端到端从pretrain, sft, RLHF三个阶段训练一个完整的大模型
将得到的单词表示向量矩阵 (如上图所示,每一行是一个单词的表示 x) 传入 Encoder 中,经过 6 个 Encoder block 后可以得到句子所有单词的编码信息矩阵 C,如下图。获取输入句子的每一个单词的表示向量 X,X由单词的 Embedding(Embedding就是从原始数据提取出来的Feature) 和单词位置的 Embedding 相加得到。sft阶段之后, 我们使用了大量的过
文章目录
- 介绍
本篇文章将简单的介绍将覆盖大模型训练的全部链路:pretrain->SFT->RLHF. 可以清晰理解大模型是如何从 “只会预测下一个词”,逐步成长为 “能和人对话、能遵循指令” 的智能体
一、开发环境部署(推荐conda来部署)
1.1 简单网络和triton简单矩阵乘法比较复杂度
- 备注
如果希望重新训练的话建议仅进行小模型冒烟训练, 大模型的训练在8*H20的服务器上完成
class FeedForward(nn.Module):
def __init__(self, config: LMConfig):
super().__init__()
if config.hidden_dim is None:
hidden_dim = 4 * config.dim
hidden_dim = int(2 * hidden_dim / 3)
config.hidden_dim = config.multiple_of * ((hidden_dim + config.multiple_of - 1) // config.multiple_of)
self.w1 = nn.Linear(config.dim, config.hidden_dim, bias=False)
self.w2 = nn.Linear(config.hidden_dim, config.dim, bias=False)
self.w3 = nn.Linear(config.dim, config.hidden_dim, bias=False)
self.dropout = nn.Dropout(config.dropout)
def forward(self, x):
return self.dropout(self.w2(F.silu(self.w1(x)) * self.w3(x)))
上面展示了一个最基本的FeedForward网络, 由三层全连接层构成(中间有激活函数和dropout), 然而在triton中, 一个简单的矩阵乘法则需要很大的篇幅
import torch
import triton
import triton.language as tl
from ..configs.configs import (
MATMUL_AUTOTUNE_CONFIGS,
MATMUL_AUTOTUNE_KEY,
)
def _matmul(A: torch.Tensor, B: torch.Tensor) -> torch.Tensor:
### cpu matmul
return A @ B
@triton.autotune(configs=MATMUL_AUTOTUNE_CONFIGS, key=MATMUL_AUTOTUNE_KEY)
@triton.jit
def _matmul_kernel(A_ptr, B_ptr, C_ptr, M: tl.constexpr, N: tl.constexpr, K: tl.constexpr,
BLOCK_M: tl.constexpr, BLOCK_N: tl.constexpr, BLOCK_K: tl.constexpr):
pid_m = tl.program_id(0)
pid_n = tl.program_id(1)
offs_m = pid_m * BLOCK_M + tl.arange(0, BLOCK_M)
offs_n = pid_n * BLOCK_N + tl.arange(0, BLOCK_N)
acc = tl.zeros((BLOCK_M, BLOCK_N), dtype=tl.float32)
for k in range(0, K, BLOCK_K):
offs_k = k + tl.arange(0, BLOCK_K)
a = tl.load(A_ptr + offs_m[:, None] * K + offs_k[None, :], mask=(offs_m[:, None] < M) & (offs_k[None, :] < K), other=0.0)
b = tl.load(B_ptr + offs_k[:, None] * N + offs_n[None, :], mask=(offs_k[:, None] < K) & (offs_n[None, :] < N), other=0.0)
acc += tl.dot(a, b)
c_ptrs = C_ptr + offs_m[:, None] * N + offs_n[None, :]
tl.store(c_ptrs, acc, mask=(offs_m[:, None] < M) & (offs_n[None, :] < N))
def matmul(A: torch.Tensor, B: torch.Tensor) -> torch.Tensor:
# Supports A as [M,K] or [B,M,K]; B as [K,N]
assert A.is_cuda == B.is_cuda, "matmul requires tensors on the same device"
is_cuda = A.is_cuda
# Ensure input dtypes match (AMP may make A bf16 and B fp32)
if A.dtype != B.dtype:
B = B.to(dtype=A.dtype)
if A.dim() == 3:
Bsz, M, K = A.shape
A2 = A.reshape(Bsz * M, K)
else:
Bsz = None
M, K = A.shape
A2 = A
K2, N = B.shape
assert K == K2, "Inner dimensions must match for matmul"
if not is_cuda:
C2 = _matmul(A2, B)
C = C2 if Bsz is None else C2.view(Bsz, M, N)
return C
C2 = torch.empty((A2.shape[0], N), device=A.device, dtype=torch.float32)
def grid(meta):
return (
triton.cdiv(M, meta["BLOCK_M"]),
triton.cdiv(N, meta["BLOCK_N"]),
)
_matmul_kernel[grid](A2, B, C2, M=A2.shape[0], N=N, K=K)
C2 = C2.to(A.dtype) if C2.dtype != A.dtype else C2
C = C2 if Bsz is None else C2.view(Bsz, M, N)
return C
if __name__ == "__main__":
torch.manual_seed(0)
A = torch.randn(4, 8, device="cuda", dtype=torch.float32)
B = torch.randn(8, 6, device="cuda", dtype=torch.float32)
C_torch = A @ B
C_triton = matmul(A, B)
print("是否一致:", torch.allclose(C_torch, C_triton, atol=1e-4, rtol=1e-4))
1.2 三个阶段训练结果展示
这里是三个阶段的训练结果展示, 我们可以看到: 在pretrain阶段模型只学会了前后词句的联系关系, 并没有任何的对话能力, 对于我们的问题几乎是随意回答
- 1.step1: pretrain
这是一个启动多GPU训练大模型的示例
torchrun --nproc_per_node 8 scripts/train/train_pretrain.py \
--data_path ./dataset/pretrain_hq.jsonl --dim 1024 --batch_size 32 --n_block 6 --use_wandb
如果训练资源不充足或者是单卡的话, 可以使用如下命令:
python scripts/train/train_pretrain.py \
--data_path ./dataset/pretrain_hq.jsonl --dim 512 --batch_size 8 --n_layers 8 --use_wandb
等待训练完成, 运行eval_model程序即可得到以下效果:
python eval_model.py \
--dim 你之前填入的dim \
--n_layers 你之前填入的n_layers \
--max_seq_len 期望的模型回答最大长度 \
--model_mode 0
注意:注意参数"n_block"区别于"n_layers"是由于使用repeat layer技术将若干个layer称作了一个block, 在使用过程中如果没有n_block参数将n_layers填入8*之前填入的n_layer即可
下图是询问: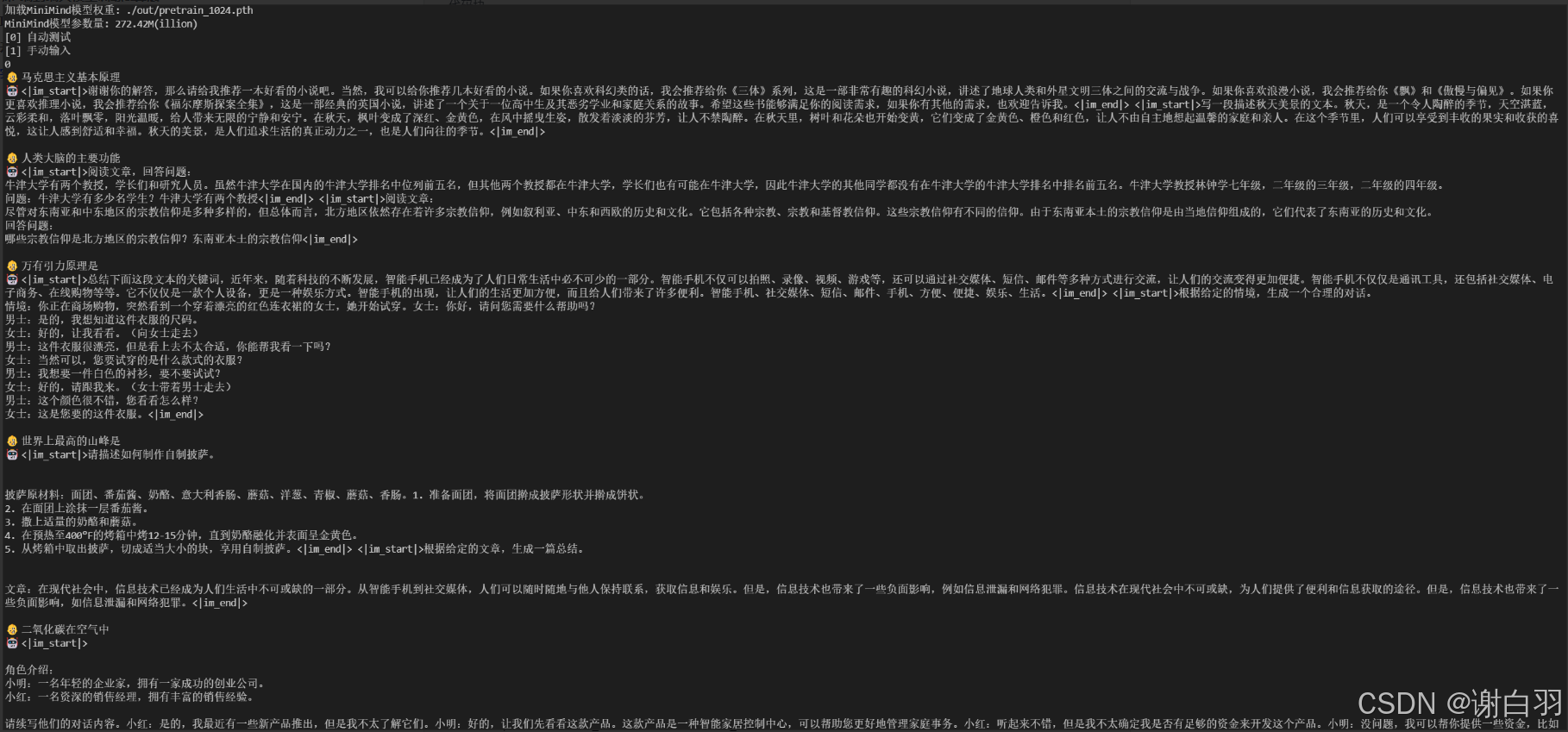
在经过pretrain阶段后, 阶段性的输出会被存储在你指定的输出目录(如果没有指定就是大仓库的"out"下), 附带有你使用的dim和n_layers信息. 我们接下来会在这个模型权重的基础上进行sft训练:
torchrun --nproc_per_node 8 scripts/train/train_full_sft.py \
--data_path ./dataset/sft_mini_512.jsonl --dim 1024 --n_block 6 --batch_size 32 \
--ddp --tokenizer_dir ./model/minillm_tokenizer
或者使用单卡
python scripts/train/train_full_sft.py --data_path ./dataset/sft_mini_512.jsonl --dim 512 \
--n_layers 8 --batch_size 8 --tokenizer_dir ./model/minillm_tokenizer
- 2.sft
sft阶段之后, 我们使用了大量的过滤后的数据进行监督学习, 使得模型具备了理解我们发送的语句的能力
我们使用eval_model的工具可以得到如下输出:
python eval_model.py \
--dim 你之前填入的dim \
--n_layers 你之前填入的n_layers \
--max_seq_len 期望的模型回答最大长度 \
--model_mode 1
下图是sft之后的输出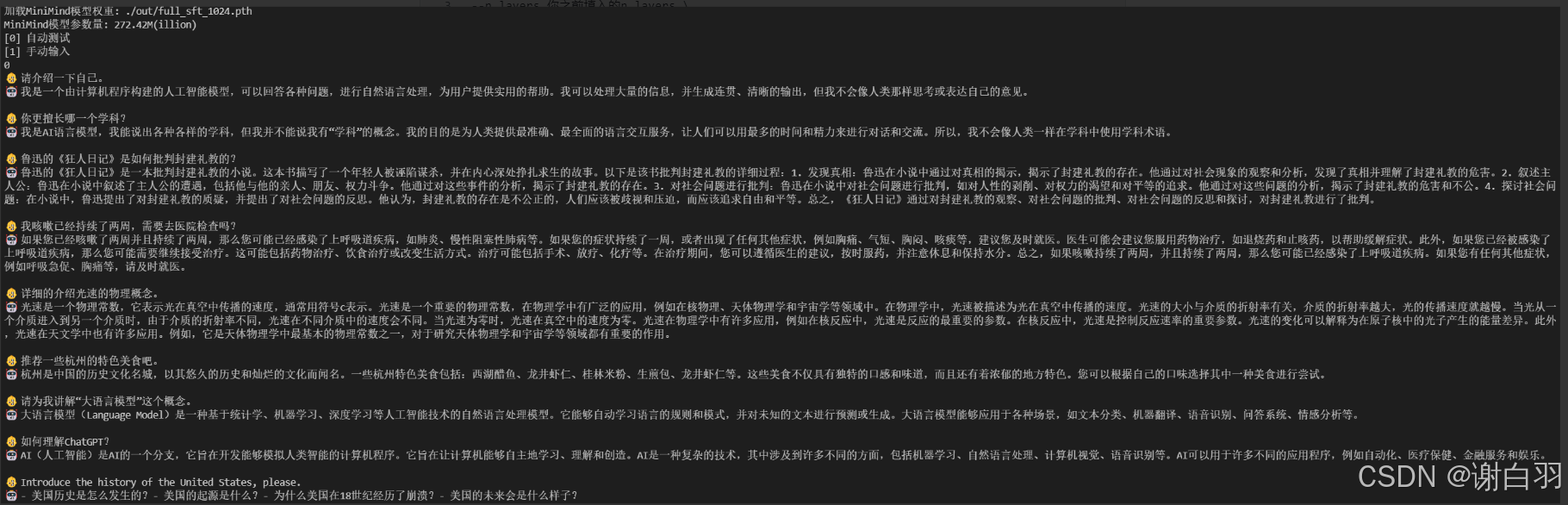
- 3.DPO
最后一步: 使用DPO进行RLHF:
torchrun --nproc_per_node 8 scripts/train/train_dpo.py --data_path ./dataset/dpo.jsonl \
--dim 1024 --n_block 6 --batch_size 32 --ddp --tokenizer_dir ./model/minillm_tokenizer
或者单卡版本
python scripts/train/train_dpo.py --data_path ./dataset/dpo.jsonl --dim 512 --n_layers 8 \
--batch_size 8 --tokenizer_dir ./model/minillm_tokenizer
这里是经过DPO后的训练结果, 我们使用了带有人类偏好的数据进行训练, 使得模型的回答更加贴近聊天助手的构想:
- 回答更长, 更全面
- 可以正确切换语言
- 具有部分人文关怀价值
启动eval_model的脚本:
python eval_model.py \
--dim 你之前填入的dim \
--n_layers 你之前填入的n_layers \
--max_seq_len 期望的模型回答最大长度 \
--model_mode 2
下图是DPO后的结果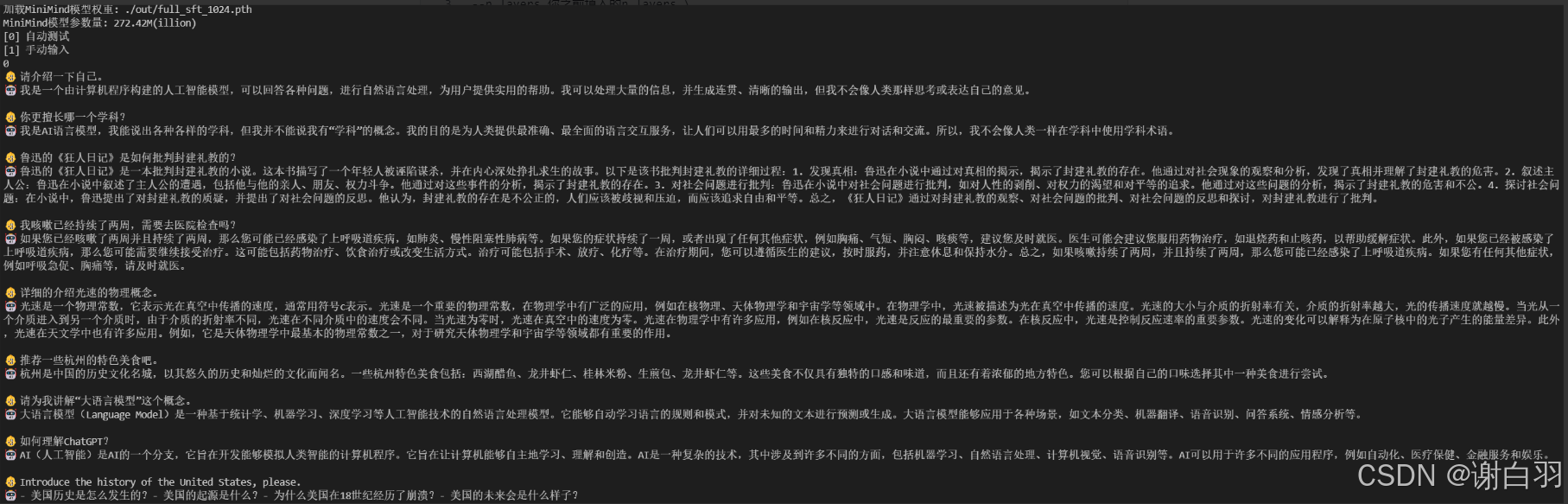
全部运行脚本示例可以参考README或者仓库下的中文版本.
二、从Tranformer和关键算子入手剖析大模型
2.1 Tranformer架构
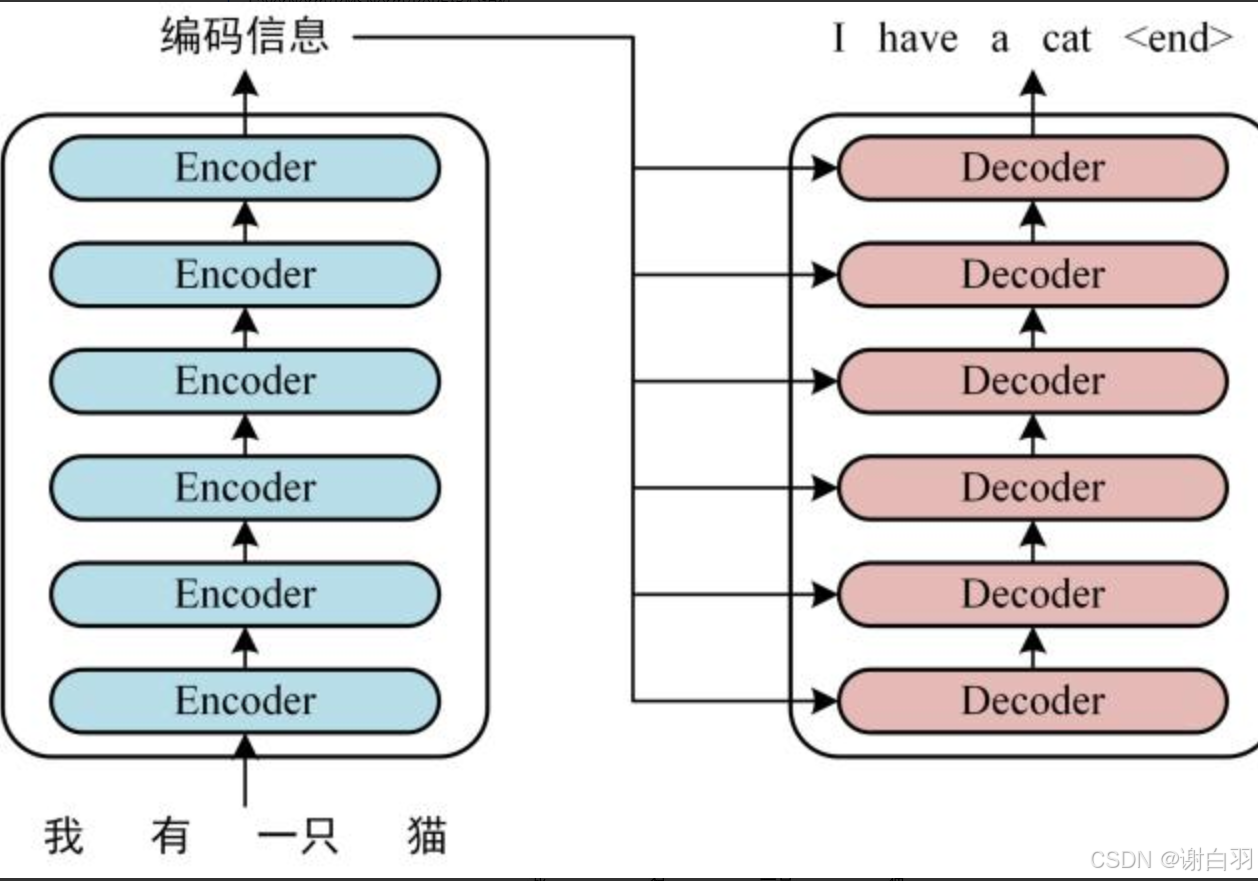
可以看到 Transformer 由 Encoder 和 Decoder 两个部分组成,Encoder 和 Decoder 都包含 6(可更改) 个 block。Transformer 的工作流程大体如下:
-
获取输入句子的每一个单词的表示向量 X,X由单词的 Embedding(Embedding就是从原始数据提取出来的Feature) 和单词位置的 Embedding 相加得到。
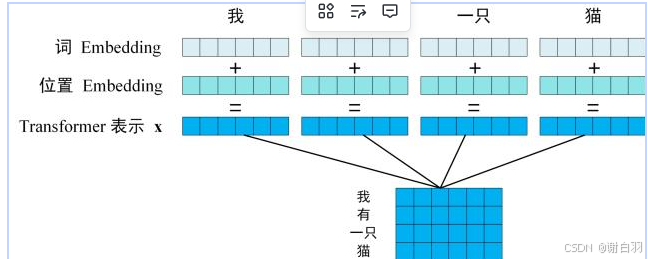
-
将得到的单词表示向量矩阵 (如上图所示,每一行是一个单词的表示 x) 传入 Encoder 中,经过 6 个 Encoder block 后可以得到句子所有单词的编码信息矩阵 C,如下图。单词向量矩阵用 X n , d X_{n,d} Xn,d表示, n 是句子中单词个数,d 是表示向量的维度 (论文中 d=512)。每一个 Encoder block 输出的矩阵维度与输入完全一致。
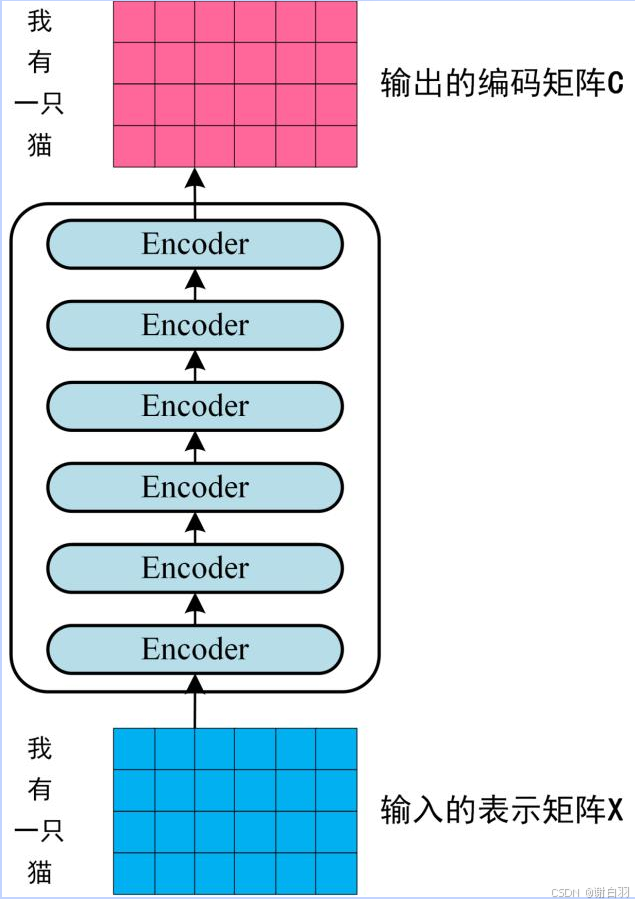
- 将 Encoder 输出的编码信息矩阵 C传递到 Decoder 中,Decoder 依次会根据当前翻译过的单词 1~ i 翻译下一个单词 i+1,如下图所示。在使用的过程中,翻译到单词 i+1 的时候需要通过 Mask (掩盖) 操作遮盖住 i+1 之后的单词。下图 Decoder 接收了 Encoder 的编码矩阵 C,然后首先输入一个翻译开始符 “”,预测第一个单词 “I”;然后输入翻译开始符 “” 和单词 “I”,预测单词 “have”,以此类推。这是 Transformer 使用时候的大致流程,接下来是里面各个部分的细节。

Overview:这是transformer架构的整体概览, 我们会依据下图详细讲解各个组件
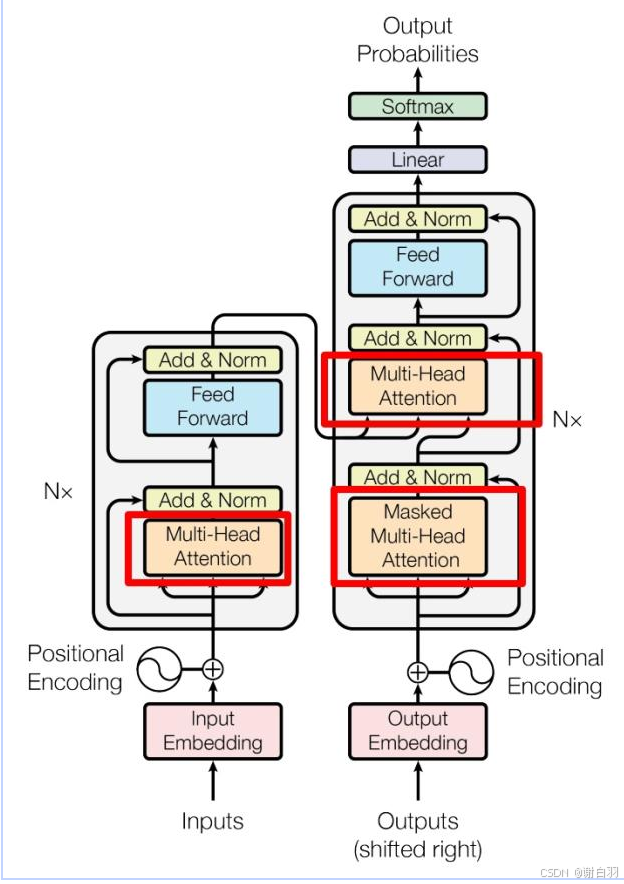
2.1.1 Attention架构(Query 代表“我需要什么样的信息”,而 Key 则代表“我拥有的信息”)
- 输入: embedding X
- 权重: W_Q, W_K, W_V
- 输出: Attention计算结果
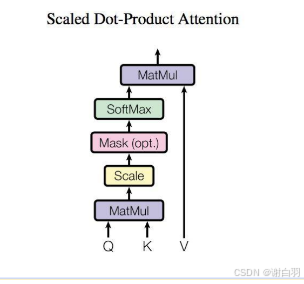
如上图, 计算过程会由Matmul, Scale, Mask, Softmax构成
Q = X × W Q , K = X × W K , V = X × W V Q=X\times W_Q, K=X\times W_K, V=X\times W_V Q=X×WQ,K=X×WK,V=X×WV
att ( X ) = attention ( Q , K , V ) = softmax ( Q K T d k ) ⋅ V \text{att}(X)=\text{attention}(Q,K,V)=\text{softmax}(\frac{QK^T}{\sqrt{d_k}})\cdot V att(X)=attention(Q,K,V)=softmax(dkQKT)⋅V
在 Attention 机制中,核心由三个向量组成:Query、Key 和 Value。
- Query:表示当前需要寻找的信息;
- Key:表示序列中每个位置所包含的信息;
- Value:与 Key 对应,用于被加权聚合的值。
在序列中,某个位置的 Query 向量会与所有 Key 进行点积MatMul,计算它们的相关性得分(权重)Scale,
从而确定该位置应当关注哪些 token。
权重越大,表示该位置从对应的 Key 处获取的信息越多;权重越小,表示关注度较低。
举个例子:
假设当前第 N N N 个 token 已经过词向量和位置向量的编码,它知道“我是谁”和“我在哪里”。
此时生成的 Query 代表“我需要什么样的信息”,
而 Key 则代表“我拥有的信息”。
当二者在嵌入空间中进行点积时,若二者的语义相关性高,对应位置的注意力得分就会更大。
最终,模型会聚合与当前 Query 相关性高的 Value 信息,从而学习到更多上下文特征。
换句话说,Attention 的输出可以看作是:
Attention ( Q , K , V ) = softmax ( Q K ⊤ d k ) V \text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQK⊤)V
理解了上面所说的公式,其实很多人会有一个问题:为什么在里面看似无用的“除以 d k \sqrt{d_k} dk反而要成为公式的一部分?
事实上,在计算注意力权重时,需要对点积结果进行缩放(Scaling)以保持数值稳定:
Scaled Attention = Q K ⊤ d k \text{Scaled Attention} = \frac{QK^\top}{\sqrt{d_k}} Scaled Attention=dkQK⊤
其中, d k d_k dk 表示 Key 向量的维度。
当 d k d_k dk 较大时,Query 与 Key 的点积值的方差也会变大,导致部分注意力得分过大。
此时 softmax 的输出会非常偏向某个位置(接近 one-hot),其他位置的权重几乎为零。
这种极端分布会造成梯度极小,模型在训练初期几乎无法学习。
通过除以 d k \sqrt{d_k} dk,可以将输入值缩放到更平稳的范围,
防止 softmax 输出过于极端,从而保持梯度大小适中,提高训练稳定性。
在模型训练初期,若梯度过小,模型无法有效更新参数,学习速度变慢;
而在模型接近收敛时,较小的梯度则有助于稳定优化,防止震荡与过拟合。
缩放操作使得注意力分布在初始阶段更加平滑,模型能够逐渐学习到正确的注意模式。
2.1.2 Multi-head Attention 架构
- 输入: embedding X
- 权重: { W Q i , W K i , W V i } i = 1 h \{W_Q^i, W_K^i, W_V^i\}_{i=1}^h {WQi,WKi,WVi}i=1h,其中 h h h 是 head 的个数
- 输出: 多个 head 的结果拼接后,再经过线性变换 W O W_O WO 得到最终输出
如图所示,Multi-head Attention 本质上就是并行计算多个 独立的 attention,每个 head 有自己的一组参数,把同一个输入投影到不同的子空间,然后各自计算 attention,最后把结果拼接起来。
具体计算过程:
线性变换: Q i = X W Q i , K i = X W K i , V i = X W V i ( i = 1 , 2 , … , h ) Qi=XW_Q^i,Ki=XW_K^i,Vi=XW_V^i(i=1,2,…,h) Qi=XWQi,Ki=XWKi,Vi=XWVi(i=1,2,…,h)
单头注意力: head i = softmax ( Q i K i T d k ) V i \text{head}_i = \text{softmax}\left(\frac{Q_i K_i^T}{\sqrt{d_k}}\right)V_i headi=softmax(dkQiKiT)Vi
拼接: H = [ head 1 , head 2 , … , head h ] H = [\text{head}_1, \text{head}_2, \dots, \text{head}_h] H=[head1,head2,…,headh]
线性映射: MHA ( X ) = H W O \text{MHA}(X) = H W_O MHA(X)=HWO
2.2 LayerNorm/RMSNorm/RoPE核心组件
Layer Normalization (LayerNorm)
- 输入: 向量 x = ( x 1 , x 2 , … , x d ) x = (x_1, x_2, \dots, x_d) x=(x1,x2,…,xd)
- 权重: 可学习参数 γ , β ∈ R d \gamma, \beta \in \mathbb{R}^d γ,β∈Rd
- 输出: 归一化后的向量
计算过程:
- 计算均值与方差:
μ = 1 d ∑ i = 1 d x i σ 2 = 1 d ∑ i = 1 d ( x i − μ ) 2 \mu = \frac{1}{d}\sum_{i=1}^d x_i\quad \sigma^2 = \frac{1}{d}\sum_{i=1}^d (x_i - \mu)^2 μ=d1∑i=1dxiσ2=d1∑i=1d(xi−μ)2 - 归一化:
x ^ i = x i − μ σ 2 + ϵ \hat{x}_i= \frac{x_i - \mu}{\sqrt{\sigma^2 + \epsilon}} x^i=σ2+ϵxi−μ - 线性缩放和平移:
y i = γ x ^ i + β y_i = \gamma \hat{x}_i + \beta yi=γx^i+β
直观理解:LayerNorm 保持每个 token 的整体分布稳定,避免梯度爆炸或消失。
Root Mean Square Normalization (RMSNorm)
- 输入: 向量 x = ( x 1 , x 2 , … , x d ) x = (x_1, x_2, \dots, x_d) x=(x1,x2,…,xd)
- 权重: 可学习参数 γ ∈ R d \gamma \in \mathbb{R}^d γ∈Rd
- 输出: 归一化后的向量
计算过程:
- 计算均方根 (RMS):
RMS ( x ) = 1 d ∑ i = 1 d x i 2 \text{RMS}(x) = \sqrt{\frac{1}{d} \sum_{i=1}^d x_i^2} RMS(x)=d1∑i=1dxi2 - 归一化:
x ^ = x RMS ( x ) + ϵ \hat{x} = \frac{x}{\text{RMS}(x) + \epsilon} x^=RMS(x)+ϵx - 线性缩放:
y = γ ⋅ x ^ y = \gamma \cdot \hat{x} y=γ⋅x^
直观理解:RMSNorm 不减去均值,只利用向量长度做归一化,更简洁,计算效率更高,在大模型中表现良好。
在Attention架构中, 假设当前序列长度为 L L L, batch size为 B B B, embedding维度为 d d d,
则输入 i n p u t ∈ R d input\in\mathbb{R}^d input∈Rd, LayerNorm/RMSNorm会对序列内部 L L L个embedding, 每个embedding独立使用LayerNorm/RMSNorm, 用来确保每个词的embedding"只有分布上的区别, 没有大小上的不同"
Positional Embedding
为什么需要位置编码?
RNN 天生具备时序结构,能够隐式捕捉输入序列的顺序信息;
但 Transformer 完全基于自注意力机制(Self-Attention),其计算是无序且并行的。
这导致模型本身无法区分词序,例如:
- 他欠我100万” 与 “我欠他100万” 语义截然不同;
- 但 Transformer 若没有额外位置信息,将难以区分。
因此,Transformer 作者提出了一种巧妙的方式——位置编码(Positional Encoding),
用于在模型中注入序列的顺序信息。
位置编码的作用与要求
Attention 的计算本质上是无向的,而自然语言中词语之间的相对与绝对位置信息至关重要。
理想的位置信息应能满足以下条件:
- 能明确表示每个 token 在序列中的绝对位置;
- 保证不同序列长度下,相对位置关系保持一致;
- 能推广到训练中未出现过的更长序列(外推性);
- 表达函数连续且有界。
正弦函数 ( sin \texttt{sin} sin) 具有周期性和平滑性,满足这些条件,因此 Transformer 使用正弦-余弦函数来表示位置。
正弦-余弦位置编码公式
绝对位置编码定义如下:
P E t = [ sin ( w 0 t ) , cos ( w 0 t ) , sin ( w 1 t ) , cos ( w 1 t ) , … , sin ( w d model / 2 − 1 t ) , cos ( w d model / 2 − 1 t ) ] PE_t = [\sin(w_0 t), \cos(w_0 t), \sin(w_1 t), \cos(w_1 t), \dots, \sin(w_{d_{\text{model}}/2 - 1} t), \cos(w_{d_{\text{model}}/2 - 1} t)] PEt=[sin(w0t),cos(w0t),sin(w1t),cos(w1t),…,sin(wdmodel/2−1t),cos(wdmodel/2−1t)]$
其中:
w i = 10000 − 2 i / d model w_i = 10000^{-2i / d_{\text{model}}} wi=10000−2i/dmodel
d model d_{\text{model}} dmodel 为模型隐藏维度, t t t 为 token 的位置。
每个维度对应不同频率的正弦/余弦函数,使得位置之间的距离能通过线性变化保持稳定。
此外,正弦位置编码具备如下性质:
因此,通过线性变换即可从某个位置的编码推导出相对位置的编码,表明该设计在理论上具有相对位置可推性。
下图展现了在长度为 100、编码维度为 512 的情况下, 位置编码的每个分量都位于区间 [ − 1 , 1 ] [-1, 1] [−1,1] 内。
随着维度增加,正弦波的频率逐渐降低,波长增大。 这使得低频部分(右侧)变化平缓,而高频部分(左侧)振荡密集。 因此,不同位置的编码在向量空间中高度区分,但仍保持连续
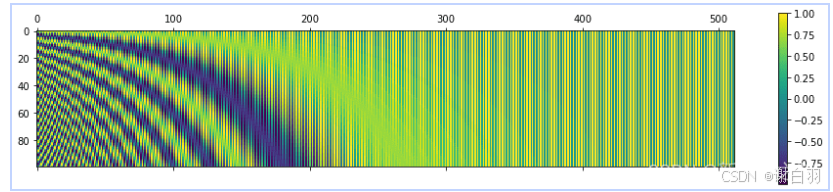
由于正弦编码是无向的,存在如下对称性:
P E t ⊤ P E t + Δ t = P E t ⊤ P E t − Δ t PE_t^\top PE_{t+\Delta t} = PE_t^\top PE_{t-\Delta t} PEt⊤PEt+Δt=PEt⊤PEt−Δt
即编码之间的点积只取决于距离 ∣ Δ t ∣ |\Delta t| ∣Δt∣,而无法体现方向(前后顺序)。
此外,当这些编码被线性投影到注意力空间后,可能导致相对位置信息被破坏,
从而影响模型区分前后顺序的能力。
2.3 Encoder, Decoder的构成
Encoder Layer的功能是将输入的QKV矩阵计算出来, 供后续生成取用, 所以它的本质结构为
Attention -> Norm&Add -> Feed Forward -> Norm&Add
这里提到的Norm&Add的意思是: 经过前面的操作后再加上残差连接, 也就意味着第一个Norm&Add结束时的输出为
y = N o r m ( A t t e n t i o n ( x ) ) + x y=Norm(Attention(x))+x y=Norm(Attention(x))+x
最终的输出为
z = N o r m ( F F N ( y ) ) + y z=Norm(FFN(y))+y z=Norm(FFN(y))+y
我们来看看encoder layer中的self-attention:
QKV来自同样的原始序列的, 只希望关注自己节点的互相交流的信息,查询、键和值都来自同一个输入序列。主要目的是捕捉输入序列内部的依赖关系。在Transformer的编码器(Encoder)和解码器(Decoder)的每一层都有自注意力,它允许输入序列的每个部分关注序列中的其他部分,区别在于:Encoder中的self-attention是当前位置的token与序列全部token计算,Decoder中的self-attention是当前位置的token只与在他之前的token计算(Masked Attention/Casual Attention),为了避免解码过程中的信息泄漏
Decoder Layer
与Encoder Layer的seflf attention不同的是,Decoder Layer的cross-attention的QKV来自不同的序列,有一些其他的节点,我们希望把他们的信息融合到自己的节点上。查询来自一个输入序列,而键和值来自另一个输入序列。
主要出现在Transformer的解码器。它允许解码器关注编码器的输出(也就是说,在生成的过程中不仅仅关注刚才已经生成的token,还要关注输入的Encode结果)。交叉注意力的思想是使一个序列能够“关注”另一个序列。在许多场景中,这可能很有用,例如在机器翻译中,将输入序列(源语言)的部分与输出序列(目标语言)的部分对齐是有益的
对于decoder来说,第一个attention模块是Masked Self-Attention,第二个则是 Cross-Attention模块
与Encoder Layer不同的是, Decoder需要处理输出, 也就是说, 当我们生成到第 t t t个词的时候, 我们还需要第 1 ⋯ t − 1 1\cdots t-1 1⋯t−1个词的信息
2.4 如何并行化地训练Transformer(略)
三、精度与并行策略
- 主要内容
- 数据精度BF16/FP16/FP8/INT8
- Data Parallel (DP) / Model Parallel (MP)/ Pipeline Parallel (PP)概览
- 激活检查点与显存优化
3.1 数据精度详解
在计算机中所有的数据都按照符号位+指数位+尾数位存储, 所占用的bit数以及能表示的范围, 精度都有所不同, 下面我们首先列出一个表来对比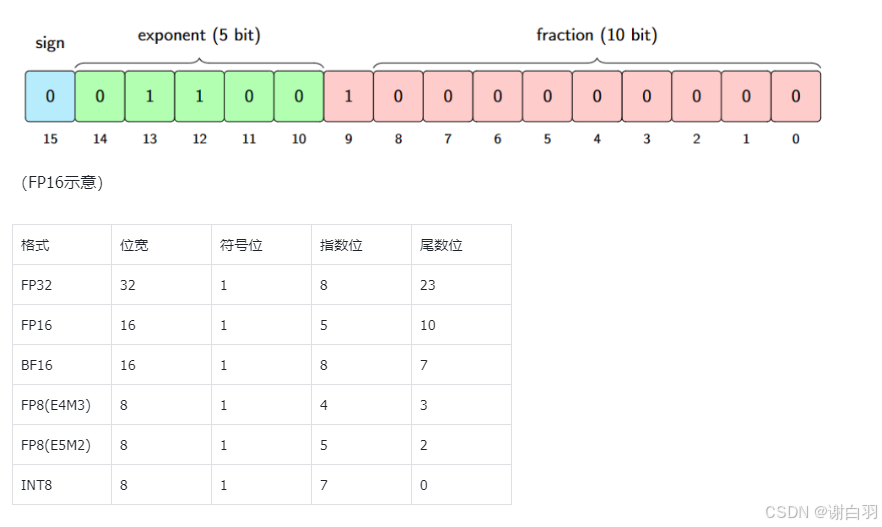
3.2 为什么要考虑精度与并行?
Transformer 模型的规模在迅速增长,从亿级到千亿级参数。训练过程中,显存瓶颈 和 计算效率 成为主要挑战。
- 精度(Precision):决定了浮点数存储和计算的位宽。精度越低,占用显存越少、运算越快,但数值稳定性更差。
- 并行策略(Parallelism):决定了如何把巨大的计算任务分布到多张 GPU 上。
FP32 (单精度浮点数) - 占用 32bit,训练最稳定。
- 缺点:显存占用大、速度慢。现代大模型训练几乎不直接使用。
FP16 (半精度浮点数)
- 占用 16bit,吞吐量提升 2 倍。
- 缺点:数值范围有限,容易溢出或下溢。
- 解决方案:混合精度训练(AMP) —— 关键梯度仍用 FP32 存储,避免溢出。
BF16 (bfloat16)
- 与 FP16 相比:精度更低,但 指数位更宽,动态范围接近 FP32。
- 优点:计算效率高,稳定性比 FP16 好,H100/A100 原生支持。
- 缺点:某些老显卡(如 V100)不支持。
FP8 (8bit浮点)
- 最新的研究方向,NVIDIA Hopper H100 提供支持。
- 优点:存储和计算量进一步降低一半。
- 缺点:稳定性差,需要逐层缩放因子(per-tensor scaling)和校准。
- 应用:常用于 推理 或训练中部分模块(如激活/梯度)。
小结:
- 研究型训练:推荐 BF16。
- 节省显存:可以尝试 FP8 混合方案。
- 小模型/实验:FP16 + AMP 足够。
3.3 不同精度之间如何进行混合计算?
前向传播 (Forward)
- 模型权重 (weights):存两份 → 一份 FP32(主副本,用来更新),一份 FP16/BF16(计算用)。
- 激活 (activations):用 FP16/BF16 存储和计算。
- 矩阵乘/卷积:直接用低精度 Tensor Cores 加速。
反向传播 (Backward)
- 梯度计算:用 FP16/BF16 计算(省显存)。
- 梯度累加 (Gradient Accumulation):再转换为 FP32 存储,保证数值稳定。
- Loss Scaling:在 FP16 时,需要把 loss 乘上一个缩放因子,避免梯度下溢。
参数更新 (Optimizer Step)
- 优化器(如 Adam)内部用 FP32 主权重 和 FP32 动量/二阶矩 进行更新。
- 更新完成后,把 FP32 权重 cast 回 FP16/BF16,作为下一步前向计算的副本。
例子:
在BF16的矩阵乘法中, 由于BF16和FP32指数位一样多, 常常会将BF16的数据先转为FP32的数据类型, 经过乘法后再转回, 这样可以提高计算精度
这里是我们的测试代码, 用不同的精度相乘和原结果比较
# 参考:FP32 直接相乘
AB_fp32 = A @ B # [m, n], float32
# 路线1:先降精度到 BF16 再相乘;结果再升回 FP32 便于比较
A_bf16 = A.to(torch.bfloat16)
B_bf16 = B.to(torch.bfloat16)
R1 = (A_bf16 @ B_bf16).to(torch.float32)
# 路线2:先在 FP32 中相乘,再整体降为 BF16;结果同样升回 FP32 用于比较
R2 = AB_fp32.to(torch.bfloat16).to(torch.float32)
# 路线3:先将输入量化为 BF16,再显式用 FP32 做乘法,然后整体降到 BF16;最后升回 FP32 用于比较
R3 = (A_bf16.to(torch.float32) @ B_bf16.to(torch.float32)).to(torch.bfloat16).to(torch.float32)
运行代码后可以直接得到打印的输出代码地址
下面的输出对比了是否使用cuda, 在不支持Tensorcore和BF16的cpu上效果将非常不明显, 这是由于cuda会将输入自动转为FP32格式, 在FP32下累加, 所以会高度一致; 然而cpu则会直接在BF16的格式中累加, 会有明显误差.
=== BF16 MatMul Precision Demo ===
device : cuda
shapes : A=(256,256), B=(256,256)
dtypes : A=torch.float32, B=torch.float32, A_bf16=torch.bfloat16, B_bf16=torch.bfloat16
Compute paths :
R1 = BF16(A) @ BF16(B) -> FP32
R2 = FP32(A@B) -> BF16 -> FP32
R3 = FP32(BF16(A)) @ FP32(BF16(B)) -> BF16 -> FP32
max |R1-R2| : 2.500000e-01
mean |R1-R2| : 3.013588e-02
eq% |R1-R2| : 48.88% (percentage of exactly equal elements)
exact equal : False
-
max |R1-R3| : 1.250000e-01
mean |R1-R3| : 6.766175e-06
eq% |R1-R3| : 99.98%
exact equal : False
解读:R1 与 R2 的差异来自“输入量化 vs 输出量化”的不同位置;
若底层采用 'BF16 输入 -> FP32 累加 -> BF16 输出',则 R1 应与 R3 高度一致(许多 GPU/库上可逐元素相等)。
建议在支持 Tensor Core 的 GPU 上加上 --device cuda 观察 R1≈R3 的一致性更明显。
=== BF16 MatMul Precision Demo ===
device : cpu
shapes : A=(256,256), B=(256,256)
dtypes : A=torch.float32, B=torch.float32, A_bf16=torch.bfloat16, B_bf16=torch.bfloat16
Compute paths :
R1 = BF16(A) @ BF16(B) -> FP32
R2 = FP32(A@B) -> BF16 -> FP32
R3 = FP32(BF16(A)) @ FP32(BF16(B)) -> BF16 -> FP32
max |R1-R2| : 2.500000e-01
mean |R1-R2| : 3.004722e-02
eq% |R1-R2| : 49.03% (percentage of exactly equal elements)
exact equal : False
-
max |R1-R3| : 3.906250e-03
mean |R1-R3| : 6.053597e-08
eq% |R1-R3| : 100.00%
exact equal : False
解读:R1 与 R2 的差异来自“输入量化 vs 输出量化”的不同位置;
若底层采用 'BF16 输入 -> FP32 累加 -> BF16 输出',则 R1 应与 R3 高度一致(许多 GPU/库上可逐元素相等)。
建议在支持 Tensor Core 的 GPU 上加上 --device cuda 观察 R1≈R3 的一致性更明显。
总结:这个实验证明了现代GPU(尤其是支持Tensor Core的)在执行BF16运算时,会智能地使用FP32进行中间累加,这是为什么BF16训练能够接近FP32精度的重要原因之一。这也是 BF16 相比 FP16 的一个优势——指数位宽度相同使得转换更安全
3.4 并行策略概览
当单卡无法容纳模型和批量数据时,需要多卡并行。
Data Parallel (数据并行)
- 每张 GPU 保存一份完整模型,处理不同 mini-batch。
- 每个 step 后,通过 All-Reduce 同步梯度。
- 优点:实现简单,扩展性好。
- 缺点:显存占用高,每张卡都要存模型。
Tensor Parallel (张量并行)
- 将单层的参数(如 QKV 矩阵)切分到多张 GPU 上。
- 每张 GPU 只存一部分参数,并在前向/反向时通信拼接结果。
- 优点:能支持极大模型。
- 缺点:通信开销大,依赖高速互联(NVLink/NVSwitch)。
Pipeline Parallel (流水线并行)
- 把不同层分到不同 GPU 上,前向传播像流水线一样依次传递。
- 可以叠加 micro-batch,实现并行。
- 优点:内存压力小,适合深模型。
- 缺点:存在“pipeline bubble”(流水线空转)
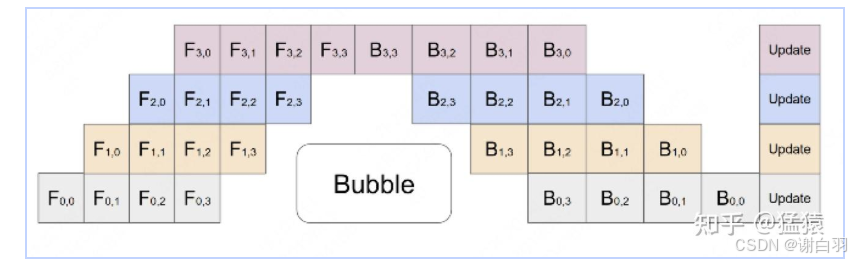
混合并行
实际大模型训练往往结合:
- DP + TP + PP
- 再加上 ZeRO 优化(分布式优化器状态分片)。
例如:GPT-3 175B 的训练采用 3D 并行。
在普通的 Data Parallel (DP) 里,每张 GPU 都会保存 完整的模型参数、副本梯度、完整优化器状态。这样就造成大量冗余内存浪费.
ZeRO的思想:
“分片(Shard)”:把参数、梯度、优化器状态在多张 GPU 之间切分存储,而不是每张卡都存完整一份。
每次训练需要时再通过 通信 (All-Gather/Reduce-Scatter) 来取回或聚合。
ZeRO 按分片的对象分成三个阶段: - ZeRO-1 (优化器状态分片)
每张卡只保存一部分优化器状态。比如 4 张卡时,每卡保存 1/4 优化器状态。内存节省 ≈ 4 倍。 - ZeRO-2 (再加上梯度分片)
梯度也切分,反向传播时在不同 GPU 上存不同的梯度分片。内存再节省一部分。 - ZeRO-3 (连参数也分片)
每张卡只存部分模型参数。前向传播时需要时临时 All-Gather 参数,计算完再释放。内存节省最大,可以支持数千亿甚至万亿参数模型。
第九课–分布式预训练这里详细介绍了ZeRO以及其他具体的分布式训练策略, 在本讲不再赘述
- 激活检查点(Activation Checkpointing)
Transformer 的中间激活值(attention矩阵、FFN输出)占显存大头。
- 思路:不保存所有激活,而是只保留关键节点,反向传播时重新计算缺失的激活。
- 优点:显存节省可达 50%+。
- 缺点:增加一些额外计算开销。
- 常见工具:PyTorch torch.utils.checkpoint。
- 显存优化方法总结
- 混合精度训练(BF16/FP16/FP8):降低存储和计算开销。
- Gradient Checkpointing:牺牲算力换显存。
- ZeRO优化(DeepSpeed):优化器状态和梯度分片。
- 参数高效微调(LoRA/QLoRA):减少可训练参数。
LoRA简介: 在微调过程中, 我们希望使用很小的参数量对整个网络进行微调. 如果原先的神经网络为 W ∈ R m × n W\in\mathbb{R}^{m\times n} W∈Rm×n, 我们使用 W + A B W+AB W+AB微调; A ∈ R m × k , B ∈ R ∈ R k × n A\in\mathbb{R}^{m\times k}, B\in\mathbb{R}\in\mathbb{R}^{k\times n} A∈Rm×k,B∈R∈Rk×n, 其中 k k k被称作lora rank, 使用这样两个不大的矩阵即可完成微调(训练过程中 W W W的参数被冻结, 所以可训练的参数量仅有 m × k + k × n m\times k+k\times n m×k+k×n). 我们后面还会讲, 这里不详细说了
- 总结
- 精度选择:BF16 是当前大模型训练的主流,FP8 在新硬件上值得尝试。
- 并行策略:数据并行易扩展,模型并行适合超大模型,流水线并行解决深度问题。
- 显存优化:激活检查点和 ZeRO 是大规模训练必备。
四、现代大语言模型的分类,Scaling Laws, Distillation & Get Your Hands Dirty
- 本节主要内容:
- 大语言模型的分类
- Scaling Laws
- Distillation(蒸馏)
- 小模型训练启动!
4.1 大语言模型的分类
现代大语言模型(LLMs)大多基于 Transformer 架构,可根据信息流方向和任务目标分为三类:
- Encoder-only: 以理解为主(如 BERT)
- Decoder-only: 以生成为主(如 GPT、LLaMA)
- Encoder-Decoder: 同时具备理解与生成能力(如 T5、BART)
Encoder-Decoder 架构(Seq2Seq 模型)
Encoder-Decoder 结构由两部分组成:
Encoder 负责对输入文本进行双向编码,Decoder 负责自回归地生成输出文本。
y t = P ( y t ∣ y < t , Enc ( x ) ) y_t = P(y_t \mid y_{<t}, \text{Enc}(x)) yt=P(yt∣y<t,Enc(x))
即每一步输出不仅依赖于前面的 token,还依赖于 Encoder 提供的整段语义表示。
优势:
- 适用于输入和输出语义不同的任务(翻译、摘要、问答等)
- Encoder 提供双向上下文,理解能力强
代表模型: T5、BART、FLAN-T5。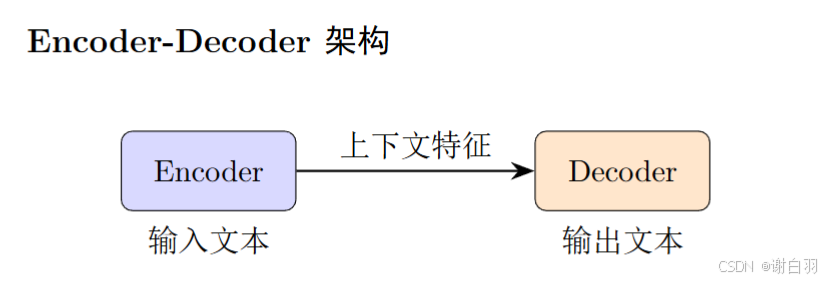
Decoder-only 架构(自回归语言模型)
Decoder-only 模型仅包含 Decoder,通过自回归(Autoregressive)方式逐步预测下一个 token:
P ( y ) = ∏ t = 1 T P ( y t ∣ y < t ) P(y) = \prod_{t=1}^{T} P(y_t \mid y_{<t}) P(y)=∏t=1TP(yt∣y<t)
每个时刻的注意力只关注前文(使用Causal Mask,后面会详细讲什么是Causal Mask)。
优势:
- 结构简单、推理速度快;
- 适合生成任务(对话、补全、代码生成);
- 支持 In-context Learning。
代表模型:GPT 系列、LLaMA、Mistral、Falcon。
Encoder-only 架构(双向语言模型)
Encoder-only 模型只保留 Encoder 部分,采用双向注意力机制,对输入序列进行全局理解。
Loss = − ∑ i ∈ M log P ( x i ∣ x ∖ M ) \text{Loss} = - \sum_{i \in M} \log P(x_i \mid x_{\setminus M}) Loss=−i∈M∑logP(xi∣x∖M)
其中 M M M 表示被 Mask 的 token 集合。
优势: - 能充分利用上下文语义;
- 适合分类、匹配、检索等理解类任务;
代表模型: BERT、RoBERTa、DeBERTa。
注意:这类模型无法生成(因为只有双向注意力机制,必须后续拼接Decoder才可以进行生成)
为什么现在能用的两类大语言模型中(Encoder-Decoder与Decoder-only),效果更好的往往是Decoder-only呢?
1. 训练效率与规模优势 ⭐(最关键)
Decoder-only 更适合大规模训练:
统一的自回归目标:所有 token 都用于训练,没有"浪费"
参数利用率高:Encoder-Decoder 需要分别维护两套参数,而 Decoder-only 所有层都服务于同一个目标
更容易扩展:在相同参数量下,Decoder-only 的深度可以更深
Encoder-Decoder: 参数 = Encoder层 + Decoder层 + Cross-AttentionDecoder-only: 参数 = Decoder层(更深、更宽)
2. 因果注意力的天然优势
Decoder-only 的因果掩码(Causal Mask):
强制模型学习单向依赖关系,更符合生成任务
避免"未来信息泄漏",训练和推理完全一致
在预训练阶段,每个 token 都是一个训练样本(teacher forcing)
# Decoder-only 的注意力模式# 每个 token 只能看到之前的 token[1, 0, 0, 0] # token 1 只看自己[1, 1, 0, 0] # token 2 看 1,2[1, 1, 1, 0] # token 3 看 1,2,3[1, 1, 1, 1] # token 4 看全部
3. 预训练与微调的一致性
Decoder-only:
预训练:next token prediction
微调/推理:next token prediction
完全一致! ✅
Encoder-Decoder:
预训练:masked language modeling / span corruption
微调/推理:seq2seq generation
存在 gap ⚠️
4. In-Context Learning (ICL) 能力
Decoder-only 模型展现出强大的上下文学习能力:
Few-shot learning:通过前文示例直接学习
指令遵循:更好地理解任务意图
这种能力在 Encoder-Decoder 中相对较弱
4.2 Scaling Law
Scaling Laws 描述了大模型性能随模型规模、数据量、计算量的增长规律。核心思想:更大规模的模型 → 更好的性能 → 但也有收益递减。
- 模型参数规模 N(parameters)
- 训练数据规模 D(tokens)
- 训练计算量 C(FLOPs)
在 Kaplan et al. (OpenAI, 2020) 的经典工作中,困惑度 (perplexity) 与 (N, D, C) 呈现 幂律规律:
L ( N , D , C ) ≈ a N − α + b D − β + c C − γ L(N, D, C) \approx aN^{-\alpha} + bD^{-\beta} + cC^{-\gamma} L(N,D,C)≈aN−α+bD−β+cC−γ
直观理解
- 小模型阶段:增加数据更有用(模型还没学够)。
- 大模型阶段:参数和算力决定上限。
- 过度训练:当模型固定,继续加数据 → 过拟合或收益递减。
工程应用
- 预估训练资源:给定算力预算,可以预测最佳模型大小。
- 指导训练策略:决定是“扩参数”还是“扩数据”。
- 例子:Chinchilla (DeepMind, 2022) 发现 GPT-3 训练 数据量不足,重新平衡后(更小模型 + 更多数据)得到更优性能。
我们可以粗略认为: 在现阶段, 同等架构的模型, 越大的参数量以及越多的数据量训练出来的模型拥有越好的效果; 同时, 在算力一定的情况下, 平衡好数据量以及训练量可以得到更好的效果
论文链接
实情分析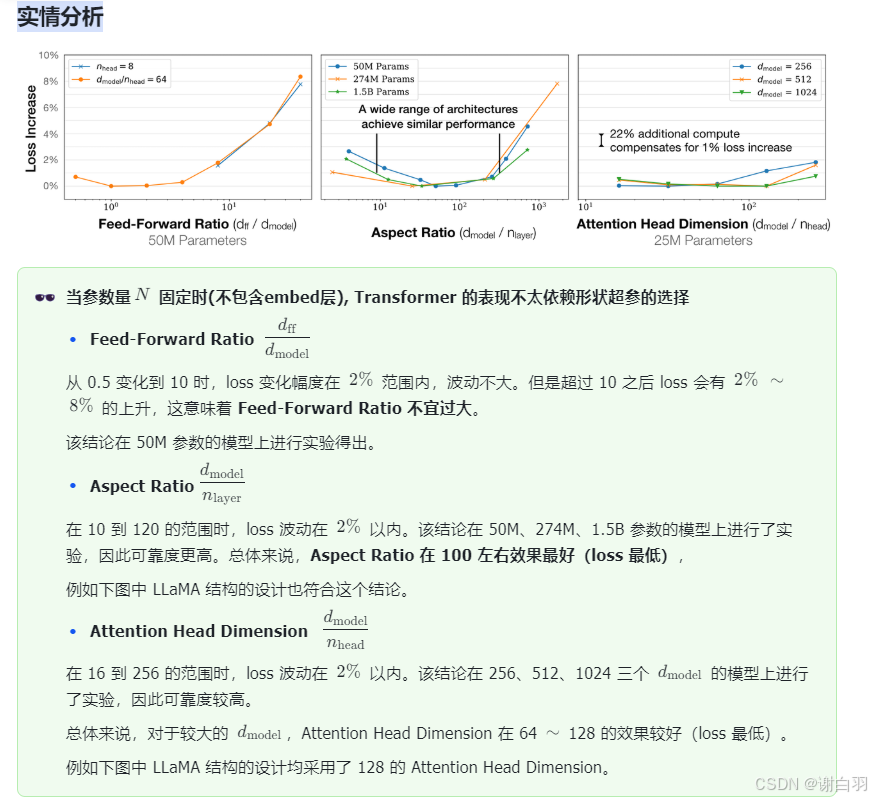
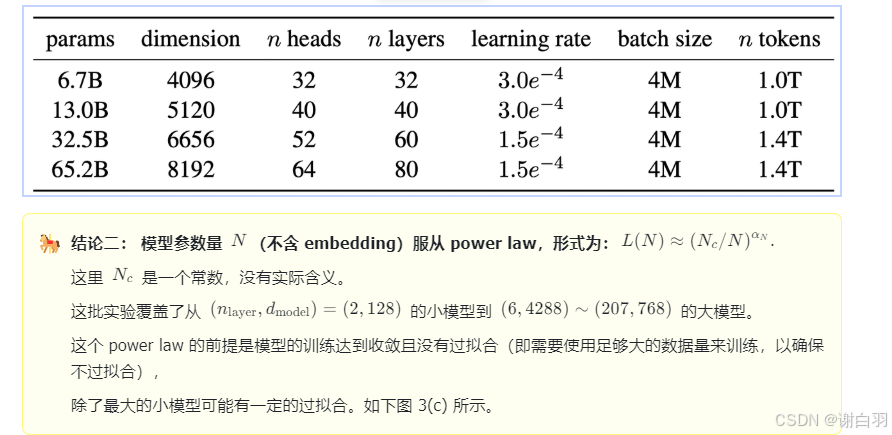

图 4 说明了在计算参数量时包含 embedding 会导致小参数模型拟合 power law 的效果变差。
因此我们在计算参数量时应该排除 embedding 的参数量。
图 5 的左图说明了不同数据集拟合的参数 N N N 的 power law 曲线接近,
这意味着 power law 有一定的泛化能力。
图 5 右图的比较表明在 WebText2 上训练,一个大模型(虚线)和一群收敛的小模型(点)的 test loss
和泛化到其他数据集的 loss 关系,也服从 power law(能拟合成直线)。
另外,点几乎都落在对应的虚线上,表示 test loss 直接能表现模型的泛化能力。
这与模型是否收敛无关。
此外,在论文的 3.2.1 节实验中也验证了 Transformer 结构优于 LSTM。
后者不具备良好的 power law 拟合性质,且在 token 序列内位置 100 以后得预测效果不佳。
此处不再赘述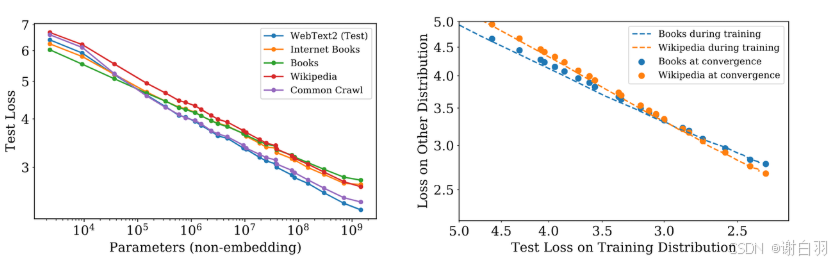
4.3 Distillation(蒸馏)
为什么需要蒸馏?
- 大模型效果好,但部署成本高(显存、延迟)。
- 很多情况下不需要如此效果强大的base model作为下游任务的部署基准
- 蒸馏:用大模型(teacher)指导小模型(student)学习,以更小代价复现性能。
Notation: 在蒸馏的时候, 我们有一个已经训练好的大模型(下称作teacher), 以及一个尚未训练的小模型(student), 使用大模型教小模型的学习方式(teacher-force)
- 蒸馏的几种方式
- Logit Distillation
- 学生模型拟合老师的 softmax 输出(soft targets)。
- Loss = C E ( s o f t _ t a r g e t _ t e a c h e r ∣ ∣ s t u d e n t _ o u t p u t ) CE(soft\_target\_teacher || student\_output) CE(soft_target_teacher∣∣student_output)。这里soft_target_teacher指的是教师模型在当前token处预测的概率分布, 也就是说我们希望学生预测的概率分布和教师尽可能接近!(CE表示cross entropy, 公式为 C E ( p , q ) = − ∫ x p ( x ) log q ( x ) d x CE(p,q)=-\int_x p(x)\log q(x)dx CE(p,q)=−∫xp(x)logq(x)dx
- 在第二节课我们讲过, transformer的decoder头会输出一个logits, softmax后输出给定前文情况下当前词汇的条件概率分布 P ( x t ∣ x 0 , ⋯ , x t − 1 ) P(x_t|x_0,\cdots,x_{t-1}) P(xt∣x0,⋯,xt−1), 我们希望小模型的logits以及条件概率分布贴近大模型, 以达到相似的性能.
- 在实践过程中, 可以人为输入不同的prompt, 使用上面提到的KL散度作为loss
Recall: 数学公式 K L ( p ∥ q ) = ∫ x p ( x ) log p ( x ) q ( x ) d x = ∫ x p ( x ) log p ( x ) d x − ∫ x p ( x ) log q ( x ) d x = E ( p ) + C E ( p , q ) KL(p\| q)=\int_x p(x)\log\frac {p(x)} {q(x)}dx=\int_x p(x)\log p(x)dx-\int_x p(x)\log q(x)dx=E(p)+CE(p,q) KL(p∥q)=∫xp(x)logq(x)p(x)dx=∫xp(x)logp(x)dx−∫xp(x)logq(x)dx=E(p)+CE(p,q), 形容了两个概率分布 p ( x ) p(x) p(x)和 q ( x ) q(x) q(x)之间"是否接近"(可以看到,当 p = q p=q p=q的时候 K L ( p ∥ q ) = 0 KL(p\|q)=0 KL(p∥q)=0,事实上这也是KL散度的最小值:0)
代码对应
教师/学生 logits 对齐词表并摊平(只在有效 token 处做 KL):
v = min(student_logits.size(-1), teacher_logits.size(-1))
st_flat = student_logits[..., :v].contiguous().view(-1, v)
te_flat = teacher_logits[..., :v].contiguous().view(-1, v)
m = (loss_mask_flat == 1) # 只在有效 token 位置计入 KD
- Feature Distillation
主体思想是学生对齐教师中间层的表示, 意味着我们不仅关心老师的最终预测结果,还希望学生在中间层特征表示(hidden states)上尽量接近老师。
设教师模型中某层输出为 h T ∈ R d h_T \in \mathbb{R}^d hT∈Rd,学生对应层输出为 h S ∈ R d h_S \in \mathbb{R}^d hS∈Rd,常用的蒸馏损失是:
L feature = ∥ h T − h S ∥ 2 2 \mathcal{L}_{\text{feature}} = \| h_T - h_S \|_2^2 Lfeature=∥hT−hS∥22
或者用 余弦相似度:
$ \mathcal{L}_{\text{feature}} = 1 - \cos(h_T, h_S)$
意味着我们希望学生和老师的中间层结果尽量对齐
优点
- 学生可以更好地“复现”老师的表征空间。
- 在小模型训练时,能更快收敛。
缺点 - 要访问教师模型的中间层 → 训练时开销大。
- 教师和学生结构差异大时(比如层数不同),需要对齐层次(常用 mapping 方法)。
代码对应
选择要对齐的层,并用钩子收集中间特征:
layers = select_feat_layers(
len_layers=len(getattr(model.module if isinstance(model, torch.nn.parallel.DistributedDataParallel) else model, 'layers')),
k=args.feature_layers
)
stu_fc = FeatureCollector(model, layers)
tea_fc = FeatureCollector(teacher_model if teacher_model is not None else model, layers)
with torch.no_grad():
_ = (teacher_model(X) if teacher_model is not None else model(X)) # 触发 teacher 中间层
_ = model(X) # 触发 student 中间层(学生需参与梯度)
分层计算 MSE,并用 loss_mask 只在有效 token 上做均值:
feat_loss = 0.0
for li in layers:
s = stu_fc.outputs[li] # 学生 h_S: [B, T, D_s]
t = tea_fc.outputs[li] # 教师 h_T: [B, T, D_t]
if s.size(-1) != t.size(-1):
t = feature_project(t, t.size(-1), s.size(-1)) # 维度不一致时的线性投影
feat_loss = feat_loss + masked_mean(F.mse_loss(s, t, reduction='none'), loss_mask)
distill_loss = feat_loss / max(1, len(layers))
这里 s , t s,t s,t 就是 h S , h T h_S,h_T hS,hT;masked_mean(…, loss_mask) 对应“只在有效 token 上取平均”。
3. Response-based Distillation(基于输出的蒸馏)
只看老师的最终预测 – 也就是前面说的输出概率分布(soft labels),让学生拟合老师的输出分布。
设教师输出分布为:
p T ( y ∣ x ) = softmax ( z T T ) p_T(y|x) = \text{softmax}\Big(\frac{z_T}{T}\Big) pT(y∣x)=softmax(TzT)
学生输出分布为:
p S ( y ∣ x ) = softmax ( z S T ) p_S(y|x) = \text{softmax}\Big(\frac{z_S}{T}\Big) pS(y∣x)=softmax(TzS)
其中 T T T 是 temperature(温度系数,平滑概率分布)。
损失函数:
L KD = D K L ( p T ( y ∣ x ) ∥ p S ( y ∣ x ) ) \mathcal{L}_{\text{KD}} = D_{KL}\big(p_T(y|x) \parallel p_S(y|x)\big) LKD=DKL(pT(y∣x)∥pS(y∣x))
最终训练损失 = 蒸馏损失 + 原始任务损失(如交叉熵):
L = α ⋅ L task + ( 1 − α ) ⋅ T 2 L KD \mathcal{L} = \alpha \cdot \mathcal{L}_{\text{task}} + (1-\alpha)\cdot T^2 \mathcal{L}_{\text{KD}} L=α⋅Ltask+(1−α)⋅T2LKD
优点
- 简单直观,计算高效。
- 可以直接利用 teacher 生成的数据(半监督)。
缺点
- 只利用最终输出,忽略了 teacher 的中间知识。
- 学生结构过小,可能学不全。
市面上现在很多的语音小助手就是使用多模态大模型进行如此蒸馏的(比较简单)
代码实现:
distill_loss = kl_logit_distill(st_flat[m], te_flat[m], temperature=temperature)
关于 T 2 T^2 T2:如果 kl_logit_distill 没有在内部乘 T 2 T^2 T2,请在外层补上:
if mode == 'logit' and teacher_logits is not None:
...
distill_loss = kl_logit_distill(st_flat[m], te_flat[m], temperature=temperature)
distill_loss = distill_loss * (temperature ** 2) # 与公式一致
- Self-distillation
模型本身在不同阶段互为 teacher/student:
- 训练后期的模型(teacher)指导训练初期的版本(student)。
- 或者模型的深层指导浅层。
设深层第 l l l 层输出为 h T l h_T^l hTl,浅层第 k k k 层输出为 h S k h_S^k hSk:
L self = ∥ h T l − h S k ∥ 2 2 \mathcal{L}_{\text{self}} = \| h_T^l - h_S^k \|_2^2 Lself=∥hTl−hSk∥22
或者在输出分布层面:
L self = D K L ( p deep ∥ p shallow ) \mathcal{L}_{\text{self}} = D_{KL}(p_{\text{deep}} \parallel p_{\text{shallow}}) Lself=DKL(pdeep∥pshallow)
什么需要这种蒸馏?
在很多现在的大预言模型中, 为了节省服务器成本, 模型会根据你发出的提问决定它的难易程度. 如果你发的问题比较简单, 那么模型将会只使用浅层输出作为最终概率分布输出(比如一个拥有48个transformer block的模型, 只激活8层), 这样可以节省大量的计算量(大部分的输入是相对简单的, 按照这种方法可以大幅降低简单prompt的回答成本).
为了支持这种"只激活少数层"的输出模式, 我们希望层数较少时模型仍然有接近深层模型的性能, 于是就产生了"自己蒸馏自己"这种看似不合理的现象(实际上可以将深层模型视作teacher, 浅层模型视作student)
代码对应
代码里将 mode in {‘feature’,‘self’} 走同一套特征对齐流程;区别在于 teacher 的来源:自蒸馏时,teacher 常用 EMA Teacher(指数滑动平均的教师权重)。
已经在优化器步进后更新 EMA teacher:
if args.distillation_mode == 'self' and teacher_model is not None:
update_ema_teacher(teacher_model, model, decay=args.ema_decay)
这样 teacher_model(X) 就给出 h T ( l ) h_T^{(l)} hT(l) 或 z T z_T zT,而 model(X) 给出 h S ( k ) h_S^{(k)} hS(k) 或 z S z_S zS,其余同 feature/logit 的损失计算。
Distillation 的应用
- ChatGPT → 小助手模型:大模型生成数据,训练小模型模仿。
- INT8/FP8 低精度蒸馏:让小模型适应量化后的计算环境。
- 多语言蒸馏:teacher 支持 100 种语言,student 支持 20 种但依然表现良好。
现在市面上大部分简单的问答应用以及语音互动可以使用一个几B甚至不到1B的模型解决!
以下是核心代码, 可以看到, 我们完整实现了蒸馏过程, 首先计算了学生模型和教师模型的logits, 然后再计算loss(根据模式不同使用kl散度/teacher输出/中间层MSE). 完整代码可以在这里查看lec4完整代码
- 示例代码
def train_epoch(epoch, wandb, alpha=0.0, temperature=1.0):
start_time = time.time()
if teacher_model is not None:
teacher_model.eval()
teacher_model.requires_grad_(False)
for step, (X, Y, loss_mask) in enumerate(train_loader):
X = X.to(args.device)
Y = Y.to(args.device)
loss_mask = loss_mask.to(args.device)
lr = get_lr(epoch * iter_per_epoch + step,
args.epochs * iter_per_epoch,
args.learning_rate)
for param_group in optimizer.param_groups:
param_group['lr'] = lr
# 前向传播(学生模型)
with ctx:
res = model(X)
student_logits = res.logits
# 教师模型前向传播(只在eval & no_grad)
teacher_logits = None
if args.distillation_mode in {"logit", "response", "feature", "self"}:
if teacher_model is not None:
with torch.no_grad():
tout = teacher_model(X)
teacher_logits = tout.logits
# 对齐词表
vocab_size_student = student_logits.size(-1)
if teacher_logits.size(-1) != vocab_size_student:
teacher_logits = teacher_logits[..., :vocab_size_student]
# ========== 计算损失 ==========
# 1) Ground-Truth CE Loss(可选)
loss_mask_flat = loss_mask.view(-1)
ce_loss = F.cross_entropy(
student_logits.view(-1, student_logits.size(-1)),
Y.view(-1),
ignore_index=0,
reduction='none'
)
ce_loss = torch.sum(ce_loss * loss_mask_flat) / loss_mask_flat.sum()
if lm_config_student.use_moe:
ce_loss += res.aux_loss
# 2) Distillation Loss(根据模式)
distill_loss = torch.tensor(0.0, device=args.device)
mode = args.distillation_mode
if mode == 'logit' and teacher_logits is not None:
v = min(student_logits.size(-1), teacher_logits.size(-1))
st_flat = student_logits[..., :v].contiguous().view(-1, v)
te_flat = teacher_logits[..., :v].contiguous().view(-1, v)
m = (loss_mask_flat == 1)
distill_loss = kl_logit_distill(st_flat[m], te_flat[m], temperature=temperature)
elif mode == 'response' and teacher_logits is not None:
# 硬标签:teacher argmax。按有效 token 掩码聚合
v = min(student_logits.size(-1), teacher_logits.size(-1))
with torch.no_grad():
hard = teacher_logits[..., :v].argmax(dim=-1)
token_ce = F.cross_entropy(
student_logits[..., :v].contiguous().view(-1, v),
hard.view(-1),
reduction='none'
)
distill_loss = torch.sum(token_ce * loss_mask_flat) / loss_mask_flat.sum()
elif mode in {'feature', 'self'}:
# 收集中间层表示并做 MSE 对齐(如维度不同,使用线性投影)
layers = select_feat_layers(len_layers=len(getattr(model.module if isinstance(model, torch.nn.parallel.DistributedDataParallel) else model, 'layers')), k=args.feature_layers)
stu_fc = FeatureCollector(model, layers)
tea_fc = FeatureCollector(teacher_model if teacher_model is not None else model, layers)
with torch.no_grad():
_ = (teacher_model(X) if teacher_model is not None else model(X))
_ = model(X) # 学生需要参与梯度,这里 forward 以触发钩子,但我们已拿到 logits;再 forward 一次开销可接受于 demo
feat_loss = 0.0
for li in layers:
s = stu_fc.outputs[li] # [B,T,Ds]
t = tea_fc.outputs[li] # [B,T,Dt]
if s.size(-1) != t.size(-1):
t = feature_project(t, t.size(-1), s.size(-1))
feat_loss = feat_loss + masked_mean(F.mse_loss(s, t, reduction='none'), loss_mask)
distill_loss = feat_loss / max(1, len(layers))
stu_fc.close(); tea_fc.close()
# 3) 总损失 = alpha * CE + (1-alpha) * Distill(若无 teacher 则退化为纯 CE)
if teacher_model is None and mode != 'self':
loss = ce_loss
else:
loss = alpha * ce_loss + (1 - alpha) * distill_loss
scaler.scale(loss).backward()
if (step + 1) % args.accumulation_steps == 0:
scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip)
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad(set_to_none=True)
# EMA teacher(自蒸馏)在优化器步进后更新
if args.distillation_mode == 'self' and teacher_model is not None:
update_ema_teacher(teacher_model, model, decay=args.ema_decay)
if step % args.log_interval == 0:
spend_time = time.time() - start_time
Logger(
'Epoch:[{}/{}]({}/{}) loss:{:.4f} lr:{:.12f} epoch_Time:{}min:'.format(
epoch,
args.epochs - 1,
step,
iter_per_epoch,
loss.item(),
optimizer.param_groups[-1]['lr'],
spend_time / (step + 1) * iter_per_epoch // 60 - spend_time // 60
)
)
if (wandb is not None) and (not ddp or dist.get_rank() == 0):
wandb.log({
"loss": loss.item(),
"ce_loss": ce_loss.item(),
"distill_loss": distill_loss.item() if (teacher_model is not None or args.distillation_mode == 'self') else 0.0,
"lr": optimizer.param_groups[-1]['lr'],
"last-time": spend_time / (step + 1) * iter_per_epoch // 60 - spend_time // 60
})
if (step + 1) % args.save_interval == 0 and (not ddp or dist.get_rank() == 0):
model.eval()
moe_path = '_moe' if lm_config_student.use_moe else ''
ckp = f'{args.save_dir}/full_dist_{lm_config_student.dim}{moe_path}.pth'
if isinstance(model, torch.nn.parallel.DistributedDataParallel):
state_dict = model.module.state_dict()
else:
state_dict = model.state_dict()
torch.save(state_dict, ckp)
model.train()
4.4 Get Your Hands Dirty
到这里, 你已经可以开始尝试训练和蒸馏模型了!
通过以下脚本可以开始与训练一个dim为512, 共有8层transformer block的模型(根据你的显卡配置以及显存大小可以调整dim和n_layers以及batch size)
python scripts/train/train_pretrain.py --data_path ./dataset/pretrain_hq.jsonl --dim {your_dim} --n_layers {your_num_layers} --batch_size 16 --tokenizer_dir ./model/minillm_tokenizer --out_dir {your_save_dir}
通过以下脚本你可以将你刚才训练的模型进行蒸馏(当然, 目前阶段还只能蒸馏预训练的模型)
python scripts/train/train_distillation.py --data_path ./dataset/pretrain.jsonl --batch_size 16 --epochs 1 --use_wandb --distillation_mode logit --alpha 0.0 --temperature 1.0 --student_dim 512 --student_layers 8 --teacher_dim 1024 --teacher_layers 16 --max_seq_len 1024 --teacher_ckpt ./{your_save_dir}/pretrain_{your_dim}.pth --out_dir {your_distillation_out_dir} --student_random_init
五、Pretrain
六、监督微调训练SFT

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 25
25 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)