AI超级智能体学习笔记day4-鱼皮
VectorStore 是 Spring AI 中用于与向量数据库交互的核心接口,它继承自 DocumentWriter。
阶段五
基础补缺:
函数式接口Supplier,Consumer,Function<T, R>
直接搜索源码快捷键:两下SHIFT
创建测试类:ALT+ENTER
var 关键字让编译器 “自动识别” 变量的类型,只支持局部变量
文档收集和切割(ETL)
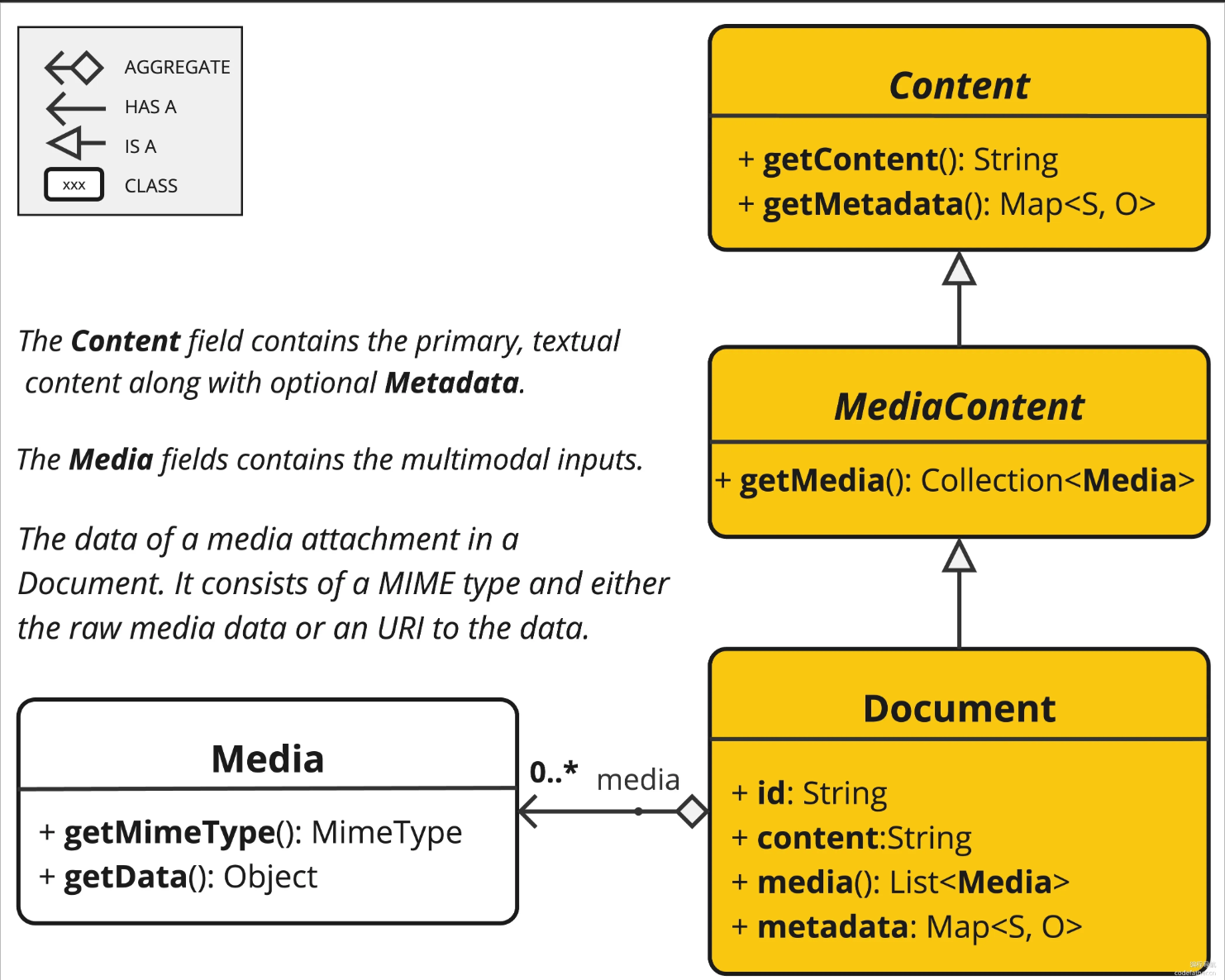
抽取(Extract)
public interface DocumentReader extends Supplier<List<Document>> {
default List<Document> read() {
return get();
}
}
Spring AI 内置的多种 DocumentReader 实现类,用于处理不同类型的数据源
转换(Transform)
DocumentTransformer 接口实现了 Function<List, List> 接口,负责将一组文档转换为另一组文档。
public interface DocumentTransformer extends Function<List<Document>, List<Document>> {
default List<Document> transform(List<Document> documents) {
return apply(documents);
}
}
1)TextSplitter 文本分割器
TokenTextSplitter 是其实现类,基于 Token 的文本分割器。它考虑了语义边界(比如句子结尾)来创建有意义的文本段落,是成本较低的文本切分方式。有参与无参两种构造方法。
2)MetadataEnricher 元数据增强器
KeywordMetadataEnricher:使用 AI 提取关键词并添加到元数据
SummaryMetadataEnricher:使用 AI 生成文档摘要并添加到元数据。不仅可以为当前文档生成摘要,还能关联前一个和后一个相邻的文档,让摘要更完整。
3)ContentFormatter 内容格式化工具
用于统一文档内容格式。
文档格式化:将文档内容与元数据合并成特定格式的字符串,以便于后续处理。
元数据过滤:根据不同的元数据模式(MetadataMode)筛选需要保留的元数据。
自定义模板:支持自定义以下格式。
加载(Load)
DocumentWriter 接口实现了 Consumer<List> 接口,负责将处理后的文档写入到目标存储中
public interface DocumentWriter extends Consumer<List<Document>> {
default void write(List<Document> documents) {
accept(documents);
}
}
1)FileDocumentWriter:将文档写入到文件系统
2)VectorStoreWriter:将文档写入到向量数据库
整个流程
PDFReader pdfReader = new PagePdfDocumentReader("knowledge_base.pdf");
List<Document> documents = pdfReader.read();
TokenTextSplitter splitter = new TokenTextSplitter(500, 50);
List<Document> splitDocuments = splitter.apply(documents);
SummaryMetadataEnricher enricher = new SummaryMetadataEnricher(chatModel,
List.of(SummaryType.CURRENT));
List<Document> enrichedDocuments = enricher.apply(splitDocuments);
vectorStore.write(enrichedDocuments);
vectorStore.write(enricher.apply(splitter.apply(pdfReader.read())));
向量转换和存储(向量数据库)
VectorStore 接口介绍
VectorStore 是 Spring AI 中用于与向量数据库交互的核心接口,它继承自 DocumentWriter
搜索请求构建
Spring AI 提供了 SearchRequest 类,用于构建相似度搜索请求
基于 PGVector 实现向量存储
1.本地或服务器安装使用
2.使用云数据库
1)首先打开 阿里云 PostgreSQL 官网,开通 Serverless 版本,按用量计费,对于学习来说性价比更高
2)开通成功后,进入控制台,先创建账号,创建数据库,安装插件,开通公网访问地址,IDEA连接数据库
3)参考 Spring AI 官方文档 整合 PGVector,先引入依赖,版本号可以在 Maven 中央仓库 查找
4)依赖-配置-使用自动注入的 VectorStore
QuestionAnswerAdvisor:RAG 专属顾问,调用传入pgVectorVectorStore(向量库),检索和提问语义相似的文档。
批处理策略(Batching Strategy)
BatchingStrategy 接口提供该功能,接口定义了一个单一方法 batch,它接收一个文档列表并返回一个文档批次列表。
public interface BatchingStrategy {
List<List<Document>> batch(List<Document> documents);
}
TokenCountBatchingStrategy 的默认实现
可以自定义 TokenCountBatchingStrategy,示例代码:
@Configuration
public class EmbeddingConfig {
@Bean
public BatchingStrategy customTokenCountBatchingStrategy() {
return new TokenCountBatchingStrategy(
EncodingType.CL100K_BASE,
8000,
0.1
);
}
}
也可以自己实现 BatchingStrategy:
@Configuration
public class EmbeddingConfig {
@Bean
public BatchingStrategy customBatchingStrategy() {
return new CustomBatchingStrategy();
}
}
文档过滤和检索(文档检索器)
预检索:优化用户查询
查询转换 - 查询重写
RewriteQueryTransformer
查询转换 - 查询翻译
TranslationQueryTransformer
查询转换 - 查询压缩
CompressionQueryTransformer
查询扩展 - 多查询扩展
都可以自定义定制 Prompt 模版,都在中间再套一层ai
检索:提高查询相关性
文档搜索
DocumentRetriever
可通过filterExpression与构造 Query 对象的 FILTER_EXPRESSION进行过滤
文档合并
Spring AI 内置了 ConcatenationDocumentJoiner 文档合并器,通过连接操作,将基于多个查询和来自多个数据源检索到的文档合并成单个文档集合。在遇到重复文档时,会保留首次出现的文档,每个文档的分数保持不变。
检索后:优化文档处理
查询增强和关联(上下文查询增强器)
QuestionAnswerAdvisor 查询增强
把用户提示词和检索到的文档等上下文信息拼成一个新的 Prompt,再调用 AI
核心逻辑:QuestionAnswerAdvisor 内置了文档检索器
RetrievalAugmentationAdvisor 查询增强
支持配置多种文档检索器,可配置ContextualQueryAugmenter实现空上下文处理
运用工厂模式创建一个自定义的 ContextualQueryAugmenter
RAG 最佳实践和调优
文档收集和切割
优化原始文档
文档切片
智能分块算法和人工二次校验
Spring AI 的 ETL Pipeline 提供的 DocumentTransformer或云服务的智能切分
元数据标注
1)手动添加元信息(单个文档)
2)利用 DocumentReader 批量添加元信息
3)自动添加元信息(基于Transformer 组件)
4)云服务平台添加
向量转换和存储
向量存储配置
选择合适的嵌入模型
(都有自己代码编写和平台选择两个方案)
文档过滤和检索
多查询扩展
效果不易评估而且代价大,通过MultiQueryExpander扩展出queries,再放到DocumentRetriever
查询重写和翻译
RewriteQueryTransformer 优化查询结构
TranslationQueryTransformer 支持多语言
云服务中,开启 多轮会话改写 功能
检索器配置
相似度阈值、返回文档数量和过滤规则
定义工厂类 LoveAppRagCustomAdvisorFactory
平台过滤标签
查询增强和关联
使用 Spring AI 的 ContextualQueryAugmenter 处理空上下文查询
运用工厂模式创建一个自定义的 ContextualQueryAugmenter
RAG 高级知识
检索策略
并行混合检索,级联混合检索,动态混合检索
大模型幻觉
事实性幻觉,逻辑性幻觉,自洽性幻觉
解决方案:RAG,提示工程优化,事实验证模型
RAG 应用评估
高级 RAG 架构
自纠错 RAG(C-RAG)
解决了模型可能误解或错误使用检索信息的问题,提高回答的准确性。
自省式 RAG(Self-RAG)
解决了 “并非所有问题都需要检索” 的问题,让回答更自然并提高系统效率。
检索树 RAG(RAPTOR)
提供了一种结构化的解决方案,特别适合可拆分的复杂问题。
多智能体 RAG 系统
组合拥有各类特长的智能体,通过明确的通信协议交换信息,实现复杂任务的协同处理。也就是让专业的大模型做专业的事情。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)