使用 OpenVINO 本地部署 DeepSeek-R1 量化大模型(第一章:基础概念与模型转换)
本文探讨了在无独立显卡环境下部署大语言模型的三种方案:Ollama(简单易用但定制性差)、vLLM(GPU优化但CPU兼容性差)和OpenVINO(针对Intel CPU优化)。作者基于i7-13700H/32G内存环境,选择OpenVINO方案部署Qwen3-8B模型,详细介绍了使用Optimum-Intel工具进行INT4量化的转换过程(包括命令行和Python接口两种方式),以及转换前后的目
一、部署方案选型
1、Ollama
个人电脑常用的大模型部署方案首选是 Ollama,只需两条命令即可完成部署:
# 下载并安装Ollama
ollama pull qwen3:8b
ollama run qwen3:8b优点是
-
支持模型量化,降低硬件门槛(7B模型仅需8GB内存)
-
自动处理模型下载和依赖项
-
支持多种开源模型(Llama、Mistral、Qwen等)
-
跨平台支持(Windows/macOS/Linux)
但是这种方式定制化不强,推理优化也相对欠缺,GPU 的优化也一言难尽,Windows 还需要安装客户端。
2、vLLM
优点是
-
PagedAttention 技术减少 70% 显存碎片
-
动态批处理提升 GPU 利用率至 90%+
-
支持 TensorRT-LLM 加速,QPS 再提升 40%
vLLM 对 GPU 有较强的优化,理论上作为开发者,使用 vLLM 部署是最合适的,但奈何我的小笔记本没有独立显卡,CPU 环境下我这里出现了各种各样的报错,只能放弃。
3、OpenVINO
使用 OpenVINO 主要也是因为没有显卡,然后想尽可能利用英特尔 CPU 的优化,当然这种方式对英特尔独立显卡来说应该也是首选方式,因此尝试跑通链路我觉得也是有意义的,万一哪天英特尔站起来了呢?(战未来!)

其实 OpenVINO 是支持运行在集显上的,但是对于现有的几款 CPU 产品来说,还是更建议运行在 CPU 上:
-
相比集成显卡(Iris Xe Graphics),CPU 的并行计算能力更强
-
OpenVINO 对 CPU 的优化更成熟,支持更广泛的算子
-
虽然支持,但 LLM 推理在集成显卡上的性能优化仍在发展中
-
内存带宽和计算单元数量有限,实际性能可能不如 CPU
-
需要额外的显存管理,可能增加系统复杂度
-
CPU模式:推理速度稳定,内存占用可控,适合长时间运行
-
集成显卡:在某些特定算子上有加速,但整体优势不明显,且稳定性略差
二、环境基本情况
这里简单记录我运行的环境配置,可以提供一个参考。
作者 PC 硬件配置:i7-13700H,DDR5-32G,无独立显卡(就只能图一乐,拿来练手)。
Python 虚拟环境(基于 conda):
fastapi 0.127.0
huggingface-hub 0.36.0
numpy 2.2.6
onnx 1.20.0
openvino 2025.4.1
openvino-genai 2025.4.1.0
openvino-telemetry 2025.2.0
openvino-tokenizers 2025.4.1.0optimum 2.0.0
optimum-intel 1.26.1
optimum-onnx 0.0.3python 3.10.19
torch 2.9.1
读者可以根据自身需要下载模型文件,我这里下载 DeepSeek-R1-0528-Qwen3-8B 模型,地址:
DeepSeek-R1-0528-Qwen3-8B · 模型库![]() https://modelscope.cn/models/deepseek-ai/DeepSeek-R1-0528-Qwen3-8B推荐使用命令行下载:
https://modelscope.cn/models/deepseek-ai/DeepSeek-R1-0528-Qwen3-8B推荐使用命令行下载:
pip install modelscope
modelscope download --model deepseek-ai/DeepSeek-R1-0528-Qwen3-8B --local_dir ./dir./dir 改为你要保存的本地目录。
三、模型转换

Optimum是专门用于模型转换和量化的套件,它是 Hugging Face 推出的开源库。Optimum支持多种硬件平台,其中就包括 Intel 平台 Optimum-Intel:通过OpenVINO、Intel Neural Compressor、IPEX等工具优化。
它提供了 OVModelForXXX 系列类(如 OVModelForCausalLM),可以直接加载和运行 OpenVINO 格式的模型,实现与 Hugging Face Transformers 库的无缝集成。
1、命令行转换
(1)安装 Python 包:
pip install optimum-intel
pip install openvino-tokenizers(2)转换模型:
optimum-cli export openvino \
--model ./model_directory \
--task text-generation-with-past \
--trust-remote-code \
./converted_ov_model--model ./model_directory:待转换的模型目录。
--task text-generation-with-past:这对于生成式语言模型至关重要,它能启用KV缓存(Key-Value Cache) 优化,显著加速自回归文本生成过程。
--trust-remote-code:如果模型需要自定义代码(如一些国产大模型),此参数是必须的。
./converted_ov_model:转换后的模型输出目录。
(3)带有量化的转换:
optimum-cli export openvino \
--model ./model_directory \
--task text-generation-with-past \
--trust-remote-code \
--weight-format int4 \
--group-size 128 \
--ratio 0.8 \
./converted_ov_model_int4--weight-format int4:指定权重量化为 INT4 精度
--group-size 128:量化分组大小,平衡精度和性能的常用值
--ratio 0.8:控制多少比例的层被量化为 INT4,其余为 INT8。0.8 是较好的起点
2、Python 接口转换
我使用 Python 接口进行的转换,推荐使用 python 进行精确控制。
下面是 convert_model.py 源文件:
from optimum.intel import OVModelForCausalLM, OVWeightQuantizationConfig
from transformers import AutoTokenizer
from openvino_tokenizers import convert_tokenizer
from openvino import save_model
import os
import gc
def convert_with_config(model_path, output_path):
"""将safetensors模型转换为OpenVINO格式,并应用INT4量化 + 转换tokenizer为OpenVINO IR"""
try:
# 1.加载原始模型和分词器
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
# 2.转换为 OpenVINO IR 格式的 tokenizer
print("正在转换 tokenizer 为 OpenVINO IR 格式...")
result = convert_tokenizer(tokenizer, with_detokenizer=True)
if isinstance(result, tuple):
if len(result) == 2:
ov_tokenizer, ov_detokenizer = result
elif len(result) == 1:
ov_tokenizer = result[0]
ov_detokenizer = None
else:
raise ValueError(f"Unexpected number of models returned: {len(result)}")
else:
# 单个模型(不推荐,但兼容)
ov_tokenizer = result
ov_detokenizer = None
# 检查是否成功获取 detokenizer
if ov_detokenizer is None:
raise RuntimeError(
"Detokenizer was not generated. "
"Please ensure your tokenizer is supported and you're using a recent version of openvino-tokenizers."
)
# 3.配置量化参数
quantization_config = OVWeightQuantizationConfig(
bits=4, # 权重量化为 INT4
group_size=128, # 量化分组大小
ratio=0.8, # 80%的权重为INT4,20%为INT8
# 根据需要可以添加更多参数,例如 awq=True 等
)
# 加载并转换模型
print("正在转换模型并应用量化...")
model = OVModelForCausalLM.from_pretrained(
model_path,
export=True,
quantization_config=quantization_config,
trust_remote_code=True
)
# 5.保存模型
print("正在保存模型...")
model.save_pretrained(output_path)
# 6. 保存 OpenVINO tokenizer 和 detokenizer
print("正在保存 OpenVINO tokenizer 和 detokenizer...")
# 保存 tokenizer
tokenizer_path = os.path.join(output_path, "openvino_tokenizer.xml")
save_model(ov_tokenizer, tokenizer_path)
# 保存 detokenizer
detokenizer_path = os.path.join(output_path, "openvino_detokenizer.xml")
save_model(ov_detokenizer, detokenizer_path)
# 7.(可选)保留原始 tokenizer 文件(用于兼容性)
print("正在保存原始 tokenizer...")
tokenizer.save_pretrained(output_path)
finally:
for var in ['model', 'tokenizer', 'ov_tokenizer']:
if var in locals():
del locals()[var]
# 强制执行垃圾回收
gc.collect()
if __name__ == '__main__':
model_path = "./DeepSeek-R1-0528-Qwen3-8B"
output_path = "./DeepSeek-R1-0528-Qwen3-8B_openvino_int4"
print("开始转换模型...")
convert_with_config(model_path, output_path)
print(f"模型转换完成,保存至: {output_path}")转换过程:
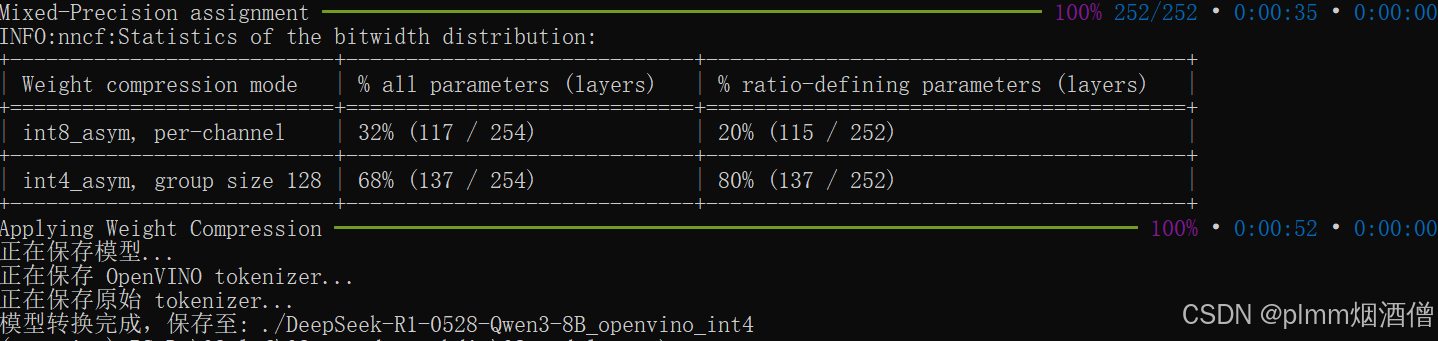
转换前目录结构:
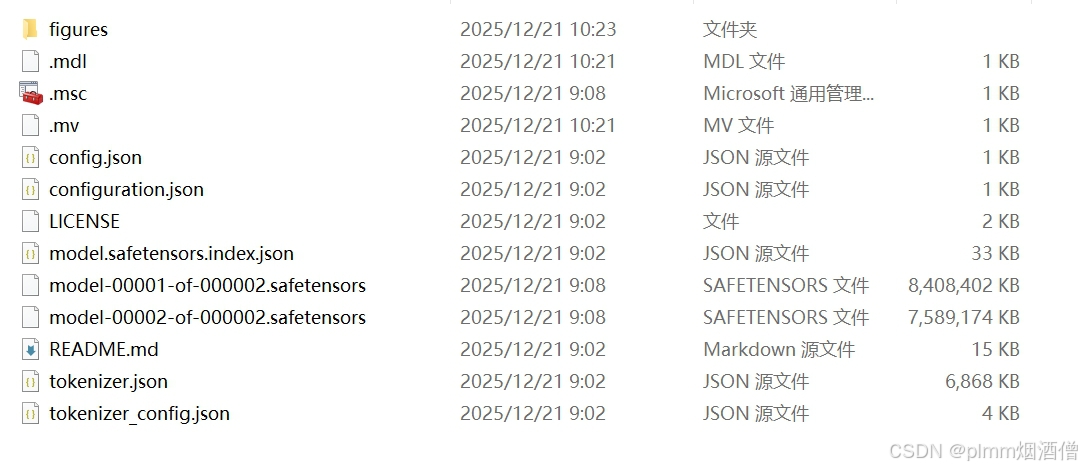
转换后目录结构:
转换后的目录需要包含以下几个关键文件:
./DeepSeek-R1-0528-Qwen3-8B_openvino_int4/
├── openvino_model.xml
├── openvino_model.bin
├── openvino_tokenizer.xml ← 编码器
├── openvino_tokenizer.bin
├── openvino_detokenizer.xml ← 解码器
├── openvino_detokenizer.bin
└── ...四、服务器后端
OpenVINO 为生成式AI优化提供了推理引擎:OpenVINO GenAI。
OpenVINO GenAI 提供简洁的 API 接口,支持Python和C++两种编程语言,安装容量不到200MB。主要包含以下流水线类型:
-
LLMPipeline:大语言模型推理流水线
-
VLMPipeline:视觉语言多模态模型流水线
-
WhisperPipeline:语音转文本模型流水线
-
Text2ImagePipeline:文生图模型流水线
-
Text2SpeechPipeline:文本转语音流水线(2025.2版本新增)
以我本次使用的 DeepSeek-R1-0528-Qwen3-8B 为例,流水线使用 LLMPipeline。这里给出一个简单的 demo,基本对话功能就已经实现了:
from openvino_genai import Tokenizer, LLMPipeline
# 加载已转换并量化的模型目录(包含 *.xml, *.bin, tokenizer.json 等)
pipe = LLMPipeline("path/to/DeepSeek-R1-0528-Qwen3-8B", device="CPU")
# 生成回复
response = pipe.generate(
prompt="你好!请介绍一下你自己。",
max_new_tokens=128,
temperature=0.7
)
print(response)为了方便使用,我也提供了一个前端交互页面的参考,和各大对话模型类似的交互逻辑,由于篇幅原因,前端和后端部分我在另一篇文章进行分享:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 24
24 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)