03 RAG - RAG简介
摘要: RAG(检索增强生成)技术通过结合信息检索与文本生成,提升大模型回答专业问题的准确性和可靠性,尤其适用于私域数据场景。其核心流程包括语义搜索和生成输出,利用向量数据库(如Faiss、Chroma)检索相关文档,再交由大模型生成答案。
RAG简介
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合信息检索与文本生成的技术,旨在提升大语言模型在回答专业问题时的准确性和可靠性。换句话说,就是通过自有垂直领域数据库检索相关信息,然后合并成为提示模板,给大模型润色生成回答。
RAG的作用
当前,数据大模型蓬勃发展,但将大模型应用于实际业务场景时会发现,通用的基础大模型基本无法满足实际业务需求,主要有以下几方面原因:
- 知识局限性
模型自身的知识完全源于它的训练数据,而现有的主流大模型如deepseek、文心一言、通义千问等的训练数据集基本都是构建于网络公开的数据,对于实时性的、非公开的或离线的数据是无法获取到的。 - 幻觉问题
所有的AI模型的底层原理都是基于数学概率,其模型输出实质上是一系列数值运算,大模型也不例外,所以它经常会一本正经地胡说八道,尤其是在大模型自身不具备某一方面的知识或不擅长的场景。 - 数据安全性
对于企业来说,数据安全至关重要,没有企业愿意承担数据泄露的风险,将自身的私域数据上传第三方平台进行训练。这也导致完全依赖通用大模型自身能力的应用方案不得不在数据安全和效果方面进行取舍。
RAG通过一系列的技术对私域数据查询检索,然后将检索结果作为数据提示通过LLM获取响应结果的一个过程。RAG方法让LLM能够获取内化知识之外的信息,并允许LLM在专业知识库的基础上,以更准确的方式回答问题,并且不会特别消耗资源。
在大模型时代,RAG是用于解决幻觉问题、知识时效问题、超长文本问题等各种大模型本身制约或不足的必要技术。
RAG主要通过检索语义匹配的文档,然后将文档知识传递给大模型,基于大模型推理获取合适的答案。RAG可以减少预训练LLM或者通用LLM的幻觉问题,消除文档标注。
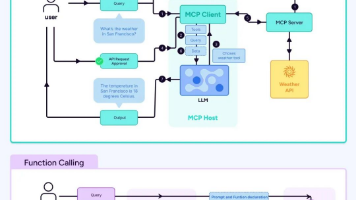
通常,基于RAG的LLM应用可以表述为一个映射过程,即基于给定数据 D,将用户输入(查询 Q)映射到预期响应(答案 A)。
例如,向 LLM 提问一个问题(qustion),RAG 从各种数据源检索相关的信息,并将检索到的信息和问题(answer)注入到 LLM 提示中,LLM 最后给出答案。
许多产品基于 RAG 构建,从基于 web 搜索引擎和 LLM 的问答服务到使用私有数据的应用程序。
早在2019年,Faiss 就实现了基于嵌入的向量搜索技术,现在 RAG 推动了向量搜索领域的发展。后来比如 chroma、weaviate 和 pinecone 这些基于开源搜索索引引擎(主要是 faiss 和 nmslib)向量数据库初创公司,增加了输入文本的额外存储和其他工具。
在这个过程中,有两个主要步骤:语义搜索和生成输出。在语义搜索步骤中,从知识库中找到与要回答的查询最相关的部分内容。然后,在生成步骤中,将使用这些内容来生成响应。
💡 小提示!
有两个最著名的基于 LLM 的管道和应用程序的开源库——LangChain 和 LlamaIndex。
RAG的问题与挑战
但是,不少人提出RAG的原罪:一周出demo,半年用不好。主要存在如下七方面的问题:
-
问题1:内容缺失
提问的问题,无法在被检索文档库中找到,最准确的答案是缺失的。理想情况下,RAG系统回应该是“抱歉,我不知道答案”。然而,对于检索内容相关但没有相关答案的问题,系统可能被误导,给出一个 错误的答案。 -
问题2:检索的
Top-K内容缺失
问题的答案在文档库中,但排名得分不够高,无法返回给用户。理论上,检索过程中所有文档都会被排名得分。然而,在实际操作中,会返回排名前K个文档,为了提高召回率,K不可能设置的无限大,必须基于LLM大模型的能力,折中选择的一个值。 -
问题3:整合策略局限性
从数据库中检索到了包含答案的文档,但在生成答案的过程中,这些文档并未被纳入上下文。当数据库返回许多文档时,会进行整合过程以获取答案,此时会发生这种情况。 -
问题4:答案存在于上下文中,但大型语言模型未能提取出正确的答案
通常,这是因为上下文中存在太多噪声或矛盾信息。简而言之,Retrival命名是对的,但是LLM根据Retrival回答问题出错。睁眼说瞎话的概率明显大于用户可以接受的概率(用户一般只能接收0.1%的错误概率) -
问题5:错误格式
问题涉及以某种格式(如表格或列表)提取信息,而大型语言模型忽略了这一指示。 -
问题6:错误的特异性
返回的答案包含在响应中,但不够具体或过于具体,无法满足用户需求。这种情况发生在RAG系统设计者对某个问题有期望的结果,例如教师对学生。在这种情况下,应该提供具体的教育内容和答案,而不仅仅是答案。当用户不确定如何提问并过于笼统时,也会出现特异性错误。 -
问题7:不完整
不完整的答案并非错误,但缺少一些信息,尽管这些信息存在于上下文中并可供提取。
面对这些问题,对RAG技术的应用和优化提出整体开发建议和思路:
- RAG系统的验证只能在运行过程中进行。
- RAG系统的稳健性是演进而非一开始就设计好的。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)