【GitHub开源AI精选】SmartResume:阿里巴巴开源高效智能简历解析系统
SmartResume是由阿里巴巴开源的智能简历解析系统,融合了OCR文本提取、PDF元数据解析、版面检测(YOLOv10模型)及轻量化大语言模型(Qwen3-0.6B微调版),支持PDF、图片、Word等多种常见格式的简历解析,能够将非结构化文本秒级转换为结构化数据,如姓名、工作经历、教育背景等,其核心创新在于通过版面感知技术重建阅读顺序,解决复杂布局导致的语义断裂问题,同时利用轻量化模型实现高
系列篇章💥
目录
前言
在当今数字化时代,企业招聘面临着海量简历的处理挑战。传统手动筛选简历的方式不仅效率低下,还容易出现错误。为解决这一痛点,阿里巴巴开源了SmartResume智能简历解析系统,旨在通过先进的AI技术,实现简历的自动化处理,提升招聘效率。
一、项目概述
SmartResume是由阿里巴巴开源的智能简历解析系统,融合了OCR文本提取、PDF元数据解析、版面检测(YOLOv10模型)及轻量化大语言模型(Qwen3-0.6B微调版),支持PDF、图片、Word等多种常见格式的简历解析,能够将非结构化文本秒级转换为结构化数据,如姓名、工作经历、教育背景等,其核心创新在于通过版面感知技术重建阅读顺序,解决复杂布局导致的语义断裂问题,同时利用轻量化模型实现高效推理,平衡精度与成本。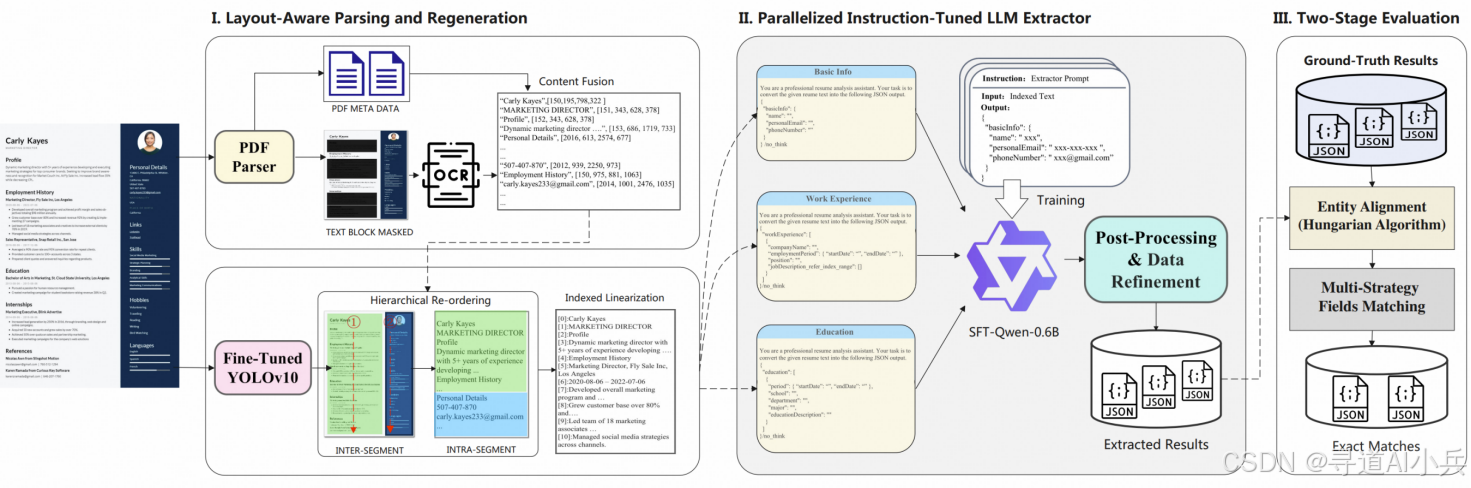
二、核心功能
(一)多格式简历解析
SmartResume支持多种常见格式的简历解析,包括PDF、图片(如JPG、PNG)、Word和Excel。通过结合OCR技术和PDF元数据提取,系统能够从不同格式的简历中提取纯文本内容,确保文本的完整性和准确性。这种多格式支持能力使SmartResume能够适应各种简历提交方式,极大地扩展了其应用场景。
(二)版面检测与阅读顺序重建
SmartResume利用YOLOv10模型进行版面检测,能够识别简历中的标题、段落、表格等区域。通过三层排序策略(段间排序、段内排序、行级索引线性化),系统按人类阅读习惯重建文本的逻辑顺序。这种版面感知技术有效解决了复杂布局导致的语义断裂问题,确保提取内容的连贯性和可读性。
(三)智能结构化处理
基于微调版Qwen3-0.6B模型,SmartResume将提取的文本内容转换为结构化的JSON格式。系统能够精准提取关键字段,如姓名、电话、邮箱、工作经历和教育背景等。通过任务分解和指针机制,SmartResume避免了传统方法中的“幻觉”问题,确保提取信息的准确性和完整性。
(四)灵活部署方案
SmartResume提供多种部署方式,包括API接口调用和本地模型部署。用户可以根据自身需求选择适合的部署方案,API调用方便与现有系统集成,而本地部署则减少了对外部服务的依赖,增强了数据隐私和安全性。这种灵活的部署方式使SmartResume能够适应不同的使用场景和需求。
(五)高效处理能力
SmartResume在性能优化方面表现出色,单页简历处理时间仅需1.22秒。在线服务的吞吐量可达每分钟240-300份简历,平均响应延迟低于2秒。这种高效的处理能力得益于系统对大语言模型的优化和版面感知技术的高效实现,使得SmartResume在处理大规模简历数据时依然保持快速和稳定。
三、技术揭秘
(一)版面感知技术
SmartResume采用先进的版面感知技术,通过YOLOv10模型检测简历中的文本块、标题、段落等区域,精准识别复杂布局。该技术结合段间排序、段内排序和行级索引线性化,按人类阅读习惯重建文本顺序,确保语义连贯性。这种版面感知方法有效解决了复杂布局导致的语义断裂问题,为后续的文本提取和结构化处理提供了坚实基础。
(二)LLM优化
SmartResume基于微调版Qwen3-0.6B模型进行内容结构化处理。该模型专门针对简历信息提取任务进行优化,通过任务分解为“基础信息提取”“工作经历提取”“教育背景提取”三个并行子任务,避免任务干扰,提升F1分数。此外,模型采用指针机制,返回原文行号索引,而非直接生成内容,有效避免“幻觉”问题,确保数据100%原样输出。
(三)指针机制
SmartResume创新性地引入指针机制,模型预测描述在原文中的行号范围,系统根据行号从原始文本中精确回填。这种机制有效降低了Token开销,避免了内容漂移和延迟不可控的问题。通过指针机制,SmartResume确保了提取信息的准确性和完整性,同时提高了系统的稳定性和可靠性。
四、应用场景
(一)企业招聘系统
在企业招聘中,SmartResume可自动解析候选人投递的简历,快速提取关键信息,如姓名、联系方式、工作经历等,并直接填充到企业的人力资源管理系统中。这大大减少了HR手动录入简历信息的工作量,提高了招聘流程的效率,使企业能够更快地筛选出合适的候选人,提升整体招聘体验。
(二)招聘平台
对于招聘平台,SmartResume能够快速对海量简历进行标签化和筛选。通过智能结构化处理,平台可以更精准地匹配职位需求与候选人简历,帮助招聘者快速找到符合要求的人才。这不仅提高了招聘效率,还能提升平台的服务质量和用户体验。
(三)校园招聘
在校园招聘场景中,SmartResume支持批量导入学生简历,能够高效匹配岗位需求,快速筛选出符合要求的候选人。这有助于企业节省时间和精力,更好地从大量学生简历中发现优秀人才,提高校园招聘的效率和质量。
(四)猎头机构
猎头机构可以利用SmartResume结构化管理候选人数据,实现精准匹配和推荐。通过智能解析简历,猎头顾问能够快速了解候选人的背景和技能,从而更高效地为客户提供高质量的人才推荐服务,提升服务质量。
(五)HR SaaS产品
SmartResume为HR SaaS产品提供了智能简历录入功能,支持API调用,方便集成到HR SaaS产品中。这使得HR SaaS产品能够更高效地处理简历数据,为用户提供更便捷、更智能的招聘管理体验,增强产品的竞争力。
五、快速使用
(一)环境准备
在开始使用SmartResume之前,需要确保你的设备满足最低配置要求:Python 3.9及以上版本,内存8GB以上,存储空间10GB以上。如果需要GPU加速,还需要安装CUDA 11.0及以上版本。这些配置将确保系统运行流畅,避免因硬件不足导致的性能问题。
- Python >= 3.9
- CUDA >= 11.0 (optional, for GPU acceleration)
- Memory >= 8GB
- Storage >= 10GB
(二)克隆仓库
通过Git将SmartResume项目克隆到本地。打开终端或命令提示符,输入以下命令:
git clone https://github.com/alibaba/SmartResume.git
cd SmartResume
这将下载项目代码到本地目录,为后续的安装和部署做好准备。
(三)创建环境
使用Conda创建一个Python环境,以确保依赖项的隔离和管理。运行以下命令:
conda create -n smartresume python=3.9
conda activate smartresume
这将创建一个名为“smartresume”的Python环境,并激活它,以便安装项目所需的依赖。
(四)安装依赖
在激活的环境中,运行以下命令安装项目所需的依赖包:
pip install -e .
(五)配置文件
在项目根目录中,复制config_template.yaml文件并重命名为config.yaml。根据你的需求修改配置文件中的参数,例如添加必要的API密钥等信息。这一步是系统正常运行的关键配置环节。
# Copy configuration template
cp configs/config.yaml.example configs/config.yaml
# Edit configuration file and add API keys
vim configs/config.yaml
(六)启动解析
通过命令行界面(CLI)或Python API调用解析功能。例如,使用CLI工具解析一个PDF简历文件:
# Parse single resume file
python scripts/start.py --file resume.pdf
# Specify extraction types
python scripts/start.py --file resume.pdf --extract_types basic_info work_experience education
或者通过Python代码调用API进行解析:
from smartresume import ResumeAnalyzer
# Initialize analyzer
analyzer = ResumeAnalyzer(init_ocr=True, init_llm=True)
# Parse resume
result = analyzer.pipeline(
cv_path="resume.pdf",
resume_id="resume_001",
extract_types=["basic_info", "work_experience", "education"]
)
print(result)
这将启动解析流程,输出结构化的JSON数据。
(七)本地模型部署(可选)
如果需要本地部署模型,可以下载模型文件并启动本地模型服务。这将减少对外部API的依赖,提升数据隐私和安全性。具体步骤如下:
# Download Qwen-0.6B-resume model
python scripts/download_models.py
# Deploy model
bash scripts/start_vllm.sh
运行该命令后,本地模型服务将启动,你可以通过本地接口进行简历解析。
六、结语
SmartResume作为阿里巴巴开源的智能简历解析系统,凭借其强大的功能和灵活的部署方式,为企业招聘提供了高效的解决方案。它不仅提高了简历处理的效率和准确性,还降低了大模型技术的使用成本。相信在未来,SmartResume将在更多招聘场景中发挥重要作用,推动招聘行业的智能化发展。
项目地址
- GitHub仓库:https://github.com/alibaba/SmartResume
- HuggingFace模型库:https://hf-mirror.com/Alibaba-EI/SmartResume

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 23
23 0
0- 0



 已为社区贡献67条内容
已为社区贡献67条内容

所有评论(0)