【TextIn大模型加速器 + 火山引擎】用Coze+TextIn+飞书搭建全自动论文处理AI工作流
TextIn大模型加速器有三大优势:- 其一:首先在论文解析的核心环节,TextIn 大模型加速器展现出极强的场景适配能力 ,可以全面支持 PDF、图片、Word 等十余种常见学术文档格式,且解析效率很高,百页的长篇论文可实现秒级完成处理,远超传统OCR工具的处理速度。针对学术论文特有的多栏布局、嵌套表格、复杂公式、图表编号等结构化元素,TextIn 能实现精准识别与还原,避免了传统工具解析后格式
本文目录
一、前言:科研文献处理的痛点与AI工具的破局之道
上周三晚上十点,实验室的灯还亮着。我对着电脑里十几篇待整理的英文论文,第5次打开 PDF 阅读器、OCR 工具、Excel 表格来回切换 —— 刚把一篇多栏论文的摘要提取出来,格式就乱成了一团;公式识别错误导致数据核对返工,好不容易整理完的关键词,还得手动复制粘贴到团队共享表格里。
作为一名科研工作者,文献处理早已成了日常科研的 “隐形负担”:每周至少8小时耗费在PDF转文字、信息筛选、数据录入上,遇到扫描版论文、复杂排版或小语种文献,传统OCR工具要么识别不全,要么格式错乱,甚至连公式符号都会变成乱码;汇总到飞书表格还得二次校对,往往一天下来 “干活两小时,整理大半天”。
相信不少科研人都有过类似的困扰:我们需要的是快速提取论文核心信息、高效沉淀研究数据,而不是在多工具切换和重复劳动中消耗精力。传统工具的短板显而易见 —— 无法适配学术论文的复杂版式,更难以实现 “解析 - 处理 - 同步” 的全链路自动化。
而这一切,正在被 AI 工具的组合创新改变。即使大模型在科研场景深度渗透,但高质量的文档解析始终是释放大模型能力的 “第一道门槛”。正是瞄准这一痛点,我用Coze+TextIn+飞书搭建了全自动论文处理AI工作流。
无需复杂编码,仅通过可视化拖拽即可串联工具,既能解决多格式论文的高精度解析难题,又能让大模型快速处理提取的核心信息,最终自动同步到飞书表格实现数据沉淀。让我们从繁琐的文献处理中解放出来,把时间真正用在核心研究上。
二、技术底层:为什么是TextIn+Coze的工作流组合?
1.1 TextIn 大模型加速器:科研数据的 “高精度处理器”
在我看来,TextIn大模型加速器有三大优势:
- 其一:首先在论文解析的核心环节,TextIn 大模型加速器展现出极强的场景适配能力 ,可以全面支持 PDF、图片、Word 等十余种常见学术文档格式,且解析效率很高,百页的长篇论文可实现秒级完成处理,远超传统OCR工具的处理速度。针对学术论文特有的多栏布局、嵌套表格、复杂公式、图表编号等结构化元素,TextIn 能实现精准识别与还原,避免了传统工具解析后格式错乱、信息缺失的问题。
- 其二是技术优势,从 “字符提取” 升级为 “语义理解”,不仅能清晰区分标题、摘要、关键词、正文、参考文献等逻辑模块,还能精准保留公式符号、段落结构等关系。
- 最后是科研适配:针对科研场景中多语言文献混杂、排版格式多样的痛点,TextIn提供了定制化的适配方案。其支持50+语种的精准识别,无论是英文、德文、日文等常见学术语种,还是小语种文献,都能实现高效解析与信息提取。同时,面对模糊不清的老旧文献、带复杂水印的涉密论文等特殊素材,TextIn 的增强解析算法能有效过滤干扰信息,确保核心学术内容的完整提取。
1.2 Coze +飞书:低代码搭建与高效协作的双引擎
再说说 Coze 平台:它最核心的优势在于提供了可视化的插件集成能力,这对非技术背景的科研人员尤为友好。我们无需掌握复杂的编程开发技能,仅通过拖拽、点选等简单操作,就能快速将 TextIn 的解析能力与大模型的交互功能串联起来 —— 从配置论文上传的入口,到关联 TextIn 的解析结果作为大模型的输入源,整个流程都能在可视化界面中完成,大幅降低了自动化工作流的搭建门槛,让科研人员能快速上手、按需调整流程。最后将识别结果能实时同步到飞书表格中,团队成员可以直接在线编辑、批注文献信息,无需反复传输文件或手动汇总。
三、实战教程:30 分钟搭建全自动论文处理工作流
2.1 前期准备:工具与权限配置
首先我们需要登录Coze平台,大家可以看看Coze的文档中心,熟悉一下Coze的基本操作。
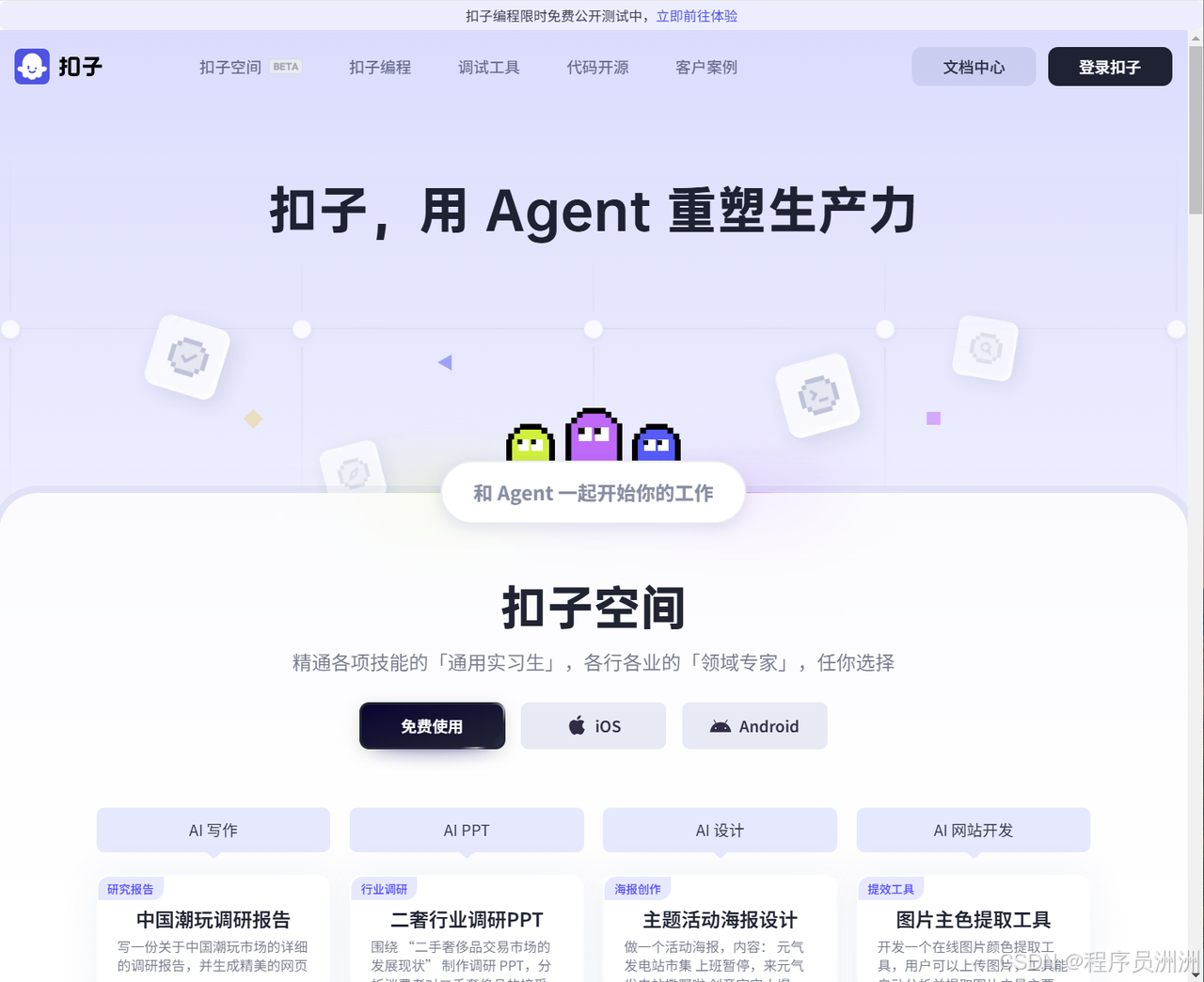
然后登录合合信息的TextIn工作台平台(https://www.textin.com/register/code/KKBKQ6),现在注册即送3000页体验哟。可以根据需要体验一下TextIn的各类产品,比如当前比较热门的通用文字识别、通用文档解析等,这些也是待会我们要在Coze平台中要引入的插件功能。
2.2 三步搭建:从插件集成到流程跑通
接下来我们就来开始搭建Coze流程吧,我们搭建的可以算是通用Agent范例,不需要依赖Rag/分片策略等,主要可以分为三个核心步骤/环节:
- Coze 流程设计:新建工作流,添加 “TextIn 文档解析” 插件,配置论文上传入口(支持单篇 / 批量上传)。
- 大模型交互配置:接入偏好大模型,设置 prompt 规则(如 “提取论文标题、摘要、关键词、核心结论”),关联 TextIn 解析结果作为输入源。
- 飞书表格输出:添加 “飞书表格” 插件,映射解析字段(论文标题→A 列、论文关键词→B 列等)。
首先我们点击Coze创建工作流,然后进行直观的工作流描述,这样如果后面有搭建Agent智能体的需求,可以让智能体知道在什么场景下调用该工作流。
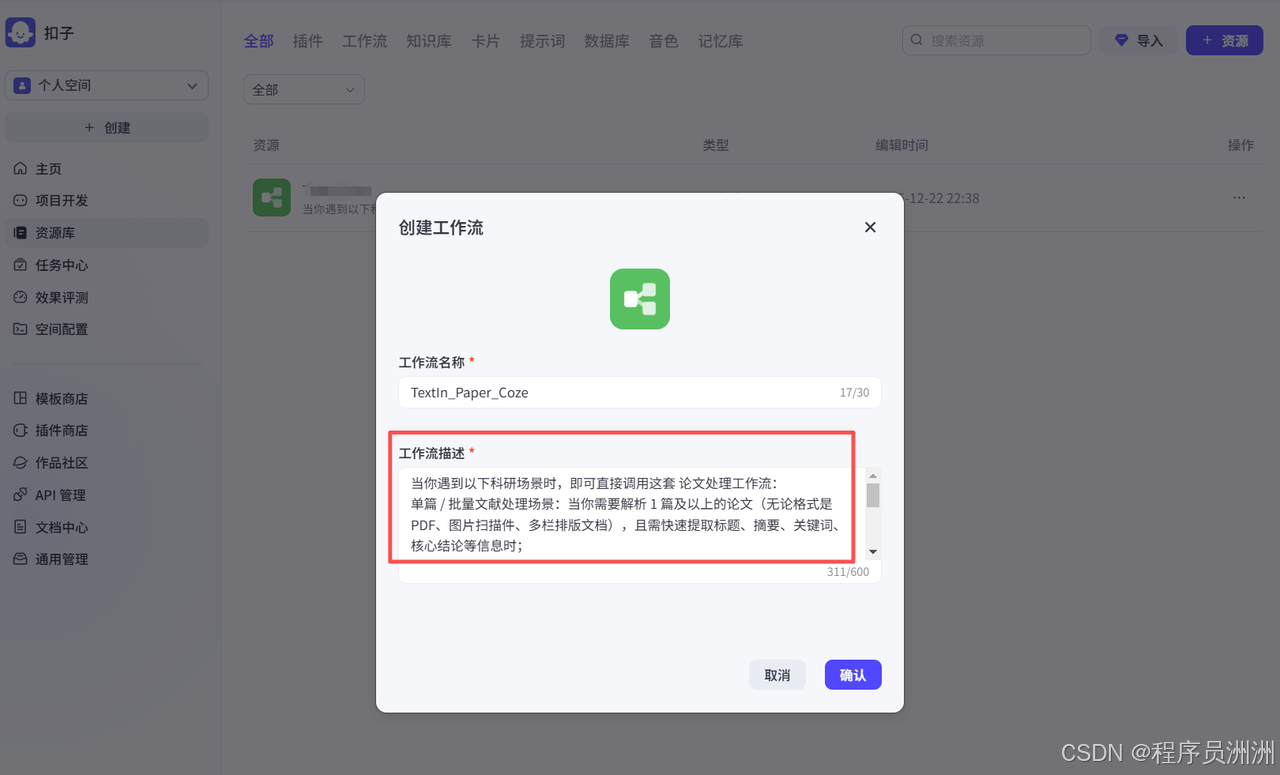
然后创建开始节点,开始节点中需要配置两个输入变量,我这里设置的是image类型的论文图片input,还有飞书的文档链接URL,飞书的文档URL后续解析完成之后的写入过程需要用到。
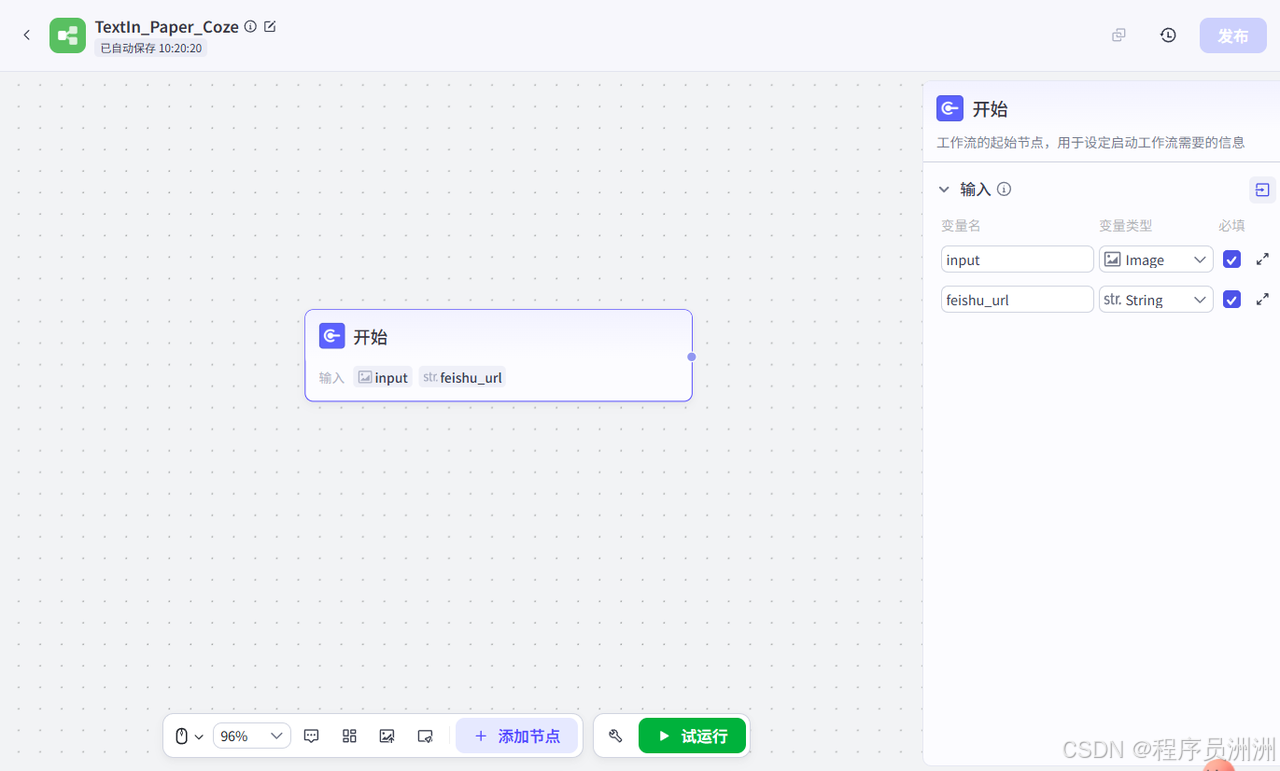
然后我们添加合合信息的TextIn ParseX解析插件,这个插件是专门LLM下游任务设计的通用文档解析服务,识别文档或图片中的文字信息,将文档解析为Markdown格式,并按常见的阅读顺序进行还原,可以赋能下游各类大语言模型任务。
这个ParseX插件是我们整个Coze工作流的重点环节,就是用来做智能文档解析处理功能的。
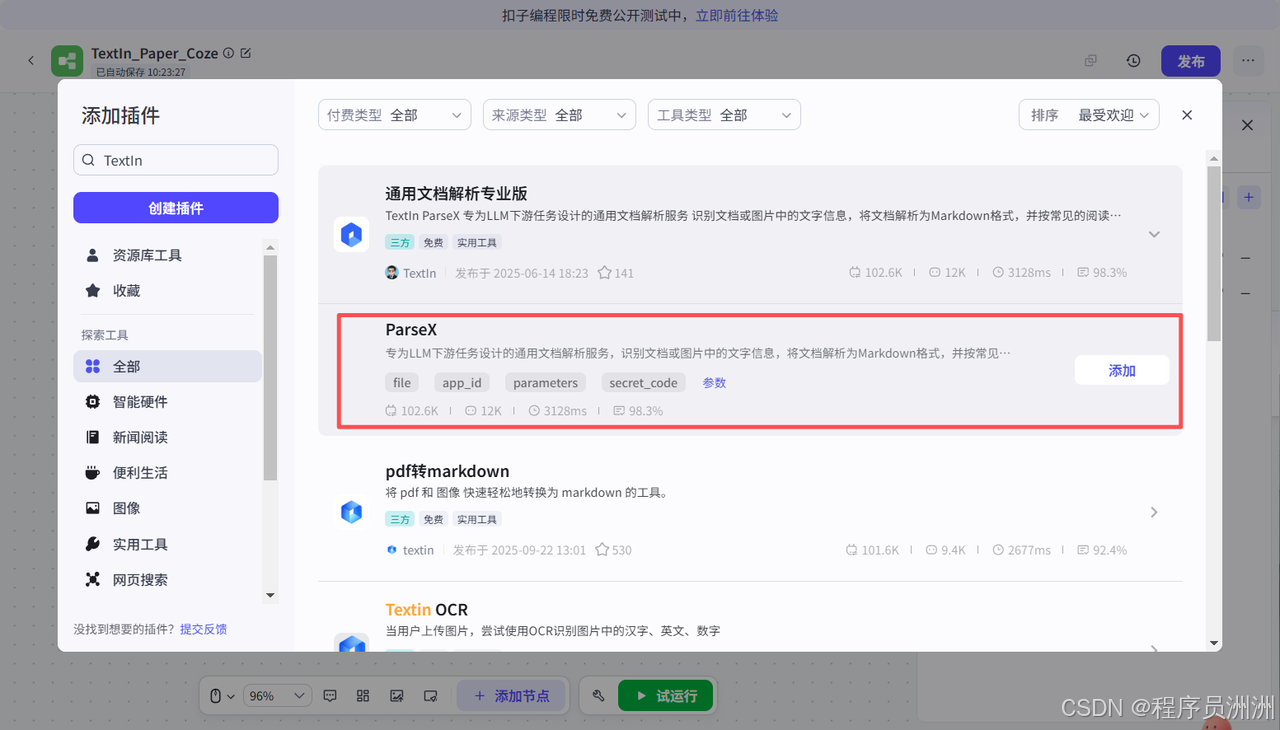
添加之后我们将开始节点和ParseX节点串联起来,然后设置ParseX对应的输入为图片,这样就可以识别到输入的论文了。
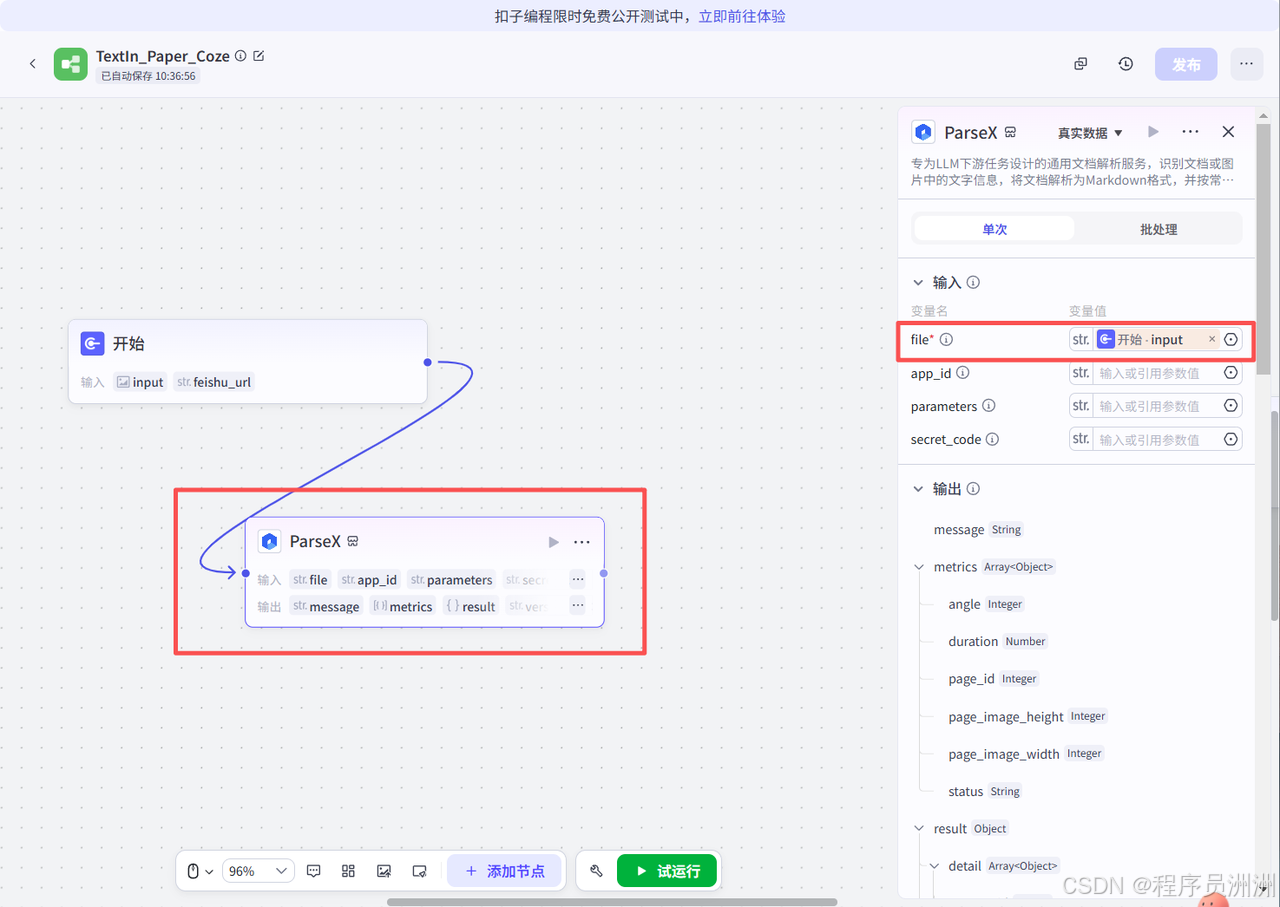
然后添加大模型节点,如图所示,配置好对应的输入、提示词、用户提示词即可。把ParseX识别的各类文字文本让大模型进行对应的提取,并且按照规定好的格式输出,比如按照Json格式输出即可。
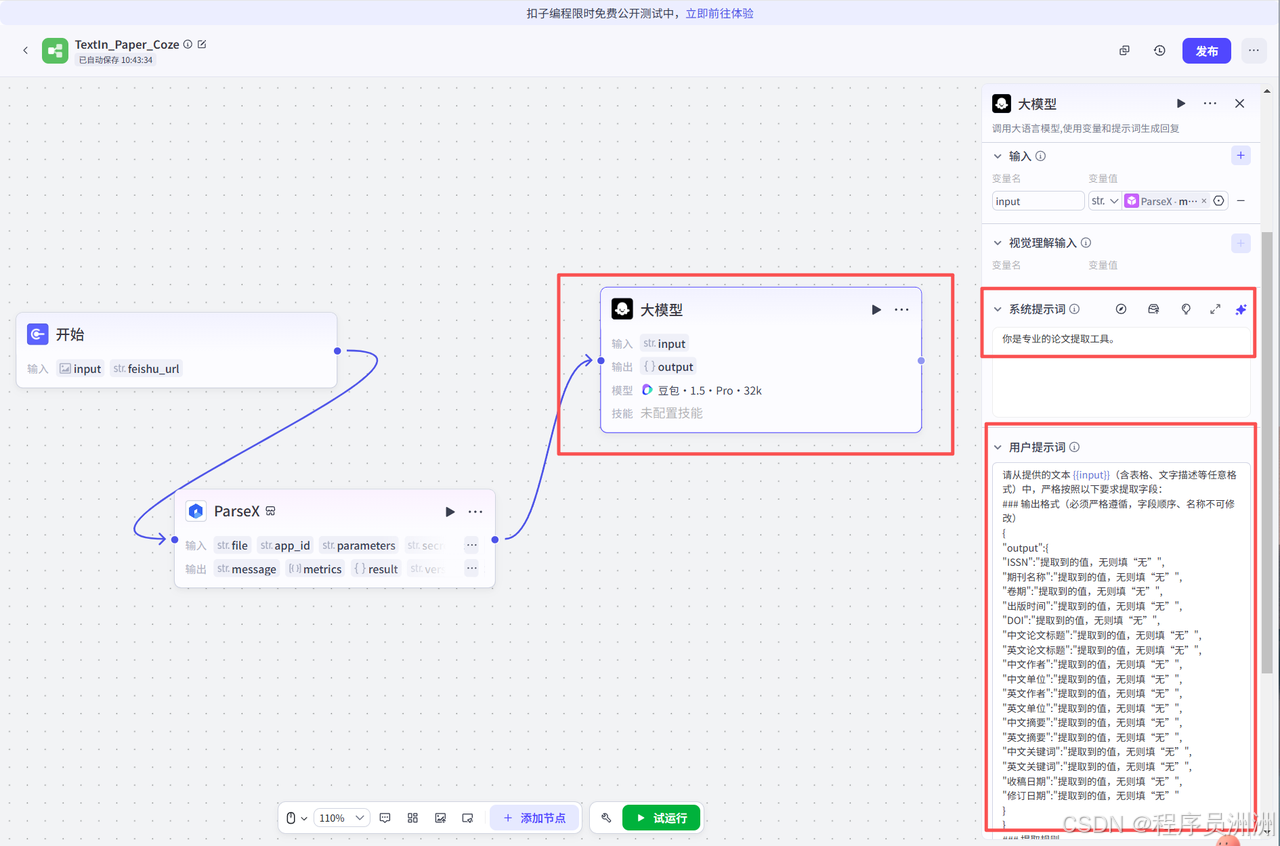
再接下来就是添加代码节点,代码节点的作用是获取大模型的格式化输出,设别嵌套的数据,然后进行对应的飞书字段映射,为后续写入飞书文档做铺垫。
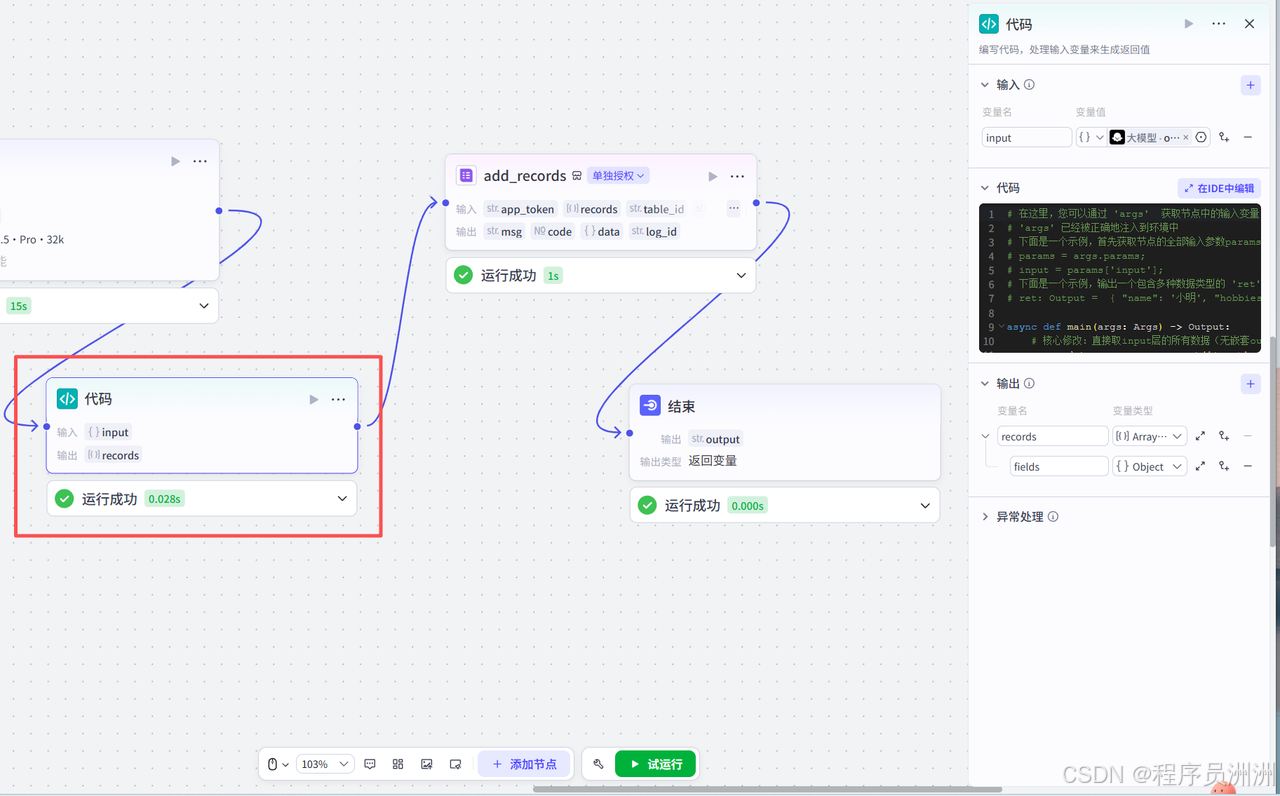
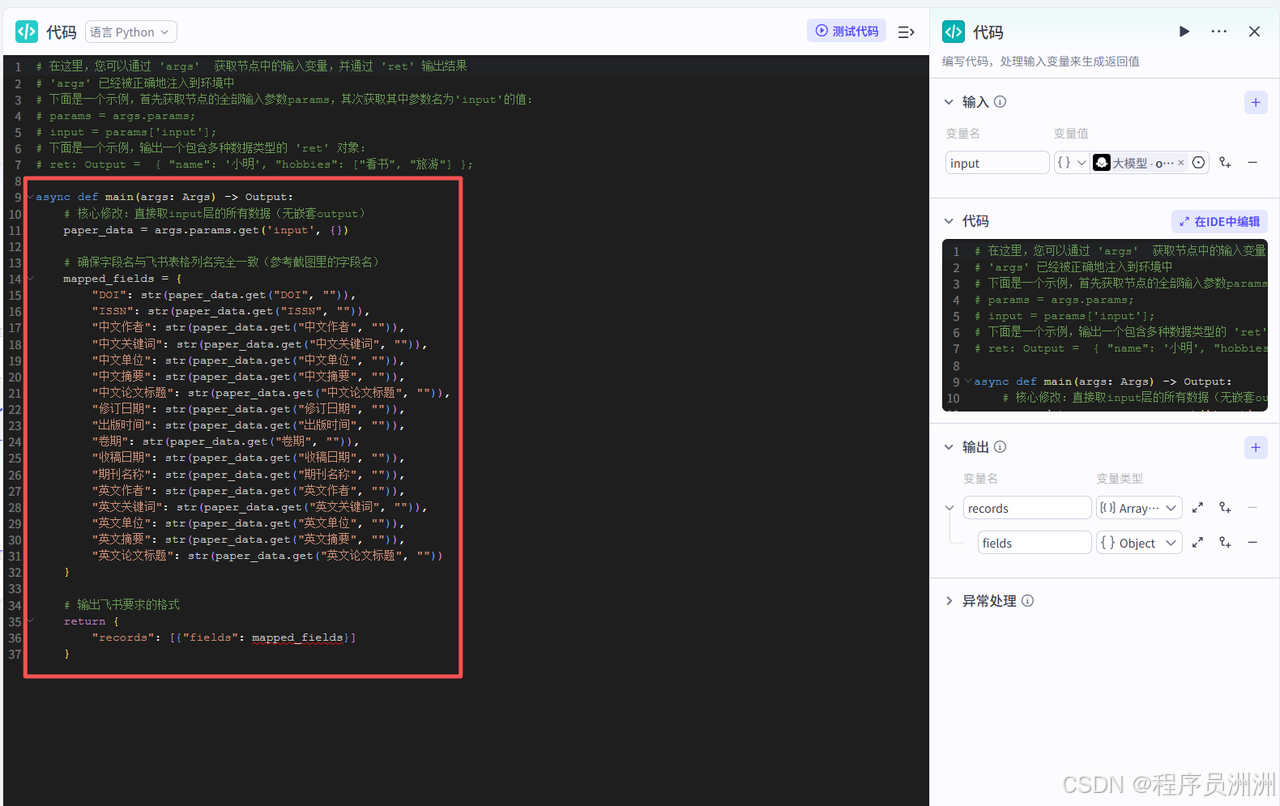
最后我们添加飞书多维表格插件节点,授权对应的飞书账号之后,配置输入与输出,工作流就基本大功告成了!
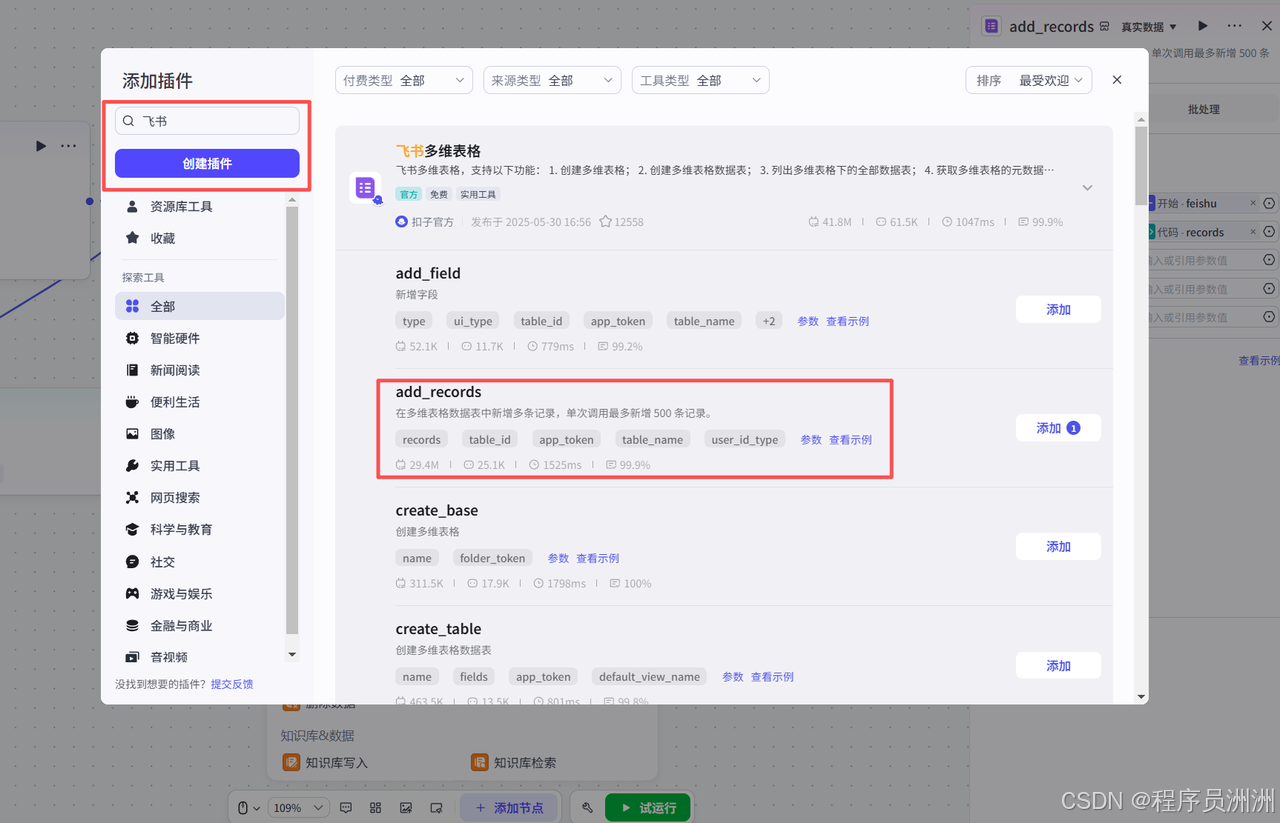
最后我们把结束节点配置一下,工作流就搭建好了!最终的链路效果如下所示~总结一下链路:
- 触发:由 “开始” 节点接收对应输入数据(即触发信号),启动整个流程;
- 解析:通过 “ParseX” 节点对输入内容进行数据解析,完成信息提取;
- LLM 处理:解析结果传入 “大模型” 节点(这里我选用豆包1.5Pro版本),由大模型进行内容处理;
- 回写:大模型输出结果经 “代码” 节点处理后,通过 “add_records” 节点回写数据;
- 收尾:最终由 “结束” 节点完成流程闭环。
后续如果各位小伙伴想搭建Agent,只需要在Coze创建智能体Agent中把这个工作流链路配置给Agent即可~
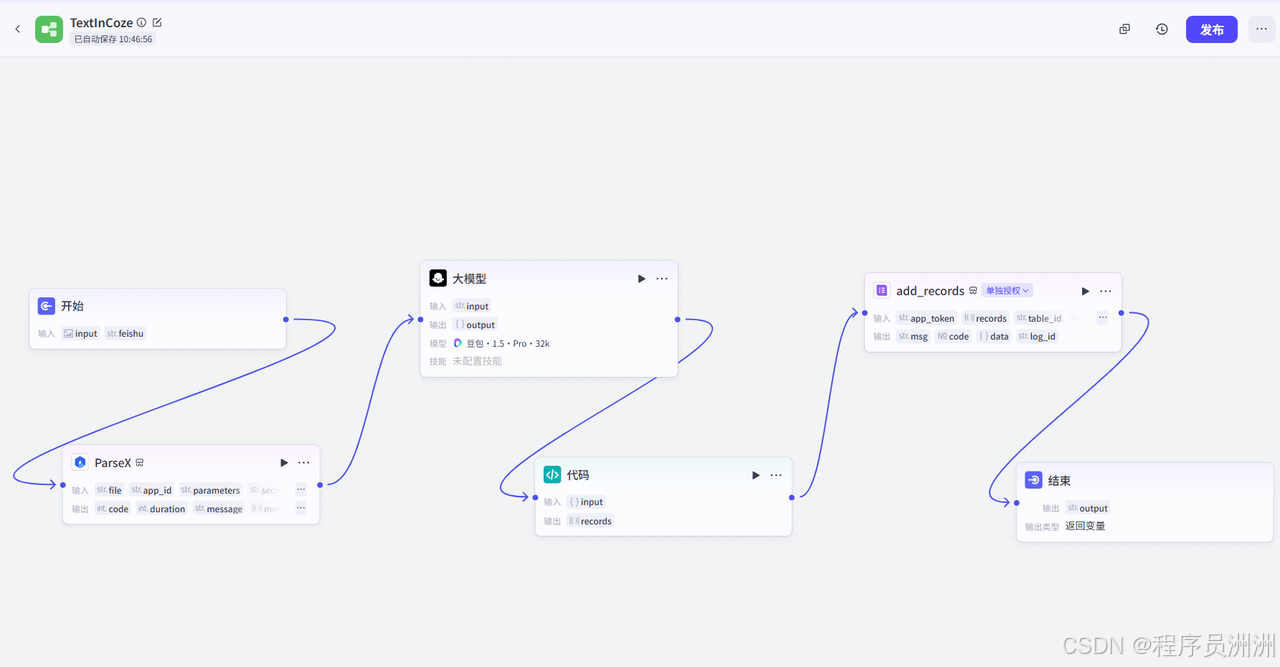
2.3 测试与优化:确保流程稳定高效
接下来我们测试整个工作流,看看是否能够运行通过。
首先在飞书文档创建对应的表格,创建需要的表格列,注意列名需要跟刚刚我们的飞书添加数据节点中的Python代码中的对应列名要对应上,比如下图所示。
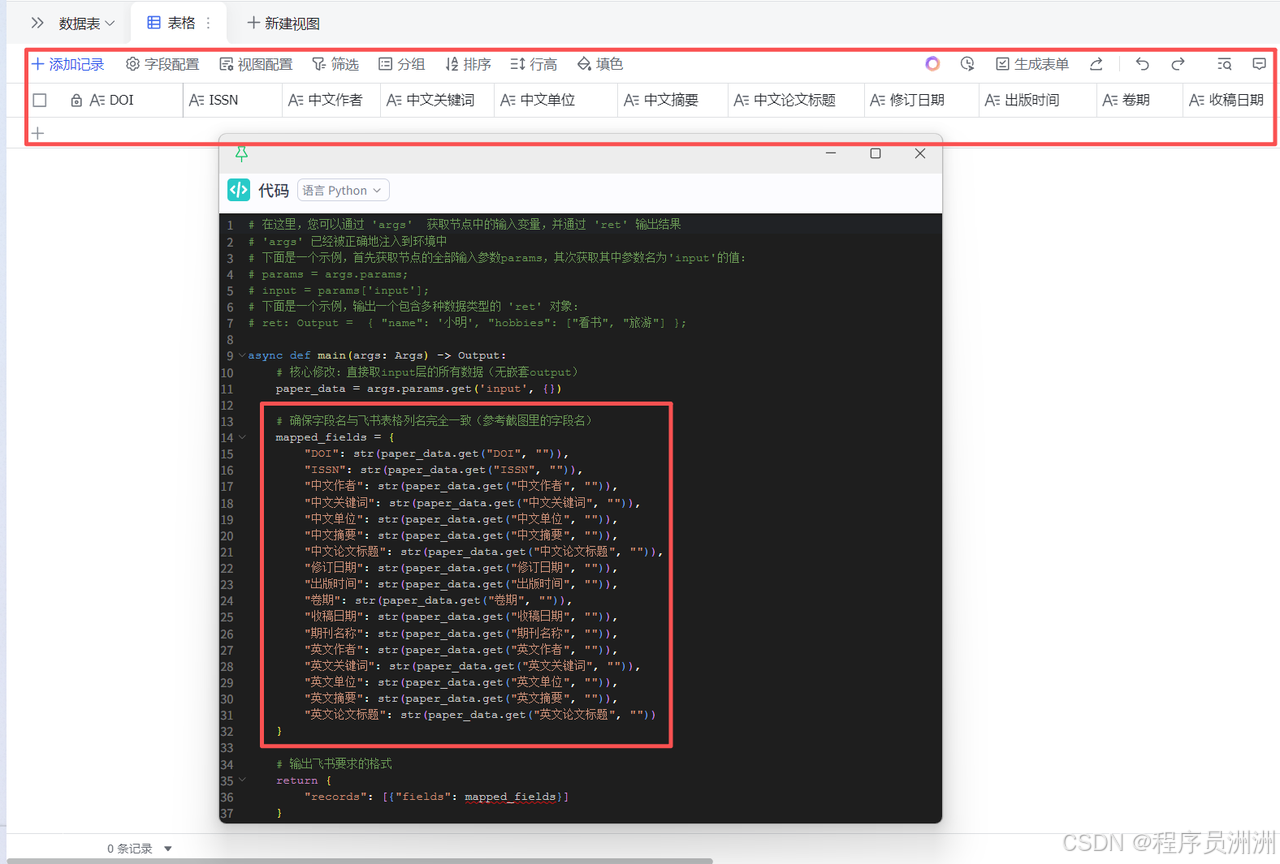
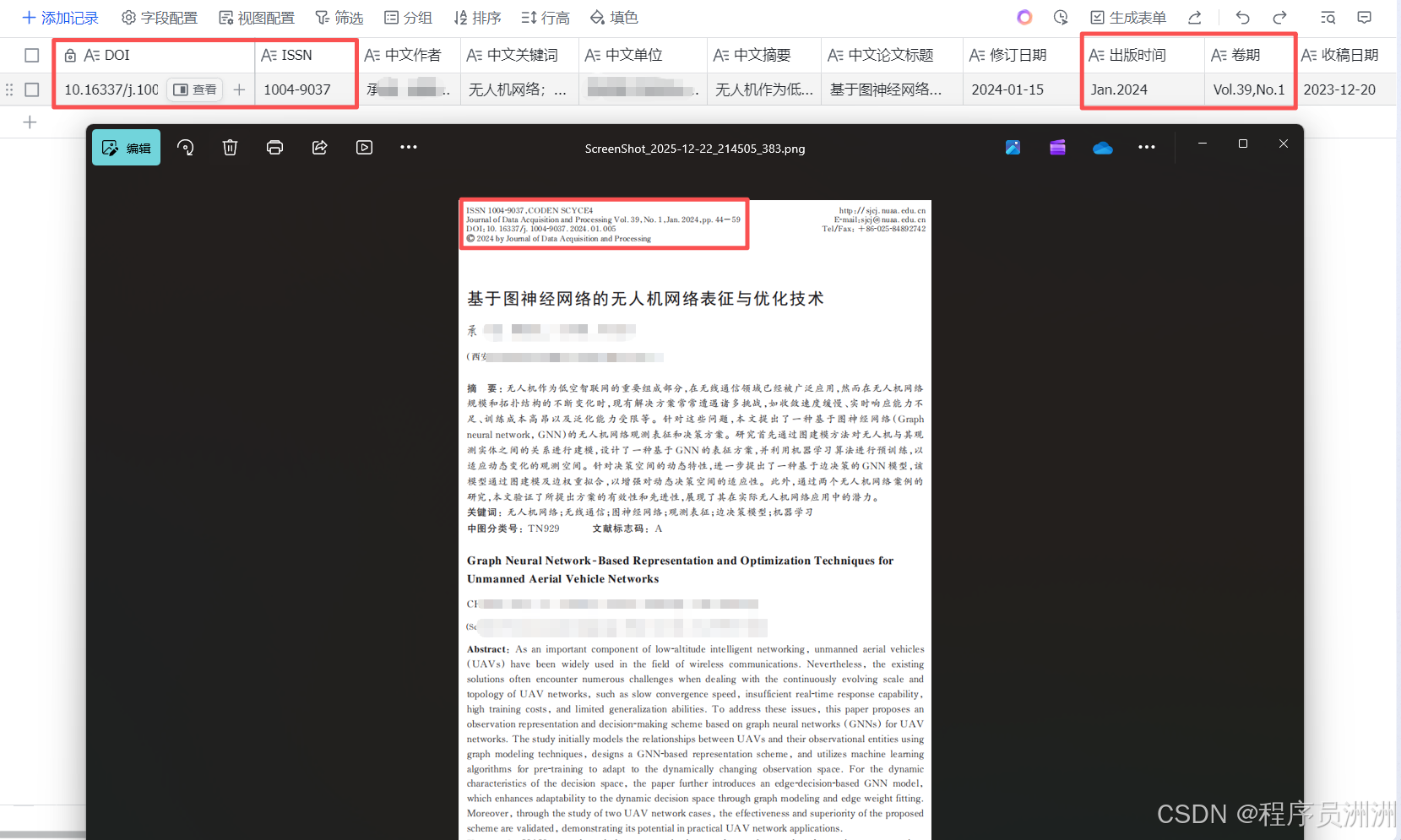
这里我选择了一篇论文作为工作流测试,选择这张图片作为输入测试,能从场景覆盖、功能验证、实用性三个维度充分检验工作流的可靠性,具体我觉得可以概括如下:
(1)覆盖了科研论文的典型复杂格式,验证ParseX适配性:
- 多元素排版适配:包含多栏布局、中英双语标题 / 作者 / 摘要、嵌套关键词列表、公式 / 缩写(如 GNN)等学术论文常见元素,能测试 TextIn 对复杂排版的解析精度;
- 多信息模块覆盖:同时包含期刊元数据(ISSN、DOI、卷期)、作者单位、收稿 / 修订日期等工作流需提取的全量字段,可一次性验证所有目标字段的提取完整性。
(2)验证工作流的核心能力与完整流程:
3. OCR 解析能力测试:图片包含印刷体、中英文混排、标点符号(分号、逗号)等,能检验 TextIn 对学术文本的字符识别准确率(避免乱码、错字);
4. 结构化提取能力验证:可验证大模型节点是否能准确区分 “中文标题 / 英文标题”“中文摘要 / 英文摘要” 等同类字段,避免信息混淆;
5. 端到端流程完整性:从图片解析→字段提取→飞书表格输出的全链路流程,能验证 Coze 工作流的插件串联、数据传递是否无断点。

接着我们点击开始节点,配置好飞书文档URL链接和图片之后,就可以点击试运行了!
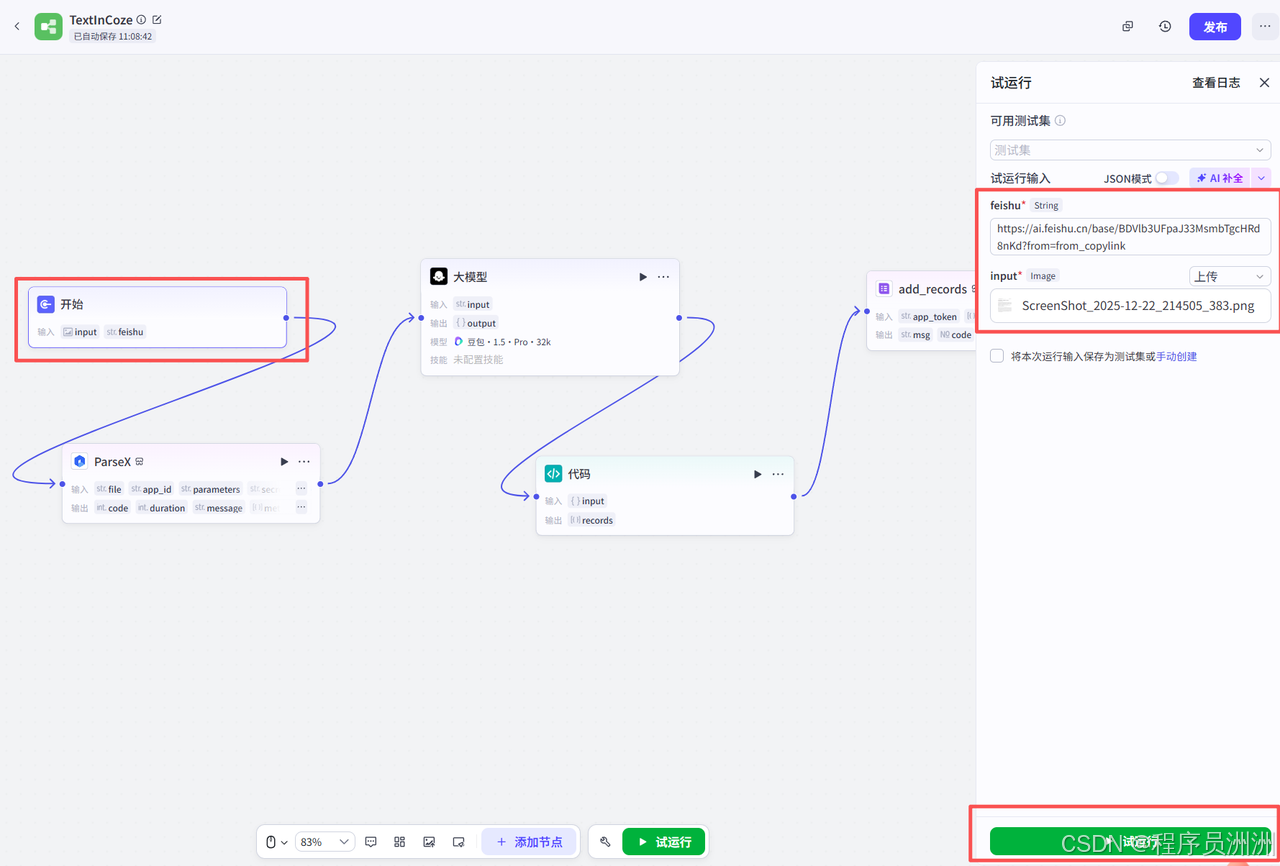
可以看到,整个过程大约5s左右就通过了整个流程,效率非常快,着实惊艳到我了,ParseX识别的数据也特别准确。后续找了其他论文多测了多次,大概发现P99处理耗时仅4.5s左右,效率可以说是远超传统OCR工具;同时从我个人的测试结果来看,ParseX的数据识别准确率是100%,单页处理成本也非常低,可以说从耗时、精度到成本的全维度优势,既刷新了流程效率的体验,也让这次自动化落地的效果着实惊艳。
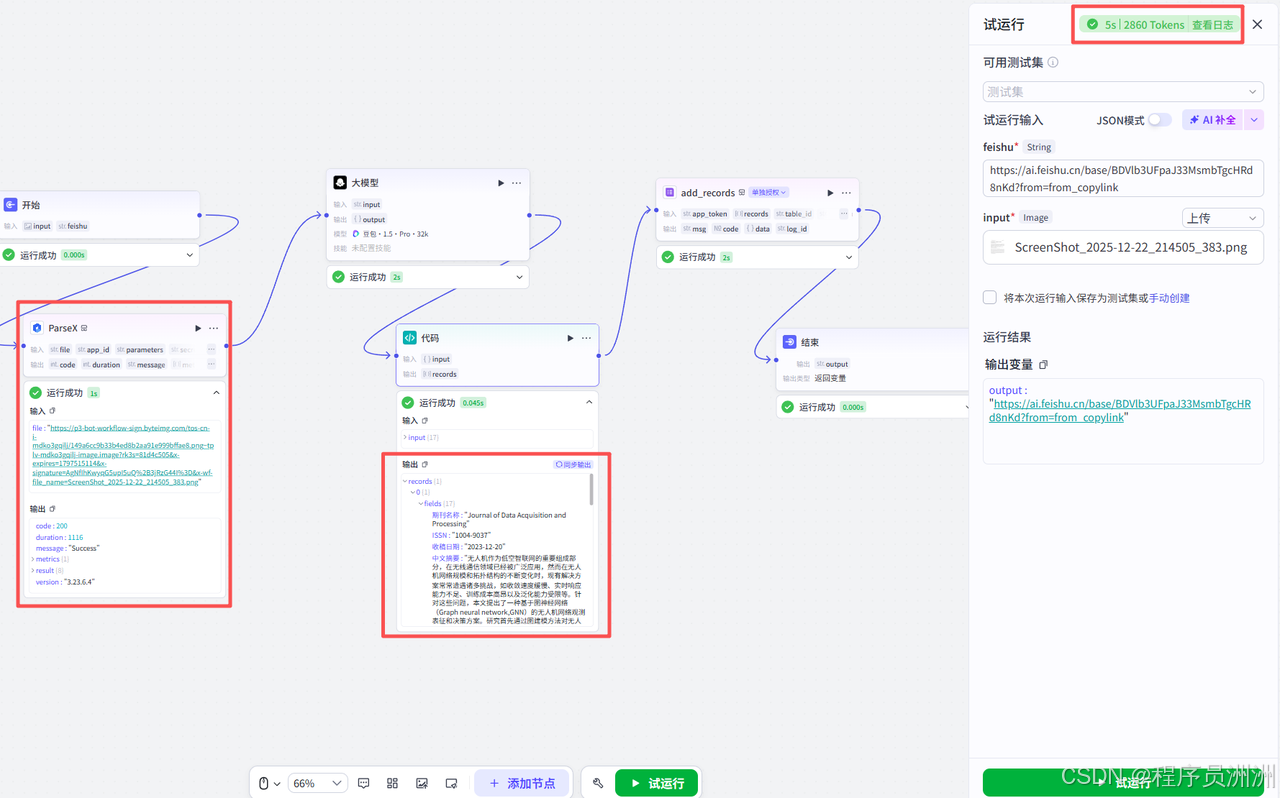
我们再打开飞书文档,就可以看到已经自动帮我们新增好对应的数据了。准确率我核对了一下,百分百正确,比如图中的左上角的很小的ISSN号,是完全能够对得上的,这一点也印证了ParseX的功能强大之处,而且效率很高,比人为手动的去挨个复制添加好很多。
四、场景价值:TextIn+Coze重新定义科研文献处理效率
对单枪匹马做研究的科研人而言,文献处理曾是绕不开的 “重复劳作”—— 从前处理一篇论文的基础信息,要先手动复制 PDF 内容、逐行录入关键词,整套流程至少耗费大几分钟。
而 TextIn+Coze 的工作流彻底重构了这个过程:从上传论文到提取完标题、摘要、关键词等核心信息,全程仅需5秒钟,效率直接提升几十倍。按每天处理10篇文献计算,原本要耗1-2小时的整理工作,现在差不多2分钟就能完成,这些精力足以用来打磨实验方案、深度分析数据,真正把重心放回科研创新本身。
总结:AI 驱动科研工作流的未来方向
总的来说,我觉得这套工作流的核心价值是TextIn的高精度解析补上了科研数据 “输入质量” 的短板,Coze 低代码能力拉低了自动化的上手门槛,飞书表格则打通了数据 “输出协同” 的环节 —— 三者形成完整闭环,让科研文献处理的效率被重新定义。
现在随着大模型与垂直工具的深度绑定,正在让科研工作流跳出 “多工具拼接” 的零散模式,转向 “全链路自动化”;未来更多重复劳动会被 AI 接管,科研人员终于能把精力集中在核心创新上。
当前 TextIn 提供 3000 页免费解析服务,点击下方链接即可获取专属体验,感兴趣的小伙伴可以来试试!快速搭建你的专属论文处理工作流,开启科研效率升级之路~
产品注册体验链接:https://www.textin.com/register/code/KKBKQ6,注册即送TextIn平台3000页体验

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)