【LocalAI】 本地部署图文教程(Windows + GPU + 多模态模型)
返回首页,刷新,我们就可以选择刚才下载好的这个模型,并且,我们上传一个图像,然后附上文字,描述图片。服装:猫咪穿着一套完整的灰色老鼠造型连体衣,设计非常逼真: 头部:帽子部分有两只大大的、圆形的米色耳朵,耳朵内侧是浅粉色,造型非常卡通。身体:衣服的腹部部分是米色的,中间有一条浅色的横向条纹,下方是白色的“肚兜”部分,后背还有一个白色的蝴蝶结装饰。背景与环境:猫咪坐在一个灰色的毛绒地毯上,背景是素净
第一部分:核心概念
- Docker镜像:可以理解为软件的“安装包”或“模板”。例如,
localai/localai:latest-gpu-nvidia-cuda-12就是一个包含了LocalAI所有运行环境的镜像。 - Docker容器:是“镜像”运行起来的实例。你可以把一个容器看作一个轻量级、独立的虚拟机,你的LocalAI服务就在这里面运行。
简单来说:下载镜像 -> 从镜像创建并运行容器 -> 访问容器内的服务。
第二部分:Windows实战部署LocalAI
请按照以下步骤操作。
步骤 1:安装Docker Desktop for Windows
参考文章:Windows安装doker教程
步骤 2:拉取并运行LocalAI容器
这是最关键的一步。请注意,在Windows PowerShell中,命令不需要加 sudo。
-
打开PowerShell:以管理员身份运行Windows PowerShell。
-
运行GPU容器:你拥有NVIDIA GPU且需要GPU推理,因此运行以下命令。注意挂载路径是
/build/models,这是很多教程中未提及的关键点。docker run -d --name local-ai -p 8080:8080 --gpus all -v D:\LocalAI\Models:/build/models localai/localai:latest-aio-gpu-nvidia-cuda-12命令解读:
-d:后台运行容器。--name local-ai:给容器起名,便于管理。-p 8080:8080:将本机的8080端口映射到容器的8080端口。--gpus all:将主机的所有GPU分配给容器使用(需要NVIDIA显卡及驱动)。-v D:\LocalAI\Models:/build/models:将本地目录D:\LocalAI\Models挂载到容器内的/build/models路径。这是存放模型文件的地方。localai/localai:latest-aio-gpu-nvidia-cuda-12:使用的GPU版本镜像。
-
验证运行:运行
docker ps,如果看到名为local-ai的容器状态为Up,说明启动成功。
步骤 3:下载并配置多模态大模型
我来帮你把第三部分补充完整,并结合你上传的图片内容和之前的描述,让整个流程更清晰易懂。
第三部分:下载并配置多模态大模型
在 Docker 容器成功运行后,你就可以在本机浏览器访问 LocalAI 的 Web 界面,来下载并加载多模态大模型(比如视觉语言模型)。下面详细说明操作步骤和可能遇到的问题。
3.1 访问 LocalAI Web 界面
- 打开浏览器,访问 http://localhost:8080/
- 或者点击容器中的PORT:8080/8080:
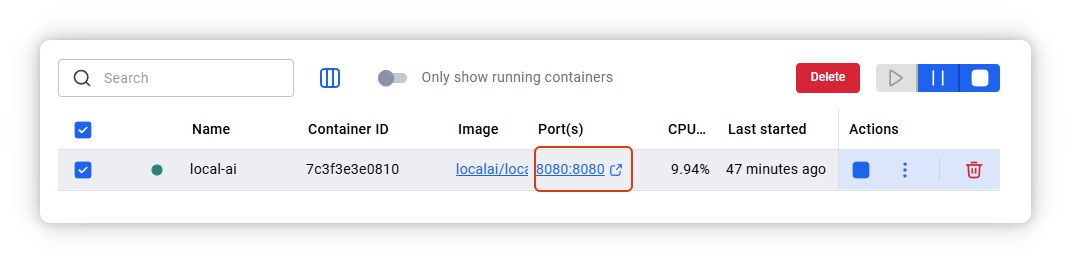
就会看到如下界面:
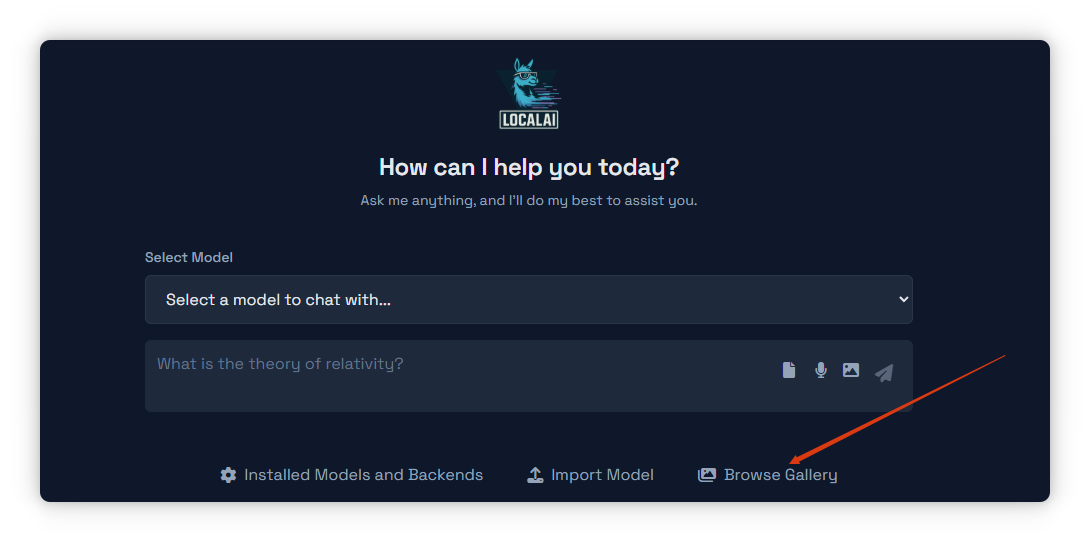
首次进入时,你会看到模型选择区,提示 Select a model to chat with…,右侧有文件、麦克风、图片、发送等图标。
界面下方有 Installed Models and Backends、Import Model、Browse Gallery 三个入口。
我们 点击 👉 Browse Gallery,去里面找模型。
3.2 在 Gallery 中搜索并下载模型
- 进入模型浏览界面:
- 顶部搜索框输入模型名称
qwen3-vl-4b-instruct或者其他模型。 - 下方有按类型过滤的按钮,确保 Vision 按钮为红色选中状态(因为这是一个视觉语言多模态模型)。
- 顶部搜索框输入模型名称
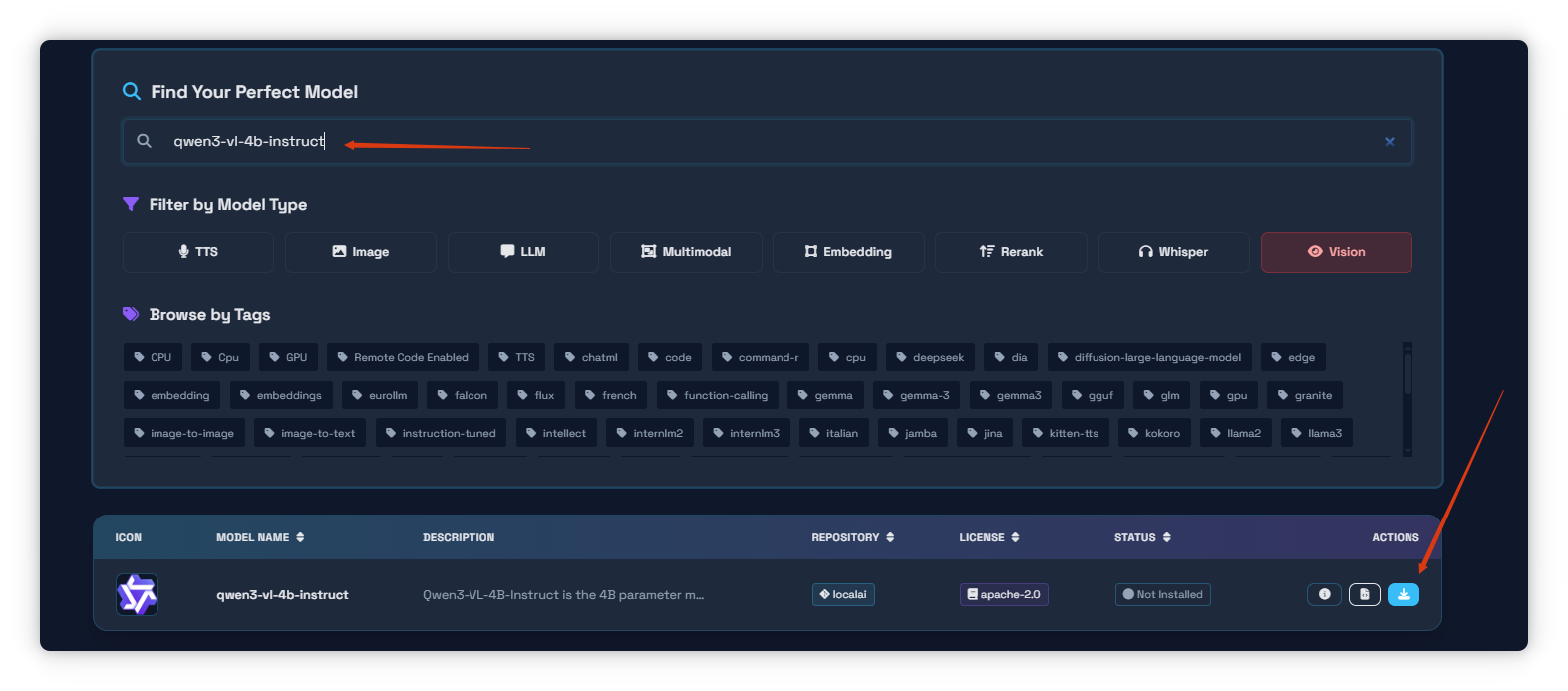 - 列表中会显示模型信息:
- 列表中会显示模型信息:
- Model Name: qwen3-vl-4b-instruct
- Description: Qwen3-VL-4B-Instruct is the 4B parameter …
- Repository: localai
- License: apache-2.0
- Status: Not Installed
- Actions: 提供下载/安装按钮
2. 点击 Install/Download 按钮开始安装模型。
3.3 处理安装失败的情况
需要科学上网,就会看到:
如果在下载过程中出现错误提示:
Error installing model "qwen3-vl-4b-instruct":
Get "https://raw.githubusercontent.com/mudler/LocalAI/master/gallery/qwen3.yaml": unexpected EOF

- 原因分析:
unexpected EOF表示在读取远程 YAML 配置文件时,网络连接中断或文件未完整下载,常见于 GitHub 原始文件链接在某些地区无法直接访问(需“科学上网”或稳定国际网络)。 - 解决方法:
- 开启可稳定访问 GitHub 的网络环境。
- 重新点击安装,等待模型下载完成。
下载成功后,模型状态会从 Not Installed 变为已安装,可在 Installed Models and Backends 中看到。
3.4 关于容器重启后访问延迟的解释
如果你不小心关闭或重启了 LocalAI 容器: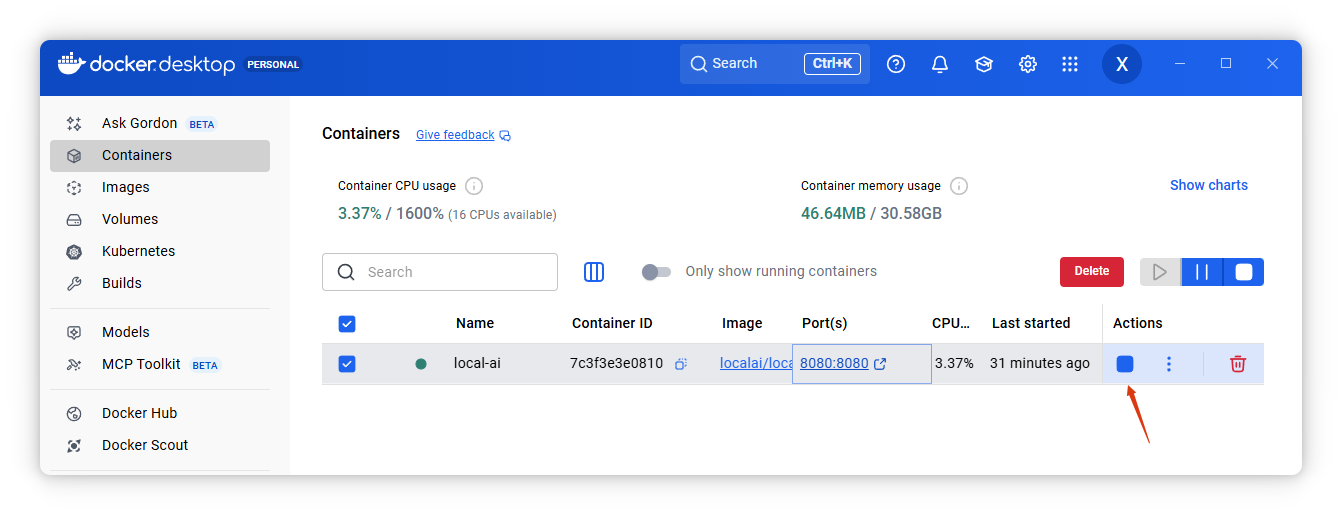
再次访问 http://localhost:8080/ 时可能会暂时出现 无法加载页面 的情况: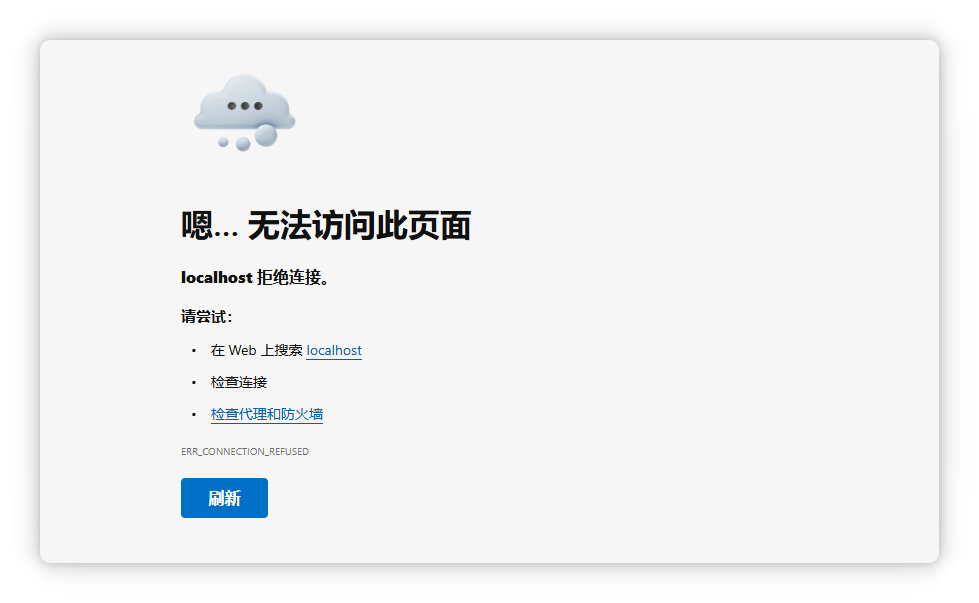
- 原因:
- 容器启动后,LocalAI 服务需要时间初始化(加载依赖、检查模型文件、启动后端服务等),通常需 几分钟。
- 在初始化完成前,Web 服务端口虽已映射,但应用本身并未完全就绪,因此浏览器会显示连接失败或超时。
- 建议:
启动容器后,先通过docker ps确认容器状态为 Up,再等待约 1–3 分钟,然后刷新页面即可正常访问。
第四部分:首页测试大模型
返回首页,刷新,我们就可以选择刚才下载好的这个模型,并且,我们上传一个图像,然后附上文字,描述图片。就会看到,已经在调用本地的GPU开始预测了。一会,就得到了文本输出。
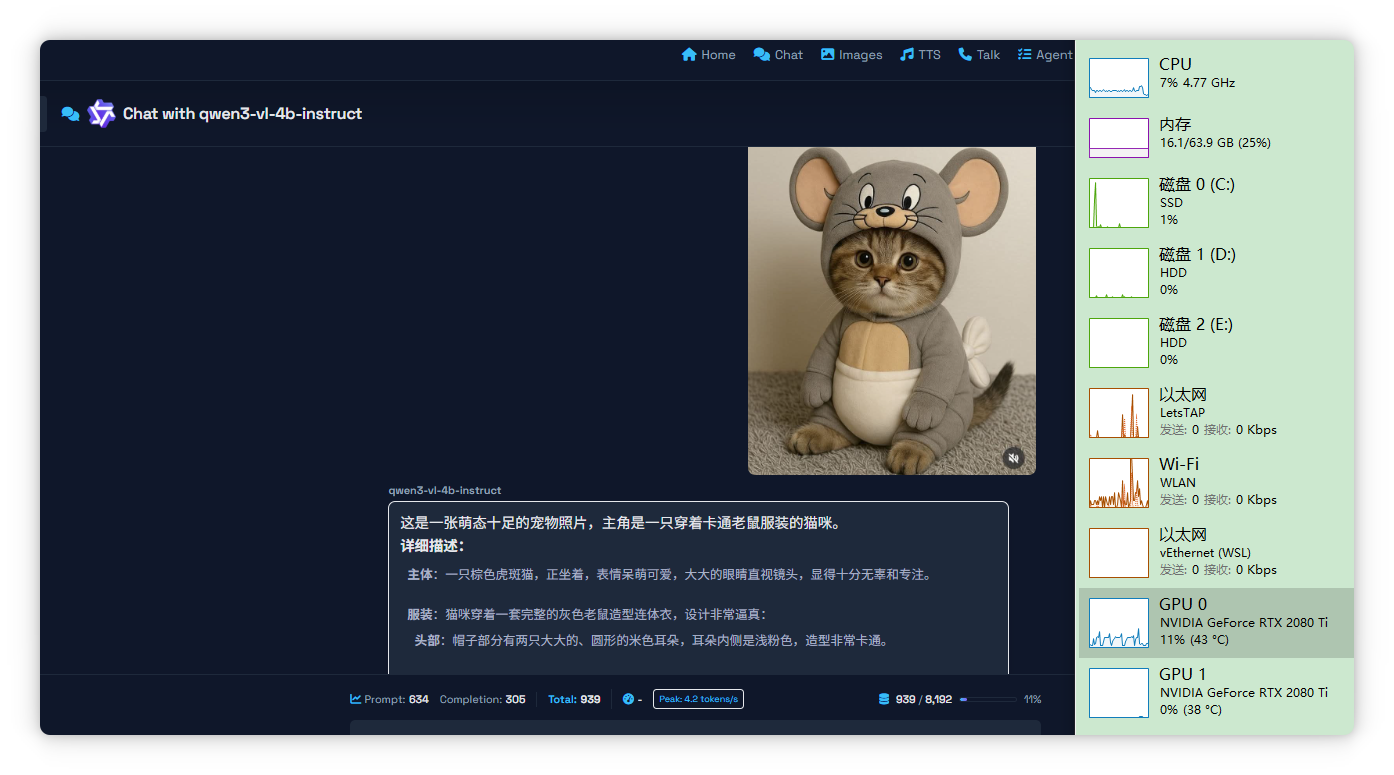
这是一张萌态十足的宠物照片,主角是一只穿着卡通老鼠服装的猫咪。 详细描述:
主体:一只棕色虎斑猫,正坐着,表情呆萌可爱,大大的眼睛直视镜头,显得十分无辜和专注。
服装:猫咪穿着一套完整的灰色老鼠造型连体衣,设计非常逼真: 头部:帽子部分有两只大大的、圆形的米色耳朵,耳朵内侧是浅粉色,造型非常卡通。
面部:帽子正面印有经典的卡通老鼠脸,包括黑色的大眼睛、黑色的瞳孔、一个黑色的小鼻子和几根胡须。
身体:衣服的腹部部分是米色的,中间有一条浅色的横向条纹,下方是白色的“肚兜”部分,后背还有一个白色的蝴蝶结装饰。
四肢:衣服覆盖了猫的四肢,前爪和后爪都清晰可见,爪子的毛色与身体协调。背景与环境:猫咪坐在一个灰色的毛绒地毯上,背景是素净的浅色墙壁,环境简洁,突出了猫咪本身。
整体风格:照片整体呈现出一种温馨、治愈、搞笑的风格,将猫咪的可爱与卡通形象完美结合,令人忍俊不禁。这张照片非常适合作为社交媒体的分享图,展现了宠物的创意造型和萌宠魅力。
第五部分:Python 调用多模态模型
下面,我们给出在 PyCharm 中调用本地 LocalAI 多模态模型(如 qwen3-vl-4b-instruct)的完整示例,支持传入图像+文本并获取模型输出。
一、前置检查
- 确保 LocalAI 容器已启动并可在浏览器打开 http://localhost:8080/,且模型 qwen3-vl-4b-instruct 处于 Installed 状态。
- 在 PowerShell 中确认容器运行正常:
docker ps - 如需 GPU 加速,确认本机 NVIDIA 驱动 + Docker GPU 支持 正常;容器内执行
nvidia-smi可验证(进入容器:docker exec -it local-ai bash)。
二、安装依赖
在 PyCharm 新建项目后,安装所需 Python 包(建议使用虚拟环境):
uv pip install -U openai requests pillow
说明:
- openai:使用与 OpenAI 兼容的接口调用 LocalAI。
- requests:兜底用,直接调用 REST 接口。
- pillow:读取本地图片并转为 Base64。
三、方案一 OpenAI 兼容客户端调用(推荐)
新建文件:client_openai.py
import base64
import time
from pathlib import Path
import openai
# 1) 配置指向本地 LocalAI(与 OpenAI 兼容)
client = openai.OpenAI(
base_url="http://127.0.0.1:8080/v1", # LocalAI 默认 OpenAI 兼容端口
api_key="EMPTY", # 本地无需密钥
)
def image_to_base64(image_path: str) -> str:
data = Path(image_path).read_bytes()
return base64.b64encode(data).decode("utf-8")
def chat_with_vision(
model: str,
image_path: str,
prompt: str,
temperature: float = 0.2,
max_tokens: int = 1024,
):
b64_img = image_to_base64(image_path)
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{b64_img}"},
},
],
}
]
start = time.time()
resp = client.chat.completions.create(
model=model,
messages=messages,
temperature=temperature,
max_tokens=max_tokens,
)
elapsed = time.time() - start
print(f"【Prompt tokens】{resp.usage.prompt_tokens}")
print(f"【Completion tokens】{resp.usage.completion_tokens}")
print(f"【Elapsed】{elapsed:.2f}s")
print("【Response】", resp.choices[0].message.content.strip())
if __name__ == "__main__":
# 注意:这里填写你在 Gallery 中安装后的实际模型名称
MODEL_NAME = "qwen3-vl-4b-instruct"
chat_with_vision(
model=MODEL_NAME,
image_path="assets/demo.jpg", # 请替换为你的图片路径
prompt="请用中文详细描述这张图片,并指出图中主要物体的位置、颜色和动作。",
temperature=0.2,
max_tokens=1024,
)
使用要点:
- 将 MODEL_NAME 替换为你 Gallery 中已安装的模型名(可在页面 Installed Models and Backends 查看)。
- 图片支持 JPEG/PNG 等常见格式;大图可先压缩以提升上传与推理速度。
- 若显存较小,可适当降低 max_tokens 或改用更轻量模型。
四、方案二 直接 REST 调用(requests)
新建文件:client_rest.py
import base64
import time
from pathlib import Path
import requests
API_BASE = "http://127.0.0.1:8080/v1"
API_KEY = "EMPTY" # 本地通常为 EMPTY
def image_to_base64(image_path: str) -> str:
data = Path(image_path).read_bytes()
return base64.b64encode(data).decode("utf-8")
def chat_with_vision_rest(
model: str,
image_path: str,
prompt: str,
temperature: float = 0.2,
max_tokens: int = 1024,
):
b64_img = image_to_base64(image_path)
payload = {
"model": model,
"messages": [
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{b64_img}"},
},
],
}
],
"temperature": temperature,
"max_tokens": max_tokens,
}
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}",
}
start = time.time()
r = requests.post(f"{API_BASE}/chat/completions", json=payload, headers=headers, timeout=120)
r.raise_for_status()
data = r.json()
elapsed = time.time() - start
print(f"【Elapsed】{elapsed:.2f}s")
print("【Response】", data["choices"][0]["message"]["content"].strip())
if __name__ == "__main__":
MODEL_NAME = "qwen3-vl-4b-instruct"
chat_with_vision_rest(
model=MODEL_NAME,
image_path="assets/demo.jpg",
prompt="请用中文详细描述这张图片。",
temperature=0.2,
max_tokens=1024,
)
运行后,就会看到如下输出: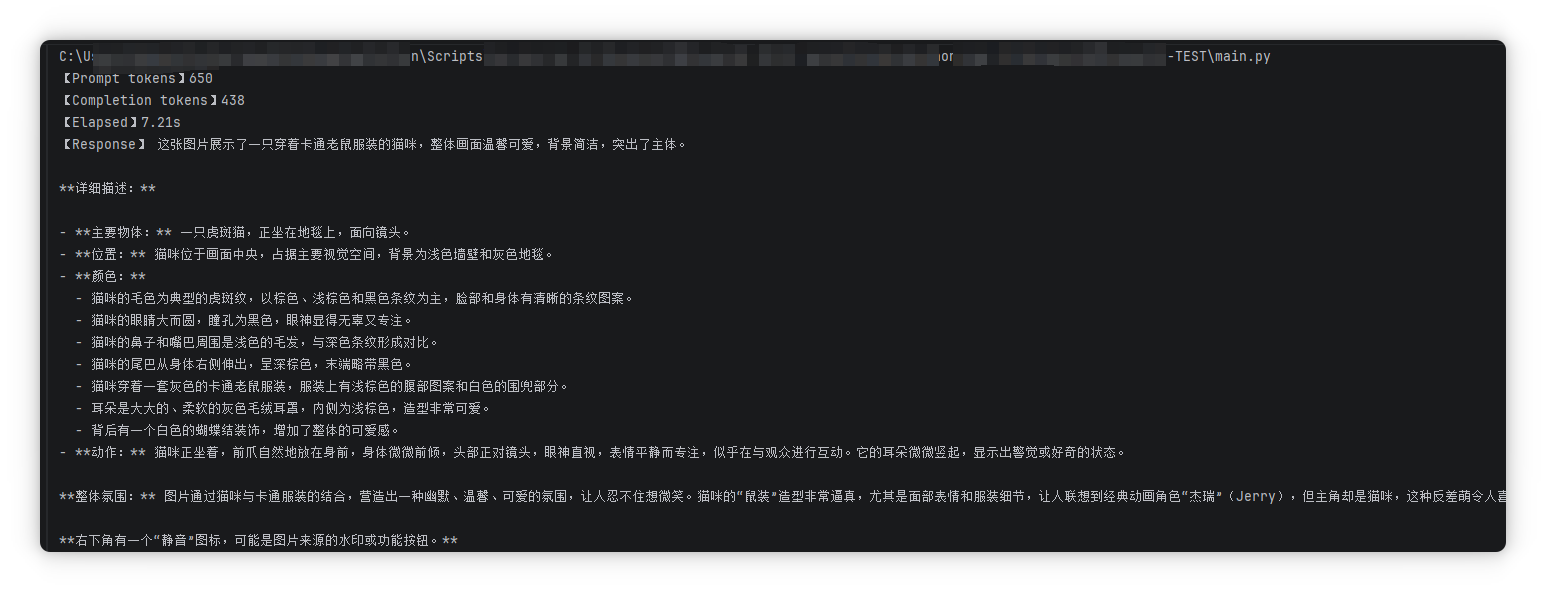

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)