基于Flask+AI的智能招聘系统:从0到1实现全流程自动化招聘分析解决方案
本文介绍了一套基于Flask+AI的智能招聘系统,旨在解决传统招聘中简历筛选效率低、技能匹配不准、面试协调繁琐等痛点。系统以Flask为后端框架,整合SQLite数据库、Ollama AI模型、PyPDF2等工具,实现用户与权限管理、职位配置、简历解析、AI技能匹配、面试安排、数据统计等全流程功能。核心亮点在于通过Ollama模型自动分析简历与职位匹配度,生成技能匹配清单和推荐指数,替代人工初筛;
目录
前言
在数字化时代,企业招聘面临着 “简历筛选效率低、技能匹配精准度不足、面试安排协调繁琐” 三大核心痛点。传统招聘流程中,HR 平均每筛选 1 个合格候选人需要查阅 50 + 份简历,花费大量时间在重复性工作上,还容易因人工判断出现偏差。
之前一直在忙,很久没有再次更新之前做的自动化智能招聘分析系统,因为之前在github上看到过类似的智能招聘助手。现在给大家分享一套基于 Flask+AI 构建的智能招聘系统,该系统整合了 PDF 简历解析、AI 技能匹配、自动化邮件通知、面试全流程管理等核心功能,实现了从 “简历上传” 到 “面试落地” 的端到端数字化管理。不仅能将简历筛选效率提升 80%,还能通过 AI 算法提升人才匹配精准度,非常适合中小企业或创业团队快速落地智能化招聘方案。可以满足日常招聘管理、简历分析、邮件发送等等。本文将从应用介绍、技术栈、核心代码解析、部署步骤等维度,带大家全面了解这套系统。
提示:以下是本篇文章正文内容,下面案例可供参考
一、系统核心功能
1.功能架构总览
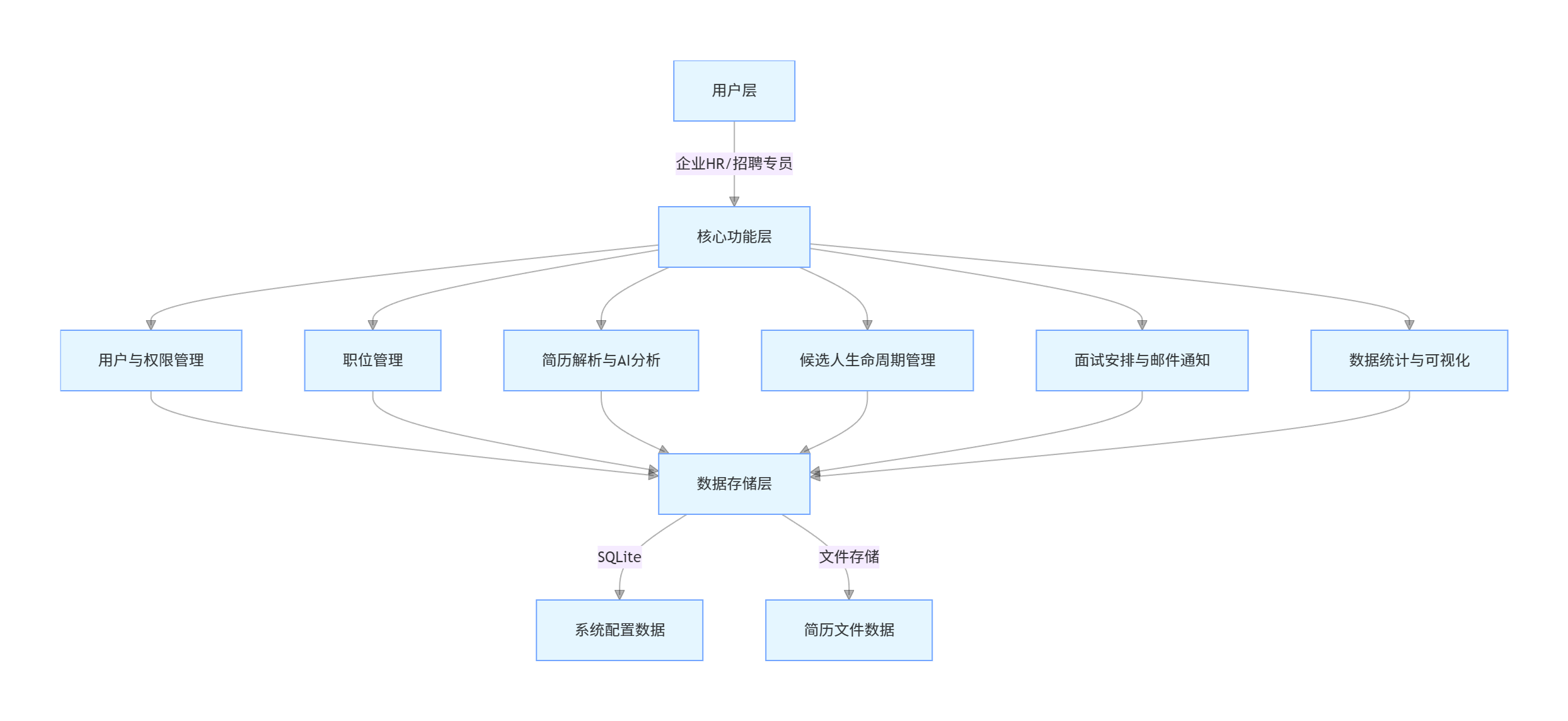
2.系统功能清单
| 模块名称 | 核心功能描述 | 技术支撑 | 应用价值 |
|---|---|---|---|
| 用户与权限管理 | 1. 企业用户注册 / 登录 / 注销;2. 系统配置(邮箱 SMTP、AI 服务地址);3. 账户安全与权限隔离 | Flask-Login、SQLAlchemy、SMTP 协议 | 保障企业数据独立,配置灵活适配不同需求 |
| 职位管理 | 1. 4 类预设职位(含技能要求);2. 自定义职位创建 / 编辑 / 删除;3. 职位候选人数量统计 | 数据库关联查询、表单验证 | 满足通用 + 个性化招聘需求,实时跟踪招聘进度 |
| 简历解析与 AI 分析 | 1. PDF 简历上传与文本提取;2. 候选人信息自动识别(姓名 / 邮箱 / 手机号);3. AI 技能匹配分析(匹配 / 缺失技能、经验评级、推荐指数) | PyPDF2、Ollama API(DeepSeek) | 替代人工初筛,提升筛选效率与精准度 |
| 候选人全生命周期管理 | 1. 候选人状态切换(待处理 / 已通过 / 已拒绝 / 面试安排);2. 候选人详情全维度展示;3. 候选人批量删除与数据管理 | 数据库 CRUD、状态联动机制 | 可视化管理招聘流程,快速定位重点候选人 |
| 面试安排与邮件通知 | 1. 自定义面试时间 / 会议链接;2. 状态联动邮件自动生成;3. 邮件预览 / 草稿 / 发送测试 | smtplib、email 模块、Bootstrap 模态框 | 自动化通知流程,降低跨部门协调成本 |
| 数据统计与可视化 | 1. 核心指标统计(候选人总数 / 通过数 / 待处理数 / 面试数);2. 最近候选人快速访问 | 数据聚合查询、响应式布局 | 直观呈现招聘进度,提升 HR 工作效率 |
二、技术栈解析
1. 后端技术栈
• 核心框架:Flask(轻量级 Web 框架,开发效率高,适合快速迭代)
• 数据库:SQLite(文件型数据库,无需额外部署,适合中小规模数据存储)
• ORM 工具:SQLAlchemy(简化数据库操作,支持数据模型快速定义)
• 认证授权:Flask-Login(用户会话管理)、Flask-WTF(表单验证与 CSRF 防护)
• AI 集成:Ollama API(支持本地部署 AI 模型,保障简历数据隐私)
• 简历解析:PyPDF2(PDF 文本提取,优化中文换行处理)
• 邮件服务:smtplib+email(支持 SSL 加密,兼容 QQ/163/Gmail 等主流邮箱)
2. 前端技术栈
• 基础架构:HTML5+CSS3+JavaScript(原生开发,降低依赖复杂度)
• 样式框架:Bootstrap 5(响应式设计,适配 PC / 移动端)
• 交互组件:Font Awesome(图标库)、模态框(面试安排 / 邮件预览)
• 可视化:自定义 CSS 动画 + 数据统计面板
3. 核心依赖清单
Flask==2.3.3
Flask-SQLAlchemy==3.0.5
Flask-WTF==1.1.1
Flask-Login==0.6.2
PyPDF2==3.0.1
requests==2.31.0
pytz==2023.3
email-validator==2.0.0三、核心模块代码功能深度解析
1. 用户与权限管理模块
1.1 用户数据模型设计
默认填充主流邮箱 SMTP 配置(QQ 邮箱),降低用户配置门槛;通过unique=True保证用户名唯一性,user_id关联所有业务表实现数据隔离。
class User(UserMixin, db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(100), unique=True, nullable=False)
password = db.Column(db.String(100), nullable=False)
company_name = db.Column(db.String(200)) # 企业名称
email = db.Column(db.String(120), nullable=False) # 发件邮箱
email_passkey = db.Column(db.String(200)) # 邮箱授权码
ollama_url = db.Column(db.String(200), default="http://localhost:11434") # AI服务地址
smtp_server = db.Column(db.String(200), default="smtp.qq.com") # SMTP服务器
smtp_port = db.Column(db.Integer, default=465) # SMTP端口这里的AI服务地址,目前我采用的是本地ollama部署的deepseek-r1:8b模型,因为需要分析简历信息,具有隐私信息,最好采用本地部署的模型会更好,避免数据泄露。由于本地部署的模型能力会比较弱,所以对服务器性能有要求,同时该模型最好带有招聘知识库,这样会更精确。

1.2 登录核心逻辑
基于 Flask-Login 实现用户会话管理,current_user.is_authenticated判断登录状态,避免重复登录。
@app.route('/login', methods=['GET', 'POST'])
def login():
if current_user.is_authenticated:
return redirect(url_for('dashboard')) # 已登录直接跳转到控制面板
form = LoginForm()
if form.validate_on_submit():
# 查询用户并验证密码
user = User.query.filter_by(username=form.username.data).first()
if user and user.password == form.password.data:
login_user(user) # 激活用户会话
return redirect(url_for('dashboard'))
else:
return render_template('login.html', form=form, error='用户名或密码错误')
return render_template('login.html', form=form)登录与注册与传统的系统登录区别不大,对应输入用户名和密码、包含公司名称和邮箱,邮箱授权码需要输入正确,这是为了后续邮件发送成功的前提,邮箱授权码获取可以参考:QQ邮箱授权码获取与应用指南-CSDN博客。
2. 简历解析与 AI 分析模块
2.1 PDF 简历文本提取
针对中文简历常见的换行混乱问题,通过判断行尾标点符号智能合并文本,保留原始段落结构。
def extract_text_from_pdf(file_path):
"""从PDF提取文本,处理中文换行问题"""
try:
with open(file_path, 'rb') as f:
pdf_reader = PyPDF2.PdfReader(f)
text = ""
for page in pdf_reader.pages:
page_text = page.extract_text()
if page_text:
lines = page_text.split('\n')
cleaned_lines = []
for i, line in enumerate(lines):
line = line.strip()
if line:
# 标点结尾保留换行,否则合并(避免中文语义断裂)
if line[-1] in ['。', ';', '!', '?', ':']:
cleaned_lines.append(line)
elif i + 1 < len(lines) and lines[i + 1].strip():
cleaned_lines.append(line + ' ')
else:
cleaned_lines.append(line)
text += ''.join(cleaned_lines) + "\n\n"
return text
except Exception as e:
print(f"PDF解析错误: {str(e)}")
return ""通过本地上传PDF简历后,会通过AI进行分析,但是目前候选人信息还是无法成功自动提取出来,后续需要进行改进完善。这样可以避免后续在填写姓名和邮箱时,出现错误,导致邮件发送出错。

2.2 候选人信息自动提取
目前候选人信息自动提取还是存在问题,无法实现自动提取PDF里的信息,后续会进行优化。
def extract_candidate_info(resume_text):
"""自动提取姓名、邮箱、手机号"""
# 提取邮箱
email_pattern = r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b'
emails = re.findall(email_pattern, resume_text)
email = emails[0] if emails else ""
# 提取手机号(中国手机号正则)
phone_pattern = r'1[3-9]\d{9}'
phones = re.findall(phone_pattern, resume_text)
phone = phones[0] if phones else ""
# 提取中文姓名(2-4个中文字符,排除非姓名词语)
name_pattern = r'[\u4e00-\u9fa5]{2,4}'
name_matches = re.findall(name_pattern, resume_text[:500]) # 优先查找简历开头
name = ""
for match in name_matches:
if match not in ['个人简历', '求职意向', '联系方式']:
name = match
break
return {'name': name, 'email': email, 'phone': phone}2.3 AI技能匹配分析
核心设计:
- 提示词工程:明确要求 AI 返回 JSON 格式,降低解析难度;
- 异常处理:补全 AI 可能缺失的字段,避免系统崩溃;
- 稳定性优化:设置低温度(0.3)保证评估结果的一致性,避免主观偏差。
def analyze_resume(resume_text, role_key):
"""AI分析简历与职位匹配度"""
# 获取职位要求(支持预设/自定义职位)
if role_key in ROLE_REQUIREMENTS:
requirements_text = ROLE_REQUIREMENTS[role_key]['requirements']
role_name = ROLE_REQUIREMENTS[role_key]['name']
else:
role = RoleRequirement.query.filter_by(key=role_key).first()
requirements_text = role.requirements if role else ""
role_name = role.name if role else "未知职位"
# 构建AI提示词(明确输出格式)
prompt = f"""
你是专业技术招聘专家,按以下要求评估简历:
职位: {role_name}
要求: {requirements_text}
简历内容: {resume_text}
评估标准:匹配70%+必要技能为通过,考虑实践经验和可转移技能
必须返回JSON格式结果:
{{
"selected": true/false,
"feedback": "详细评估反馈",
"matching_skills": ["技能1"],
"missing_skills": ["技能2"],
"experience_level": "初级/中级/高级",
"recommendation_score": 0-100
}}
"""
# 调用Ollama API
response = call_ollama_api(prompt, current_user.id)
try:
# 提取并处理AI输出(兼容格式不规范问题)
json_start = response.find('{')
json_end = response.rfind('}') + 1
result = json.loads(response[json_start:json_end])
# 补全缺失字段(避免AI输出不完整)
if 'recommendation_score' not in result:
match_count = len(result.get('matching_skills', []))
missing_count = len(result.get('missing_skills', []))
total = match_count + missing_count
result['recommendation_score'] = int((match_count / total) * 100) if total > 0 else 0
return result
except:
# 异常降级:返回默认结果
return {"selected": False, "feedback": "分析失败", "matching_skills": [], "missing_skills": [], "experience_level": "未知", "recommendation_score": 0}
# Ollama API调用函数
def call_ollama_api(prompt, user_id):
user = User.query.get(user_id)
ollama_url = user.ollama_url if user else "http://localhost:11434"
try:
response = requests.post(
f"{ollama_url}/api/generate",
json={
"model": "deepseek-r1:8b",
"prompt": prompt,
"stream": False,
"options": {"temperature": 0.3} # 低温度保证结果稳定
}
)
return response.json().get("response", "")
except Exception as e:
print(f"AI调用失败: {str(e)}")
return ""可以根据匹配的结果,结合实际需求进行验证,然后修改提示词关键信息,提高匹配精度。这里的界面设计是可以很好帮助招聘人员来识别候选人,例如技能评估、匹配度、推荐指数等等,可以很好看见该候选人的优势和劣势。
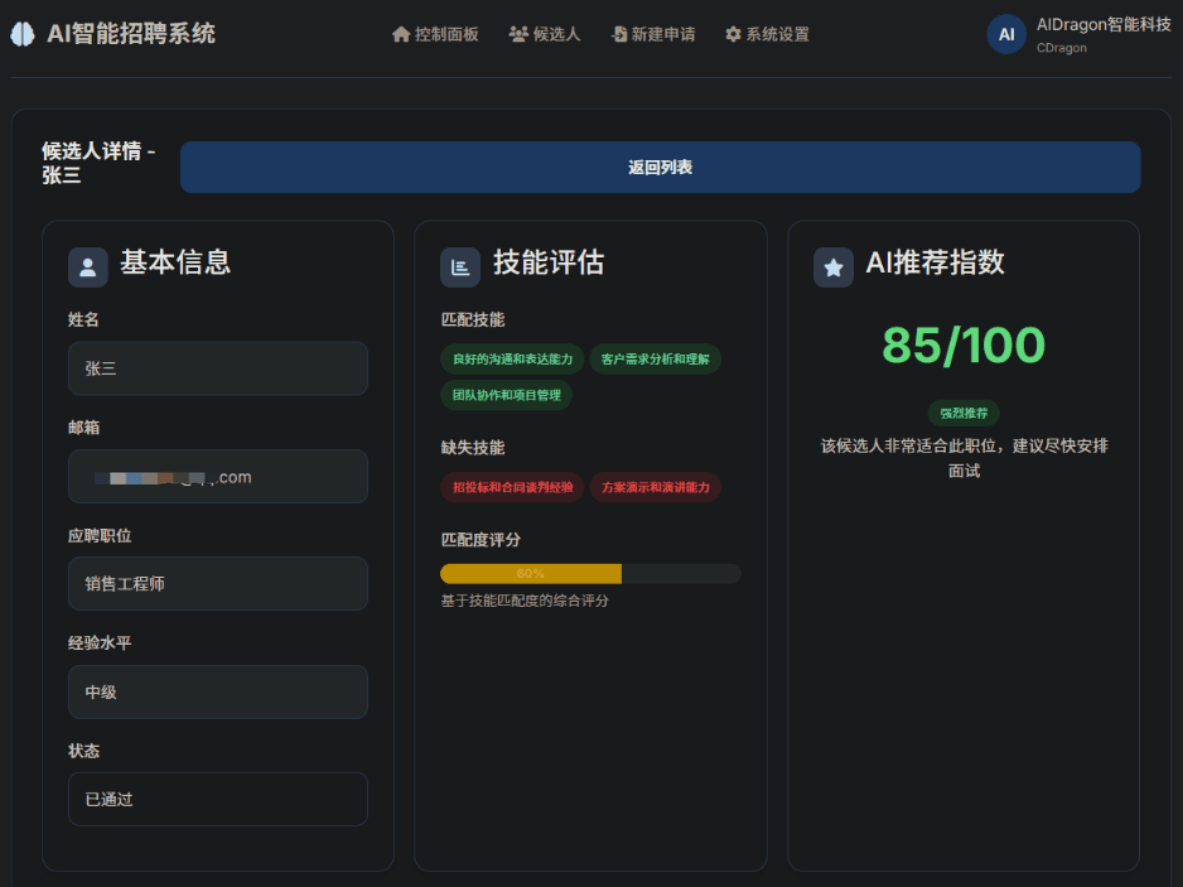
3. 面试安排与邮件通知
3.1 面试安排核心逻辑
时区处理采用pytz库,确保面试时间以北京时间展示,避免跨时区沟通偏差。
@app.route('/candidate/<<int:candidate_id>/schedule_interview', methods=['POST'])
@login_required
def schedule_interview_api(candidate_id):
candidate = Candidate.query.get_or_404(candidate_id)
if candidate.user_id != current_user.id:
return jsonify({'success': False, 'message': '无权操作'}), 403
data = request.json
interview_time_str = data.get('interview_time')
meeting_link = data.get('meeting_link')
# 解析面试时间(北京时间处理)
try:
beijing_tz = pytz.timezone('Asia/Shanghai')
interview_time = datetime.strptime(interview_time_str, '%Y-%m-%dT%H:%M')
interview_time = beijing_tz.localize(interview_time)
except ValueError:
return jsonify({'success': False, 'message': '时间格式错误'}), 400
# 更新候选人状态与面试信息
candidate.status = 'interview_scheduled'
candidate.interview_time = interview_time
candidate.meeting_link = meeting_link
# 生成标准化面试通知邮件
interview_email_content = f"""
尊敬的{candidate.name},
感谢您应聘{current_user.company_name}的{ROLE_REQUIREMENTS[candidate.role]['name']}职位。
现将面试安排通知如下:
面试时间:{interview_time.strftime('%Y年%m月%d日 %H:%M')}
会议链接:{meeting_link}
请提前5分钟加入会议,准备好相关技术问题的讨论,祝面试顺利!
{current_user.company_name}招聘团队
"""
# 发送邮件并更新状态
success, message = send_email(
subject=f"{ROLE_REQUIREMENTS[candidate.role]['name']}职位面试通知",
body=interview_email_content,
to_email=candidate.email,
user_id=current_user.id,
candidate_id=candidate.id
)
if success:
candidate.email_content = interview_email_content
candidate.email_sent = True
db.session.commit()
return jsonify({'success': True, 'message': '面试已安排并通知候选人'})
else:
return jsonify({'success': False, 'message': f'面试安排成功但邮件发送失败: {message}'})3.2 邮件发送功能
使用Header类处理中文主题和发件人名称,避免乱码;针对不同邮箱的认证失败、连接失败等问题,返回明确的错误提示,便于用户排查。
def send_email(subject, body, to_email, user_id, candidate_id=None):
"""基于SMTP协议发送邮件,支持SSL加密"""
user = User.query.get(user_id)
if not user.email or not user.email_passkey:
return False, "邮箱或授权码未设置"
try:
# 构建邮件内容(处理中文编码)
msg = MIMEMultipart()
msg['Subject'] = Header(subject, 'utf-8') # 中文主题编码
msg['From'] = formataddr((str(Header(f"{user.company_name}招聘团队", 'utf-8')), user.email))
msg['To'] = to_email
msg.attach(MIMEText(body, 'plain', 'utf-8'))
# SSL加密连接(解决465端口兼容问题)
context = ssl.create_default_context()
context.check_hostname = False
context.verify_mode = ssl.CERT_NONE
# 连接SMTP服务器并发送
with SMTP_SSL(user.smtp_server, user.smtp_port, context=context) as server:
server.login(user.email, user.email_passkey)
server.sendmail(user.email, [to_email], msg.as_string())
# 同步邮件发送状态
if candidate_id:
candidate = Candidate.query.get(candidate_id)
if candidate:
candidate.email_sent = True
candidate.email_sent_at = datetime.utcnow()
db.session.commit()
return True, "邮件发送成功"
except smtplib.SMTPAuthenticationError:
return False, "邮箱认证失败,请检查授权码"
except smtplib.SMTPConnectError:
return False, "无法连接SMTP服务器"
except Exception as e:
return False, f"发送失败: {str(e)}"在进行发送邮件给候选人时,会弹出错误提示信息“邮件发送失败”,但是实际该功能是已经实现发送,这里也是一个奇怪的bug。

3.3 邮件编写与实际发送
AI会继续详细的分析与评估,同时会根据候选人的简历给出适当的建议,之后会根据评估结果续写邮件。若该候选人为合适人选,那邮件会发出面试邀请;若不适合,则邮件会发出拒绝。
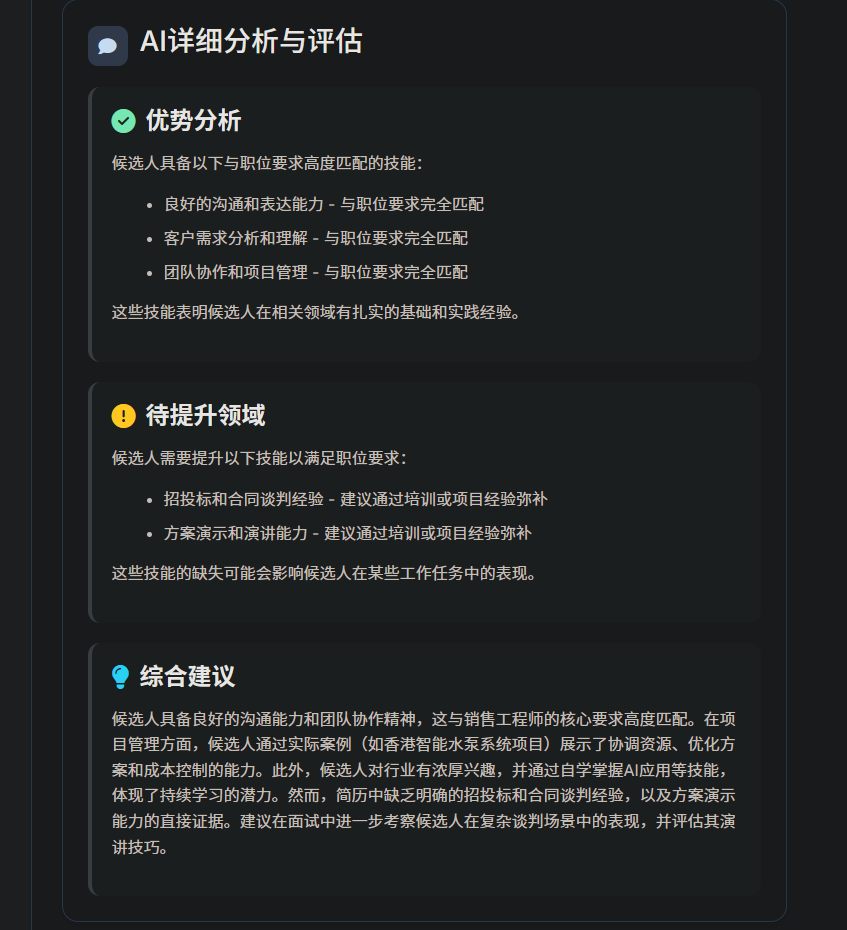
邮件内容,支持自定义修改,用户可以在原AI续写的内容上进行修改,可以灵活回答。
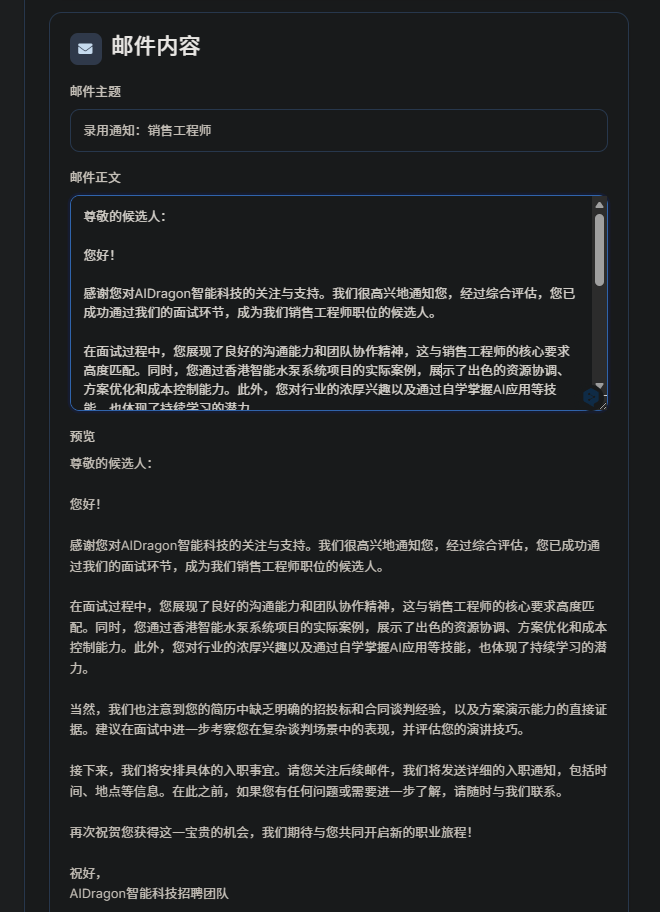
可以非常清晰看到,录用通知是成功发送到应聘者的邮箱里的,并且内容与系统里AI生成的是一致的,而且格式和排版上也是接近招聘形式。
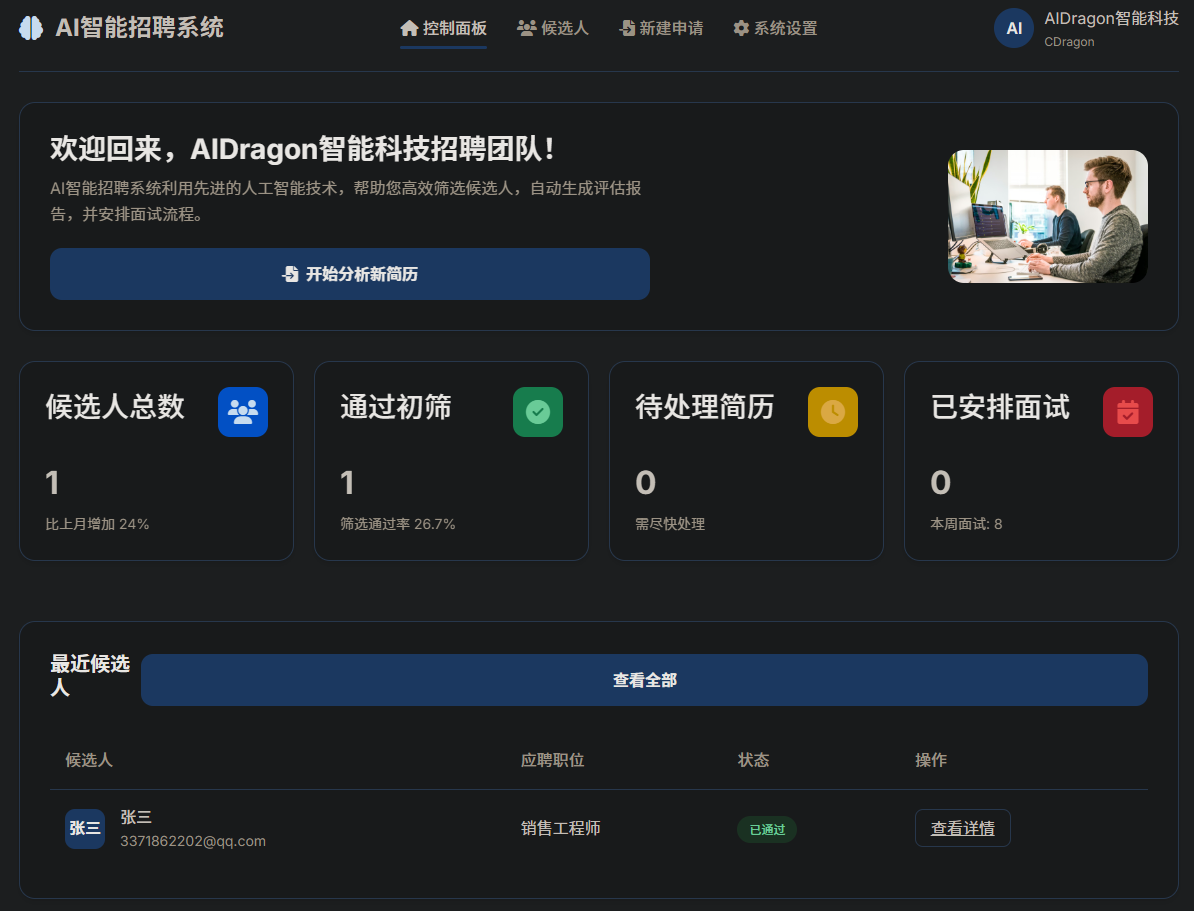
4. 数据统计与可视化模块
通过 SQLAlchemy 的筛选器和聚合查询高效统计数据,限制最近 5 条候选人数据展示,平衡数据完整性与页面加载速度。
@app.route('/dashboard')
@login_required
def dashboard():
# 查询最近5条候选人数据(提升页面加载速度)
candidates = Candidate.query.filter_by(user_id=current_user.id).order_by(Candidate.id.desc()).limit(5).all()
# 统计核心招聘指标
total_candidates = Candidate.query.filter_by(user_id=current_user.id).count()
selected_count = Candidate.query.filter_by(user_id=current_user.id, status='selected').count()
pending_count = Candidate.query.filter_by(user_id=current_user.id, status='pending').count()
interview_count = Candidate.query.filter_by(user_id=current_user.id, status='interview_scheduled').count()
return render_template('dashboard.html',
company_name=current_user.company_name,
candidates=candidates,
total_candidates=total_candidates,
selected_count=selected_count,
pending_count=pending_count,
interview_count=interview_count)前端界面上也做了适当的调整,目前没有添加太多元素,看起来简洁,符合常规网页系统风格。
四、系统部署与运行步骤
1. 环境准备
• 操作系统:Windows/macOS/Linux 均可
• Python 版本:3.8 及以上
• 依赖工具:Git、pip
• 可选:Ollama 本地部署(需提前安装并启动,默认端口 11434)
2. 部署步骤
# 1. 克隆项目代码
完整项目代码可以关注公众号“AICDragon”获取
cd ai_recruitment_agent
# 2. 安装依赖包
pip install -r requirements.txt
# 3. 启动Ollama服务(本地AI模型,可选)
# 拉取DeepSeek模型
ollama pull deepseek-r1:8b
# 启动Ollama服务
ollama serve
# 4. 运行Flask应用
python app.py
# 5. 访问系统
# 浏览器打开 http://127.0.0.1:5000,注册企业账户后即可使用3. 关键配置说明
邮箱配置:登录后进入 “系统设置”,填写 SMTP 服务器(如 QQ 邮箱为smtp.qq.com)、端口(465)、邮箱授权码(需在邮箱设置中开启 SMTP 服务并获取)。
• AI 服务配置:默认使用本地 Ollama 服务(http://localhost:11434),支持替换为远程 Ollama 服务地址。
五、系统优化与扩展
1. 核心优势
• 轻量化部署:无需复杂服务器配置,单机即可运行,适合中小团队快速落地;
• 数据隐私保护:支持本地部署 Ollama 模型和 SQLite 数据库,简历数据不经过第三方;
• 高可定制化:支持自定义职位、邮件模板、AI 评估规则,适配不同企业需求;
• 易用性强:可视化操作界面,无需专业技术背景即可上手。
2. 未来扩展方向
• 简历格式扩展:支持 Word、图片简历解析(集成 python-docx、pytesseract);
• 多 AI 模型适配:增加 GPT、Claude 等第三方模型调用接口,支持模型选择;
• 数据分析增强:添加招聘转化率、技能缺口趋势图表(集成 echarts);
• 招聘平台对接:支持 Boss 直聘、智联招聘简历批量导入;
• 移动端适配:开发小程序或 APP,支持随时随地查看招聘进度。
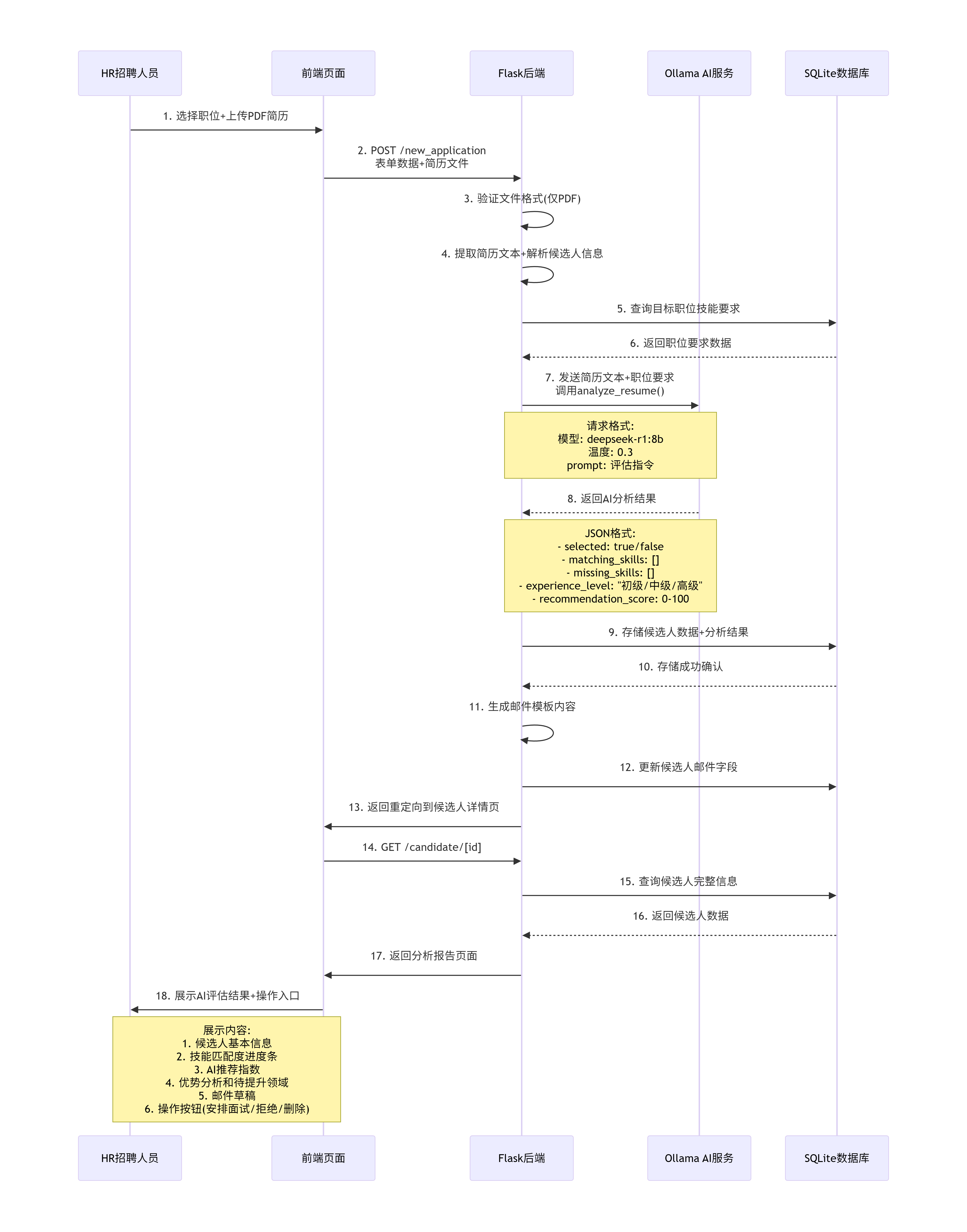
3.关键场景时序交互图
总结
这套基于 Flask+AI 的智能招聘系统,通过 “技术 + 场景” 的深度融合,完美解决了传统招聘流程中的效率低、精准度不足、协调繁琐等痛点。其核心价值在于:用 AI 替代重复性的简历筛选工作,用自动化流程简化面试安排与通知,用数据化手段提升招聘决策质量。
对于企业用户而言,系统可直接部署使用,快速降低招聘成本;对于开发者而言,代码中的 AI 调用、PDF 解析、SMTP 邮件发送等模块,可作为 Flask 项目开发的参考案例,助力快速落地类似应用。
随着 AI 技术的持续迭代,智能招聘将进一步向 “个性化匹配 + 全流程自动化” 方向发展,这套系统为企业提供了一个低成本、高性价比的智能化转型起点。如果需要进一步定制功能或解决部署问题,欢迎在评论区交流!如果需要获取系统完整代码、数据库初始化脚本或部署问题排查指南,可以留言告诉我,我会整理一份完整的资源包分享给大家~也欢迎大家关注公众号&视频号“AICDragon”

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)