[X]/10分 - [评估理由]- 准确性:[X]/10分 - [评估理由]- 覆盖面:[X]/10分 - [评估理由]**总分:[X]/40分 (百分比: [X]%)****阈值判断:**- 判断结果:[PASS/FAIL]- 判断依据:总分≥32分(80%)为PASS,否则为FAIL**质量分析:**[详细分析检索质量的优缺点]""", description="评估检索质量并进行80%阈值判断", output_key="quality_evaluation", generate_content_config=types.GenerateContentConfig( temperature=0.1, top_p=0.8, max_output_tokens=1536, ))
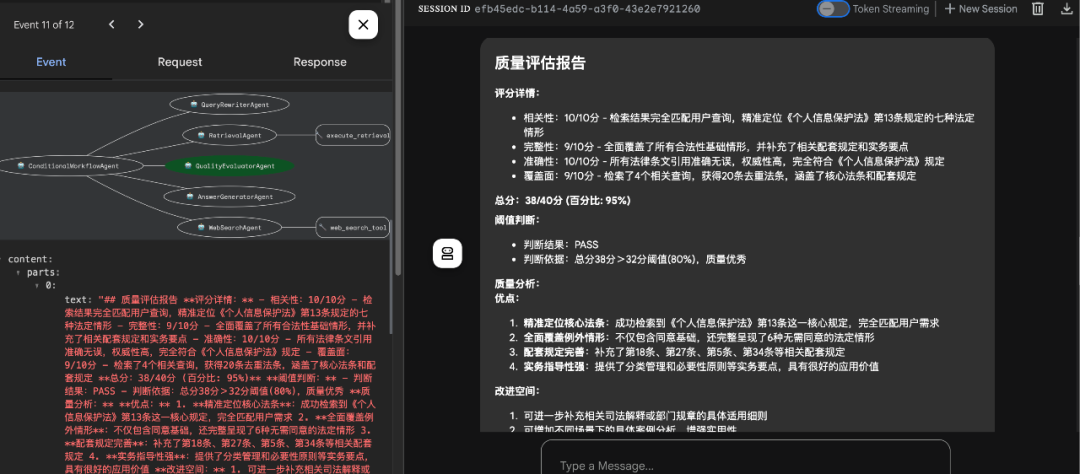
- 互联网搜索
使用SerpAPI进行搜索:
def web_search_tool(query: str, max_results: int = 5) -> str: """执行互联网搜索并返回格式化结果""" try: from serpapi import GoogleSearch
# 获取API密钥 api_key = os.getenv('SERPAPI_API_KEY') if not api_key: return "错误:未设置SERPAPI_API_KEY环境变量"
# 配置搜索参数 - 基于SerpAPI文档样例 params = { "engine": "google_light", "q": query, "location": "China", # 可选:搜索地理位置 "google_domain": "google.com", "hl": "zh-cn", # 界面语言:中文 "gl": "cn", # 搜索地区:中国 "api_key": api_key }
# 执行搜索 search = GoogleSearch(params) results = search.get_dict()
- 结果整合
使用LLM进行结果整合。
# 答案生成Agent(基于阈值判断)answer_generator_agent = LlmAgent( name="AnswerGeneratorAgent", model=LiteLlm(model="deepseek/deepseek-chat"), instruction="""你是专业法律咨询顾问。基于质量评估结果和可用数据源生成专业法律建议。**质量评估结果:**{quality_evaluation}**本地检索结果:**{retrieval_results}**网络搜索结果(如有):**{web_search_results}**生成规则:**1. **如果质量评估为PASS**: - 优先基于本地检索结果生成专业法律咨询 - 提供具体的法条引用和解释 - 给出实用的建议和注意事项2. **如果质量评估为FAIL但有网络搜索结果**: - 融合本地检索和网络搜索结果 - 优先使用本地法条,网络信息作为补充 - 智能去重,按权威性排序:法条 > 司法解释 > 案例 > 专家观点3. **如果质量评估为FAIL且无网络结果**: - 输出标准回复,不生成具体法律建议 - 建议用户重新描述问题或咨询专业律师**PASS时的输出格式:**# 法律咨询意见## 问题分析[基于检索结果分析用户问题]## 相关法条[引用具体法条和条文内容]## 法律解释[解释相关法条的含义和适用]## 建议措施[提供具体的行动建议]**适用条件:**[说明适用的具体情况]**注意事项:**[重要提醒和建议]**免责声明:**本咨询基于现有法律条文,具体适用需结合实际情况,建议咨询专业律师。**融合多数据源时的输出格式:**# 法律咨询意见## 问题分析[基于本地和网络结果分析用户问题]## 相关法条[优先引用本地法条和条文内容]## 法律解释[解释相关法条的含义和适用,网络信息作为补充]## 建议措施[提供具体的行动建议]**适用条件:**[说明适用的具体情况]**注意事项:**[重要提醒和建议]**免责声明:**本咨询基于现有法律条文和公开信息,具体适用需结合实际情况,建议咨询专业律师。**FAIL时的输出格式:**很抱歉,根据您的问题描述,我无法找到足够准确的法律条文来提供专业建议。建议您:1. 重新详细描述您的具体情况2. 咨询专业律师获得准确的法律意见3. 联系相关法律援助机构如需进一步帮助,请提供更多具体信息。""", description="基于质量阈值判断生成专业法律咨询答案", output_key="final_answer", generate_content_config=types.GenerateContentConfig( temperature=0.1, top_p=0.8, max_output_tokens=2048, ))
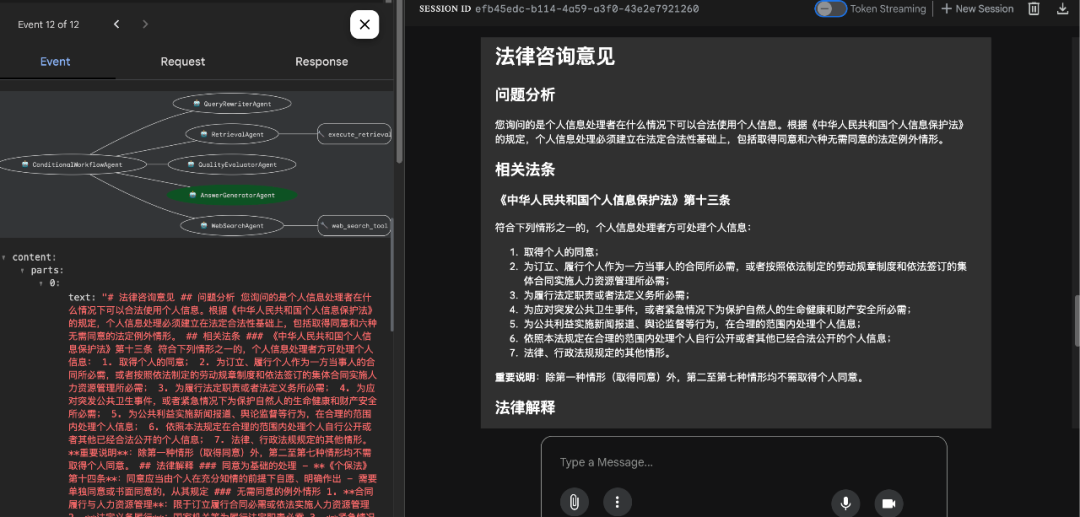
场景一:命中搜索结果如下:
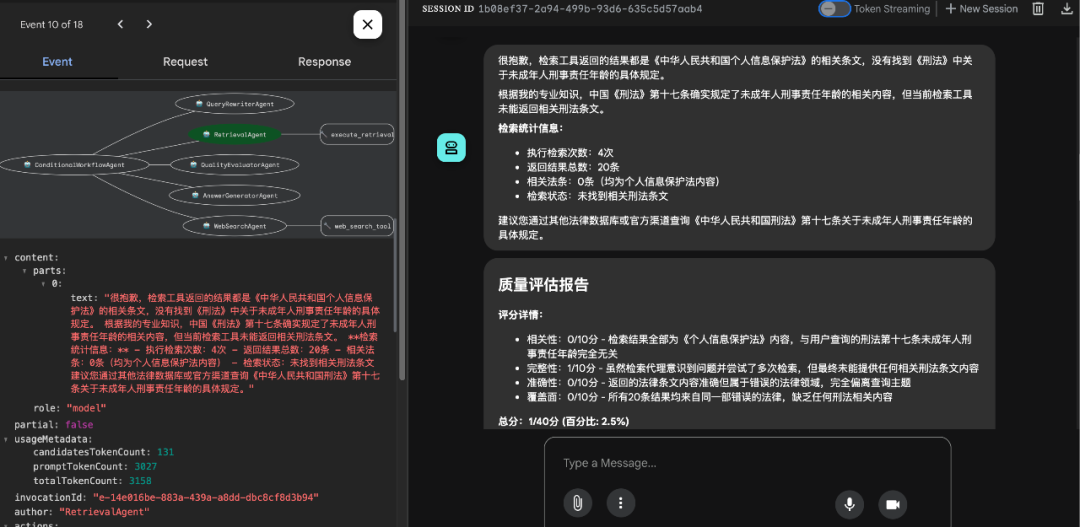
场景二:1. 未命中结果如下:
场景二:2. 触发互联网搜索结果如下:
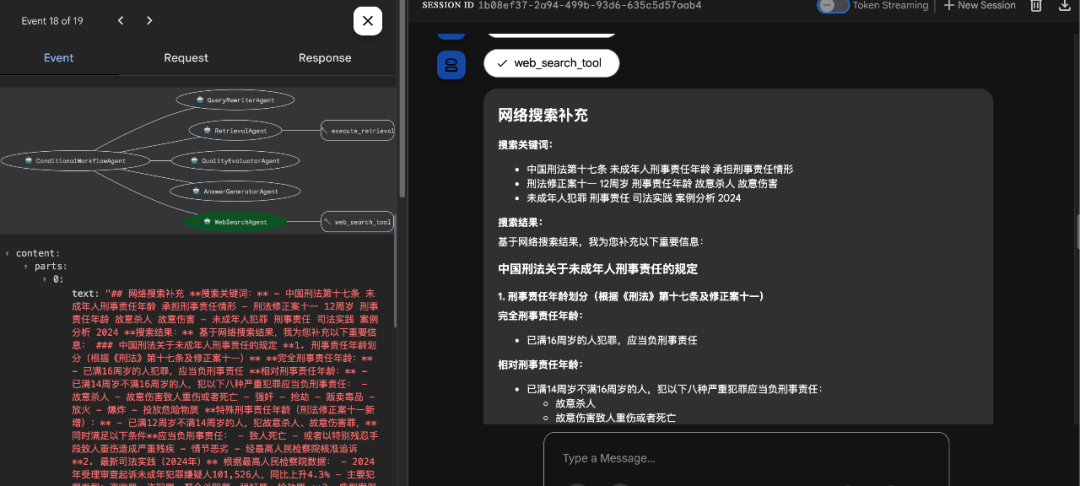
场景二:3. 最终返回结果如下:

五、实战借鉴意义
即使在日常业务中:
- 查询重写能显著提升命中率。
例如,将口语化表述改写为专业术语;
将模糊问题重写为清晰、完整的查询。
- 查询重写可采用 规则 + LLM双路结合。
小模型 LLM 既能降低成本,也能缩短响应时间。
- 查询路径可采用 漏斗模型:
逐步评估结果质量,若达标提前终止,降低延迟;
若不达标,则逐步扩展搜索途径,确保查询质量。
- 经过 LLM 的二次优化,结果在 逻辑性与可读性上会有显著提升,更贴近实际使用需求。
整体来看,Agentic RAG 在查询链路上提供了可行的优化思路,是企业落地 RAG 系统时非常值得借鉴的一类实践方案。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献405条内容
已为社区贡献405条内容

所有评论(0)