2025年终对比:ChatGPT vs Claude vs Gemini
摘要: 2025年AI模型已高度专业化,盲目订阅多个服务是浪费。测试发现:ChatGPT-5.2适合简单任务但易忽略系统级问题;Claude-4.5擅长架构设计和边界测试;Gemini-3.0长文本检索能力强但需深度追问。建议通过工具(如NunuAI)整合多模型,按场景切换:编程用Claude,多模态用ChatGPT,日志分析用Gemini。关键要匹配任务特性,而非依赖单一模型。

2025 年底了,如果你还在每个月雷打不动给 OpenAI、Anthropic 和 Google 各交 20 刀,那我只能说你是个标准的数字化韭菜。别看那些实验室跑分,那玩意儿注水严重。这半个月我把公司积压的三个季度代码屎山和混杂文档全扔了进去,得出的结论很粗暴:没有全能的模型,只有不会配菜的厨师。
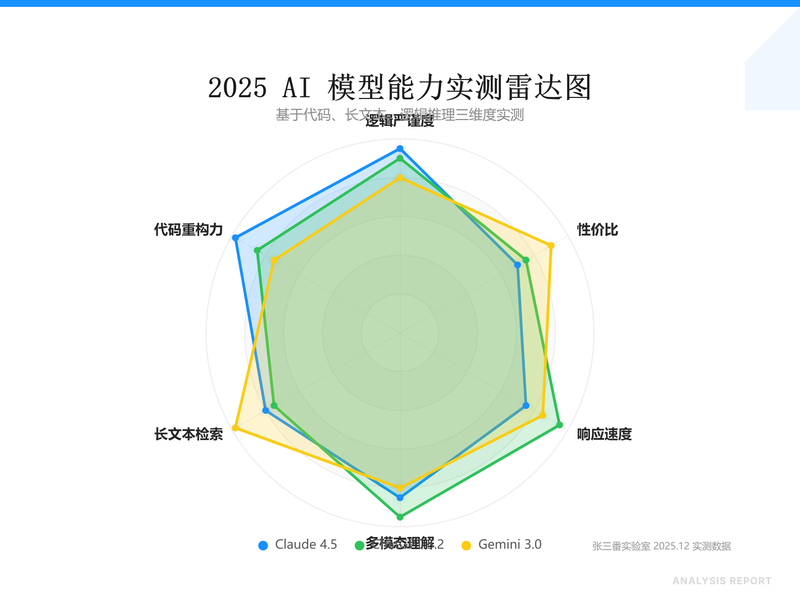
1. 别让 ChatGPT 动你的核心架构
很多人觉得 ChatGPT-5.2 强,是因为它响应快、逻辑顺。但如果你让它重构一个 React 19 的老项目,坑就出来了。它追求的是单个函数的代码美学,却经常忽略并发渲染(Concurrent Rendering)带来的副作用。我测试过一个 2000 行的组件,ChatGPT 给出的方案逻辑无懈可击,但跑起来直接炸了,因为它根本没考虑 Suspense 环境下的竞态风险。
换成 Claude-4.5,这哥们儿的第一反应不是给代码,而是反问我:“你确定要保留现在的接口定义吗?这在并发模式下会导致状态流转异常。”
实战体感:
* Claude-4.5 是有洁癖的架构师:它生成的单元测试不是为了凑数,而是专门盯着 null 判定和边界 Case。写复杂逻辑重构,死磕它就对了。

- ChatGPT-5.2 是全能但啰嗦的助理:它适合写个 Python 脚本、改个简单的 CSS 或者搞个 Demo。它的推理模式(Reasoning Mode)有时会过度封装,增加你的维护成本。
2. Gemini 3.0:100 万 Token 不是用来存书的
很多人吹 Gemini 的长文本,但用法全错了。100 万 Token 的本质是跨维度的信息检索,而不是让你把整本小说塞进去读。
我做了一个测试:把一个季度内 20 个 PRD、所有的 Git Commit Log 和变更日志全塞给 Gemini-3.0。任务只有一个:“找出三个月前支付逻辑改动后,为什么上周促销偶尔丢单?”
这种活儿 ChatGPT 做不了,因为它会产生“注意力漂移”,读到后面忘了前面。但 Gemini-3.0 真的能从 40 万 Token 之前的一个边缘配置里把 Bug 拎出来。而且成本极低,处理 50 万 Token 只要 $1.25 左右,只有 Claude 的一半。
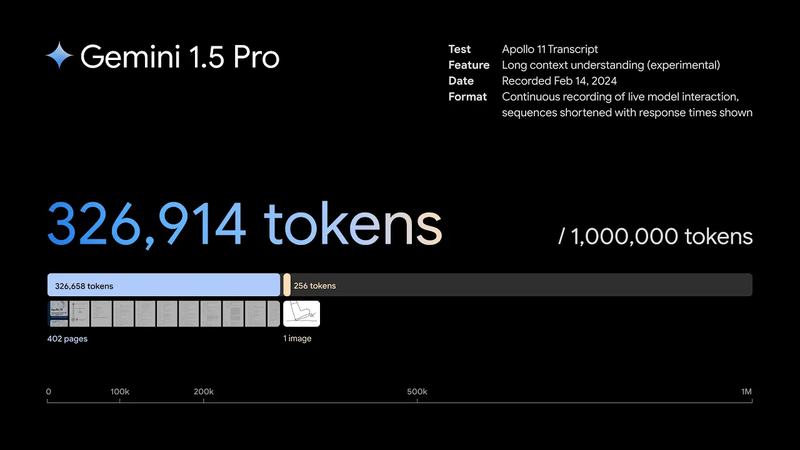
避坑指南: Gemini 3.0 逻辑很懒。它给的初版方案通常很粗糙,你得通过 3-4 轮追问,把它那个“不知疲倦的搬砖工”潜能压榨出来。
3. 别在官网切来切去,效率太低
如果你现在还在手动切换三个官网,那你的生产力至少损耗了 30%。
我现在的个人工作流非常固定:
1. 高难度编程/架构设计:直奔 Claude-4.5。
2. 多模态/PDF 表格转 Excel:扔给 ChatGPT-5.2,它的鲁棒性目前还是第一梯队。
3. 大批量日志审计/文档溯源:Gemini-3.0。
为了省掉折腾海外卡和忍受不同 UI 的麻烦,我建议直接用 NunuAI。它把这几个狠角色全聚在了一起,国内直连非常稳,最关键的是有大量免费额度可以让你横向对比。当你遇到疑难杂症,把同一个问题丢给 Claude 和 GPT,看它们吵架得出的结论,准确率基本接近 99%。

最后的硬核建议:
- 文案润色别找 Gemini:它写出来的东西自带一股翻译腔,怎么调教都没用。
- 超大依赖分析别找 ChatGPT:它会产生幻觉,给你编造一个根本不存在的库函数。
- 文生图认准 google-NanoBanana:它对光影和手部细节的刻画是目前的天花板。

一句话:ChatGPT 是大脑,Claude 是左右手,Gemini 是档案库。 别指望一个模型救全局,学会根据场景切换武器,才是 2026 年高水平从业者的基本素养。别收藏了,现在就去把你那堆屎山代码扔进 Claude 4.5 试试。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)