Claude Skill架构全解析:从理论到实践,带你深入AI能力落地秘籍!
在人工智能从原型验证迈向工业化部署的关键转折点,企业面临的核心挑战已从“能否实现”转向“如何高效、安全、可持续地规模化”。传统AI Agent模式受困于上下文(Token)成本与能力增长的线性矛盾、工具调用的安全黑洞以及知识资产的沉淀难题。Anthropic推出的Claude Skill System,并非仅仅是另一种工具调用接口,而是一场深刻的架构哲学变革——它将AI能力从临时、模糊的提示词(P
摘要 (Executive Summary)
在人工智能从原型验证迈向工业化部署的关键转折点,企业面临的核心挑战已从“能否实现”转向“如何高效、安全、可持续地规模化”。传统AI Agent模式受困于上下文(Token)成本与能力增长的线性矛盾、工具调用的安全黑洞以及知识资产的沉淀难题。Anthropic推出的Claude Skill System,并非仅仅是另一种工具调用接口,而是一场深刻的架构哲学变革——它将AI能力从临时、模糊的提示词(Prompt)升维为标准、可治理、可复用的“数字资产”。
本报告的核心结论是:Claude Skill System通过其独创的“三级懒加载(Lazy Loading)架构”、“确定性脚本外包”的SOP(标准操作程序)理念以及强制执行的三A(Audit, Authorization, Accounting)治理框架,成功定义了一种新的企业级AI能力交付范式 [2, 5, 25]。其核心价值在于:第一,成本革命:通过元数据常驻、主体按需加载的机制,理论上允许技能库无限扩展,而单次对话的推理成本保持稳定,从根本上优化了总拥有成本(TCO)[1, 2]。第二,安全与合规升维:将Skill视为“可执行代码”,强制企业建立涵盖审计、授权和全程日志的治理流程,满足了金融、法律等高度监管行业的刚性需求 [25, 28]。第三,能力资产化:将最佳实践固化为包含指令(SKILL.md)和脚本(scripts/)的标准化技能包,实现了AI能力的可版本控制、可测试和可传承,解决了“AI黑盒”与“知识流失”的顽疾 [6, 33]。
对于寻求构建长期、稳健AI竞争力的企业而言,采纳Claude Skill模式意味着从管理“AI助手个体”转向运营“AI能力工厂”。本报告建议决策者将其视为核心数字战略的一部分,设立专门的AI能力中心进行统筹,以在即将到来的AI工业化竞争中抢占先机 [10, 25]。
一、引言:企业AI规模化部署的“三重门”与范式革新需求
当前,企业AI应用正普遍遭遇“规模化鸿沟”。许多组织成功部署了令人惊艳的AI原型,却在将其转化为稳定、可靠、可管理的生产系统时举步维艰。这一鸿沟主要由三道“门槛”构成:
-
效率与成本门槛(The Efficiency-Cost Wall)
:传统方法中,为了让AI掌握复杂能力,开发者倾向于将所有工具描述和系统指令塞入上下文。这导致上下文窗口迅速膨胀,Token消耗呈线性甚至指数级增长,使得大规模部署的经济性变得不可持续 [4, 12]。有分析指出,不当的上下文管理是AI项目成本失控的主要原因之一 [23]。
-
安全与治理门槛(The Security-Governance Chasm)
:当AI获得调用外部API、执行代码或访问数据库的能力时,风险性质发生了根本改变——从“内容风险”升级为“执行风险”。缺乏对AI执行动作的细粒度审计、基于角色的权限控制和完整的操作日志,使得AI系统难以通过企业合规审查,更无法应用于核心业务流程 [20, 28]。
-
资产化与演进门槛(The Assetization-Evolution Gap)
:AI能力往往被困在冗长的系统提示(System Prompt)和临时的配置文件中,难以进行版本控制、质量测试和团队间共享。这导致了“重复造轮子”和“知识孤岛”,最佳实践无法沉淀,AI系统的迭代演进举步维艰 [4, 6]。
在此背景下,Claude Skill System的推出代表了一种根本性的范式革新 [25]。它不再将AI视为一个需要被不断“灌输”指令的黑箱,而是将其重构为一个核心推理引擎,其能力由外部一系列标准化、模块化、可治理的“技能资产”动态装备。本报告将深入解构这一系统的技术架构,对比分析其与传统方案的差异化优势,并提供从认知到落地的完整实践路径。
二、架构深度解构:Claude Skill的“三级懒加载”引擎与运行机制
Claude Skill System的技术精髓在于其清晰的分层架构和高效的按需加载机制,这直接击中了企业AI规模化中成本与效率的核心痛点。
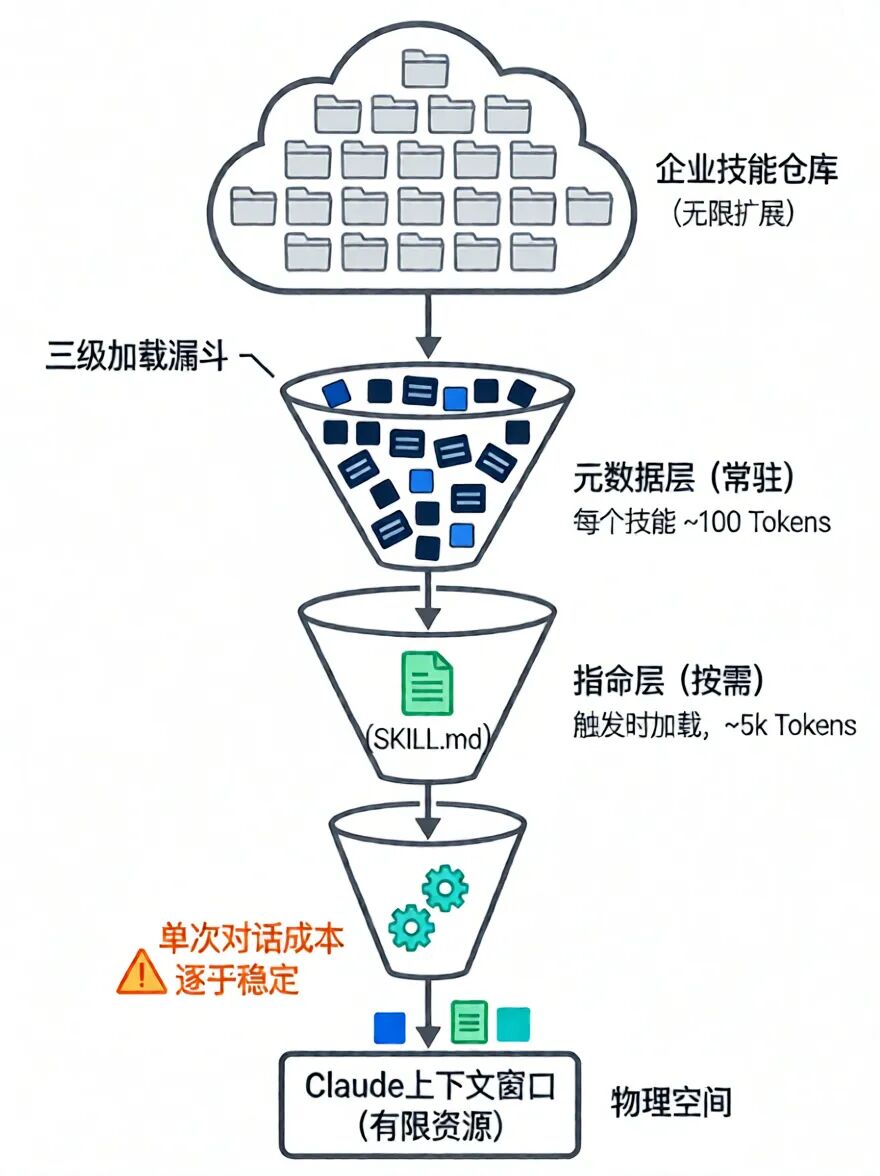
2.1 三级渐进式加载:实现“无限技能库”的工程魔法
Claude Skill的加载并非一次性行为,而是一个精妙的三级渐进过程,完美平衡了“能力丰富性”与“运行时效性” [2, 35]。
-
第一级:元数据层(Metadata - Always Loaded)
:当Claude启动或一个会话开始时,仅有每个已安装技能的极简元数据被加载到上下文窗口中。这些元数据通常只包含技能名称、一句话描述和触发关键词,每个技能仅消耗约100个Tokens [1]。这相当于一份技能目录,让模型知道“有哪些技能可用”,但不知道“具体怎么用”。这确保了即使拥有成百上千个技能,基础对话的上下文开销也微乎其微。
-
第二级:指令层(Instructions - Loaded on Demand)
:当用户的请求与某个技能的元数据匹配时,系统会动态地将该技能的核心文件——
SKILL.md——加载到上下文中 [35, 38]。这个Markdown文件包含了使用该技能的详细指南、工作流程、示例和注意事项,规模通常控制在5k Tokens以内 [5]。此时,Claude从“知道技能存在”变为“懂得如何运用该技能”。 -
第三级:资源层(Resources - Loaded on Execution)
:在技能执行的具体环节,如果需要参考特定文档、模板或运行脚本,Claude会通过Bash命令(如
cat REFERENCE.md或python scripts/process.py)来按需读取或执行这些资源 [2]。关键的是,只有这些命令的输出结果(而非脚本本身)被注入上下文,实现了成本的最小化。
这种设计与操作系统中的“虚拟内存”和“动态链接库”思想异曲同工,使系统能够维持一个庞大的“技能虚拟地址空间”,而仅在需要时将少数“页面”交换进有限的“物理内存”(上下文窗口)中 [1, 10]。
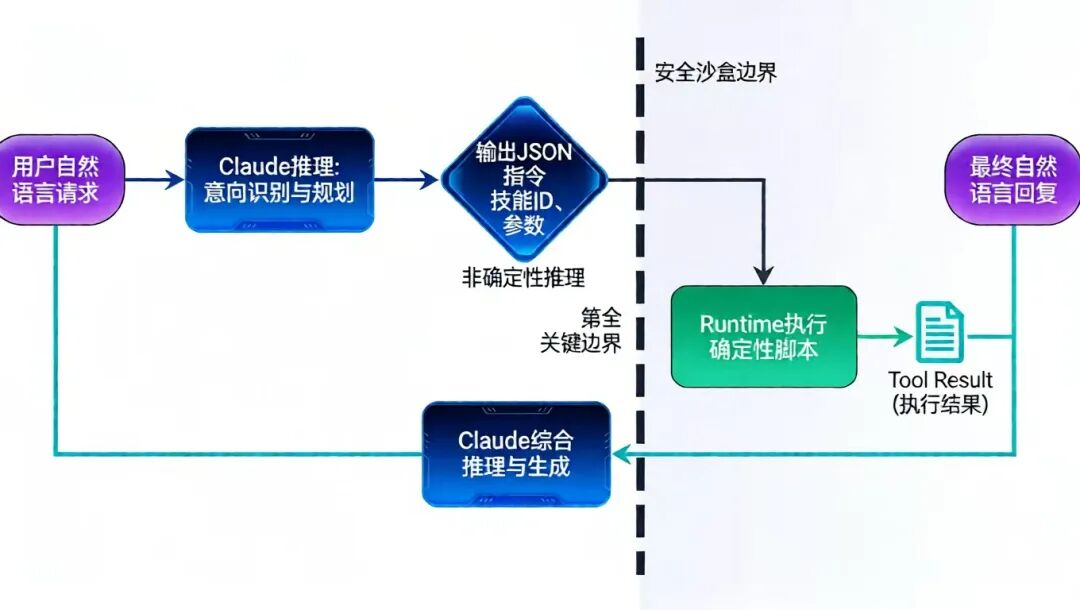
2.2 闭环工作流:模型决策与外部执行的清晰边界
Claude Skill的执行遵循一个严谨的、步骤分离的闭环,这体现了其将“推理”与“执行”解耦的核心设计哲学 [27]。
-
意图识别与技能触发
:用户输入自然语言请求。Claude基于常驻的元数据,判断是否需要以及需要调用哪个技能。
-
JSON指令输出(模型侧)
:Claude进行规划与推理,但绝不直接执行代码。它仅输出一个结构化的JSON对象,其中包含要调用的技能ID、函数名和参数。这确保了模型行为的确定性和可预测性。
-
Runtime执行(系统侧)
:外部Runtime(一个安全的代码执行环境)接收并解析JSON指令,定位并执行对应的脚本(如Python、Bash)。这是模型与真实世界之间不可逾越的“安全沙盒”边界 [28]。
-
结果格式化与上下文注入
:Runtime将脚本执行的结果(可能是数据、文件ID或状态信息)格式化为标准的
Tool Result消息,重新注入对话上下文。 -
综合推理与最终回复
:Claude接收到执行结果作为新的“观察”,结合原始请求和自身推理,生成面向用户的最终自然语言回复。
这个流程的核心价值在于“权责分离”:模型负责其擅长的、不确定性的语义理解与规划;Runtime负责确定性的、可精确复现的计算与操作。这不仅提升了结果可靠性,也为安全审计奠定了坚实基础 [5, 27]。
2.3 技能资产包:标准化的结构与内容
一个Claude Skill是一个标准的文件夹,其结构体现了模块化设计思想 [33, 40]:
my-skill/├── SKILL.md # 核心:YAML前言(元数据)+ Markdown指令├── scripts/│ └── process.py # 确定性逻辑的Python脚本├── templates/│ └── report.docx # 可引用的模板文件└── references/ └── api_ref.md # 参考文档
SKILL.md是技能的“大脑”,其开头的YAML块定义了技能名称、描述等元数据,后续的Markdown部分则是详细的操作手册 [36, 39]。这种基于文件系统的设计,使得技能可以像普通代码一样用Git进行版本控制,无缝集成到CI/CD流水线中 [31]。
三、企业级差异化优势:从技术特性到治理模型的升维竞争
Claude Skill System的竞争力不仅在于其优雅的技术架构,更在于它将这些技术特性转化为切实可行的企业治理模型,从而在与OpenAI Assistants/Tools等方案的竞争中形成了鲜明的差异化定位。
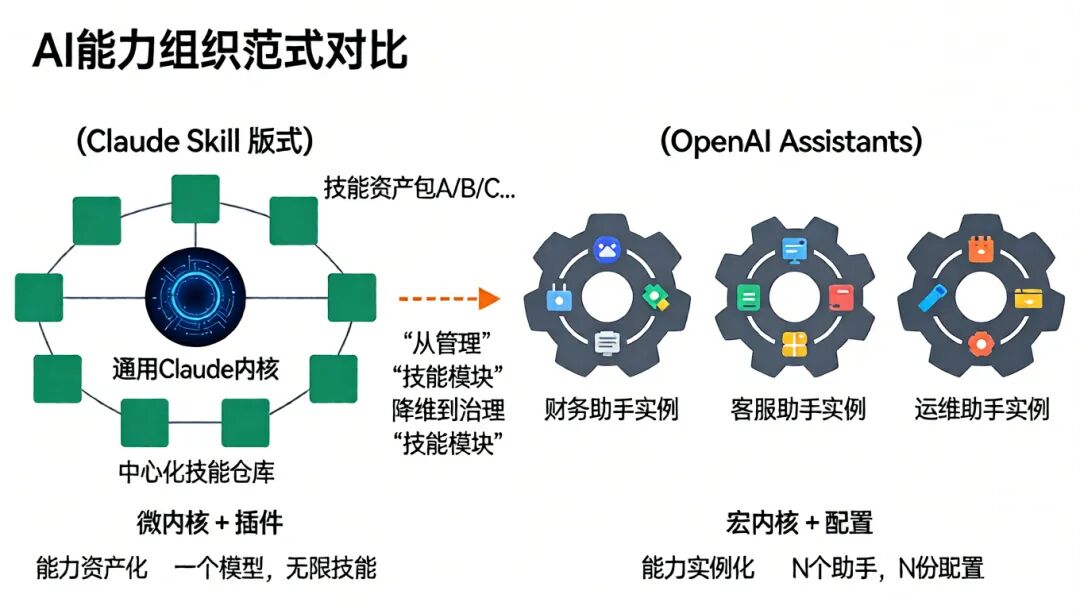
3.1 架构哲学对比:模块化资产仓库 vs. 集成化助手实例
这是两种截然不同的AI能力组织范式。
-
Claude Skill范式
:遵循“微内核+插件”架构。一个统一的、通用的Claude模型作为内核,所有专业化能力都以外挂“技能资产包”的形式存在。企业维护的是一个中心化的技能仓库,技能可以被任何会话按需调用。这种模式将复杂度从管理无数个定制化的“Agent实例”降维到治理标准化的“技能模块” [25]。社区分析指出,这有效避免了“Agent动物园”带来的管理混乱 [32]。
-
OpenAI Assistants范式
:更接近“宏内核+配置”架构。每个Assistant都是一个相对独立的实例,其能力(通过Function Calling或知识库)在创建时被定义和绑定。要扩展或修改能力,通常需要创建新的Assistant或修改现有Assistant的配置。这导致了能力的碎片化和复用困难。
辩证分析:OpenAI的集成化模式在构建单一、专注的对话体验时可能更简单直观。然而,当企业需要跨部门部署数十上百个AI应用时,Claude的模块化资产模式在标准化、可复用性和长期治理成本上展现出压倒性优势。前者像是为每个任务定制一把瑞士军刀,后者则是建立一个工具库,为通用机器人配备可更换的专用工具头。
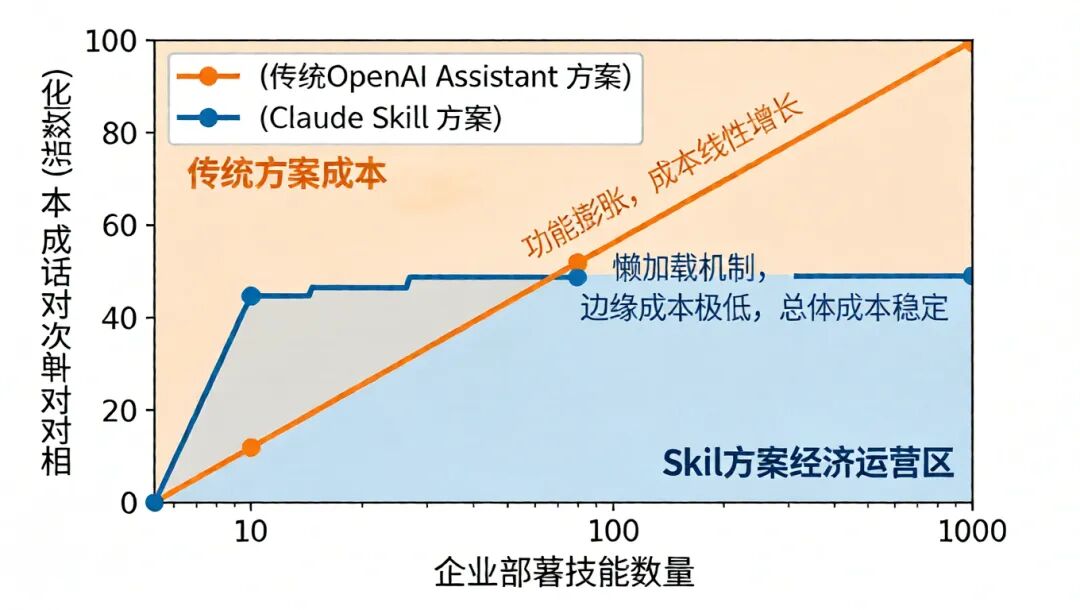
3.2 总拥有成本(TCO)分析:懒加载带来的经济性革命
Token成本是企业AI部署中不可忽视的硬性支出。Claude Skill的懒加载机制对其TCO产生了根本性影响。
-
Claude Skill的成本模型
:成本主要由两部分构成:(1) 基础会话成本:由模型本身和常驻的少量技能元数据决定,几乎恒定。(2) 技能执行成本:仅在技能被触发时产生,加载
SKILL.md和执行脚本输出的Token费用。由于大多数技能在大多数会话中不被触发,因此边际成本极低。这使得企业可以大胆扩展技能库,而无需担心成本失控。 -
传统/OpenAI Assistants的成本压力
:为了赋予Assistant足够的能力,开发者通常需要将大量工具描述、系统指令和上下文示例一次性填入。这些内容在每次对话开始时都需全额支付Token费用,无论本次对话是否用到所有这些功能 [12]。随着功能复杂化,上下文迅速膨胀,成本线性增长。
行业定价对比显示,Claude的每百万Token输出成本较高 [23]。但若考虑效率因素——即完成相同复杂任务所需的交互轮次和总体Token消耗——Claude Skill通过精准的按需加载和高效的流程执行,往往能在整体工作流成本上取得优势,特别是在涉及复杂、多步骤的企业流程中 [16]。
3.3 治理深度对比:执行安全与流程合规 vs. 内容安全
在企业级场景中,安全与合规是决策的底线。两者在此维度上关注点截然不同。
-
Claude Skill:强调“执行治理”
:它将Skill明确定义为“可执行代码”,因此其治理框架(三A框架)紧紧围绕代码执行展开 [25, 28]。
-
审计(Audit)
:所有技能的代码(脚本)必须在上线前经过安全扫描和合规审查,确保无恶意操作或数据泄露风险。技能的所有调用、执行参数和结果都会生成不可篡改的审计日志。
-
授权(Authorization)
:可以实现基于角色(RBAC)或属性的访问控制(ABAC)。例如,只有财务部的员工才能触发“生成财务报表”技能;只有高级工程师才能运行“部署生产环境”脚本。
-
计量(Accounting)
:对技能的使用次数、执行时长、资源消耗进行精细计量,用于成本分摊、性能优化和合规报告。
-
OpenAI:侧重“内容安全”
:OpenAI提供了强大的内容过滤系统、隐私承诺和企业级数据管理。其安全重点在于防止模型生成有害、偏见或不准确的内容,以及保障用户数据不被用于训练。然而,对于模型调用外部工具(Functions)的行为,企业需要自行构建外部的审计和授权层。
结论:对于关注内容生成合规性(如营销、客服)的企业,OpenAI的方案成熟可靠。但对于需要将AI嵌入核心运营流程(如自动交易、法律文件生成、IT运维)的企业,Claude Skill内置的、针对“执行”的深度治理能力是不可或缺的刚需,它直接将AI从“建议者”提升为“可信赖的操作者”。
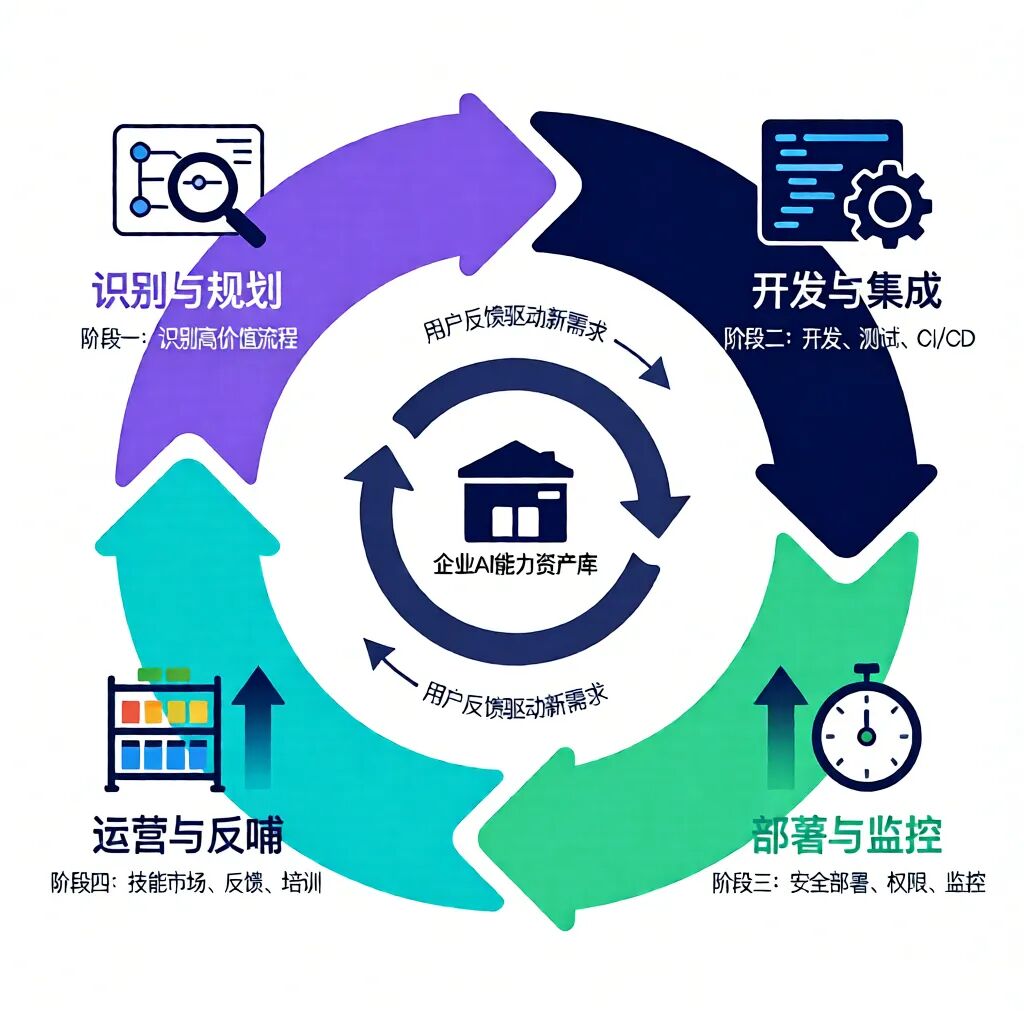
四、实践落地指南:构建企业内部的“AI能力工厂”
将Claude Skill System成功落地,意味着在企业内部建立一套生产、管理和运营AI能力资产的完整体系。以下是一个四阶段的实施路径图。
4.1 第一阶段:战略规划与技能识别
-
确立治理组织
:成立由IT、安全、合规、业务部门代表组成的“AI技能治理委员会”,负责制定技能开发标准、审批流程和运营策略。
-
高价值流程挖掘
:筛选适合技能化的场景。理想候选通常具有:高频重复(如日报生成)、强流程性(如客户入职SOP)、需结合专业知识与计算(如财务分析)、当前存在人工瓶颈等特点。
-
技能设计规范
:制定企业内部的《技能开发规范》,明确规定
SKILL.md的模板(必须包含目标、前置条件、输入/输出格式、错误处理)、脚本编写的安全要求(禁止网络访问、文件系统白名单)、以及资源文件的组织方式。
4.2 第二阶段:开发、测试与CI/CD集成
-
开发环境搭建
:配置安全的代码执行沙箱环境(Runtime),确保技能脚本在受限的权限下运行,与企业生产网络隔离。
-
技能开发
:
-
编写
SKILL.md:使用清晰的逻辑和示例,将SOP转化为AI可理解的指令。避免冗长,超过500行应考虑拆分为引用文件 [40]。
-
开发脚本
:用Python或Bash编写确定性逻辑。脚本应具有良好的错误处理和日志输出,以便于调试和审计。
-
自动化测试
:将技能包视为软件组件,建立自动化测试管道。
-
单元测试
:对脚本逻辑进行测试。
-
集成测试
:模拟Claude API调用,验证从自然语言请求到技能触发再到最终输出的端到端流程。可以利用开源框架进行模拟 [31]。
-
CI/CD流水线
:将技能文件夹纳入Git仓库。通过CI/CD工具(如GitHub Actions),在代码提交时自动运行测试、安全扫描,并自动打包(ZIP)技能,准备部署 [31]。
4.3 第三阶段:安全部署与权限配置
-
部署上线
:通过Claude API或管理控制台,将打包好的技能ZIP文件上传至企业的Claude环境。
-
配置权限(Authorization)
:在企业的身份管理系统(如Okta, Azure AD)与Claude Skill治理层之间建立集成。根据前期规划,为不同用户组配置可访问的技能白名单。
-
监控与告警
:启用并配置审计日志(Accounting)。监控技能调用频率、失败率、执行时长等指标,设置异常告警(如某个高权限技能被异常频繁调用)。
4.4 第四阶段:运营、演进与文化建设
-
运营反馈循环
:定期分析审计日志和用户反馈,识别使用率低或问题多的技能,进行优化或下线。
-
建立技能市场
:在企业内部创建一个可搜索的技能目录,鼓励各部门分享和复用技能,避免重复建设。可以设立奖励机制,激励员工贡献高质量技能。
-
培训与推广
:对业务人员进行培训,让他们了解如何通过自然语言有效调用现有技能来解决工作问题,提升AI赋能的普及度。
-
演进路线图
:关注Anthropic的技能生态发展,评估引入外部优秀技能或参与技能标准共建的可能性,持续将AI能力工厂做大做强。
五、未来展望:Skill驱动的AI能力生态与战略意义
Claude Skill System的推出不仅是一个产品特性,更可能预示着一个新产业生态的萌芽。
-
技能标准化与跨平台移植
:Anthropic已宣布开放Skill标准 [25]。未来,我们可能看到类似Docker容器的“技能容器”标准出现,使得为Claude开发的技能能够经过少量适配,在其他AI模型或平台上运行。这将极大繁荣AI能力开发生态,降低企业锁定风险。
-
AI编写AI技能(Meta-Skill)
:一个自然演进的方向是开发能让Claude自行创建或优化技能的“元技能”。Claude可以分析一个低效的工作流程,自动生成对应的
SKILL.md草案和脚本框架,再由人类工程师审核和完善。这将实现AI能力的自我进化。 -
企业AI架构的核心层
:在未来企业的数字化架构中,“Skill层”可能成为介于基础大模型与具体业务应用之间的关键能力中间件。它封装了企业的核心业务流程、知识经验和合规要求,是企业真正的“AI数字资产”。
-
对竞争格局的影响
:Claude Skill在企业和开发者群体中获得的积极反响,正在迫使整个行业重新思考AI能力的交付方式 [19, 29]。它成功地将竞争焦点从单纯的“模型能力竞赛”部分转向了“开发者体验与生态系统建设”。未来,拥有更丰富、更易治理的技能生态的平台,将获得更强的客户粘性和更深的行业渗透力。
六、结论
Claude Skill System是一次针对企业AI规模化核心痛点的精准架构响应。它通过三级懒加载解决了成本与效率的困局,通过模型与Runtime的权责分离实现了流程的确定性与可审计性,通过技能资产化和三A治理框架满足了企业对于安全、合规与知识沉淀的根本需求。
这项技术远不止于让AI“更强大”,而是致力于让AI在企业中“更可用、更可靠、更可管理”。对于志在通过人工智能构建长期竞争优势的企业而言,理解并采纳Claude Skill所代表的“能力资产化”范式,不仅仅是引入一项新工具,更是启动一场关乎未来数字化核心竞争力的深度变革。建议企业将其提升至战略高度,系统规划,分步实施,逐步建立起内生的、持续进化的AI能力工厂,以驾驭下一波AI工业化的浪潮。
七、如何学习AI大模型?
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献163条内容
已为社区贡献163条内容

所有评论(0)