Kimi K2 Thinking:面向思考+工具调用的高阶智能体大模型
最近Kimi K2 Thinking 在国内外AI圈引起了不小的轰动,它以“思考(thinking tokens)+ 长序列工具调用” 为核心设计理念,并提出训练与推理策略。
最近Kimi K2 Thinking 在国内外AI圈引起了不小的轰动,它以“思考(thinking tokens)+ 长序列工具调用” 为核心设计理念,并提出训练与推理策略。

一、为什么需要K2 Thinking
传统大语言模型在一步到位的生成或短期多步思考上表现良好,但在长序列、多次工具交互、跨工具计划执行时遇到三类瓶颈:
- 上下文/记忆带宽受限:长程推理需要跨数万甚至十万级 tokens 的思考轨迹与工具输出管理;
- 工具协同复杂:在 agentic 场景下,模型要在搜索、代码执行、浏览、计算等工具间反复切换并保证连贯性与正确性;
- 推理稳定性与可控性:更多步意味着更高的出错累积风险,需要机制保证思考质量随步数增长仍受控。
K2 的核心思想是把思考作为第一类资源来尺度化(thinking-token scaling),并把工具调用作为可被计划与管理的长期行动序列。换言之,不只是更多参数,而是把推理过程本身(thinking)与工具交互能力纳入模型与评测范畴。
二、核心能力亮点
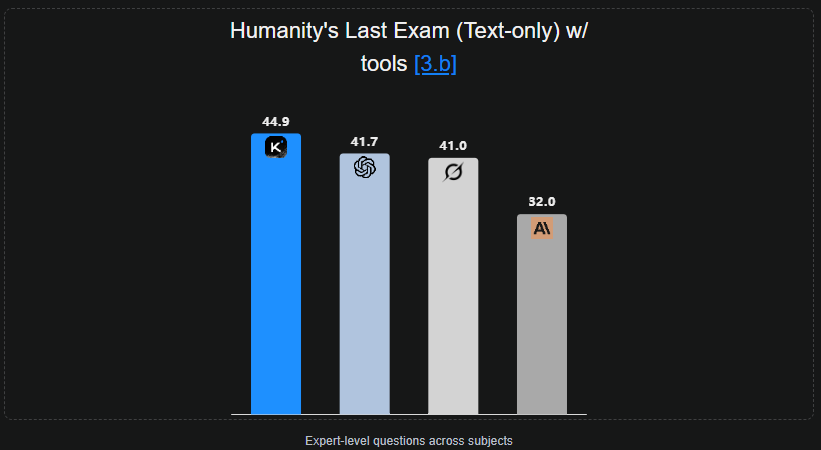
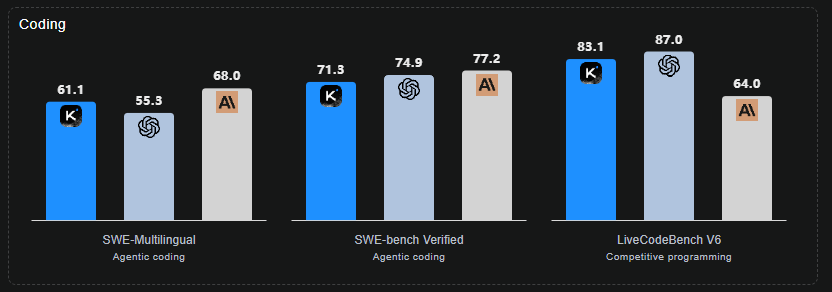
- 在Humanity’s Last Exam (HLE)(带工具)上达到 44.9%;BrowseComp 得 60.2%;SWE-Bench Verified 得 71.3%。这些指标表明 K2 在 复合长程推理 + agentic 搜索 + 代码生成 任务上具有领先性。
- 可执行 200–300 次连续工具调用,并在数百次步骤中保持连贯推理(test-time scaling)。
- 在示例中以 23 次交错的推理与工具调用解出博士级数学问题,展示了深层次、分段式解题能力。
- 工程实践上通过 量化感知训练(QAT)与 INT4 权重量化,在保证性能的同时显著提升推理吞吐。
K2 的贡献不是单纯提升单步预测质量,而是把思考 + 调用工具的整体能力当作第一阶工程目标,并提出训练与推理策略来支撑这一目标。
三、架构与推理范式
下面把 K2 的体系按静态能力(模型/参数)与动态能力(推理/工具策略)拆解说明。
3.1 模型层面(静态)
- 基础语言/思考模型:大规模 Transformer或 Mixture-of-Experts 变体,优化用于长上下文(256k tokens)的 attention / memory 管理。
- 思考令牌(thinking tokens):不同于普通生成的 completion token,Kimi K2 Thinking将推理中间态显式化为可累积的长上下文片段,系统上允许在推理环节内保留大量思考 token 以供后续检索与反思。
- 工具接口模块(tool adapters):统一的 tool-call 协议与序列化器(search, browse, python, shell, code-executor 等),使工具调用成为模型输出 space 的一部分,而非外部黑盒。
- 反思/重写层(reflection module):在长期推理中周期性执行反思策略,将中间输出压缩或抽象为更高层计划,减少冗余上下文占用。
3.2 推理层面(动态)
- 计划—执行—验证循环(plan → call tool(s) → read result → update plan):K2 把这套循环做为基本单元,并允许嵌套与并行(比如heavy mode 先 rollout 多轨迹,再合并)。
- 长步预算与步数管理:明确定义思考令牌预算与步骤上限(发布里 HLE 配置示例:步数上限 120、每步思考 token 48k;agentic 搜索步数上限可达 300,24k token/step)。这种显式预算设计有助于可重复评测与工程控制。
- 可微分/可训练工具调用策略:在训练或 fine-tuning 阶段利用模拟工具回环或真实工具沙箱让模型学习何时调用哪个工具、如何合并多工具信息,减少训练/测试差距。
- 上下文管理策略:当累积的工具输出超出模型上下文限制时,采用压缩或隐藏策略(如只保留摘要+关键证据),从而维持 long-horizon consistency。
四、关键工程实现
4.1 测试时尺度化(Test-time scaling)
- 思考令牌尺度化:通过允许超长上下文并结合分层 attention / retrieval,实现上百 KB — MB 级别的思考日记保存。
- 工具步数纵向扩展:把单次思考分为若干步,每步有固定预算;并在模型内显式计数与终止条件,避免无限循环。
4.2 工具协同与鲁棒性
- 工具结果插入策略:将工具输出作为特殊 token 插入上下文,并在需要时用检索或摘要替换旧的工具输出来节省上下文。
- 多轨并行与聚合(Heavy Mode):先并行 rollout 多个解法轨迹(例如 8),再让模型做 meta-reasoning 聚合结果,减少单轨陷入局部最优的概率。
- 工具沙箱与可信度估计:每个工具输出伴随可信度/元信息,模型学会在不同置信区间内对输出赋予不同权重。
4.3 性能优化:量化、内存与延迟
- Post-training QAT + INT4 权重量化:在保持精度的前提下把推理成本降到一半。K2 报告在 INT4 下仍能取得接近 FP16 的评测结果(通过 QAT 调校 MoE 路径/权重分布)。
- FlashAttention /块化 attention:用于大上下文以降低显存峰值。
- 思考令牌压缩策略:周期性将一段思考路径摘要为更短的 token(自动抽象),保留关键信息,丢弃冗余中间步骤。
一个正常的agent的工作流如下:
- Plan(内生成):模型写出分步骤计划(可包括要调用的工具名、预期输入/输出)。
- Call tool(s):按计划顺序调用检索/浏览/代码执行等工具(一次或并行多次)。
- Observe:把工具返回的结构化结果插入上下文(并记录证据元信息)。
- Update plan / Reflect:基于新证据修正计划(可能展开更多子任务)。
- Terminate / Synthesize:生成最终答案或交付物,并在需要时做可验证的总结(包含证据链)。
K2 的核心工程是在上面流程中保证长程一致的记忆管理与工具调用决策的稳定性。
五、评测结果与能力
发布摘要给出一组代表性 benchmark 分数,反映多个维度:
- 推理(长程 + 多工具):HLE w/ tools = 44.9%(state-of-the-art in release);能够在数十次工具调用内解决高难度学术问题(23 次交错推理+工具调用解博士级题)。

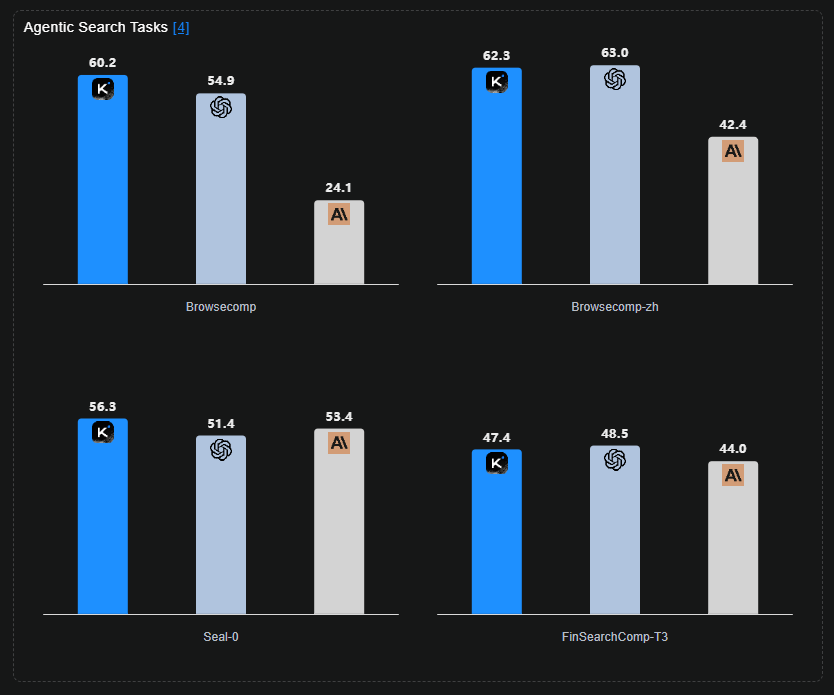
- Agentic 搜索/浏览:BrowseComp = 60.2%(远超人类 baseline 29.2%),说明 K2 在动态网页检索、证据聚合、长期信息追踪上有显著优势。
- 编码/工程能力:SWE-Bench Verified = 71.3%;LiveCodeBench、OJ-Bench 等显示在多语言编程、算法题、终端交互场景有实际落地能力。
- 多语言/多任务泛化:报告中的多项任务(MMLU、AIME、HMMT 等)在 no-tool/with-tool 两种设定下都有稳健表现,表明基础思考模型的横向泛化能力。
这些成绩强调工具链 + 思考预算对最终能力的巨大影响 —— 不是单纯把参数做大,而是构建长期一致的推理/工具框架。
Kimi K2 Thinking 的核心贡献在于 把“思考”与“工具调用”两项运行时资源纳入模型设计与评测范畴,并通过工程化手段(长上下文管理、工具协议、QAT、并行轨迹聚合)把实验室能力推进到可用水平。它不是简单把模型做大,而是重新定义如何在测试时(test-time)扩大推理能力:更多的思考 token、更多的工具步数、以及更稳健的推理闭环。
📚推荐阅读
详解Kimi Linear——有望替代全注意力的全新注意力架构

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 38
38 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)