拒绝复制粘贴!我用多 Agent 搭了个“全平台文章同步助手”(附架构源码)
写文章 1 小时,分发排版 2 小时?这是很多技术博主的噩梦。把一篇公众号文章同步到知乎、CSDN、头条,不仅要改格式(Markdown vs 富文本),还要改语气(专业 vs 通俗)。与其机械地复制粘贴,不如交给 AI。但简单的 ChatGPT 对话往往很难控制输出格式。今天分享一个我开发的基于 Qwen 的多 Agent 框架,并用它实现了一个“全平台文章同步助手”。输入文章内容或链接,自动生
🚀大模型落地开发实战指南!请关注微信公众号:「AGI启程号」 深入浅出,助你轻松入门!
📚 数据分析、深度学习、大模型与算法的综合进阶,尽在CSDN博客主页
目录
写文章 1 小时,分发排版 2 小时?
这是很多技术博主的噩梦。把一篇公众号文章同步到知乎、CSDN、头条,不仅要改格式(Markdown vs 富文本),还要改语气(专业 vs 通俗)。
与其机械地复制粘贴,不如交给 AI。但简单的 ChatGPT 对话往往很难控制输出格式。
今天分享一个基于 Qwen 的多 Agent 框架实现了一个“全平台文章同步助手”。输入文章内容或链接,自动生成 3 个平台的发布文件。
01 为什么要用“多 Agent”?
—— 把大模型从“单打独斗”变成“团队作战"
很多开发者还在试图用一条几千字的 Prompt 让大模型干完所有事,结果往往是顾此失彼。如果把大模型比作一个聪明的实习生,多 Agent 架构(PEA 模式)就是把他拆成了一个团队:
🧠 Planner(规划者):
负责动脑。拿到任务,先拆解成 [Step 1, Step 2, Step 3]。
🛠️ Executor(执行者):
负责动手。根据规划,去调用工具(联网、读文件、写代码)。
📝 Answer(汇报者):
负责动嘴。把执行的一堆零散结果,汇总成你想要的样子。
这套架构最大的好处是:
可观测、易调试、不再“抽卡”赌运气。
02 落地案例:全平台文章同步助手
基于这套框架,我开发了一个实用的工具。
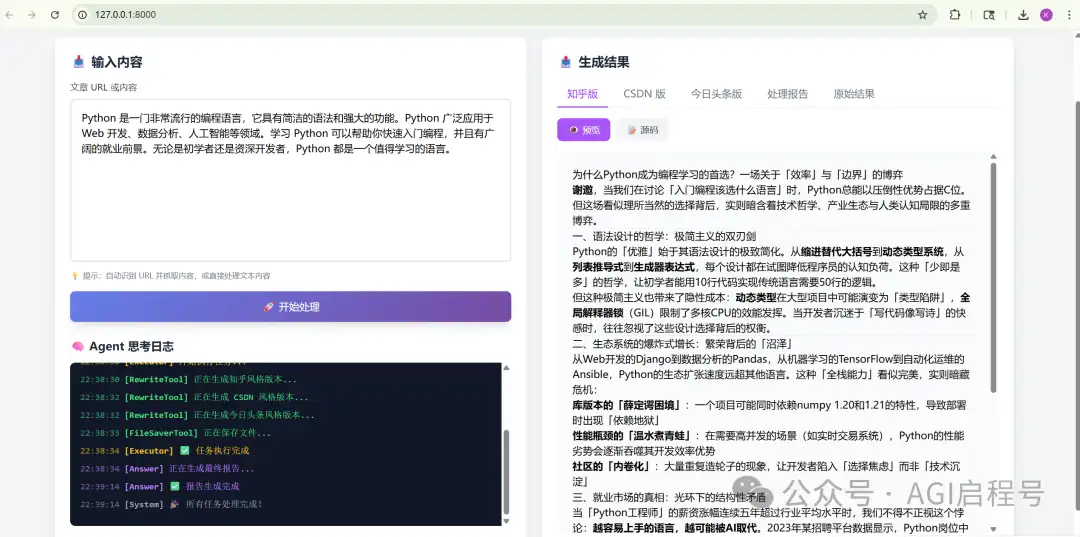
💡 使用场景:我写好了一篇公众号文章,想同步到其他平台。
👉 操作演示:在前端输入公众号链接(或者直接粘贴文本),点击执行。
✨ 最终产出:Agent 会在我的桌面上自动生成 output/ 文件夹,包含:
-
知乎版:自动添加“谢邀”风格开头,深度分析风,Markdown 格式。
-
CSDN 版:自动提取技术点生成目录,教程风,Markdown 格式。
-
头条版:
标题党风格,短段落,自动渲染为 HTML(带样式),复制即可发布。
本期代码运行实例详见github:https://github.com/SWUSTcyt/
multi-agent-framework
03 核心架构拆解(附关键代码)
这个项目的核心,是一条串联起 Plan -> Execute -> Answer的全流程接口。
3.1 核心编排:主控逻辑
后端通过 /solve接口,像流水线一样调度三个 Agent:
# main.py 核心逻辑
@router.post("/solve", response_model=SolveFullResponse)
def api_solve(req: FullFlowRequest):
"""全流程接口:串联执行规划 → 执行 → 回答"""
try:
# 1. Plan: 脑子先动,产出步骤
planner_output = call_planner(req.question)
# 2. Execute: 手脚并用,调用工具
results = execute_plan(
planner_output.plan,
PRIMARY_TOOL_NAME,
FALLBACK_TOOL_NAME
)
# 3. Answer: 整理汇报
report = FullExecutionReport(
plan=planner_output.plan,
results=results
)
answer_content = call_answer_agent(report)
return SolveFullResponse(...)
3.2 Planner:聪明的“分流器”
用户有时给 URL,有时给文本。Planner 也就是“规划 Agent”,它通过正则判断输入类型,并决定后续的任务参数。
# planner_agent.py
# 判断输入类型(URL 或文本)
is_url = bool(re.match(r'^https?://', user_query.strip()))
if not is_url:
# 如果是文本输入,直接将内容注入到后续任务中
for task in plan_dict.get("sub_tasks", []):
if task.get("task_type") == "rewrite_content":
# 自动注入 raw_content 参数,Executor 不需要知道数据来源
task["extra_params"]["raw_content"] = user_query.strip()
3.3 Executor:插件化的“工具人”
这是框架最灵活的地方。Executor 只管看任务类型 (task_type),然后去 Registry 里找对应的工具。
这意味着,如果我要加一个“发送邮件”的功能,只需要写一个 MailTool,不需要改动 Agent 的核心代码。
# executor_agent.py
if task.task_type == "fetch_content":
# 调用抓取工具
result = registry.execute_tool(
"fetch_content",
task.keywords,
**task.extra_params
)
elif task.task_type == "rewrite_content":
# 调用重写工具(支持多平台参数切换)
platform = task.extra_params.get("platform", "zhihu")
result = registry.execute_tool(
"rewrite_content",
raw_content,
**tool_params
)
return ExecutionResult(
source=f"rewrite_{platform}",
status="success",
data=data
)
04 前端体验:所见即所得
为了让这个工具真正好用,前端(基于 Alpine.js + Tailwind CSS)做了针对性的优化。
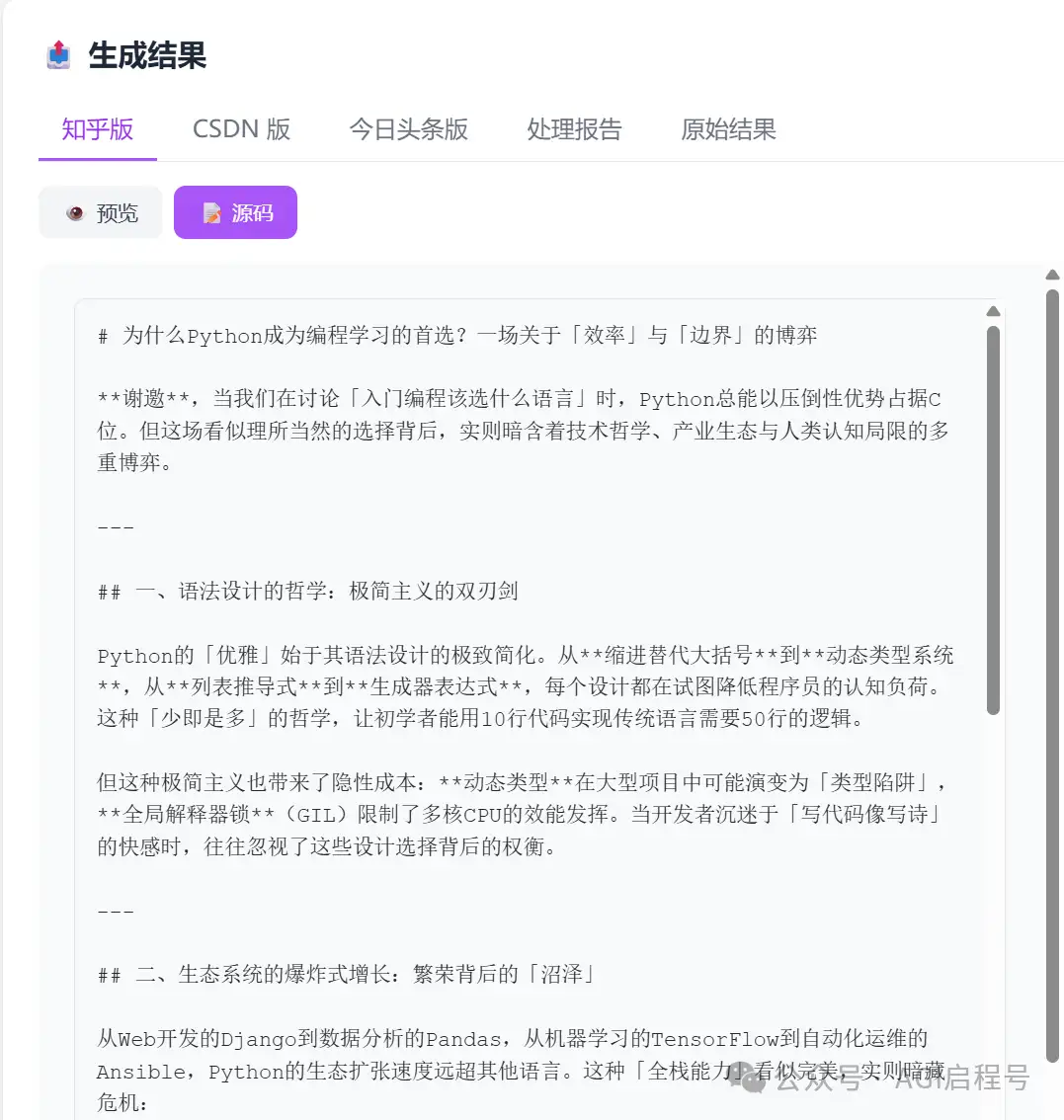
除了展示 Agent 的思考日志,最重要的是**“多视图切换”**:
- Tab 切换:快速对比知乎、CSDN、头条三个版本的差异。
- 源码/预览模式:既可以看 Markdown 源码方便复制,也可以看渲染后的效果。
05 总结与展望
这套 PEA (Plan-Execute-Answer) 框架不仅适用于文章同步,其实稍微改改 Tool,就能变成:
- 竞品分析 Agent:搜索竞品 -> 抓取价格 -> 生成对比表格。
- 研报生成 Agent:拆解目录 -> 联网搜索 -> 汇总写长文。
工程化的核心,就是把偶然的“灵光一现”,变成稳定的“生产流水线”。
如果你对这个框架感兴趣,或者想看更多关于大模型应用开发方向的代码实践,欢迎在评论区留言!
关注微信公众号及时获取更多技术资讯
本期代码运行实例详见github:https://github.com/SWUSTcyt/
multi-agent-framework

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 27
27 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)