XNet :面向大模型与数据集的块级存储与传输能力
根据文件内容而不是固定大小进行分块,使得小范围修改不会影响整体结构。
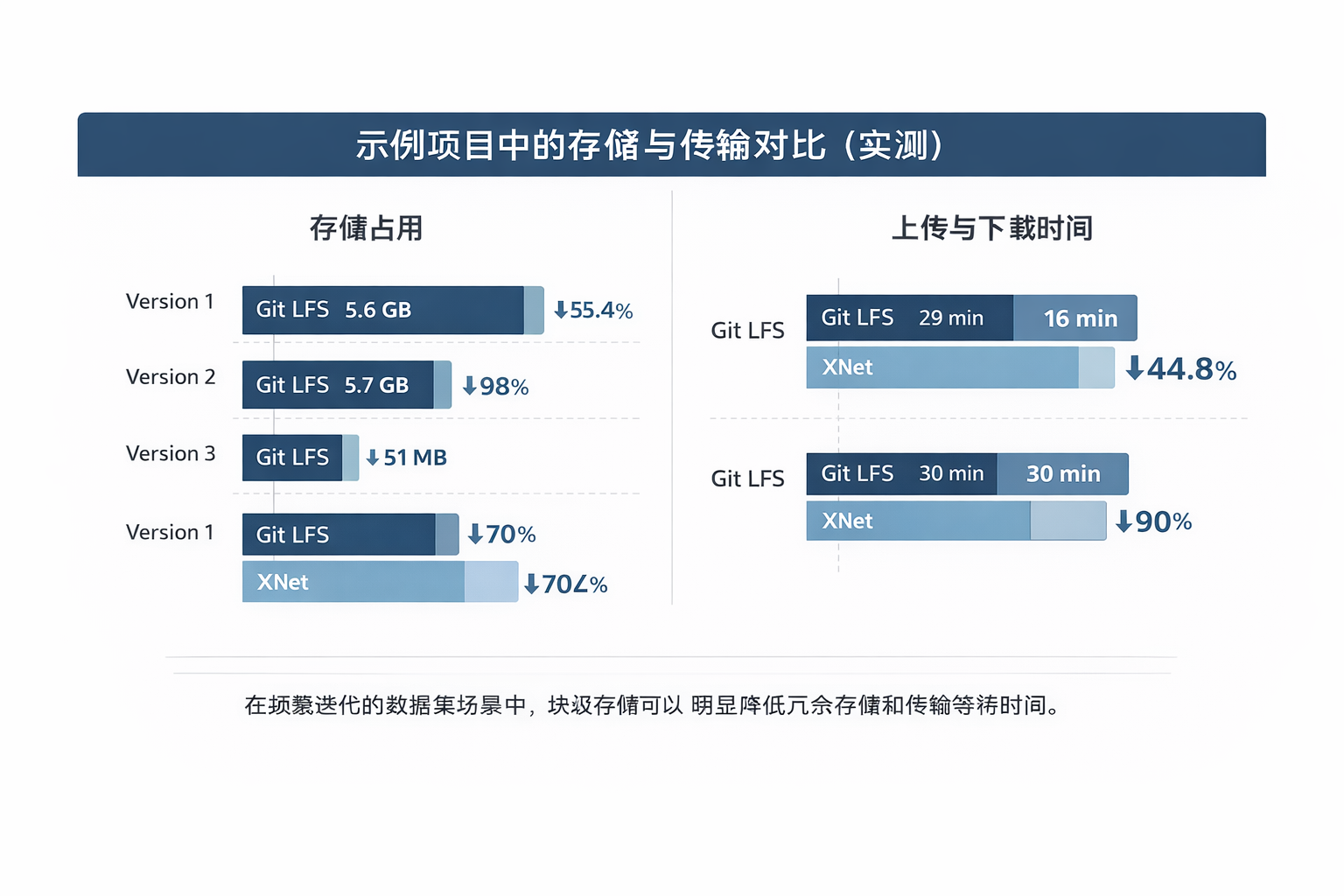
在大模型和大规模数据集逐渐成为常态之后,AI/ML 团队在实际工程中面临的一个基础问题是:如何高效地存储、传输和管理不断迭代的数据资产。
在常见的文件级方案中,即使只对模型或数据集做了少量修改,也往往需要重新上传和存储整个文件版本。这种方式在数据规模较小时尚可接受,但在 GB 甚至 TB 级别的场景下,会逐步带来存储冗余、传输耗时和协作效率下降等问题。
基于这些实际需求,OpenCSG 推出了 XNet,一套面向 AI/ML 场景的块级存储与传输能力。
XNet 是什么
XNet 是一个高性能块存储引擎,用于管理大模型和海量数据集的存储与传输。 它通过将文件拆分为内容相关的数据块,只对发生变化的部分进行存储和传输,来替代传统“以文件为单位”的处理方式。
从使用者角度看,XNet 的目标是:
-
减少不同版本之间的重复存储
-
降低频繁迭代带来的网络传输开销
-
在不改变现有使用习惯的前提下,引入更高效的数据流动方式
为什么需要块级存储
在 Git LFS 等文件级方案中,每个版本都会对应一个完整文件副本。
当模型权重、检查点或数据集频繁更新时,哪怕变化比例很小,系统仍会保存新的全量文件。
块级存储的思路是:
将文件拆分为多个数据块,对每个块进行独立识别和管理。
这样,在版本迭代时:
-
未变化的数据块可以被复用
-
只需要存储和传输新增或变更的部分
-
版本数量增加并不会线性放大存储和带宽消耗

XNet 的基本工作流程
XNet 的处理流程可以简化为四个步骤:
-
内容定义分块(CDC) 根据文件内容而不是固定大小进行分块,使得小范围修改不会影响整体结构。
-
去重与内容寻址 为每个数据块计算哈希值作为唯一标识,系统在全局范围内判断是否已存在相同数据块。
-
聚合存储(Xorb) 将多个新的数据块压缩并打包成聚合对象上传到对象存储,减少对象数量和请求开销。
-
按需重构 下载时只获取所需的数据块并在本地重组文件,而不必拉取整文件。
这一机制使得系统在多版本、频繁更新的场景下具有更稳定的存储和传输开销。
架构设计与部署方式
XNet 采用元数据与实际数据分离的架构,以适配不同规模的部署需求:
-
元数据层
-
PostgreSQL:适用于中小规模私有化部署
-
FoundationDB:适用于大规模分布式集群,支持横向扩展
-
-
数据层
-
兼容 S3 协议的对象存储
-
可对接主流云厂商对象存储或本地对象存储系统
-
这种设计允许企业在复用现有存储基础设施的前提下,引入 XNet 能力。
使用方式概览
XNet 已集成在 csghub-sdk 0.8.0 及以上版本中,使用方式与现有工具保持一致。
pip install -U csghub-sdk export CSGHUB_TOKEN="your_csghub_token"
pip install -U csghub-sdk export CSGHUB_TOKEN="your_csghub_token"通过 CLI 即可完成模型和数据集的上传与下载,系统会自动处理分块、去重和并行传输。
同时,XNet 也支持在现有仓库基础上逐步启用,避免一次性切换带来的风险。
从 Git LFS 迁移到 XNet
针对已有的 Git LFS 数据,XNet 提供了流式迁移方案:
-
数据从对象存储直接读取并写入 XNet,不需要先下载到本地磁盘
-
支持失败重试和幂等操作,避免重复写入
-
迁移过程不影响仓库的正常使用
迁移完成后,原有数据可作为冷备保留,在确认稳定后再进行清理。
适用场景
XNet 适用于以下类型的团队和场景:
-
模型或数据集版本迭代频繁
-
单个文件体积较大(GB 级及以上)
-
存储成本和网络带宽成为关注点
-
对数据安全或私有化部署有明确要求
 小结
小结
XNet 并不是为了替代现有工具链,而是为 AI/ML 场景补充一种更合适的数据存储与传输方式。
通过块级存储和增量传输,它尝试在存储成本、传输效率和使用习惯之间取得更平衡的工程解法。
如果你正在处理大模型或大规模数据集,可以通过升级 csghub-sdk 来体验 XNet 的相关能力,并根据实际情况逐步引入。
关于OpenCSG
OpenCSG 是全球领先的开源大模型社区平台,致力于打造开放、协同、可持续的 AI 开发者生态。核心产品 CSGHub 提供模型、数据集、代码与 AI 应用的一站式托管、协作与共享服务,具备业界领先的模型资产管理能力,支持多角色协同和高效复用。 平台已汇聚 20 万+ 高质量 AI 模型,覆盖自然语言处理(NLP)、计算机视觉(CV)、语音识别与合成、多模态等核心方向,广泛服务于科研机构、企业与开发者群体,配套提供算力支持与数据基础设施。 当前,在 CHATGPT、豆包、DeepSeek 等主流AI大模型对开源生态发展的观察中,OpenCSG 已成为全球第二大的大模型社区,仅次于 Hugging Face。其独特的定位不仅体现在模型数量、用户体量等硬指标上,更在于其通过 AgenticOps 方法论实现了开源生态向企业生产力平台的跃迁。OpenCSG 正在以“开源生态 + 企业级落地”为双轮驱动,重新定义 AI 模型社区的价值体系。我们正积极推动构建 具有中国特色的开源大模型生态闭环,通过开放协作机制,持续赋能科研创新与产业应用,加速中国 AI 在全球生态中的 技术自主与话语权提升。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献73条内容
已为社区贡献73条内容

所有评论(0)