生产训练GPU服务器深度修复技术:从内核崩溃到环境重建
本文记录了一台搭载4块RTX 3080显卡的服务器在Ubuntu系统升级过程中出现的多重故障及修复过程。主要问题包括:内核版本不匹配导致RAID驱动加载失败、APT依赖冲突、核心库丢失等。通过USB Live环境修复,采用外科手术式方法手动下载并安装关键库文件,最终重新部署了NVIDIA驱动和CUDA 13.1。整个修复过程耗时两天,涉及内核更新、APT依赖修复、显卡驱动重装等关键步骤。文章还总结
1. 故障全景
- 硬件: Supermicro X11DPG-QT, 4x RTX 3080, RAID1 (Adaptec)
- 系统: Ubuntu18.04<-Ubuntu20.04<-Ubuntu22.04
- 起始问题: 系统升级 (18.04->22.04) 后回退旧内核,删除新内核,并且手工编译修复NVDIA驱动导致无法启动(核心:研发对于系统环境不了解,手工编译驱动,导致内核等环境未能更新,最终引起系统无法正常启动进入系统,在修复过程中还擅自删除了很多关键环境的依赖,引起系统多重故障)。
- 最终解决: USB Live修复 RAID 驱动加载,禁用原NVDIA的显卡驱动,解决 APT 依赖死节,重新部署 CUDA 13.1。
很久没有这样深耕运维技术解决问题了,全是为了给研发擦屁股的救援行动,机房连续待两天才解决;非常感慨AI的发展,否则估计以我的能力只能请外援。全过程尝试使用元宝、通义等国内主流的AI,但是发现它们经常上下文丢失,反复提供同一种解决方案,根本得不到进展。最终选择使用Opus,问题处理的质量立即得到了质的提升。
2. 关键错误日志存档 (Error Logs)
阶段一:启动崩溃 (Kernel Panic)
现象:系统无法启动,屏幕输出:
VFS: Cannot open root device "UUID=85beb..." or unknown-block(0,0): error -6
Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0)
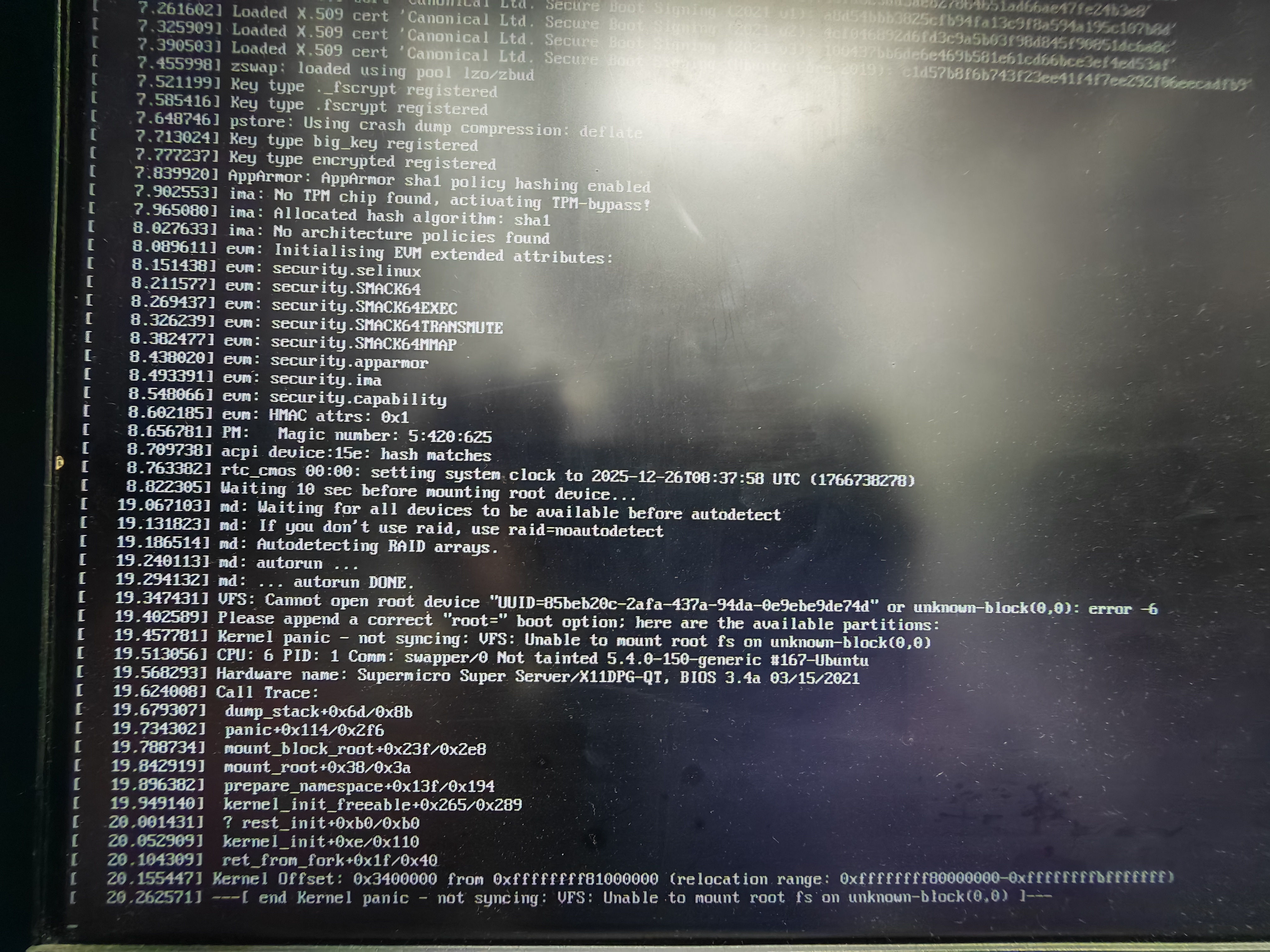
期间以为是系统启动太快,RAID硬件没有足够的时间识别到系统就判断异常导致,尝试修改无线延迟识别硬件状态后还是无法解决。
诊断:内核版本 (5.4.0-150) 过旧,与 22.04 的 initramfs 不匹配,导致 Adaptec RAID 驱动 (aacraid/smartpqi) 未加载,无法识别根分区。
阶段二:APT 依赖死节 (Dependency Hell)
现象:尝试安装新软件时报错:
下列软件包有未满足的依赖关系:
gcc-11 : 依赖: gcc-11-base (= 11.4.0-1ubuntu1~22.04.2) 但是 11.4.0-2ubuntu1~18.04 正要被安装
依赖: libgcc-11-dev (= 11.4.0-1ubuntu1~22.04.2) 但是它将不会被安装
E: 无法修正错误,因为您要求某些软件包保持现状...
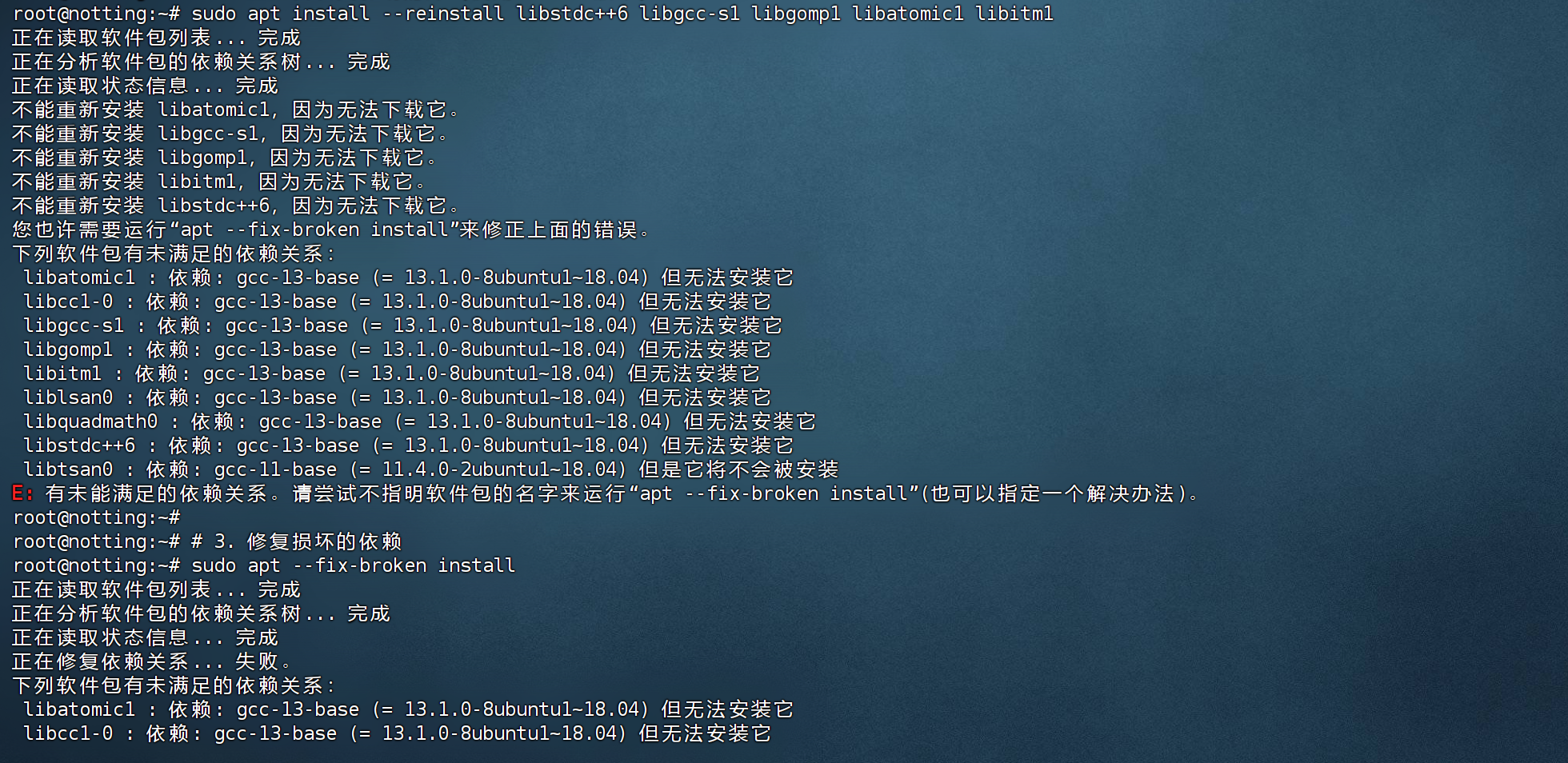
诊断:系统中残留了 Ubuntu 18.04 PPA 源的 GCC 包(版本号 11.4.0-2ubuntu1~18.04 被误判为比 22.04 官方包更新),导致无法安装任何编译工具。
阶段三:核心库丢失 (System Breakage)
现象:强制卸载冲突包后,apt 彻底损坏:
root@notting:~# sudo apt update
apt: error while loading shared libraries: libstdc++.so.6: cannot open shared object file: No such file or directory
诊断:libstdc++6 被意外卸载,导致所有依赖 C++ 库的系统工具(apt, add-apt-repository 等)失效。
3. 详细修复流程与命令 (Step-by-Step Commands)
步骤 1:构建 Chroot 救援环境
在 Live USB 中执行,用于接管原系统:
# 定义分区变量
ROOTFS="/media/ubuntu/85beb20c-2afa-437a-94da-0e9ebe9de74d"
BOOTFS="/media/ubuntu/b06dcd24-3f63-4010-aeca-f83c8fe22dae"
# 挂载文件系统
sudo mount --bind "$BOOTFS" "$ROOTFS/boot"
for i in /dev /dev/pts /proc /sys /run; do
sudo mount --bind "$i" "$ROOTFS$i"
done
# 进入环境
sudo chroot "$ROOTFS" /bin/bash
步骤 2:解决 Kernel Panic (安装正确内核)
为了支持 Adaptec RAID 卡和 22.04 系统,安装 5.15 内核:
# 配置 DNS 确保网络正常
echo "nameserver 8.8.8.8" > /etc/resolv.conf
# 安装 Ubuntu 22.04 标准 HWE 内核
apt update
apt install linux-image-5.15.0-116-generic linux-headers-5.15.0-116-generic
# 更新引导配置
update-grub
此时重启,服务器已能进入命令行,但无显卡驱动。
步骤 3:外科手术式修复 APT (最关键一步)
当 apt 损坏时,使用 wget 手动下载官方 deb 包并用 dpkg 强行安装。
1. 下载 22.04 原生核心库 (注意版本匹配)
cd /tmp
# 下载 gcc-12-base, libgcc-s1, libstdc++6 的 22.04 版本
wget http://archive.ubuntu.com/ubuntu/pool/main/g/gcc-12/gcc-12-base_12.3.0-1ubuntu1~22.04.2_amd64.deb
wget http://archive.ubuntu.com/ubuntu/pool/main/g/gcc-12/libgcc-s1_12.3.0-1ubuntu1~22.04.2_amd64.deb
wget http://archive.ubuntu.com/ubuntu/pool/main/g/gcc-12/libstdc++6_12.3.0-1ubuntu1~22.04.2_amd64.deb
2. 强制覆盖安装
因为依赖关系已乱,必须强制覆盖:
sudo dpkg -i --force-overwrite gcc-12-base*.deb libgcc-s1*.deb libstdc++6*.deb
执行后 apt 命令恢复正常。
3. 清理残留与修复依赖
# 强制移除所有 18.04 遗留的冲突包
sudo dpkg --purge --force-depends gcc-11-base gcc-13-base libgcc-s1 libgomp1 libatomic1
# 让 apt 自动修复缺失的依赖链
sudo apt --fix-broken install
# 补全基础编译环境
sudo apt install build-essential gcc-11 g++-11
步骤 4:显卡驱动与 CUDA 部署
1. 清理旧环境
# 移除所有旧驱动和配置
sudo nvidia-uninstall
sudo apt remove --purge '^nvidia-.*'
sudo rm -rf /var/lib/dkms/nvidia
sudo rm -rf /etc/modprobe.d/blacklist-nvidia.conf
2. 安装新驱动 (支持 DKMS)
# 安装 590 版本开放内核模块驱动
sudo apt install nvidia-driver-590-open
# 验证 DKMS 编译状态
dkms status
# 输出应包含: nvidia/590.48.01, 5.15.0-116-generic, x86_64: installed
3. 安装 CUDA 13.1
# 添加官方源
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt update
# 安装 Toolkit
sudo apt install cuda-toolkit-13-1
4. 验证结果
重启后执行 nvidia-smi:
- Driver Version: 590.48.01
- CUDA Version: 13.1
- GPU Status: 4x NVIDIA GeForce RTX 3080 (正常运行,Persistence-M: On)
- Process: Docker/Ollama 进程已成功调用 GPU。
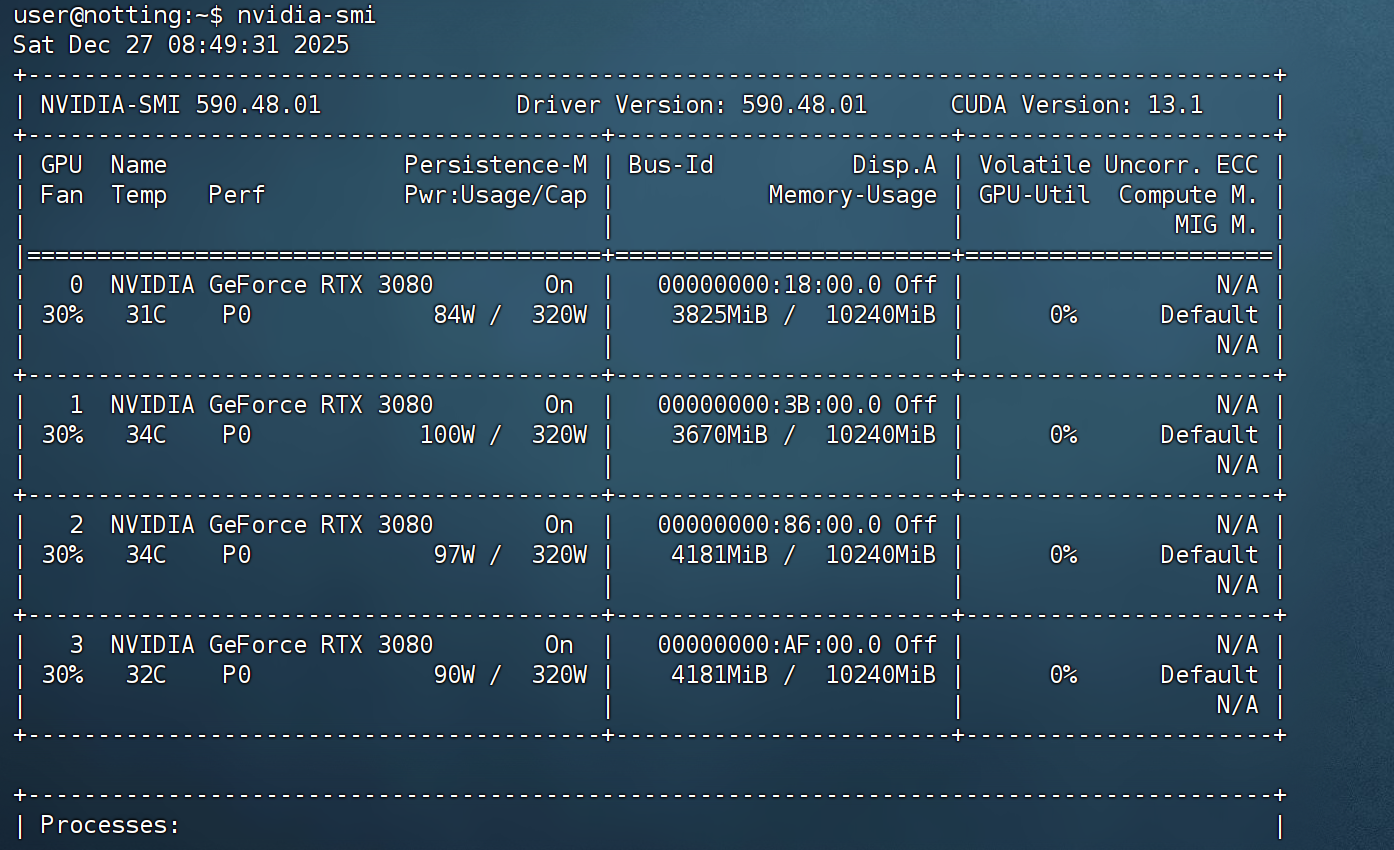
本次是研发人员想升级驱动到最新版本,发现内核不兼容,顺手升级内核引起的异常问题,初步反馈给到IT部门修改启动旧版内核后本来已经正常启动。但是研发私自删除新版本内核,然后编译修复NVDIA的驱动,过程中一些删除指令发散,导致关键的依赖和启动环境丢失造成。作为相关的一些高危操作,应当先做好备份等行为再执行。
5. 预防措施与最佳实践
5.1 系统升级前的准备工作
在进行大版本升级或内核更新前,务必执行以下检查:
# 1. 完整备份关键分区
sudo rsync -aAXv /boot /backup/boot-$(date +%Y%m%d)
sudo tar czf /backup/etc-$(date +%Y%m%d).tar.gz /etc
# 2. 记录当前系统状态
uname -r > /backup/kernel-version.txt
dpkg -l | grep nvidia > /backup/nvidia-packages.txt
dkms status > /backup/dkms-status.txt
# 3. 检查并清理旧 PPA 源
ls -la /etc/apt/sources.list.d/
# 移除不兼容的 PPA
sudo rm /etc/apt/sources.list.d/*18.04*
# 4. 确保至少保留 2 个可用内核
dpkg -l | grep linux-image
5.2 内核管理规范
# 查看已安装的内核
dpkg --list | grep linux-image
# 锁定当前稳定内核(防止自动升级)
sudo apt-mark hold linux-image-$(uname -r)
# 解除锁定
sudo apt-mark unhold linux-image-$(uname -r)
# 安全删除旧内核(保留当前和前一个版本)
sudo apt autoremove --purge # 仅在确认后执行
6. 故障排查决策树
关键诊断命令
# 在 Live USB 中检查原系统
sudo blkid # 查看分区 UUID
sudo fdisk -l # 查看磁盘布局
lspci | grep -i raid # 检测 RAID 控制器
# 在 chroot 环境中
lsinitramfs /boot/initrd.img-$(uname -r) | grep -i raid # 检查 initramfs 内容
journalctl -xb # 查看启动日志
7. DKMS 管理最佳实践
7.1 DKMS 状态检查
# 查看所有 DKMS 模块状态
dkms status
# 查看特定模块的详细信息
dkms status nvidia/590.48.01
# 检查模块是否已加载到当前内核
lsmod | grep nvidia
7.2 手动管理 DKMS 模块
# 为新内核手动构建模块
sudo dkms install nvidia/590.48.01 -k 5.15.0-116-generic
# 移除失败的构建
sudo dkms remove nvidia/590.48.01 --all
# 强制重新构建
sudo dkms autoinstall -k $(uname -r)
7.3 DKMS 故障排查
# 查看构建日志
cat /var/lib/dkms/nvidia/590.48.01/build/make.log
# 检查编译依赖
dpkg -l | grep -E "build-essential|linux-headers|gcc"
# 确认 GCC 版本兼容性
gcc --version # 应为 11.x 或更高
8. CUDA 环境配置
8.1 环境变量设置
将以下内容添加到 ~/.bashrc 或 /etc/profile.d/cuda.sh:
# CUDA 13.1 环境变量
export CUDA_HOME=/usr/local/cuda-13.1
export PATH=$CUDA_HOME/bin:$PATH
export LD_LIBRARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATH
export CUDA_VISIBLE_DEVICES=0,1,2,3 # 指定可见的 GPU
应用配置:
source ~/.bashrc
# 验证
nvcc --version
which nvcc
8.2 多版本 CUDA 管理
# 使用符号链接切换 CUDA 版本
sudo ln -sf /usr/local/cuda-13.1 /usr/local/cuda
# 查看已安装的 CUDA 版本
ls -l /usr/local/ | grep cuda
9. 性能验证与测试
9.1 GPU 基础测试
# 实时监控 GPU 状态
nvidia-smi -l 1
# 查看详细 GPU 信息
nvidia-smi -q
# 测试 GPU 拓扑结构(多 GPU 通信)
nvidia-smi topo -m
9.2 CUDA 功能测试
# 编译并运行 CUDA 示例
cd /usr/local/cuda/samples/1_Utilities/deviceQuery
sudo make
./deviceQuery
# 带宽测试
cd /usr/local/cuda/samples/1_Utilities/bandwidthTest
sudo make
./bandwidthTest
9.3 多 GPU 负载测试
# 使用 stress-ng 测试(需安装)
sudo apt install stress-ng
stress-ng --gpu 4 --timeout 60s
# 或使用 GPU burn 测试
git clone https://github.com/wilicc/gpu-burn
cd gpu-burn
make
./gpu_burn 60 # 运行 60 秒压力测试
10. 常见陷阱与警告
[!CAUTION]
高风险操作 - 请务必谨慎
⚠️ 不要轻易执行的命令
# 危险:可能删除正在使用的内核
sudo apt autoremove # 执行前务必检查将要删除的包
# 危险:强制依赖可能导致系统崩溃
sudo dpkg --purge --force-depends [package] # 仅在救援模式使用
# 危险:可能破坏引导
sudo rm -rf /boot/* # 永远不要这样做
⚠️ 内核管理注意事项
- 至少保留 2 个可用内核:当前使用的 + 一个备用
- 删除内核前验证:确保备用内核能正常启动
- GRUB 默认项:不要设置为
saved,使用数字索引(如0)
⚠️ 驱动安装陷阱
- 避免混用安装方式:不要同时使用
.run文件和apt - Secure Boot 冲突:如果启用了 Secure Boot,DKMS 模块需要签名
- 内核升级后:务必检查
dkms status确认驱动已重新编译
11. 快速恢复检查清单
重启前必检项(Critical Pre-Reboot Checklist)
# ✅ 1. 验证 DKMS 模块已安装
dkms status | grep nvidia
# 预期输出:nvidia/590.48.01, 5.15.0-116-generic, x86_64: installed
# ✅ 2. 确认内核模块文件存在
ls -lh /lib/modules/$(uname -r)/updates/dkms/nvidia*.ko
# 应看到:nvidia.ko, nvidia-drm.ko, nvidia-modeset.ko, nvidia-uvm.ko
# ✅ 3. 验证 initramfs 已更新
ls -lh /boot/initrd.img-$(uname -r)
# 检查时间戳是否为最近
# ✅ 4. 确认 GRUB 配置正确
grep GRUB_DEFAULT /etc/default/grub
# 应为:GRUB_DEFAULT=0 或具体的内核版本
# ✅ 5. 测试 GRUB 更新无错误
sudo update-grub
# 应无 error 输出
# ✅ 6. 检查 fstab 正确性
sudo mount -a
# 应无错误(所有分区可挂载)
# ✅ 7. 验证网络配置(SSH 访问)
ip addr show
systemctl status ssh
重启后验证清单(Post-Reboot Verification)
# ✅ 1. 确认内核版本
uname -r
# 应为:5.15.0-116-generic
# ✅ 2. 验证 GPU 驱动
nvidia-smi
# 应显示 4 块 RTX 3080
# ✅ 3. 检查 CUDA 可用性
nvcc --version
# 应显示:Cuda compilation tools, release 13.1
# ✅ 4. 验证 DKMS 模块已加载
lsmod | grep nvidia
# 应看到多个 nvidia 相关模块
# ✅ 5. 检查系统日志无严重错误
journalctl -p err -b
dmesg | grep -i error
12. 应急联系与资源
官方文档
社区支持
- NVIDIA 开发者论坛:https://forums.developer.nvidia.com/
- Ubuntu 论坛:https://ubuntuforums.org/
- Stack Overflow CUDA 标签:https://stackoverflow.com/questions/tagged/cuda
紧急救援命令速查
# Live USB 快速挂载
sudo mount /dev/sda3 /mnt
sudo mount /dev/sda1 /mnt/boot
for i in /dev /proc /sys /run; do sudo mount --bind $i /mnt$i; done
sudo chroot /mnt
# 快速修复 GRUB
sudo grub-install /dev/sda
sudo update-grub
# 快速重建 initramfs
sudo update-initramfs -u -k all

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)