Prompt Caching:让LLM Token成本降低10倍,这是怎么做到的?
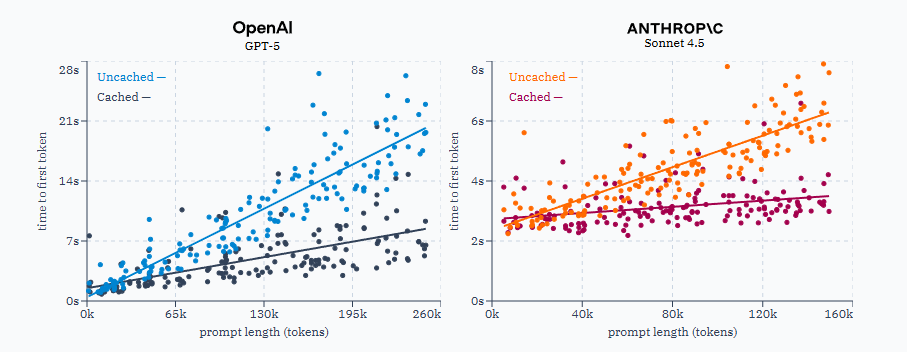
在撰写这篇文章时,无论是OpenAI还是Anthropic的API,缓存输入Token的单价都比常规输入Token便宜10倍。,提示词缓存可以**“为长提示词减少高达85%的延迟”**。在实际测试中发现,对于足够长的提示词,这一说法确实成立。测试中向Anthropic和OpenAI发送了数百次请求,当所有输入Token都被缓存时,首个Token的响应时间显著缩短。看到这些渐变文字和漂亮图表后,是否
提示词缓存:让LLM Token成本降低10倍的秘密
在撰写这篇文章时,无论是OpenAI还是Anthropic的API,缓存输入Token的单价都比常规输入Token便宜10倍。
Anthropic官方宣称,提示词缓存可以**“为长提示词减少高达85%的延迟”**。在实际测试中发现,对于足够长的提示词,这一说法确实成立。测试中向Anthropic和OpenAI发送了数百次请求,当所有输入Token都被缓存时,首个Token的响应时间显著缩短。
看到这些渐变文字和漂亮图表后,是否想过一个问题…
缓存的Token到底是什么?
在那些庞大的GPU集群中究竟发生了什么,让服务商能够给出10倍的输入Token折扣?它们在请求之间保存了什么?这可不是简单地保存响应结果,然后在收到相同提示词时复用——通过API就能轻松验证并非如此。发送同一个提示词十几次,即使usage部分显示使用了缓存输入Token,每次得到的响应仍然不同。
供应商的文档虽然很好地解释了如何使用提示词缓存,但回避了究竟缓存了什么这个核心问题。为了找到答案,决定深入研究LLM的工作原理,直到完全理解服务商缓存的确切数据、它的用途,以及它如何让一切变得更快更便宜。
读完这篇文章,将会:
- 更深入地理解LLM的工作原理
- 建立关于LLM运行方式的新认知
- 了解被缓存的确切数据,以及它们如何降低LLM请求成本
LLM架构
从本质上讲,LLM是巨大的数学函数。它们接收一串数字作为输入,产生一个数字作为输出。LLM内部是一个包含数十亿个精心排列的运算的庞大图结构,将输入数字转换为输出数字。
这个庞大的运算图可以粗略分为4个部分。
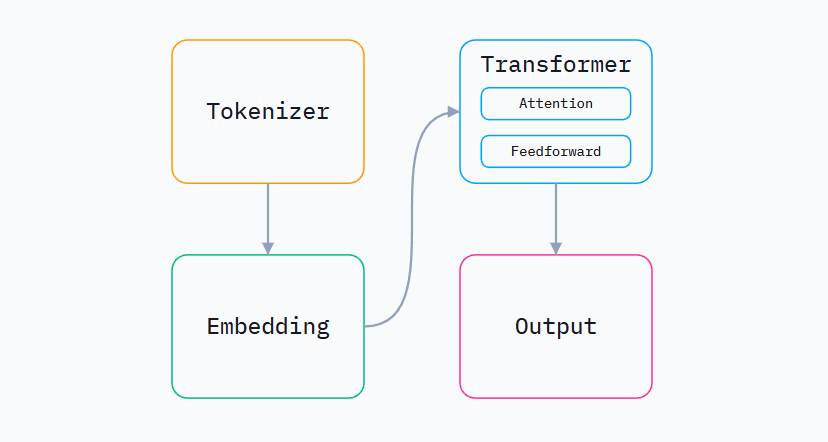
图中的每个节点都可以看作一个接收输入、产生输出的函数。输入以循环方式送入LLM,直到一个特殊的输出值告诉它停止。用伪代码表示如下:
prompt = "生命的意义是什么?"
tokens = tokenizer(prompt)
while True:
embeddings = embed(tokens)
for attention, feedforward in transformers:
embeddings = attention(embeddings)
embeddings = feedforward(embeddings)
# 获取最后一个生成的 token
output_token = output(embeddings)
if output_token == END_TOKEN:
break
tokens.append(output_token)
print(decode(tokens))
LLM的代码出乎意料地简洁
虽然上面的代码大幅简化了,但现代LLM所需的代码行数之少确实令人惊讶。
Sebastian Raschka使用PyTorch创建了开源模型的独立重新实现版本,还有大量其他优质教育材料。以当前领先的开源模型之一Olmo 3为例,只用了几百行代码。
提示词缓存发生在transformer的"注意力"(attention)机制中。接下来将按顺序介绍LLM的工作原理,直到抵达那个关键部分。这意味着需要从讨论Token(tokens)开始。
分词器(Tokenizer)
在LLM处理提示词之前,需要将其转换为可操作的表示形式。这是分词器和嵌入阶段共同完成的两步过程。在介绍到嵌入部分之前,这一切的必要性可能还不够清晰,暂且先了解分词器做了什么。
分词器接收提示词,将其切分成小块,并为每个独特的块分配一个整数ID,称为"Token"。例如,GPT-5对提示词"Check out ngrok.ai"的分词结果如下:
提示词被分割成数组["Check", " out", " ng", "rok", ".ai"],并转换为Token[4383, 842, 1657, 17690, 75584]。相同的提示词总是产生相同的Token。Token还区分大小写,因为大小写传达了关于词语的信息。例如,大写的"Will"更可能是人名,而小写的"will"则不太可能。
为什么不直接按空格或字符分割?
这是个相当复杂的问题,详细讨论会让文章篇幅翻倍。简单来说,这是一种权衡。如果想深入了解,Andrej Karpathy有一个出色的视频,从零开始构建分词器。对于提示词缓存来说,只需知道分词化将文本转换为数字就足够了。
Token是LLM输入和输出的基本单位。向ChatGPT提问时,响应会以Token流的形式返回,LLM每完成一次迭代就发送一个Token。服务商这样做是因为生成完整响应可能需要数十秒,但逐个发送Token让整个过程感觉更具互动性。
提示词Token输入,✨ AI运算 ✨,输出Token产生,不断重复。这个过程称为"推理"(inference)。注意每个输出Token都会在下一次迭代前追加到输入提示词中。LLM需要所有上下文来产生良好答案。如果只输入提示词,它会不断尝试生成答案的第一个Token。如果只输入答案,它会立即忘记问题。整个提示词加上答案都需要在每次迭代中送入LLM。
那个199999的Token是什么?
推理必须在某个时刻停止。LLM有各种"特殊"Token可以输出,其中之一用于标记响应结束。在GPT-5分词器中这是Token199999。这只是LLM终止的众多方式之一。可以通过API指定生成的最大Token数,服务商可能还有其他与安全相关的停止规则。
还有用于标记对话消息开始和结束的特殊Token,这就是ChatGPT和Claude等聊天模型如何知道一条消息在哪里结束、另一条在哪里开始。
关于分词器的最后一点:存在很多不同的分词器!ChatGPT使用的分词器与Claude使用的不同。即使是OpenAI制造的不同模型也使用不同的分词器。每个分词器都有自己的文本分割规则。如果想了解各种分词器如何分割文本,可以查看tiktokenizer。
现在已经介绍了Token,接下来谈谈嵌入。
嵌入(Embedding)
来自分词器的Token现在送入嵌入阶段。要理解嵌入,有助于先理解模型的目标是什么。
当人类用代码解决问题时,编写的函数接收输入并产生输出。例如华氏度转摄氏度的转换。
def fahrenheit_to_celsius(fahrenheit):
return ((fahrenheit - 32) * 5) / 9
可以向fahrenheitToCelsius输入任何数字并得到正确答案。但如果遇到一个不知道公式的问题呢?如果只有下面这个神秘的输入输出表格呢?
| 输入 | 输出 |
|---|---|
| 21 | 73 |
| 2 | 3 |
| 10 | 29 |
| 206 | 1277 |
这里不期望能识别出这个函数,虽然如果把截图粘贴到ChatGPT,它会立即算出来。
当知道每个输入的预期输出,但不知道产生输出的函数时,可以"训练"模型来学习这个函数。方法是给模型一个画布——那个庞大的数学运算图——不断修改这个图,直到模型收敛到正确的函数。每次更新图结构时,都会将输入通过它来检查输出与正确答案的接近程度。持续这样做直到满意为止。这就是训练。
事实证明,在训练模型输出正确文本时,能够识别两个句子何时相似会很有帮助。但相似指的是什么?它们可能在悲伤、幽默或发人深省方面相似。可能在长度、节奏、语气、语言、词汇、结构方面相似。可以用大量维度来描述两个句子的相似性,而句子可能在某些维度上相似但在其他维度上不同。
Token没有维度。它们只是普通整数。但嵌入,嵌入有很多维度。
嵌入是长度为n的数组,表示n维空间中的一个位置。如果n是3,嵌入可能是[10, 4, 2],表示3维空间中的位置x=10, y=4, z=2。在训练LLM时,每个Token被分配一个随机的起始位置,训练过程会移动所有Token,直到找到能产生最佳输出的排列。
嵌入阶段首先查找每个Token的嵌入。用伪代码表示如下:
# 训练期间创建,推理期间永不改变
EMBEDDINGS = [...]
def embed(tokens):
# 将 token ID 数组转换为对应的向量数组
return [EMBEDDINGS[token] for token in tokens]
将tokens这个整数数组转换为嵌入数组。一个数组的数组,或者说"矩阵"。
Token[75, 305, 284, 887]被转换为3维嵌入的矩阵。
给嵌入的维度越多,它用来比较句子的维度就越多。这里讨论的是3维嵌入,但当前模型的嵌入有数千个维度。最大的模型甚至超过10,000维。
为了展示更多维度的价值,下面有8组彩色形状,开始时处于1维空间。它们位于一条线上,是一团难以理解的混乱。但随着添加更多维度,很明显有8个不同的相关组。
嵌入阶段还做了最后一件事。在获取Token的嵌入后,它将Token在提示词中的位置编码到嵌入中。这部分的工作原理没有深入研究,因为它对提示词缓存的工作方式影响不大,但如果没有它,LLM将无法判断提示词中Token的顺序。
更新之前的伪代码,假设存在一个名为encodePosition的函数。它接收嵌入和位置,返回包含位置编码的新嵌入。
EMBEDDINGS = [...]
def embed(tokens):
# 输入: Token 数组 (整数)
# 输出: n 维嵌入向量的数组 (矩阵)
result = []
for i, token in enumerate(tokens):
embedding_vector = EMBEDDINGS[token]
# 将位置 i 的信息编码进向量
positioned_vector = encode_position(embedding_vector, i)
result.append(positioned_vector)
return result
总而言之,嵌入是n维空间中的点,可以将其视为所代表文本的语义含义。在训练期间,每个Token在这个空间中移动,靠近其他相似的Token。维度越多,LLM对每个Token的表示就越复杂和细腻。
分词器和嵌入阶段所做的工作都是为了将文本转换为LLM可以处理的形式。现在来看看transformer阶段中这项工作的具体内容。
Transformer
transformer阶段的任务是接收嵌入作为输入,并在n维空间中移动它们。它通过两种方式做到这一点,这里只关注第一种:注意力(attention)。本文不会讨论"前馈"(Feedforward)或输出阶段(👀)。
注意力机制的工作是帮助LLM理解提示词中每个Token之间的关系,通过允许Token影响彼此在n维空间中的位置来实现。它以加权方式组合提示词Token的嵌入。输入是整个提示词的嵌入,输出是所有输入嵌入的加权组合后的单个新嵌入。
例如,如果提示词是"Mary had a little",产生4个TokenMary、had、a和little,注意力机制可能决定生成下一个Token时应该使用:
- 63%的
Mary嵌入 - 16%的
had嵌入 - 12%的
a嵌入 - 9%的
little嵌入
然后通过权重缩放并求和来组合它们。这就是LLM如何知道应该在多大程度上关心或"注意"提示词中的每个Token。
这是目前为止最复杂和抽象的部分。首先以伪代码形式展示,然后看看嵌入如何通过它被操纵。本想让这部分少些数学内容,但这里很难避免一些数学运算。
注意力中的大多数计算都是矩阵乘法。关于矩阵乘法,这篇文章只需要知道输出矩阵的形状由输入矩阵的形状决定。输出总是具有与第一个输入矩阵相同的行数和与第二个输入矩阵相同的列数。
考虑到这一点,下面是简化的注意力机制如何计算分配给每个Token的权重。代码中用*表示矩阵乘法。
# WQ 和 WK 在训练期间学习,推理期间不变
# 它们是 n * n 矩阵 (n 为嵌入维度)
WQ = [[...], [...], [...]]
WK = [[...], [...], [...]]
def attention_weights(embeddings):
# 这里的 @ 表示矩阵乘法
Q = embeddings @ WQ
K = embeddings @ WK
# 计算分数:Q 乘以 K 的转置
scores = Q @ transpose(K)
# 应用因果掩码 (Mask),防止看到未来的 Token
masked = mask(scores)
return softmax(masked)
来看看嵌入在这个函数中如何流动。
这些WQ和WK变量是什么?
还记得前面说过每个Token的嵌入被分配一个随机位置,然后训练过程对它们进行微调,直到模型收敛到一个好的排列吗?
WQ和WK类似。它们是n乘n的矩阵,n是嵌入维度,在训练开始时被赋予随机值。然后在训练期间也会被调整,以帮助模型收敛到良好的解决方案。
任何在训练期间被调整的东西都被称为"模型参数"。嵌入向量和这些WQ、WK矩阵中的每个浮点数都是一个参数。当听到模型被描述为拥有"1750亿参数"时,说的就是这些数字。
至于WQ和WK实际上是什么,其实并不完全清楚。随着模型收敛,它们最终代表了某种有助于模型产生良好输出的嵌入转换。它们可能在做任何事情,解释其中的内容是一个开放且活跃的研究领域。
要获得Q和K,将embeddings分别乘以WQ和WK。WQ和WK的行数和列数始终等于嵌入维度数,本例中为3。这里为WQ和WK选择了随机值,为便于阅读将值四舍五入到小数点后两位。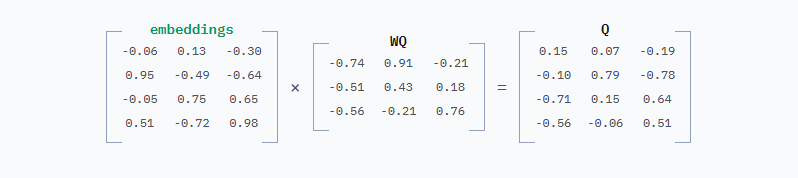
计算K的方式完全相同,只是用WK代替WQ。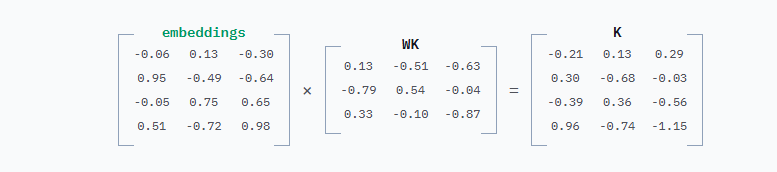
然后将Q和K相乘。将K"转置",即沿对角线翻转,这样得到的矩阵是方阵,行数和列数都等于输入提示词中的Token数。
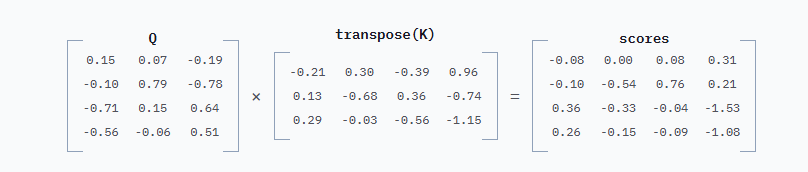
这些scores表示每个Token对下一个生成的Token的重要程度。左上角的数字-0.08是"Mary"对"had"的重要程度。再往下一行,-0.10是"Mary"对"a"的重要程度。在矩阵运算之后会展示一个可视化图。接下来的所有操作都是关于将这些分数转换为可用于混合嵌入的权重。
这个scores矩阵的第一个问题是它允许未来Token影响过去。在第一行中,唯一已知的词是"Mary",所以它应该是唯一对生成"had"有贡献的词。第二行同理,已知"Mary"和"had",所以只有这两个词应该对生成"a"有贡献,依此类推。
为了解决这个问题,对矩阵应用三角掩码来消除未来Token。但不是将它们置零,而是设为负无穷大。原因马上解释。
第二个问题是这些分数是任意数字。如果它们是跨每行总和为1的分布,会更有用。这正是softmax函数的作用。softmax的工作细节不重要,它比简单地将每个数字除以行的总和稍微复杂一点,但结果相同:每行总和为1,每个数字介于0和1之间。
为了解释负无穷大,这里是softmax的代码实现:
import math
def softmax(matrix):
output_matrix = []
for row in matrix:
# 对行中的每个元素取指数
exps = [math.exp(x) for x in row]
# 计算该行指数的总和
sum_exps = sum(exps)
# 归一化,使行总和为 1
normalized_row = [exp / sum_exps for exp in exps]
output_matrix.append(normalized_row)
return output_matrix
它不是简单地求和然后除以总和。而是先对每个数字取Math.exp,即e^x。如果使用零而不是负无穷大,Math.exp(0) === 1,所以零仍会贡献权重。Math.exp(-Infinity)是0,这正是想要的。
下面的网格显示了提示词"Mary had a little"的注意力权重示例。这些权重与上面的计算不匹配,因为它们来自运行在优秀的Transformer Explained网站上的GPT-2版本。这些是来自真实模型(尽管较旧)的真实权重。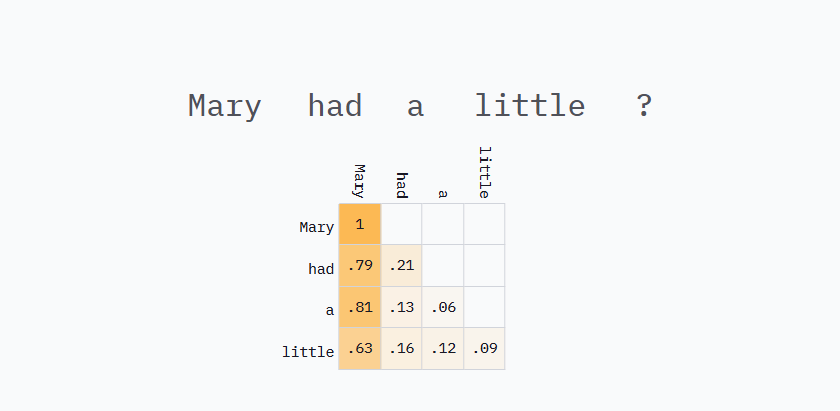
在第一行,只有"Mary",所以Mary对"had"贡献100%。然后在第二行,“Mary"贡献79%,而"had"贡献21%来生成"a”,依此类推。LLM认为这个句子中最重要的词是"Mary"可能并不令人惊讶,Mary在每一行都有最高权重。如果要求完成句子"Jessica had a little",不太可能选择"lamb"。
剩下的就是混合Token嵌入,这比生成权重要简单得多。
# 训练期间学习的矩阵
WV = [[...], [...], ...]
def attention(embeddings):
# 获取 V 矩阵
V = embeddings @ WV
# 获取权重矩阵 (来自上面的函数)
weights = attention_weights(embeddings)
# 最终输出:权重与 V 的加权组合
return weights @ V
与之前类似,有一个在训练时确定的WV矩阵。用它从Token嵌入中得到V矩阵。
为什么不直接混合嵌入?
当推导Q和K然后相乘以获得注意力权重时,完全是在处理Token彼此的相关性。嵌入编码了关于Token的各种语义含义,一个维度可能代表"颜色",另一个代表"大小",另一个代表"粗鲁程度"等等。权重使用相似性来确定相关性。
WV允许模型决定要传递哪些维度。在句子"Mary had a little"中,关于Mary的重要信息是她的名字。模型可能也学到了很多关于血腥玛丽鸡尾酒或苏格兰女王玛丽的知识。这些与童谣无关,传递它们会引入噪音。所以WV允许模型在混合嵌入之前过滤掉无关特征。
然后将V乘以生成的weights,输出是一组新的嵌入:
注意力机制的最终输出是这个output矩阵的最后一行。来自先前Token的所有上下文信息都通过注意力过程混合到这最后一行中,但必须计算所有先前的行才能做到这一点。
总而言之,嵌入输入,新嵌入输出。注意力机制进行了大量复杂的数学运算,根据在训练期间学习的WQ、WK和WV矩阵,按重要程度混合Token。这就是让LLM知道其上下文窗口中什么重要以及为什么重要的机制。
现在终于知道了讨论缓存所需的一切知识。
注意力机制还有更多内容
这里展示的是注意力的简化版本(确实如此!)旨在突出对提示词缓存最重要的内容。实际应用中还有更多内容,如果有兴趣深入了解,推荐观看3blue1brown关于注意力的视频。
提示词缓存
再次看看上面的网格,但这次将看到它如何在推理循环中生成每个新Token时被填充。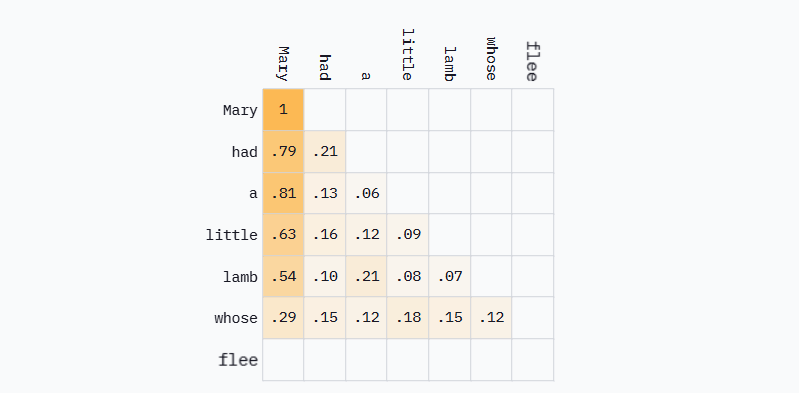
每个新Token都被追加到输入并完整重新处理。但仔细观察,多播放几次动画:之前的权重都没有改变。第2行始终是0.79和0.21。第3行始终是0.81、0.13、0.06。**在重做很多不必要的计算。**如果刚刚完成处理"Mary had a",那么"Mary had a little"的大部分矩阵乘法都是不必要的,而这正是LLM推理循环的工作方式。
可以通过对推理循环进行两个改变来避免这些重复计算:
- 每次迭代缓存
K和V矩阵。 - 只将最新的Token送入模型,而不是整个提示词。
再次演示矩阵乘法,但这次有前4个Token的K和V矩阵缓存,只传入单个Token的嵌入。是的,又是矩阵运算,抱歉,但大部分与之前相同,会快速过一遍。
计算新的Q只产生一行输出。WQ与之前相同。
然后计算新的K也只产生一行输出,WK同样相同。
但接着将这新的一行追加到上一次迭代缓存的4行K中:
现在有了所有Token的K矩阵,但只需要计算最后一行。
以这种方式继续得到新的scores:
和新的weights:
整个过程中,只计算需要的内容。完全没有重新计算旧值。这延续到获取新的V行:
并追加到缓存的V:
最后将新的weights与新的V相乘得到最终的新embeddings: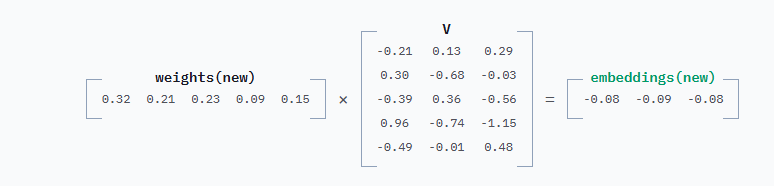
这单个新的嵌入行就是需要的全部。来自先前Token的所有上下文信息都通过缓存的K和V融入其中。
缓存的数据是embeddings * WK和embeddings * WV的结果,即K和V。因此,提示词缓存通常被称为"KV缓存"。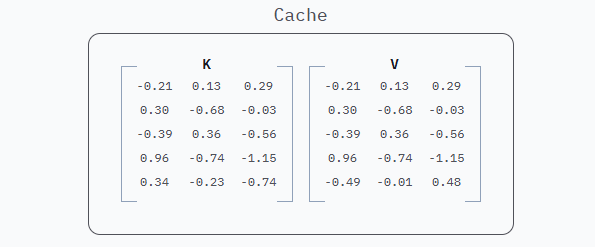
就是这样,上面的K和V矩阵,它们就是服务商保存在庞大数据中心中的1和0,用来为用户提供10倍便宜的Token和更快的响应。
服务商在请求发出后的5-10分钟内保留每个提示词的这些矩阵,如果发送以相同提示词开头的新请求,它们会重用缓存的K和V而不是重新计算。真正酷的是可以部分匹配缓存条目并仍然使用匹配的部分,而不是全部。
下面的可视化在几个具有相似前缀的提示词之间循环,展示缓存条目可能如何被使用。缓存会定期清空以展示如何重新填充。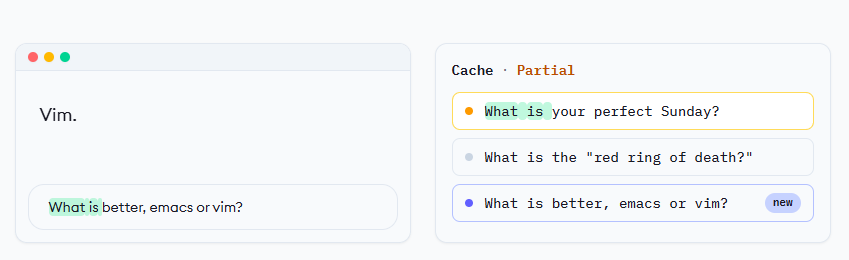
OpenAI和Anthropic的缓存方式截然不同。OpenAI自动完成所有工作,尝试在可能时将请求路由到缓存条目。在实验中,通过发送请求后立即重新发送,命中率约为50%。考虑到长上下文窗口的首字节时间可能很长,这可能导致性能不一致。
Anthropic给予更多控制权,让用户决定何时缓存以及缓存多久。需要为这种特权付费,但在实验中,当要求Anthropic缓存提示词时,它们100%的时间都会路由到缓存条目。这可能使它们更适合在长上下文窗口上操作并需要可预测延迟的应用。
温度参数呢?
LLM服务商提供各种参数来控制模型产生内容的随机性。常见的有temperature、top_p和top_k。这些参数都影响推理循环的最后一步,即模型根据分配给词汇表中每个Token的概率来选择Token。这发生在注意力机制产生最终嵌入之后,所以提示词缓存不受这些参数影响。可以自由更改它们而不用担心使缓存的提示词失效。
参考文献
为了学习撰写这篇文章所需的一切知识,查阅了许多资源,以下是最有帮助的:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)