Agent Skill, 提高MCP的使用效率
Agent Skill
MCP 核心是标准化智能体与外部工具/资源的通信方式。当智能体需要访问文件系统、数据库、GitHub、Slack 等各种服务时,传统做法是为每个服务编写专门的适配器,工作量大且难以维护。MCP 通过定义统一的协议规范,让所有服务都能以相同的方式被访问。
MCP 的设计思想是"上下文共享"。不仅是一个远程过程调用协议,同时允许智能体和工具之间共享丰富的上下文信息。
MCP增强了Agent的能力,但也带来了两个问题。
第一个问题是上下文爆炸。为了让智能体能够灵活查询数据库,MCP 服务器通常会暴露数十甚至上百个工具(不同的表、不同的查询方法)。这些工具的完整 JSON Schema 在连接建立时就会被加载到系统提示词中,可能占用数万个 token。据社区开发者反馈仅加载一个 Playwright MCP 服务器就会占用 200k 上下文窗口的 8%,这在多轮对话中会迅速累积,导致成本飙升和推理能力下降。
第二个问题是能力鸿沟。MCP 解决了"能够连接"的问题,但没有解决"知道如何使用"的问题。拥有数据库连接能力,不等于智能体知道如何编写高效且安全的 SQL;能够访问文件系统,不意味着它理解特定项目的代码结构和开发规范。这就像给一个新手程序员开通了所有系统的访问权限,但没有提供操作手册和最佳实践。
为解决上述两个问题,提出了Agent Skill 概念。
Agent Skill
Agent Skills 是一种标准化的程序性知识封装格式,教导智能体如何正确使用这些工具。
连接性(Connectivity)与能力(Capability)应该分离。MCP 专注于前者,Skills 专注于后者。这种职责分离带来了清晰的架构优势:
-
MCP 的职责:提供标准化的访问接口,让智能体能够"够得着"外部世界的数据和工具
-
Skills 的职责:提供领域专业知识,告诉智能体在特定场景下"如何组合使用这些工具"
渐进式披露-Progressive Disclosure
Agent Skills 的最核心的创新。将技能信息分为三个层次,智能体按需逐步加载,既确保必要时不遗漏细节,又避免一次性将过多内容塞入上下文窗口。
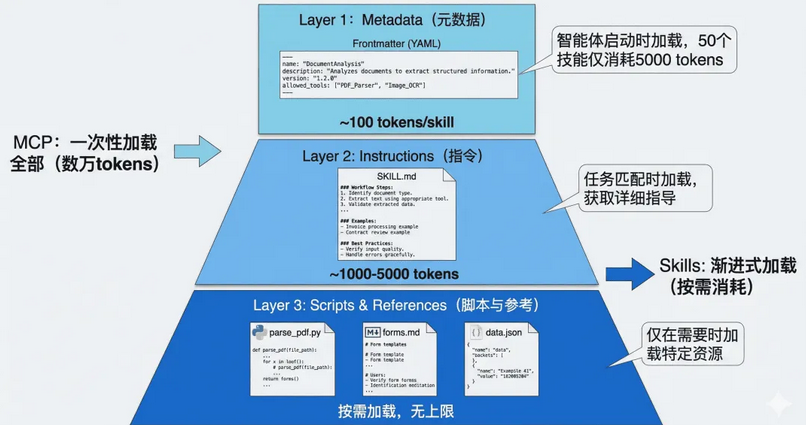
元数据(Metadata)
每个技能都存放在一个独立的文件夹中,核心是一个名为 SKILL.md 的 Markdown 文件,必须以 YAML 格式的 Frontmatter 开头,定义技能的基本信息。
当智能体启动时,扫描所有已安装的技能文件夹,仅读取每个 SKILL.md 的 Frontmatter 部分,将这些元数据加载到系统提示词中。实测每个技能的元数据仅消耗约 100 个 token。即使你安装了 50 个技能,初始的上下文消耗也只有约 5,000 个 token。
而在在典型的 MCP 实现中,当客户端连接到一个服务器时,通常会通过 tools/list 请求获取所有可用工具的完整 JSON Schema,可能立即消耗数万个 token。
技能主体(Instructions)
当智能体通过分析用户请求,判断某个技能与当前任务高度相关时,则进入第二层加载。智能体读取该技能的完整 SKILL.md 文件内容,将详细的指令、注意事项、示例等加载到上下文中。智能体获得了完成任务所需的全部上下文:数据库结构、查询模式、注意事项等。这部分内容的 token 消耗取决于指令的复杂度,通常在 1,000 到 5,000 个 token 之间。
附加资源(Scripts & References)
对于更复杂的技能,SKILL.md 可以引用同一文件夹下的其他文件:脚本、配置文件、参考文档等。智能体仅在需要时才加载这些资源。
示例:一个 PDF 处理技能的文件结构如下
skills/pdf-processing/
├── SKILL.md # 主技能文件
├── parse_pdf.py # PDF 解析脚本
├── forms.md # 表单填写指南(仅在填表任务时加载)
└── templates/ # PDF 模板文件
├── invoice.pdf
└── report.pdf
在 SKILL.md 中,可以这样引用附加资源:
-
当需要执行 PDF 解析时,智能体会运行
parse_pdf.py脚本 -
当遇到表单填写任务时,才会加载
forms.md了解详细步骤 -
模板文件只在需要生成特定格式文档时访问
SKILL.md 文件的标准结构
---
# === 必需字段 ===
name: skill-name
# 技能的唯一标识符,使用 kebab-case 命名
description: >
简洁但精确的描述,说明:
1. 这个技能做什么
2. 什么时候应该使用它
3. 它的核心价值是什么
# 注意:description 是智能体选择技能的唯一依据,必须写清楚!
# === 可选字段 ===
version: 1.0.0
# 语义化版本号
allowed_tools: [tool1, tool2]
# 此技能可以调用的工具列表(白名单)
required_context: [context_item1]
# 此技能需要的上下文信息
license: MIT
# 许可协议
author: Your Name <email@example.com>
# 作者信息
tags: [database, analysis, sql]
# 便于分类和搜索的标签
---
# 技能标题
## 概述
(对技能的详细介绍,包括使用场景、技术背景等)
## 前置条件
(使用此技能需要的环境配置、依赖项等)
## 工作流程
(详细的步骤说明,告诉智能体如何执行任务)
## 最佳实践
(经验总结、注意事项、常见陷阱等)
## 示例
(具体的使用案例,帮助智能体理解)
## 故障排查
(常见问题和解决方案)
SKILL编写建议
精准描述
-
精确定义适用范围:避免模糊的描述如"帮助处理数据"
-
包含触发关键词:让智能体能够匹配用户意图
-
说明独特价值:与其他技能区分开来
专注独立功能
Skill 应该专注于一个明确的领域或任务类型。如果一个 Skill 试图做太多事情会导致:
-
hDescription 过于宽泛,匹配精度下降
-
指令内容过长,浪费上下文
-
难以维护和更新
与其创建一个"通用数据分析"技能,不如创建多个专门的技能:
-
mysql-employees-analysis:专门分析 employees 数据库 -
sales-data-analysis:专门分析销售数据 -
user-behavior-analysis:专门分析用户行为数据
脚本优先
对于复杂的、需要精确执行的任务,优先使用脚本而不是依赖 LLM 生成。例如,在数据导出场景中,与其让 LLM 生成 Excel 二进制内容(容易出错),不如编写一个专门的脚本来处理这个任务,SKILL.md 中只需要指导智能体何时调用这个脚本即可
渐进策略
合理利用三层结构,将信息按重要性和使用频率分层:
-
SKILL.md 主体:放置核心工作流、常用模式
-
附加文档(如
advanced.md):放置高级用法、边缘情况 -
数据文件:放置大型参考数据,通过脚本按需查询
参考:
https://mp.weixin.qq.com/s/-wzXL3uzkhPCB0SF8Cq6eg?wxwork_userid=adobebaba

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)