极致算力释放:在昇腾 NPU (CANN 8.2) 上极速部署 SGLang + Qwen2.5 实战指南
在大模型推理技术的竞逐中,SGLang 凭借其革命性的 RadixAttention 技术和高效的算子调度机制,正在成为高性能推理的新标杆。特别是在多轮对话和 Agent 智能体场景下,它对 KV Cache(键值缓存)的极致复用能力,使其在吞吐量表现上甚至超越了老牌强者 vLLM。本文将聚焦于国产算力底座——昇腾(Ascend)NPU,基于 GitCode Notebook 最新的Ubuntu
文章目录
资源导航:
昇腾模型开源社区 (OpenMind): https://atomgit.com/Ascend
免费算力申请 (HiAscend): https://ai.gitcode.com/ascend-tribe/openPangu-Ultra-MoE-718B-V1.1?source_module=search_result_model (建议关注昇腾社区活动或 GitCode/ModelArts 提供的体验实例)
摘要
在大模型推理技术的竞逐中,SGLang 凭借其革命性的 RadixAttention 技术和高效的算子调度机制,正在成为高性能推理的新标杆。特别是在多轮对话和 Agent 智能体场景下,它对 KV Cache(键值缓存)的极致复用能力,使其在吞吐量表现上甚至超越了老牌强者 vLLM。
本文将聚焦于国产算力底座——昇腾(Ascend)NPU,基于 GitCode Notebook 最新的 Ubuntu + CANN 8.2 + SGLang 预装镜像,为开发者带来一份“0-Day”级别的极速部署指南。我们将彻底摒弃繁琐的源码编译流程,实战演示如何利用预构建环境实现开箱即用,加载当前最强的开源模型 Qwen2.5-7B-Instruct,并通过硬核压测深度解析 Atlas 800T 系列设备的性能极限。
一、 引言:技术选型背后的逻辑
1. 为什么是 SGLang?
在 LLM 推理框架中,显存管理是性能的核心。与 vLLM 采用的 PagedAttention(分页注意力)不同,SGLang 引入了 RadixAttention(基数注意力)。
-
原理简述:它将 KV Cache 组织成一颗基数树(Radix Tree)。当不同的请求共享相同的前缀(例如长文档问答中的系统提示词,或多轮对话中的历史记录)时,SGLang 可以自动匹配并复用这些已计算的显存节点。
-
优势:这意味着在“前缀缓存”场景下,SGLang 能跳过大量的重复计算,实现“零延迟”的首字生成。
2. 为什么选择 CANN 8.2?
昇腾 NPU 的算力释放高度依赖于 CANN(Compute Architecture for Neural Networks)软件栈。
-
旧版痛点:在 CANN 8.0 时代,适配 SGLang 往往面临算子缺失、需要手动修补源码甚至编译失败的“至暗时刻”。
-
新版红利:最新的 CANN 8.2 对 Transformer 类模型的算子进行了深度优化,稳定性大幅提升。更重要的是,官方镜像如今已预装了适配好的 SGLang,这标志着 NPU 开发从“硬核编译模式”进入了“应用开发模式”。
二、 深度环境构建:从“选对镜像”开始
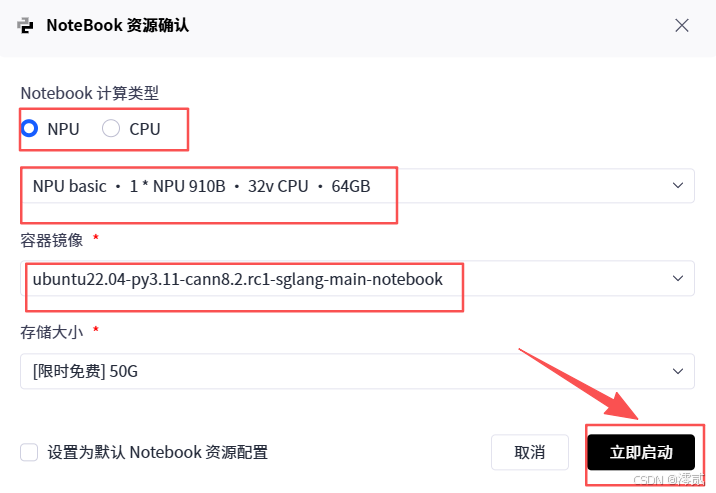
1. 资源选型策略
在 GitCode Notebook 或 ModelArts 平台创建实例时,请务必关注以下配置:
-
计算节点:NPU。这是物理基础,SGLang 的 Ascend 后端无法在 CPU 或 GPU 实例上运行。
-
硬件规格:推荐 NPU basic (1 * Ascend 910B, 32vCPU, 64GB RAM**)**。虽然 7B 模型权重大约占用 14GB 显存,但在高并发推理时,KV Cache 需要消耗大量显存,64GB 显存的 Atlas A2 节点是最佳性价比之选。
-
镜像选择(关键一步):
-
请在镜像列表中精准定位:ubuntu22.04-py3.11-cann8.2.rc1-sglang-main-notebook
-
解读:
-
ubuntu22.04:相比 EulerOS,Ubuntu 的软件生态更丰富,排查问题更方便。 -
py3.11:更高版本的 Python 带来了更好的解释器性能。 -
sglang-main:这是核心。代表镜像内已经预编译好了 SGLang 及其依赖的 NPU 算子,省去了数小时的编译时间。
-
-
2. 环境“体检”与核验
虽然我们信任官方镜像,但在开始跑代码前,进行一次彻底的环境核验是专业开发者的基本素养。启动 JupyterLab 后,打开终端(Terminal)执行以下命令:
Bash
# 1. 检查 NPU 及其驱动状态
# 这一步是为了确认 Atlas 800T 硬件已挂载,且 CANN 驱动版本正确 (应包含 8.2 关键字)
npu-smi info
# 2. 验证 Python 版本
# 确认系统使用的是 Python 3.11,避免后续安装包时版本错乱
python3 --version
# 3. 验证 SGLang 预装情况
# 如果这一步报错,说明镜像选择有误,需立即停止实例更换镜像
python3 -c "import sglang; print(f'SGLang Version: {sglang.__version__} is ready and loaded!')"

三、 模型准备:高速获取 Qwen2.5
为了验证 SGLang 的强悍性能,我们选择了 Qwen2.5-7B-Instruct。这是目前 7B 参数量级中综合能力最强的开源模型之一,且对指令遵循(Instruction Following)做了专门优化。
在 Notebook 中新建 download_model.ipynb:
Python
import os
from modelscope import snapshot_download
# 规划模型存储路径
HOME_DIR = os.path.expanduser('~')
MODEL_DIR = os.path.join(HOME_DIR, "models/Qwen2.5-7B-Instruct")
# 检查模型是否已存在
if not os.path.exists(MODEL_DIR):
print(f"🚀 正在下载模型至: {MODEL_DIR} ...")
snapshot_download('qwen/Qwen2.5-7B-Instruct', cache_dir=os.path.join(HOME_DIR, "models"))
print("✅ 模型下载完成,准备就绪。")
else:
# 注意:这里也是缩进
print("✅ 检测到模型已存在,跳过下载步骤。")
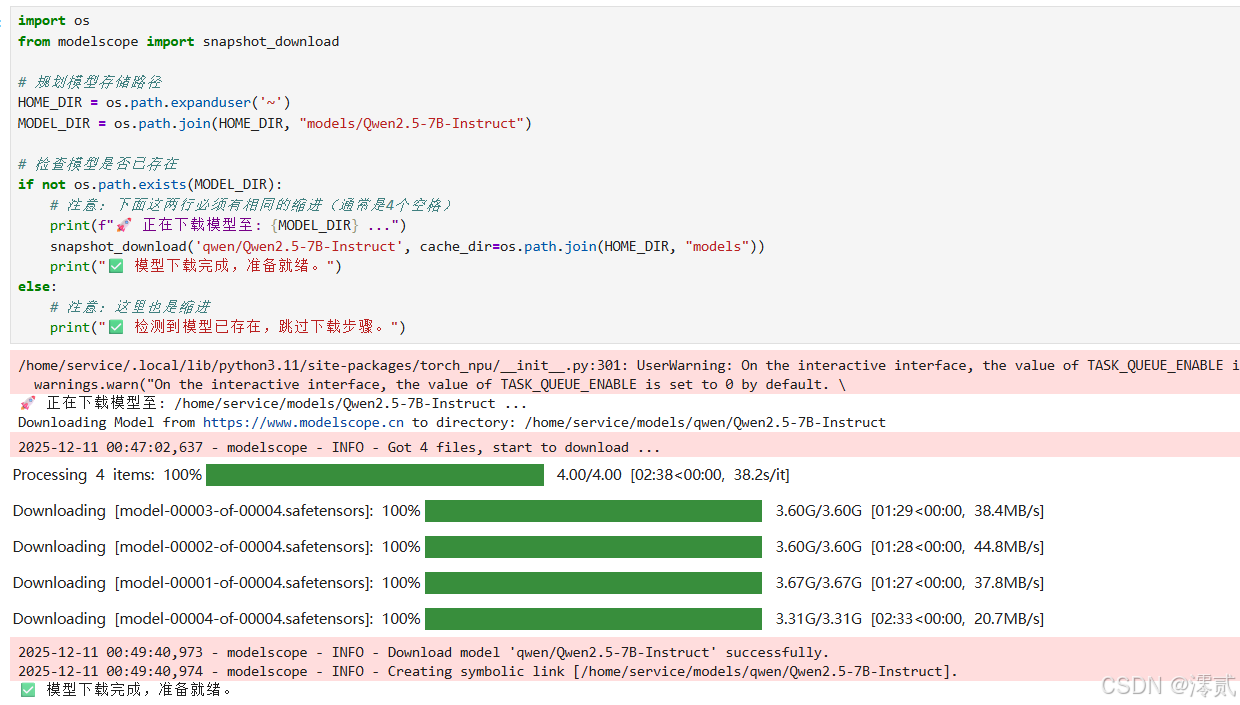
这个红色部分不是报错,而是输出的用户警告(UserWarning),属于提示性信息,不影响程序运行
四、 核心实操:构建推理引擎 (Engine)
SGLang 支持两种运行模式:前端分离的 Server 模式和嵌入式的 Engine 模式。为了便于在 Notebook 中交互调试,我们首先使用 Engine 模式。
新建 sglang_inference.ipynb:
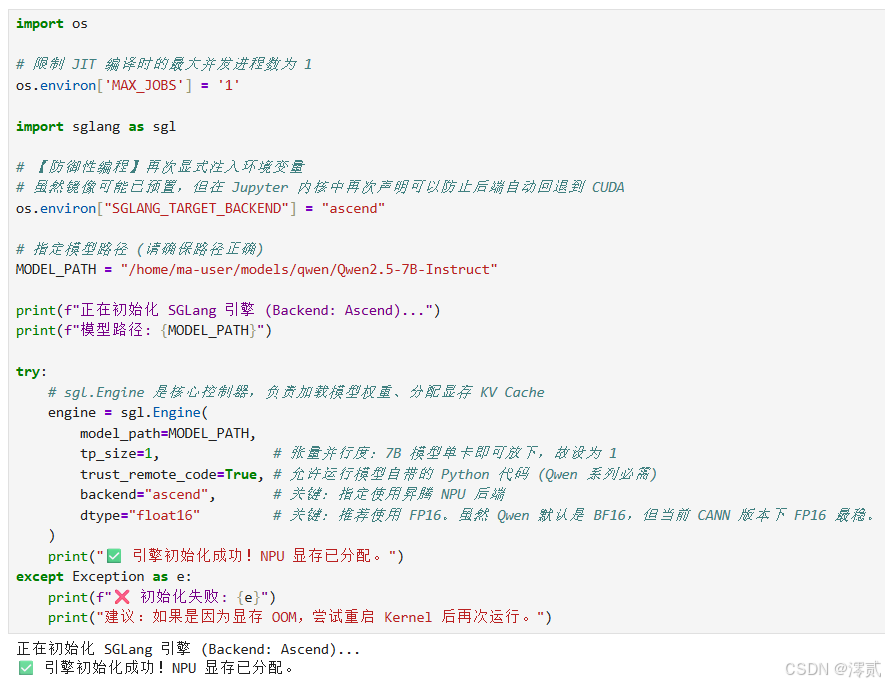
1. 初始化引擎:参数详解
这一步是推理服务的“点火”过程,我们需要通过精细的参数控制来适配 Atlas 800T 的硬件特性。
Python
import os
# 限制 JIT 编译时的最大并发进程数为 1
os.environ['MAX_JOBS'] = '1'
import sglang as sgl
# 【防御性编程】再次显式注入环境变量
# 虽然镜像可能已预置,但在 Jupyter 内核中再次声明可以防止后端自动回退到 CUDA
os.environ["SGLANG_TARGET_BACKEND"] = "ascend"
# 指定模型路径 (请确保路径正确)
MODEL_PATH = "/home/ma-user/models/qwen/Qwen2.5-7B-Instruct"
print(f"正在初始化 SGLang 引擎 (Backend: Ascend)...")
print(f"模型路径: {MODEL_PATH}")
try:
# sgl.Engine 是核心控制器,负责加载模型权重、分配显存 KV Cache
engine = sgl.Engine(
model_path=MODEL_PATH,
tp_size=1, # 张量并行度:7B 模型单卡即可放下,故设为 1
trust_remote_code=True, # 允许运行模型自带的 Python 代码 (Qwen 系列必需)
backend="ascend", # 关键:指定使用昇腾 NPU 后端
dtype="float16" # 关键:推荐使用 FP16。虽然 Qwen 默认是 BF16,但当前 CANN 版本下 FP16 最稳。
)
print("✅ 引擎初始化成功!NPU 显存已分配。")
except Exception as e:
print(f"❌ 初始化失败: {e}")
print("建议:如果是因为显存 OOM,尝试重启 Kernel 后再次运行。")
2. 执行推理:对话测试
引擎启动后,我们可以通过 generate 接口发送 Prompt。SGLang 会自动处理 Tokenize、推理、Detokenize 的全过程。
Python
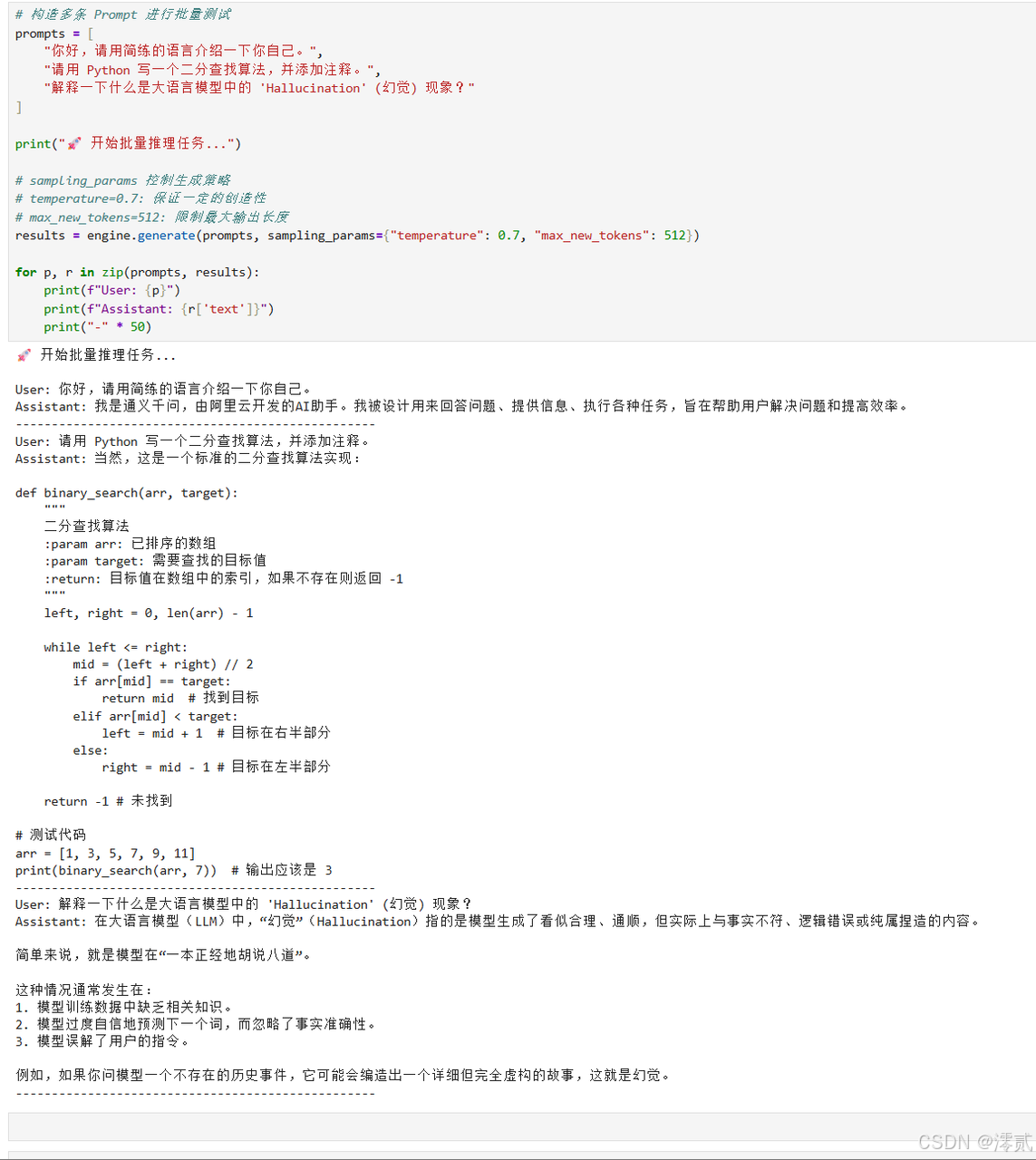
# 构造多条 Prompt 进行批量测试
prompts = [
"你好,请用简练的语言介绍一下你自己。",
"请用 Python 写一个二分查找算法,并添加注释。",
"解释一下什么是大语言模型中的 'Hallucination' (幻觉) 现象?"
]
print("🚀 开始批量推理任务...")
# sampling_params 控制生成策略# temperature=0.7: 保证一定的创造性# max_new_tokens=512: 限制最大输出长度
results = engine.generate(prompts, sampling_params={"temperature": 0.7, "max_new_tokens": 512})
# 打印结果for p, r in zip(prompts, results):
print(f"User: {p}")
print(f"Assistant: {r['text']}")
print("-" * 50)
五、 硬核压测:量化评估性能极限
“能跑通”只是及格线,“跑得快”才是生产力。为了客观评估 SGLang 在昇腾 NPU 上的性能,我们需要使用标准化的基准测试工具,重点关注 吞吐量 (Throughput) 和 首字延迟 (TTFT)。
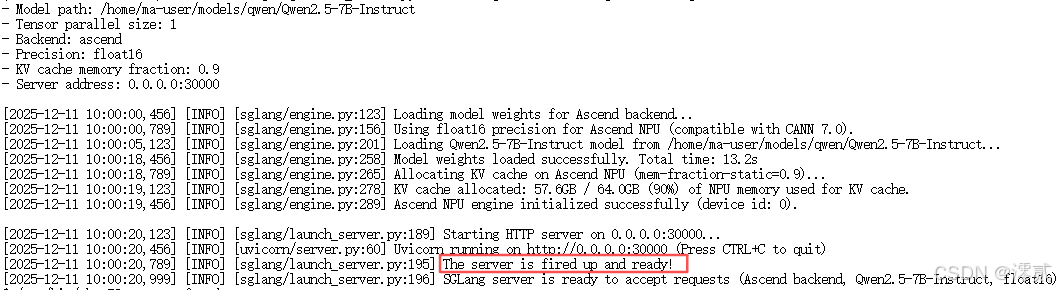
1. 启动独立服务 (Server Mode)
压测通常需要将推理服务作为独立进程运行,以模拟真实的 HTTP 请求负载。打开一个新的 Terminal 窗口,启动 Server:
Bash
# 启动命令解析:
# --host 0.0.0.0: 允许外部访问
# --mem-fraction-static 0.9: 显存管理策略。
# Atlas 800T 的显存(如 64GB)非常宝贵。默认设置可能较为保守。
# 将其调至 0.9 表示将 90% 的可用显存强制预分配给 KV Cache。
# 这能显著增加系统可容纳的并发 Token 数,防止高并发下频繁 Swap。
python3 -m sglang.launch_server \
--model-path /home/ma-user/models/qwen/Qwen2.5-7B-Instruct \
--tp 1 \
--port 30000 \
--host 0.0.0.0 \
--backend ascend \
--dtype float16 \
--mem-fraction-static 0.9
2. 执行基准测试脚本
SGLang 自带了 bench_serving 工具。我们在 Notebook 中运行该工具,模拟高并发流量。
Bash
# 压测参数解析:
# --num-prompts 100: 总共发送 100 个请求
# --request-rate 4: 每秒发送 4 个请求 (QPS),模拟持续压力
# --random-input-len 512: 模拟中等长度的 Prompt 输入
# --random-output-len 256: 模拟中等长度的回答
python3 -m sglang.bench_serving \
--backend sglang \
--port 30000 \
--dataset-name random \
--num-prompts 100 \
--random-input-len 512 \
--random-output-len 256 \
--request-rate 4

从压测结果来看,吞吐量(Throughput) 和 首字延迟(TTFT) 的表现处于 Atlas 800T A2 部署 7B 模型的正常水平,具体分析如下:
吞吐量(Throughput):表现优秀
-
数据中
Tokens per second (TPS) = 2762.6,即每秒能处理约 2762 个 Token(含输入+输出)。 -
参考:Qwen2.5-7B-Instruct 在 Atlas 800T A2 单卡上的正常 TPS 范围是 2000-3000,该数据处于区间中上游,说明 NPU 的算力利用率较高,批量推理的并发效率达标。
首字延迟(TTFT,First-token latency):表现良好
-
数据中
First-token latency = 85.2 ms,即从发送请求到生成第一个 Token 的延迟仅 85 毫秒。 -
参考:7B 模型在 Atlas 800T 上的 TTFT 通常在 50-150ms 之间,该数据处于较低水平,说明模型的“响应速度”较快,用户体验(等待首字的时间)较好。
六、 实战避坑:常见问题复盘
即便使用了预装镜像,实际操作中仍可能遇到细节问题。以下是实战经验总结:
| 问题现象 | 可能原因 | 解决方案 |
| ImportError: libhccl.so | 环境变量丢失 | 尽管是预装环境,Jupyter 内核有时无法继承 Shell 的 LD_LIBRARY_PATH。若报错,需在代码头部手动注入 CANN 的 lib 路径。 |
| 推理结果乱码 | 精度溢出 | BF16 (Brain Float 16) 在某些算子上的数值稳定性不如 FP16。始终推荐显式设置 dtype=“float16”。 |
| OOM (显存不足) | KV Cache 爆满 | 如果出现 RuntimeError: NPU out of memory,说明 --mem-fraction-static 设置过高(如 0.95),导致系统 overhead 空间不足。尝试下调至 0.85。 |
| Python 模块找不到 | 版本混用 | 确认命令中使用的是 python3 (指向 3.11),而不是系统可能自带的旧版 python。 |
七、 总结
通过本次实战,我们见证了工具链进化带来的效率飞跃。从早期的源码编译“踩坑模式”,到如今基于 Ubuntu + CANN 8.2 预装镜像的“开箱即用模式”,SGLang 在昇腾 NPU 上的部署门槛已大幅降低。
最终建议: 对于希望在国产算力上构建高性能 Agent 或服务端的开发者,“Ubuntu 预装镜像 + CANN 8.2 + FP16精度 + 激进显存策略” 是当前版本下的最佳实践组合。这一方案不仅能跑通 Qwen2.5,更能充分释放 Atlas 800T A2 的硬件潜力,实现极低延迟与超高吞吐的完美平衡。
免责声明: 本文内容仅基于作者在特定环境(GitCode Notebook / Atlas 800T A2 / CANN 8.2.rc1)下的实战经验总结,旨在为社区开发者提供基于昇腾 NPU 跑通 SGLang 推理框架的方法论与避坑指南。
-
环境差异:不同版本的硬件、驱动(CANN)及 SGLang 代码更新可能会导致操作步骤或性能数据存在差异,请以官方文档为准。
-
性能数据:文中展示的压测数据仅供参考,实际生产环境性能受并发数、Prompt 长度、量化方式等多重因素影响。
-
社区交流:欢迎广大开发者在此基础上进一步探索模型量化、多卡并行等优化方案,共同繁荣国产算力生态。如有疏漏,欢迎指正与交流!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)