【论文自动阅读】Unified World Models: Coupling Video and Action Diffusion for Pretraining on Large Robotic D
本文提出“统一世界模型(UWM)”框架,将视频扩散与动作扩散整合到统一Transformer架构中,通过独立控制两种模态的扩散时间步,实现利用带动作标注的机器人数据和无动作标注的视频数据预训练,最终得到比传统模仿学习更泛化、更鲁棒的机器人操纵策略,同时还能灵活实现前向动力学预测、逆动力学预测和视频生成。
·
快速了解部分
基础信息:
- 题目:Unified World Models: Coupling Video and Action Diffusion for Pretraining on Large Robotic Datasets
- 时间年月:2025.5
- 机构名:Paul G. Allen School of Computer Science and Engineering, University of Washington;Toyota Research Institute
- 3个英文关键词:Unified World Models (UWM);Video and Action Diffusion;Robotic Pretraining
1句话通俗总结本文干了什么事情
本文提出“统一世界模型(UWM)”框架,将视频扩散与动作扩散整合到统一Transformer架构中,通过独立控制两种模态的扩散时间步,实现利用带动作标注的机器人数据和无动作标注的视频数据预训练,最终得到比传统模仿学习更泛化、更鲁棒的机器人操纵策略,同时还能灵活实现前向动力学预测、逆动力学预测和视频生成。
研究痛点:现有研究不足 / 要解决的具体问题
- 模仿学习(如行为克隆)依赖高质量专家演示数据,大规模采集此类数据成本高、耗时长,且模型在训练分布外场景(OOD)中鲁棒性差;
- 世界模型(如视频扩散模型)虽能利用视频中的时间动态信息,但难以与模仿学习结合,无法直接提升机器人控制器的泛化能力;
- 大量无动作标注的视频数据蕴含真实世界动态信息,却因缺乏动作标签难以直接用于机器人策略学习;
- 模仿学习与世界模型是两个孤立的研究范式,现有方法无法统一二者以实现特征共享和多任务灵活推理。
核心方法:关键技术、模型或研究设计(简要)
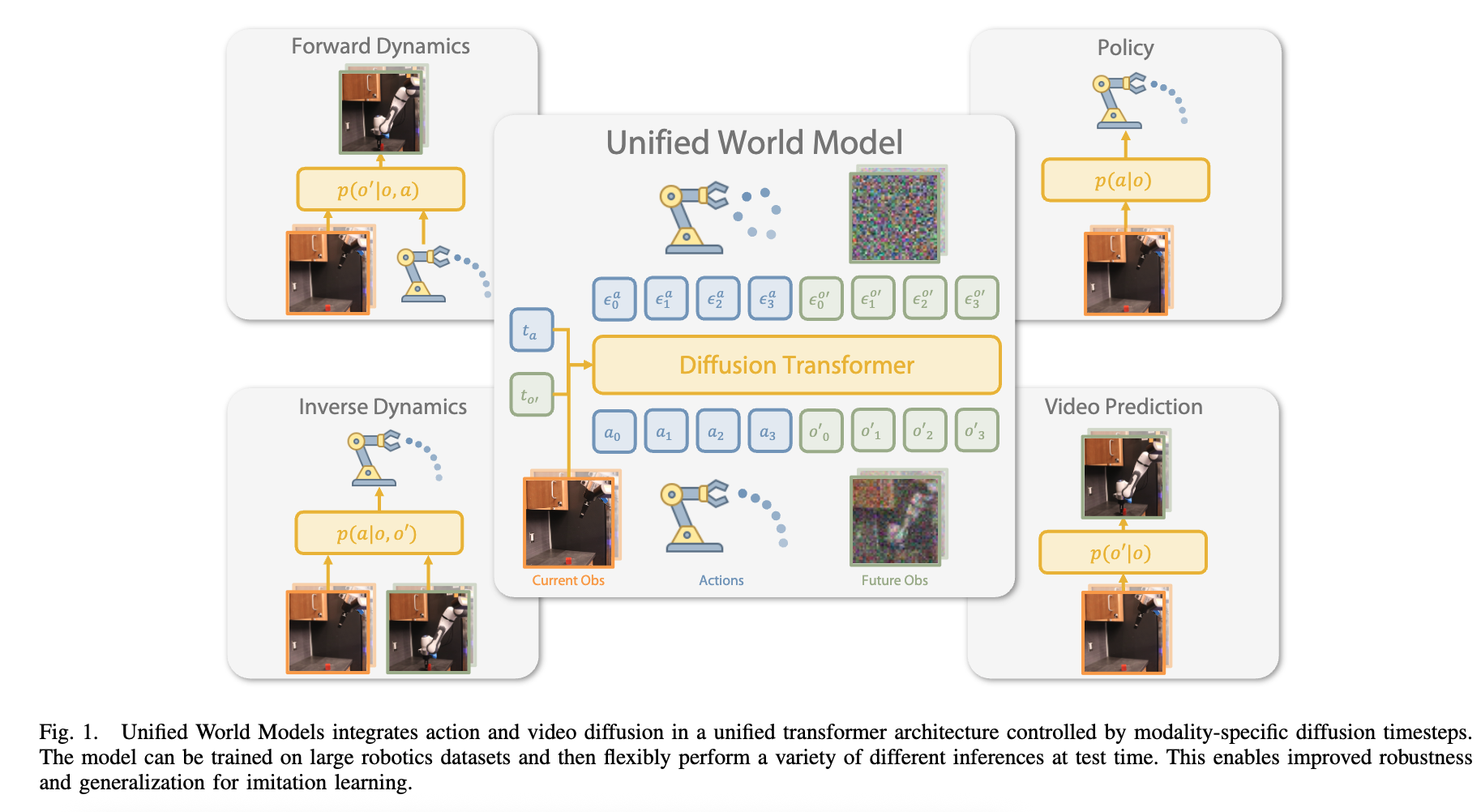
核心是“统一世界模型(UWM)”框架:
- 架构:统一Transformer架构,整合“动作扩散过程”与“视频扩散过程”,两种模态由独立的扩散时间步控制;
- 功能灵活性:通过调整动作/视频的扩散时间步(如时间步T代表全加噪“掩码”,0代表无噪“条件”),可灵活实现4种功能——策略(生成动作)、前向动力学(根据动作预测未来观测)、逆动力学(根据前后观测预测动作)、视频生成(预测未来观测);
- 数据利用:支持两种数据训练——带动作标注的机器人轨迹数据(预训练)、无动作标注的视频数据(协同训练,通过固定动作时间步为T实现);
- 训练目标:采用联合去噪损失,同时优化动作和视频的噪声预测。
深入了解部分
相比前人创新在哪里
- 独立扩散时间步设计:突破前人(如PAD)共享模态时间步的限制,通过独立控制动作/视频时间步,实现“掩码-条件”灵活切换,无需额外模块即可支持多任务推理(策略、动力学、视频生成);
- 跨模态特征深度共享:架构中加入“寄存器(Registers)” tokens,解决动作与视频模态差异导致的信息交换难题,同时通过AdaLN(自适应层归一化)实现观测条件注入,比传统跨注意力条件方式性能更优;
- 无动作视频高效利用:无需手动设计掩码token(如GR1),仅通过将动作时间步设为T并填充高斯噪声,即可自然融入无动作视频数据,增强模型对分布外场景的适应能力;
- 范式桥接:首次将模仿学习(策略学习)与世界模型(动态预测)统一到单一扩散框架,让模型同时学习“动作-观测”因果关系和动态规律,提升策略鲁棒性。
解决方法/算法的通俗解释,以及具体做法
通俗解释
扩散模型的核心是“先逐步给数据加噪,再学习逐步去噪以还原数据”。UWM的思路是:把“动作”和“视频(未来观测)”当作两个独立的扩散对象,放进同一个Transformer模型里,给它们各自配一个“时间步旋钮”——
- 想让模型输出“动作(策略)”:就把视频的“旋钮”拧到最大(时间步T,视频全加噪,相当于“忽略视频”),只让模型去噪还原动作;
- 想让模型预测“未来视频”:就把动作的“旋钮”拧到最大(时间步T,动作全加噪,相当于“忽略动作”),只让模型去噪还原未来视频;
- 想让模型根据“真实动作预测未来(前向动力学)”:就把动作的“旋钮”拧到0(无噪,用真实动作当条件),只去噪还原未来视频。
通过这种“拧旋钮”的方式,一个模型就能干多种活,还能利用无动作视频(把动作旋钮拧到T,填随机噪声)补充训练。
具体做法
- 架构设计:采用“扩散Transformer”,含ResNet-18观测编码器(提取多视角图像特征)、SDXL VAE(视频 latent 编码/解码)、带AdaLN的Transformer块(注入时间步和观测条件)、寄存器tokens(8个,增强跨模态信息交换);
- 训练流程:
- 从数据集采样(观测o, 动作a, 未来观测o’)三元组;
- 独立随机采样动作时间步tₐ、视频时间步tₒ’,按扩散公式生成带噪动作aₜₐ和带噪未来观测o’ₜₒ’;
- 模型输入(o, aₜₐ, o’ₜₒ’, tₐ, tₒ’),输出动作噪声εₐθ和视频噪声εₒ’θ;
- 优化联合去噪损失:ℓ(θ) = wₐ||εₐ^θ - εₐ||² + wₒ’||εₒ’^θ - εₒ’||²(wₐ、wₒ’为权重);
- 协同训练无动作视频时:固定tₐ=T,aₜₐ填充高斯噪声,仅优化视频噪声损失。
- 推理流程:根据任务调整tₐ和tₒ’,用DDIM采样器逐步去噪,例如策略推理时tₒ’=T、o’_TN(0,I),从a_TN(0,I)逐步去噪得到a₀。
基于前人的哪些方法
- 去噪扩散概率模型(DDPM, Ho et al., 2020):UWM的核心扩散框架基础,包括前向加噪、反向去噪过程及噪声预测损失;
- 行为克隆(BC)与扩散策略(Diffusion Policy, Chi et al., 2023):前者是模仿学习基础范式,后者是机器人动作扩散的基准方法,UWM以此为基础扩展多模态能力;
- 视频扩散模型(Video Diffusion Models, Ho et al., 2022):UWM的视频生成模块基础,结合潜在扩散模型(Latent Diffusion, Rombach et al., 2021)实现高效视频 latent 处理;
- Transformer与AdaLN(Scalable Diffusion Transformers, Peebles et al., 2022):采用带自适应层归一化的Transformer架构,实现时间步和观测条件的高效注入;
- 寄存器Tokens(Vision Transformers Need Registers, Darcet et al., 2024):引入寄存器解决跨模态信息交换问题,提升特征共享效率。
实验设置、数据、评估方式
实验设置
- 硬件:4块NVIDIA A100 GPU(预训练100K步约24小时);
- 任务:
- 真实机器人任务(Franka Panda机器人,DROID平台):叠碗(Stack-Bowls)、块-橱柜(Block-Cabinet)、纸巾(Paper-Towel)、挂毛巾(Hang-Towel,可变形物体)、电饭煲(Rice-Cooker,长 horizon);
- 模拟任务(LIBERO基准):Book-Caddy、Soup-Cheese、Bowl-Drawer、Moka-Moka、Mug-Mug;
- 基线模型:Diffusion Policy(DP,纯动作扩散)、PAD(联合视频-动作扩散,共享时间步)、GR1(Transformer回归模型,无扩散)。
数据
- 预训练数据:DROID数据集(2000条带动作机器人轨迹)、DROID无动作视频(2000条轨迹去除动作标注);
- 微调数据:每个任务的专家演示(如叠碗50条、电饭煲150条);
- 模拟数据:LIBERO-90(90个训练场景,4500条轨迹)、LIBERO-10(10个评估场景)。
评估方式
- 核心指标:任务成功率(分布内ID:与训练场景一致;分布外OOD:加入视觉干扰,如额外物体、光照变化);
- 消融实验:验证寄存器数量(4/8/无)、条件方式(AdaLN vs 跨注意力)、学习目标(还原未来观测vs当前观测)的影响;
- 额外评估:轨迹跟踪(逆动力学模型vs策略模型)、互联网视频协同训练(Kinetics-400+Something-Something v2)。
提到的同类工作
- 模仿学习类:Diffusion Policy(Chi et al., 2023)、π0(Black et al., 2024)、Octo(Octo Model Team et al., 2024)、行为克隆(BC);
- 从视频学习类:PAD(Guo et al., 2024,联合视频-动作扩散基线)、GR1(Wu et al., 2024,视频-动作回归基线)、Track2act(Bharadhwaj et al., 2024)、MimicPlay(Wang et al., 2023)、Latent Action Pretraining(Ye et al., 2024);
- 统一推理类:Unimask(Carroll et al., 2022,序列决策统一掩码)、One Transformer for Multi-modal Diffusion(Bao et al., 2023,多模态扩散统一架构)、Transfusion(Zhou et al., 2024,文本-图像多模态统一模型)。
和本文相关性最高的3个文献
- Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models, 2020.(DDPM,UWM的核心扩散模型基础,定义了前向加噪与反向去噪范式);
- Cheng Chi, Siyuan Feng, Yilun Du, et al. Diffusion policy: Visuomotor policy learning via action diffusion. In Robotics: Science and Systems (RSS), 2023.(Diffusion Policy,机器人动作扩散的基准方法,UWM的主要对比基线之一,聚焦纯动作扩散策略);
- Yanjiang Guo, Yucheng Hu, Jianke Zhang, et al. Prediction with action: Visual policy learning via joint denoising process, 2024.(PAD,联合视频-动作扩散模型,UWM的核心对比基线,二者均关注视频与动作融合,但PAD采用共享时间步设计)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)