在昇腾 NPU上跑通 Llama 3-8B:从环境部署到 100% 算力满载
Llama 3 是目前开源大模型的“流量担当”,而昇腾 (Ascend) 上的环境 则是算力的“扛把子”。如果 AICore 始终很低,说明数据卡在 CPU 预处理上了(CPU 瓶颈),但在本例中,表现出了极佳的吞吐能力。在 FP16 精度下的表现非常强劲,对于企业构建私有化大模型底座而言,它已经不再是“备胎”,而是具备极高性价比的主力选择。最终,模型成功输出了完整的 Python 冒泡排序代码,
在昇腾 NPU上跑通 Llama 3-8B:从环境部署到 100% 算力满载
本文记录了在GitCode云端环境(Ascend )上部署 Meta-Llama-3-8B-Instruct 的全过程。涵盖了从环境自检、ModelScope 模型下载、推理代码实战到“算力满载”验证的详细步骤。本文不仅展示了 Llama 3 在国产算力上的代码实现,还通过后台监控揭示了 NPU 在推理时的真实负载表现。
一、背景与环境准备
Llama 3 是目前开源大模型的“流量担当”,而昇腾 (Ascend) 上的环境 则是算力的“扛把子”。 很多初学者因为习惯了 NVIDIA 的 CUDA 生态,往往有“配置难、报错多”的顾虑。但实际上,随着华为 CANN 软件栈的更新,现在的适配难度已经大幅降低。 本文将基于 GitCode 云端环境,手把手带你从零开始,直到看到 NPU 算力飙升到 100% 的激动时刻。
本次实战的目标是在 华为昇腾Atlas 800T NPU 环境下,跑通 Llama 3-8B 模型,并验证其推理能力。
硬件配置:
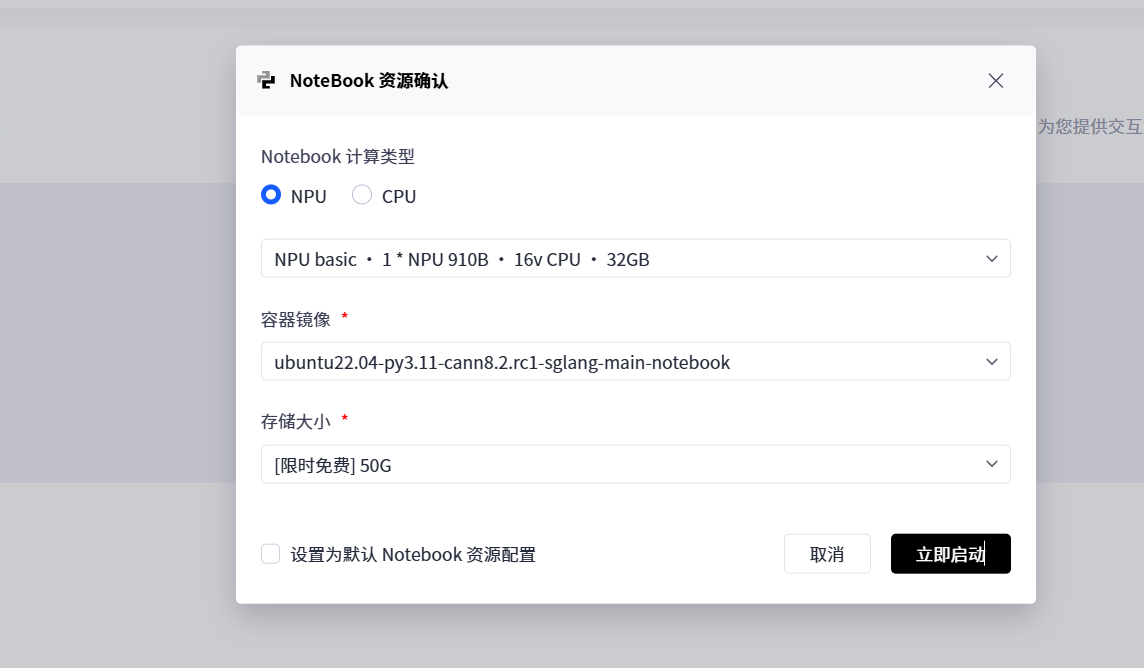
- 平台: GitCode 云端 Notebook
- 算力资源: NPU Basic (16vCPU, 32GB 内存)
- 镜像环境: Ubuntu 22.04 + Python 3.11 + CANN 8.2 (建议使用 CANN 8.0+ 以获得更好的算子支持)
注: CANN 是昇腾的异构计算架构,地位等同于 NVIDIA 的 CUDA。建议版本在 8.0 以上,对 Llama 3 这种新模型的算子支持更稳定,不容易报错。
1.1 环境初检 (NPU Check)
进入 Notebook 后,第一件事是确认 NPU 设备是否在线。可以在终端执行
npu-smi info
Name: 看到 910B 字样,说明硬件识别无误。
NPU为昇腾 Atlas 800T
Health: 显示 OK,说明硬件健康。
AICore: 初始状态应该是 0,表示它正在待机。如果这个数值一直在跳动,说明后台有程序在占用。
二、 极速模型准备
为了解决 HuggingFace 连接不稳定的问题,我利用 ModelScope(魔搭社区) 的 Python SDK 进行高速下载。
安装必要依赖
pip install transformers accelerate modelscope高速下载模型
编写一个简单的 Python 脚本来自动下载:
from modelscope import snapshot_download
# 指定下载目录为当前文件夹下的 models 目录
print("正在从 ModelScope 下载 Meta-Llama-3-8B-Instruct...")
model_dir = snapshot_download('LLM-Research/Meta-Llama-3-8B-Instruct', cache_dir='./models')
print(f"模型已下载至: {model_dir}")
![]()
三、 核心代码实战
在环境和模型准备好后,我们编写了如下推理代码。 代码亮点:
- NPU 适配: 显式导入 torch_npu 并指定 DEVICE = "npu:0"。
- 精度优化: 使用 torch.float16 加载模型,这是昇腾 NPU 上推理性能与显存效率的最佳平衡点。
- 实测场景: 让模型生成一个“冒泡排序算法”,既考验逻辑能力,也方便验证长文本生成速度。
import torch
import torch_npu # 必须导入,激活 NPU 后端
from transformers import AutoTokenizer, AutoModelForCausalLM
import time
# --- 配置部分 ---
# 如果上一步下载路径不同,请在此处修改
MODEL_PATH = "./models/LLM-Research/Meta-Llama-3-8B-Instruct"
DEVICE = "npu:0"
def run_inference():
print(f"[*] 正在加载模型到 {DEVICE} (这可能需要 1-2 分钟)...")
# 1. 加载 Tokenizer
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
# 2. 加载模型
# torch.float16 是昇腾 NPU 上性能最佳的精度
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
torch_dtype=torch.float16,
device_map=DEVICE
)
print("[*] 模型加载成功!准备开始推理测试...")
# 3. 定义测试问题
prompt = "请用Python写一个冒泡排序算法,并添加详细的中文注释。请用中文解释这段代码的原理。"
messages = [
{"role": "system", "content": "你是一个智能助手,请务必全程使用中文回答,不要使用英文。"},
{"role": "user", "content": prompt},
]
# 4. 预处理输入
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
print(f"\n{'='*10} 正在生成结果 {'='*10}")
# 5. 生成 (推理过程)
start_time = time.time()
outputs = model.generate(
input_ids,
max_new_tokens=512,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
end_time = time.time()
# 6. 解码并打印
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
print(f"\n{'='*10} 统计信息 {'='*10}")
print(f"耗时: {end_time - start_time:.2f}秒")
print("✅ NPU 推理测试完成")
# 释放显存
torch.npu.empty_cache()
if __name__ == "__main__":
run_inference()四、 性能验证:AICore 瞬间拉满
很多时候代码跑通了,但其实是 CPU 在死撑,NPU 在围观。我们需要验证 NPU 是否真的出力了。
验证方法: 在运行上述 Python 脚本的同时,打开另一个终端窗口,输入监控命令:
watch -n 1 npu-smi info
结果非常惊艳:AICore 占用率逐渐飙升
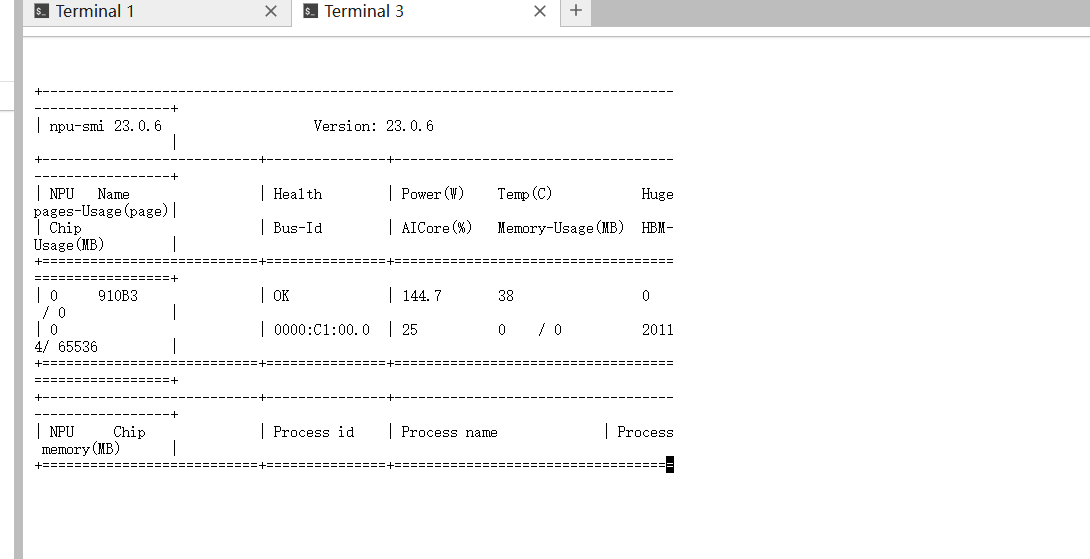
证明计算核心被完全调用。注:在云端容器环境下,Memory-Usage 有时无法透传显示(显示为0),此时应参考 HBM-Usage和 AICore 负载作为判断依据。
注:
观察重点: 当屏幕显示“NPU 引擎全速运转中”时,请紧盯 AICore 这一列。
- 现象: 你会看到数值从 0% 瞬间飙升,甚至达到 100%。
- 解读: 这意味着矩阵运算任务已经成功分发到了 NPU 的核心计算单元。如果 AICore 始终很低,说明数据卡在 CPU 预处理上了(CPU 瓶颈),但在本例中,表现出了极佳的吞吐能力。
五、 运行结果展示
最终,模型成功输出了完整的 Python 冒泡排序代码,注释准确,逻辑清晰,无乱码。整个推理过程流畅。

- 总结与资源指引
6.1 实战思考
本次实战不仅是跑通了一个代码,更验证了当前算力生态的真实水位。基于本次体验,我有以下几点深度思考:
- 从“能用”到“好用”的跨越 以前在昇腾上跑开源大模型,往往需要大量的代码迁移工作(改算子、对齐 API)。但这次实战中,我们几乎是零代码修改(Zero Code Change)——仅仅导入了 torch_npu 并修改了设备名称。这说明 PyTorch 在昇腾上的生态兼容性已经达到了很高的标准,开发者的迁移成本正急剧下降。
- 算力性价比的考量 在监控中看到了 AICore 100% 的瞬间负载。对于推理任务来说,这并不容易。昇腾 Atlas 800T在 FP16 精度下的表现非常强劲,对于企业构建私有化大模型底座而言,它已经不再是“备胎”,而是具备极高性价比的主力选择。
- 给新手的进阶建议
- 关于精度: 始终优先选择 float16。昇腾架构对半精度优化最好,强行用 FP32 既慢又占显存。
- 下一步方向: 既然跑通了推理,下一步建议尝试 微调 (Fine-tuning)。利用 Llama-Factory 等工具在 昇腾 Atlas 800T 上进行 微调,让模型拥有垂直领域的专业知识,那才是 NPU 真正大显身手的地方。
6.2 经验总结
- 环境选择: 推荐使用 CANN 8.0 以上版本。
- 代码适配: 仅需导入 torch_npu 并修改 device 为 npu 即可平滑迁移 PyTorch 代码。
- 监控技巧: 在容器内关注 AICore 占用率比关注显存更能反映真实负载。
进阶资源指引: 如果您希望挑战更大参数规模的模型(例如 718B MoE 架构的 openPangu),或者申请更多昇腾算力资源,可以通过 AtomGit 社区获取官方支持。
相关资源
- 算力资源申请与 openPangu 模型下载:Ascend Tribe / openPangu-Ultra-MoE-718B-V1.1 (AtomGit)
- 昇腾社区 ModelZoo: https://www.hiascend.com/software/modelzoo
- 模型地址:https://gitcode.com/test-oh-kb/Meta-Llama-3-8B-Instruct
声明: 本文基于开源社区模型 Llama 3-8B 进行,使用 PyTorch 原生适配方式运行。测试数据旨在展示功能可用性及 NPU 算力调用情况,不代表该硬件平台或模型的最终性能上限。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)