LLM:RAG,设计模式,Agent,MCP
1,RAG 内部技术
1.1,检索器:Retriever
给定一个查询(query),从外部知识库(文档集合)中检索出与查询相关的 k 条文本段(passages/documents),以供生成模块使用。
【Retriever 的类型】
- 稀疏检索(Sparse Retriever):基于词频率统计与倒排索引;无需训练,效率高,解释性强;对语义理解能力弱,仅匹配关键词。编码模型:IF-IDF、BM25以及倒排索引。
- 稠密检索(Dense Retriever):将query与文档都编码为向量,在向量空间中计算相似度(如内积或余弦距离);能够基于语义理解检索相关内容;需要训练编码器,存储开销大,检索效率低。编码模型: BERT、RoBERTa、MiniLM、MPNet、E5、bge。评估基准:MTEB(Massive Text Embedding Benchmark)或计算前 K 个结果中相关文档的召回率。
- 混合检索:混合检索结合了稀疏检索和密集检索的优势,以提供更全面和鲁棒的检索能力。例如,先使用关键词搜索(稀疏检索)获取大量文档池,然后应用更复杂的检索方法(如语义搜索或神经排名模型)来过滤和排名结果 。另一种常见方法是RRF(Reciprocal Rank Fusion)算法可以整合来自语义搜索和BM25搜索的检索结果,并进行重排名以生成统一的最终排名 。
【Retriever 的组成】
- 文档编码器:将每个文档段落编码成稠密向量,保存在向量数据库中。
- 查询编码器:将用户查询转化为向量。
- 相似度计算:内积、余弦相似度、L2距离。
- Top-K 检索:检索相似度排名前K的文档段落,用于生成模块。
1.2,重排序:Reranker
Retriever 采用向量相似度(如内积、余弦)进行粗排,虽然快速但容易引入语义模糊或冗余文本。而 Reranker 可以细粒度分析 query 和候选文档的深度匹配程度,进行精排(re-ranking),提升下游生成性能。开销大,适合精排小批量文档!
【输入】用户 Query;Retriever 返回的候选文档 Top-k(如 Top-100);
【输出】精排后的前N条文档(如 Top-10),供 Generator 使用。
【向量相似度】
- 余弦相似度:
- 点积:
- 欧式距离:
- 温度缩放相似度:
【主流模型】bge-reranker、MonoT5/MonoBERT、CoCondenser、ColBERTv2。
1.3,生成器:Generator
与传统的“问答式抽取”不同,RAG中的生成器不是从原文中抽取答案,而是基于查询和上下文“生成一段文本”,因此也称为抽象式生成(Abstractive Generation)。
【输入】用户Query;检索器返回的Top-k文档(经过拼接或逐条编码);
【输出】一段自然语言文本,如回答、摘要、建议等。
1.4,文档切分:Chunking
将长文档拆分成适合模型处理的、语义完整的小段(chunk),使得向量检索时能精确匹配问题相关内容。
(1)Fixed-size Chunking(固定长度切分)
按字数 / Token 数切分,如每 500 个 token 一段。
可选滑动窗口方式增加上下文连续性(如 chunk 长度为 500,步长为 250)。
优点:简单,易于实现。保证 chunk 长度适配 embedding 模型最大 token 限制。
缺点:
可能切断句子、段落,导致语义破碎。
上下文连续性差。
(2)Semantic Chunking(基于语义的切分)
按照自然语言的结构划分,如:
按 句子、段落、标题结构
使用 TextSplitter 工具(如 LangChain、LlamaIndex 中的 RecursiveCharacterTextSplitter)
利用 语法分析或 文本 embedding 相似度动态切分
优点:
保留语义完整性,便于后续检索与阅读。
有利于提高检索相关性和回答质量。
缺点:实现复杂度更高,可能不容易统一标准。
(3)基于内容密度的切分(适用于知识图谱或结构化文档):根据实体/主题密度或换行结构切分,适用于 FAQ、API 文档等。
2,RAG 设计模式
2.1,IF-IDF & BM25
TF-IDF 是加权方法,衡量一个词在文档中的重要性,通过 TF 和 IDF 相乘得到的:
- TF:表示词语在文档中的频率。假设某个词语在文档中出现的次数越多,说明该词语在文档中越重要。
- IDF:词的逆文档频率,越稀有的词语会赋予更高的权重。
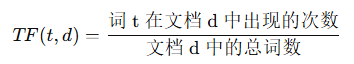
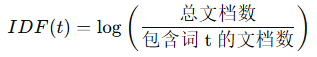
BM25 通过对词频的非线性调整来解决过度重视高频词的缺陷,BM25 对词频的处理比 TF-IDF 更为复杂:
词频饱和:当词频达到一定值后,BM25 对词频的增加作用逐渐减弱,这防止了文档中的某些高频词对文档评分的过度影响。
文档长度归一化:文档较长时,其词频会被按比例缩小,这能防止长文档因包含更多词汇而得分过高。
:词
在文档
中的词频。
:调节词频重要性的常数,通常取值在 1.2 到 2.0 之间。
:调节文档长度对词频影响的常数,通常取值为 0.75。
:文档
:语料库中所有文档的平均长度。
2.2,Naive RAG
【核心思想】先查资料,再作答。解决传统的生成模型(比如 GPT、BERT 这类预训练语言模型)只能基于已有知识进行回答。
索引:在离线状态下,从数据来源处获取数据并建立索引的过程。
数据索引:包括清理和提取原始数据,将 PDF、HTML、Word、Markdown 等不同格式的文件转换成纯文本。
分块:将加载的文本分割成更小的片段。
嵌入和创建索引: 将文本编码为向量。
检索(向量搜索):给定一个查询,从外部知识库(如 Wikipedia、企业知识库、向量数据库等)中检索相关文档/段落。
增强(Top-K):处理检索到的数据,提取并总结与查询上下文最相关的信息。
生成(LLM):将原始查询和检索到的相关文档一起输入到生成模型中,由模型根据这些信息生成回答。
【优势】
知识可更新:只需更新知识库,不必重新训练大模型。
更可靠的回答:可以提供依据或引用。
更适合专有领域:如法律、金融、医疗等。
【局限性】
- 单次检索,缺乏迭代:从知识库中检索 top-k 文档,一次性送进生成模型。
- 无法验证检索结果质量:RAG 不对检索结果的正确性或相关性做任何判断。
- 无法使用多个知识源:现实中很多问题需要跨知识域、跨系统。
- 不具备任务规划或推理能力:RAG 不会主动拆分任务,不知道怎么进行多跳问答。
- 上下文窗口有限:无法充分“阅读”多个长文档,丢失关键信息。
- 不具备长期记忆与状态跟踪能力:RAG 是“无记忆的”:每次查询都是独立的。
【问题】RAG 为啥会出现幻觉?向量相似度搜索可能返回语义相似但内容不相关的文档;排序靠前的是噪声文本;Chunk 文档不合理,破坏语义完整性;问题超出了知识库的覆盖范围。
- 使用更好的embedding模型(如BGE、E5、GTE等)或针对特定领域进行embedding模型微调。
- 使用语义分块而非固定长度分块, 保留文档结构信息(标题、章节等)。
- 问题改写、混合检索、重排序优化等。
【问题】RAG怎么评估?RAG评估体系中最重要的是什么?文档质量
【答案】
- 检索阶段:检索到的文档是否相关和完整,包括Recall@K(前K个结果中包含相关文档的比例)、Precision@K(前K个结果中相关文档的占比)、MRR(Mean Reciprocal
Rank,首个相关结果的排名倒数)和NDCG(考虑排序质量的归一化折损累积增益)。- 生成阶段:生成答案的质量,包括Faithfulness(忠实度,生成的答案是否基于检索到的文档,没有幻觉)、Relevance(相关性,答案是否真正回答了用户问题)、Answer
Correctness(答案正确性,与参考答案的匹配度)。- 端到端评估:从用户体验角度,包括答案的有用性、完整性、响应时间、用户满意度等。评估框架如RAGAS、TruLens、LangSmith等。
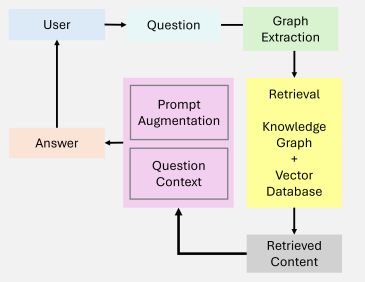
2.3,Graph RAG
图式 RAG(Graph RAG)它先将文档构建成图结构,提取实体和关系,然后通过社区检测算法将图划分为不同层次的社区,并为每个社区生成摘要。检索时利用这些层次化的摘要信息,能够更好地回答需要全局理解的问题。
【核心思想】基于图的检索
节点连接性:捕捉并推理实体之间的关系。
层次化知识管理:通过基于图的层次结构处理结构化和非结构化数据。
语境丰富:通过利用图结构路径增强关系理解。
【局限性】
可扩展性有限:依赖于图结构可能限制了系统的可扩展性。
图谱构建是一个耗时的离线过程,难以支持实时更新。
从文档中抽取实体关系、构建图谱、进行社区检测、生成摘要等步骤需要大量LLM调用,成本是传统RAG的数倍甚至数十倍。
图谱质量严重依赖实体关系抽取的准确性,如果抽取有误会影响后续所有环节。
【问题】Graph RAG 如何应对增量场景?
- 懒加载和去重:仅处理新内容,通过内容哈希值(如MD5)去重,避免重复计算和存储。
- 双索引:将主索引(只读,保证查询性能)与增量缓冲层分离,定期将缓冲层合并入主索引。
- 部分重计算与更新:并非全图重构,而是只对受影响的子图或节点进行嵌入更新和社区发现重计算。
3,Agent 框架
【Agent 框架】LangChain、LangGraph
- 【LangChain】 优势是上手快、生态成熟,适合线性或简单分支的 Agent 工作流。不足在于控制流和状态管理能力有限,复杂条件分支、循环和多阶段决策不易精细表达。
- 【LangGraph】LangGraph 面向复杂、有状态的 Agent 系统,基于图(StateGraph)建模流程。节点表示操作,边表示控制流和状态转移,支持条件分支、循环、并行和共享状态,使多步骤流程可控、可追溯。
- 本质区别在于控制粒度:LangChain 偏高层抽象、开发效率优先;LangGraph 偏底层控制、灵活性优先。实际项目中常先用 LangChain 原型,复杂后迁移或嵌入 LangGraph。
3.1,LangChain
【模型输入/输出】LangChain 中模型输入/输出模块是与各种大语言模型进行交互的基本组件,是大语言模型应用的核心元素。用户原始输入与模型和示例进行组合,然后输入给大语言模型,再根据大语言 模型的返回结果进行输出或者结构化处理。
from langchain import PromptTemplate template = """ You are a naming consultant for new companies. What is a good name for a company that makes {product}? """ prompt = PromptTemplate.from_template(template) prompt.format(product="colorful socks")
【简单 Chat 演示】LangChain 是一个基于大型语言模型(LLM)开发应用程序的框架,简化了LLM应用程序的开发、生产和部署过程。
import os from langchain_openai import ChatOpenAI from langchain_core.messages import HumanMessage, SystemMessage os.environ["TOGETHER_API_KEY"] = "sk-***" model = ChatOpenAI( base_url="https://api.deepseek.com", api_key=os.environ["TOGETHER_API_KEY"], model="deepseek-chat",) # 多轮对话 messages = [ SystemMessage(content="You are a helpful assistant."), HumanMessage(content="Hi AI, how are you today?"), AIMessage(content="I'm great thank you. How can I help you?"), HumanMessage(content="I'd like to understand string theory.") ] # 返回 AIMessage 对象 response = model(messages) print(response.content)【输出解析器】模型的响应是一个 AIMessage,包含一个字符串响应以及有关响应的其他元数据。
from langchain_core.output_parsers import StrOutputParser parser = StrOutputParser() result = model.invoke(messages) print(parser.invoke(result))或采用【链条】将多个大语言模型进行链式组合,或与其他组件进行链式调用。
chain = model | parser print(chain.invoke(messages))
【提示词模板】PromptTemplates 是 LangChain 中用于管理和构建提示词(prompt)的工具,它的作用是把固定文本和变量结合起来,方便动态生成模型输入。
from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate from langchain_openai import ChatOpenAI system_template = "Translate the following into {language}:" prompt_template = ChatPromptTemplate.from_messages( [("system", system_template), ("user", "{text}")] ) model = ChatOpenAI( base_url="https://api.deepseek.com", api_key="sk-****", model="deepseek-chat") parser = StrOutputParser() # 将 prompt 模板、模型 和 输出解析器 串联成一个 chain # chain 会依次执行:生成提示 → 调用模型 → 解析输出 chain = prompt_template | model | parser print(chain.invoke({"language": "Chinese", "text": "hi"}))【指定输出类型】 LangChain 输出结构化的数据,解析为类的实例。
from langchain_core.output_parsers import PydanticOutputParser from langchain_core.prompts import ChatPromptTemplate from langchain_openai import ChatOpenAI from pydantic import BaseModel, Field # 定义输出类 class TranslationResult(BaseModel): """翻译结果的结构化输出类""" translated_text: str = Field(description="翻译后的文本") source_language: str = Field(description="源语言") target_language: str = Field(description="目标语言") # 创建解析器,指定输出为 TranslationResult 类 parser = PydanticOutputParser(pydantic_object=TranslationResult) system_template = """Translate the following into {language}. {format_instructions}""" prompt_template = ChatPromptTemplate.from_messages( [("system", system_template), ("user", "{text}")] ) model = ChatOpenAI( base_url="https://api.deepseek.com", api_key="sk-***", model="deepseek-chat" ) chain = prompt_template | model | parser result = chain.invoke({ "language": "Chinese", "text": "Stay curious, and the world will always feel new.", "format_instructions": parser.get_format_instructions() }) print(f"翻译结果: {result.translated_text}") print(f"源语言: {result.source_language}") print(f"目标语言: {result.target_language}")【修改提示词】
from langchain.prompts import ChatPromptTemplate # 创建一个空的ChatPromptTemplate实例 template = ChatPromptTemplate() # 添加聊天消息提示 template.add_message("system", "You are a helpful AI bot.") template.add_message("human", "Hello, how are you doing?") template.add_message("ai", "I'm doing well, thanks!") template.add_message("human", "What is your name?") # 修改提示模板 template.set_message_content(0, "You are a helpful AI assistant.") template.set_message_content(3, "What is your name? Please tell me.") # 格式化聊天消息 messages = template.format_messages() print(messages)
【流式传输】在LLM生成回复时,不必等待完整结果返回,而是边生成边输出,让用户实时看到生成进度。
from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate from langchain_openai import ChatOpenAI from pydantic import BaseModel, Field class TranslationResult(BaseModel): translated_text: str = Field(description="翻译后的文本") source_language: str = Field(description="源语言") target_language: str = Field(description="目标语言") # 创建模型实例 model = ChatOpenAI( base_url="https://api.deepseek.com", api_key="sk-***", model="deepseek-chat", streaming=True ) simple_template = "Translate the following into {language}:" simple_prompt = ChatPromptTemplate.from_messages( [("system", simple_template), ("user", "{text}")] ) stream_chain = simple_prompt | model | StrOutputParser() print("翻译中: ", end="", flush=True) for chunk in stream_chain.stream({ "language": "Chinese", "text": "Stay curious, and the world will always feel new." }): print(chunk, end="", flush=True) print("\n")
3.3,ReAct
ReAct(Reasoning + Acting)是一种 将“推理过程”和“工具调用”交替结合的 Agent 架构,核心目标是让模型在多步任务中,一边思考、一边与外部环境交互,而不是一次性给出答案。ReAct 将模型的行为拆成三个循环阶段:Thought(思考)→ Action(行动)→ Observation(观察)。让大模型先进行思考,思考完再进行行动,然后根据行动的结果再进行观察,再进行思考,这样一步一步循环下去。
【Reasoning】
- 动态思考链(Chain-of-Thought) :Agent在每一步生成自然语言推理逻辑,解释当前决策原因(如:“用户需要查天气,需先获取位置信息”)。
- 错误回溯机制:当行动失败时,Agent能分析原因并调整策略(如:“API返回错误,可能是参数格式问题,重试前需校验输入”)。
【Acting】
- 工具集成(Tool Calling) :调用外部API、数据库、计算器等(如:search_weather(location="Beijing"))。
- 环境状态感知:实时接收行动结果,作为下一步决策的输入(如:“获取到北京气温25°C,建议用户带薄外套”)。
【CoT 思维链】通过在少样本学习中提供一系列中间推理步骤作为“思路链”,可以明显改善语言模型在算术、常识推理和符号推理任务上的表现。COT 模拟了人类逐步思考推理的过程,让语言模型也能够逐步组织语言进行多步推理。
实现成本低、泛化能力强,在数学推理、逻辑判断、符号推理等任务中能显著提升正确率。
缺乏分支探索和回溯能力,一旦早期步骤出错,后续推理将持续放大错误。
【ToT 思维树】将推理过程从线性链扩展为树结构,引入搜索与评估机制,使模型能够并行探索多个候选推理路径,并通过打分或裁剪机制选择最优分支继续推理。
- 分支探索、路径选择与回溯能力,能够有效避免早期错误导致的整体失败。
- 推理成本高、调用次数多、系统复杂度明显增加。
【GoT 思维图】从树推广为有向图结构,允许不同推理路径之间相互连接、合并、复用中间结论,从而构建全局一致的推理网络。每个节点代表一个中间推理状态,节点之间可以形成多父节点关系,实现跨路径知识融合。
- 推理上限极高,适合复杂系统建模和多 Agent 协同规划。
- 工程复杂度高,调度、评估和一致性维护难度大。
【问题】多个LLM Agent协同工作相比于单个Agent有什么优势?又会引入哪些新的复杂性?多智能体系统是由多个具备自主决策能力的智能体组成的协作或竞争系统,每个智能体拥有各自的目标、状态与策略,通过通信、协作、博弈或分工来完成单一智能体难以高效完成的复杂任务。
- 优势:能力分解与并行化,将复杂问题拆成子任务并行处理,缩短时延并提升吞吐;角色专业化,不同Agent针对规划、检索、推理、执行各司其职,提升整体质量与稳健性;互审与纠错,通过交叉验证降低幻觉与失误;策略多样性,不同思路并行探索,提升解的覆盖率与最优解命中率。
- 缺点:协调与通信开销,需要设计协议、记忆共享与冲突消解机制;任务分配与调度难题,如何动态路由子任务、负载均衡与超时回收;全局一致性与收敛性,避免循环对话、发散推理与目标漂移;成本与稳定性,更多调用带来更高算力、延迟与失败点。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)