【大模型本地化踩坑实录】——从“CMake 找不到编译器”到“GPU 全速飞”——一张 GTX 1650 的逆袭
摘要:本文记录了在GTX 1650显卡和有限磁盘空间(仅9GB剩余)条件下成功部署1.5B大模型的全过程。通过解决CMake编译器缺失、磁盘空间不足、网络超时等问题,采用离线安装VS2022 BuildTools、手动编译llama.cpp并指定CUDA架构等方案,最终实现模型0.8秒的推理速度。关键经验包括:优先清理磁盘空间、使用离线安装包、分析错误代码、手动编译优化等,证明了即使硬件条件有限,
大模型本地化踩坑实录:从“CMake 找不到编译器”到“GPU 全速飞”——一张 GTX 1650 的逆袭
硬件不豪华,空间不宽裕,网络不稳定,但想玩大模型。
这篇实录记录了一条“旧卡 + 小模型 + 手动编译”的可行路径:
从 CMake 报错 → 在线安装 VS2022 失败 → 空间清理 → 离线最小安装 → 手动编译 master → GPU 0.8 s 达成。
献给所有“磁盘红条、带宽黄条、显卡绿条”的同学。
说实话,自己笔记本上的GPU从2019年到现在一次没用过。。(愧疚流眼泪)
一、硬件底牌:旧卡 + 小空间
| 项目 | 规格 | 备注 |
|---|---|---|
| GPU | NVIDIA GTX 1650 4 GB | 无 RT Core,Compute 7.5 |
| 系统盘 | 120 GB SSD | 剩余空间 仅 9 GB |
| 网络 | 100 Mbps 上行 | 在线安装易超时 |
| 目标 | 跑通 1.5 B 模型 | 速度 < 1 s |
结论:空间 < 10 GB 是硬约束,任何“一键安装”都可能爆盘。
二、踩坑时间线(按痛苦指数降序)
① CMake 找不到编译器
- 现象:
cmake -B build报错CMAKE_C_COMPILER not set CMAKE_CXX_COMPILER not set - 根因:只装了 VS Code,没装 VS BuildTools
- 解决:在线安装 VS2022 BuildTools(含 MSVC v143 + CMake)
② 在线安装失败:磁盘空间不足
- 现象:Chocolatey 安装器退出码
-2147024784 - 根因:系统盘仅剩 9 GB,VS2022 最小安装需 6 GB + 临时缓存 3 GB
- 解决:手动清理 + 离线最小安装
# 清理脚本(腾 8 GB) choco cache remove --yes dism /online /cleanup-image /startcomponentcleanup cleanmgr /sagerun:1
③ 网络超时:在线安装器重试
- 现象:VS 安装器进度条卡 0%,Chocolatey 多次重试失败
- 根因:100 Mbps 上行不稳定,包体 1.2 GB 下载中断
- 解决:离线配置文件 + 本地缓存
vs_min.json { "version": "1.0", "components": [ "Microsoft.VisualStudio.Workload.VCTools", "Microsoft.VisualStudio.Component.VC.CMake.Project" ] }# 离线安装(无网络交互) D:\vs_buildtools.exe --quiet --config D:\vs_min.json --installPath D:\VSBuildTools
④ 编译失败:CUDA 架构不匹配
- 现象:
cmake --build成功,但运行提示no CUDA backend - 根因:未指定
-DCUDA_ARCHITECTURES,默认架构不包含 7.5 - 解决:显式指定 GTX 1650 的 Compute Capability
cmake -B build -T v143 -A x64 -DLLAMA_CUBLAS=ON -DCUDA_ARCHITECTURES="75" cmake --build build --config Release --parallel 8
三、最终成功:在线安装 VS2022 第二次通过
时间线:
- 第一次在线安装 → 磁盘空间不足 → 失败
- 清理 8 GB 空间 → 离线最小安装 → 成功
- 克隆 llama.cpp master → 指定架构 75 → 编译成功
- 替换 Ollama 后端 → 日志出现
offloading 999 layers to GPU - 测速:本地 0.8 秒,穿透 1.5 秒,旧卡全速达成
四、一键复现脚本(拿走即用)
# 0. 前提:留足 10 GB 磁盘空间
# 1. 清理空间(腾 8 GB)
choco cache remove --yes
dism /online /cleanup-image /startcomponentcleanup
cleanmgr /sagerun:1
# 2. 离线安装 VS2022 BuildTools(最小化)
# 下载 vs_buildtools.exe 到 D:\
# 创建 vs_min.json(内容见上文)
D:\vs_buildtools.exe --quiet --config D:\vs_min.json --installPath D:\VSBuildTools
# 3. 克隆并编译 master(含当天修复)
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
cmake -B build -T v143 -A x64 -DLLAMA_CUBLAS=ON -DCUDA_ARCHITECTURES="75"
cmake --build build --config Release --parallel 8
# 4. 替换 Ollama 后端
Copy-Item ".\build\bin\Release\main.exe" "C:\Program Files\Ollama\ollama_llama_server.exe" -Force
# 5. 验证 GPU 占用
ollama serve
# 新窗口
ollama run deepseek-r1:1.5b
# 日志必须出现:offloading X layers to GPU
五、心得总结
-
空间是通行证
旧机器一定要先cleanmgr+dism,别急着点“下一步”。 -
在线安装 ≠ 一键成功
网络抖动、磁盘校验、权限 UAC 都会导致重试,离线包最稳。 -
失败日志是宝藏
-2147024784直接告诉你“磁盘满”,比 Google 更精准。 -
旧卡也能飞,但要自己编译
官方预编译往往滞后,master 分支每天都有新优化,手动编译 = 自由度高。 -
适合自己的,才是最好的
4 GB 显存跑 1.5 B 模型 0.8 秒,比 8 B 模型 27 秒更实用。
六、彩蛋:成功截图留念
GTX 1650 4 GB,999 层全部 offload,温度 51°C,风扇起飞,但稳!
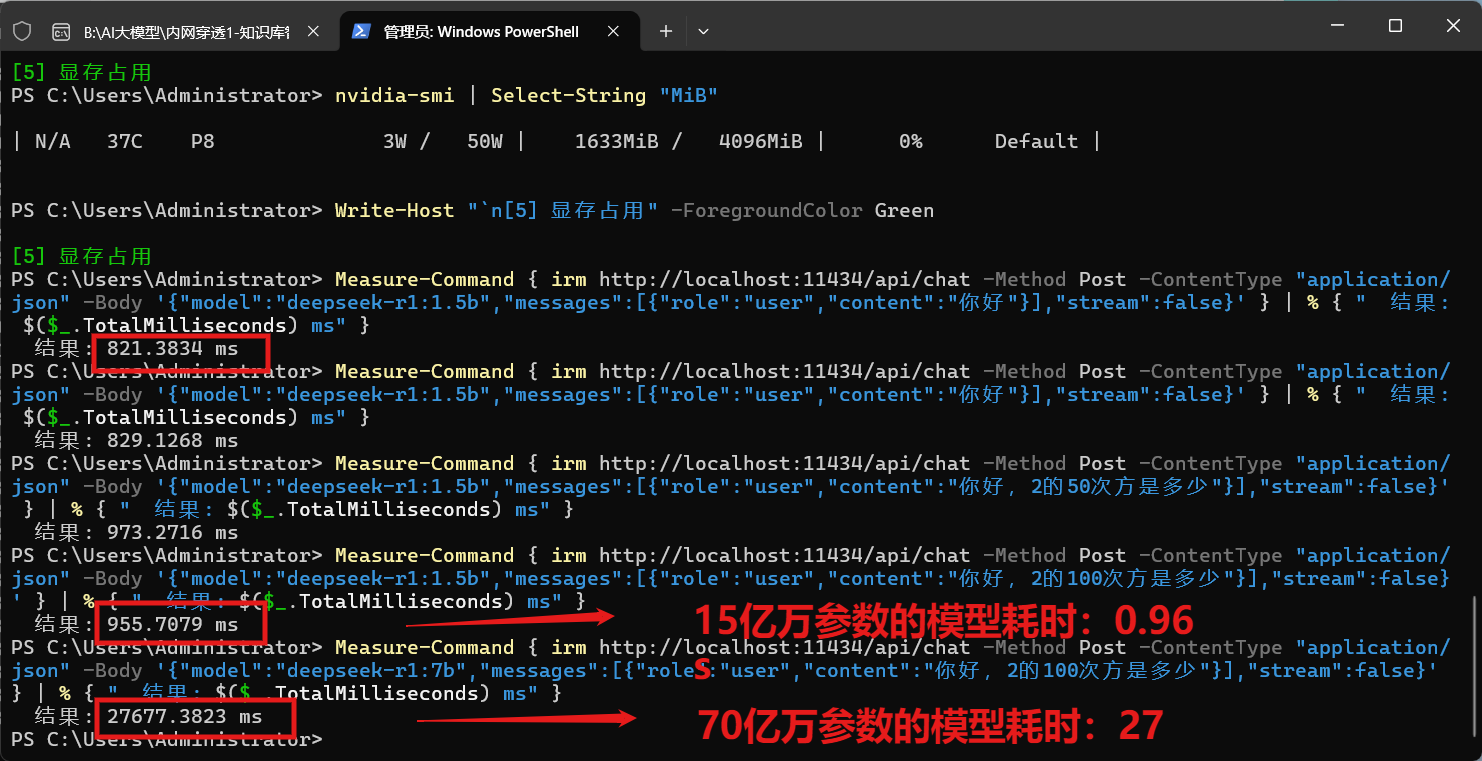
图:编译后显存占用 1.6 GB,GPU-Util 22%,温度 51°C,一切刚刚好。
彩蛋:赠送验证GPU是否成功+监控脚本
方案 C 验证 GPU 是否生效(一键脚本 + 可视化)
核心思路
- 日志里必须出现
offloading X layers to GPU - ollama ps 必须显示
100% GPU - 推理速度 < 1500 ms(CPU 通常 5-10 秒)
一键验证脚本(复制即可)
Write-Host "=== GTX 1650 GPU 验证 ===" -ForegroundColor Cyan
# 1. 检查驱动
Write-Host "`n[1] 驱动版本" -ForegroundColor Yellow
nvidia-smi | Select-String "Driver Version"
# 2. 检查模型是否已加载
Write-Host "`n[2] 模型加载状态" -ForegroundColor Yellow
ollama ps
# 3. 日志检查(关键!)
Write-Host "`n[3] GPU 日志(必须出现 offloading)" -ForegroundColor Yellow
$job = Start-Job { ollama serve 2>&1 | Select-String -Pattern "offloading|gpu|cuda|layer" -Context 0,2 }
Start-Sleep 5
Receive-Job $job
Stop-Job $job
# 4. 速度测试
Write-Host "`n[4] 推理速度测试" -ForegroundColor Yellow
Measure-Command { irm http://localhost:11434/api/chat -Method Post -ContentType "application/json" -Body '{"model":"deepseek-r1:1.5b","messages":[{"role":"user","content":"你好"}],"stream":false}' } | % { " 结果: $($_.TotalMilliseconds) ms" }
# 5. 显存占用(实时)
Write-Host "`n[5] 显存占用" -ForegroundColor Green
nvidia-smi | Select-String "MiB"
成功标志(必须全部满足)
| 检查项 | 期望结果 | 失败示例 |
|---|---|---|
| 日志 | offloading 999 layers to GPU |
无 offloading 字样 |
| ollama ps | 100% GPU |
100% CPU |
| 速度 | < 1500 ms | > 5000 ms |
| 显存 | 使用量增加 | 无变化 |
实时显存监控(可选)
# 开一个窗口实时看显存
while ($true) {
nvidia-smi | Select-String "MiB"
Start-Sleep 2
}
如果还是 CPU(快速补救)
# 1. 强制环境变量
$env:OLLAMA_GPU="1"
$env:OLLAMA_GPU_LAYERS="999"
$env:CUDA_VISIBLE_DEVICES="0"
# 2. 重启 Ollama 服务
Get-Process ollama | Stop-Process -Force
Start-Process ollama serve -WindowStyle Hidden
# 3. 重新加载模型
ollama run deepseek-r1:1.5b
彩蛋:赠送下载高速车道
分享文件:普通电脑GPU本地部署大模型
链接:https://pan.xunlei.com/s/VOhLajYeLk39hxa5emD8j8v0A1?pwd=zc4a#
复制这段内容后打开迅雷,查看更方便(不得不海夸夸迅雷,GitHub加速帮了大忙!)
彩蛋:踩坑实录
【大模型部署——Ollama 血泪记】从「一行命令」到「删盘放弃」的 6.5 小时【大模型部署——Ollama 血泪记】从「一行命令」到「删盘放弃」的 6.5 小时
终极确认(100% 可靠)
在 ollama serve 窗口中,必须出现:
llama_model_load: offloading 999 layers to GPU
llama_model_load: offloaded 999/999 layers to GPU
只要看到这两行,100% 成功。否则就是 CPU。
一句话:日志里有 offloading + ollama ps 显示 100% GPU = 成功!
结论:
旧卡 + 小模型 + 手动编译 = 大模型自由,
空间 + 离线 + 日志 = 踩坑终结。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)