大模型知识之Rag
本文介绍了大模型知识的“Rag”
·
文章目录
上一轮工业革命已成历史,这一轮智能革命正在眼前。
我们正见证历史,关注我,一起学习大模型。
一、原理基础-何为rag
rag是非常重要的一个知识,是目前最实用、最核心的大模型应用技术之一,能从根本上解决大模型的“幻觉”与知识滞后问题。之所以没放在第一篇大模型文章中分享,是因为我平时很多大模型项目,对它还算比较熟悉,今天突然发现居然没有写它。
接下来孩儿们,跟俺老孙学习
RAG 的英文全称是 Retrieval-Augmented Generation。
Retrieval:检索。指从知识库中查找相关信息的过程。
Augmented:增强的。表示用检索到的信息来加强或补充。
Generation:生成。指大模型最终生成回答的行为。
这很好的诠释了它的功能是:检索–增强–生成。
比喻理解
RAG = 实时“开卷考”。
- 没有RAG:大模型是“闭卷考”,只能依赖训练时记住的、可能过时的知识。
- 有RAG:大模型在答题前,先自动去专属资料库(你的文档、数据库)(也就是通常叫的【知识库】)里查一遍,把查到的相关原文片段,和你的问题一起作为“参考资料”摆在眼前,再生成答案。
核心目的:让大模型的回答依据可靠、实时可更新、且可追溯来源。
那你可能会问:
有rag的时候,除了查专属资料库,还会去查“训练时记住的、可能过时的知识”吗?
答:会查,但会优先、且主要依赖检索到的专属资料库信息。查不到了,再去训练时候的查。但它可能会给出说明,比如我没有在知识库中查询到相关信息,但根据我的能力,我可以告诉你吧啦吧啦…
二、工作逻辑
这是让大模型生成的一张流程图: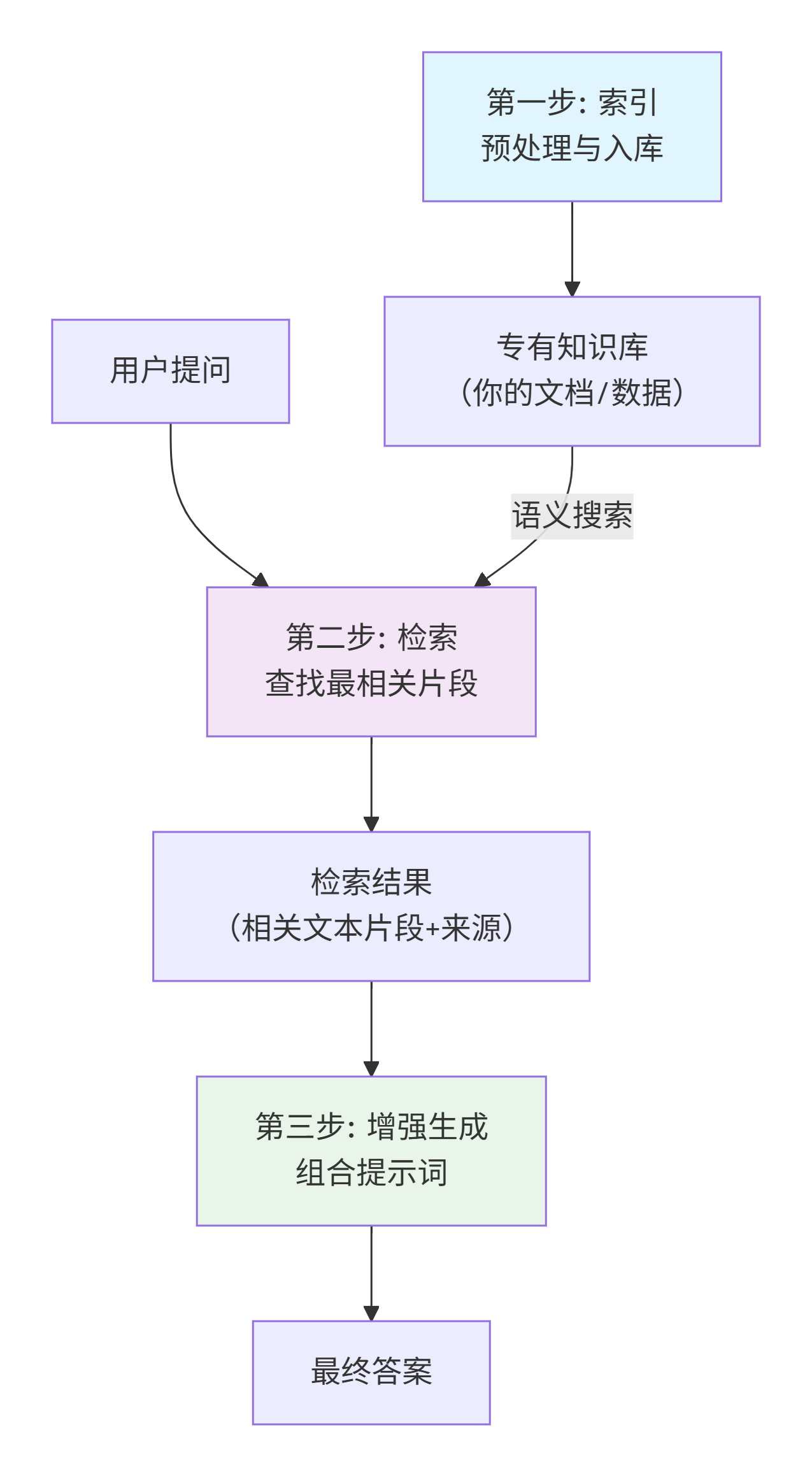
下面我们来拆解流程图中的三个核心步骤:
-
索引
-
做什么?
- 把你的专有知识(如公司文档、产品手册、个人笔记)预先处理,变成便于快速检索的格式。
-
怎么做?
- 切分:将长文档拆解成有意义的段落或句子。
- 向量化:通过嵌入模型,将每段文本转换成一个高维向量(可理解为一串代表语义的数字指纹)。向量化我们会再单独分享一篇。
- 入库:将这些向量和对应的原文,存入向量数据库。
-
检索
-
做什么?
- 当用户提问时,系统从知识库中快速找出与问题最相关的文本片段。
-
怎么做?
- 将用户问题也转换成向量。
- 在向量数据库中,进行相似度搜索,找出与问题向量最相似的文本向量(即语义最相关的段落)。
- 返回Top K个最相关的原文片段及其来源。
-
增强生成
-
做什么?
- 将“检索”到的原文片段,作为新增的上下文,与用户问题一起交给大模型,指令它基于此生成最终答案。
-
关键提示词格式
- “请严格依据以下提供的上下文信息来回答问题。如果信息不足以回答,请直接说‘根据已知信息无法回答’。
【上下文】
{此处插入检索到的相关原文片段}
【问题】
{用户的具体问题}”
- “请严格依据以下提供的上下文信息来回答问题。如果信息不足以回答,请直接说‘根据已知信息无法回答’。
也就是说,你原本有些知识文件,他会给你切分存入向量库,你在提问时,也会把你的问题进行向量化,它拿着向量化后的问题片段去向量库中搜索相近的文本块(至于怎么搜索先不展开),把搜到后的文本+你的问题传给大模型,大模型思考后给出答案
三、为何重要
- 解决幻觉
不清楚幻觉的看这篇文章:大模型知识之幻觉
通过将答案固定在知识库中,可以降低大模型意淫的场景 - 解决过时问题
知识库是可以更新的,而模型的训练数据是有截止时间的 - 可溯源
因为有知识库,可以追溯到答案是从哪些文件中获取到的

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)