《PDF解析工程实录》第 6 章|区域级 Pipeline:不是终局答案,而是现实阶段的工程形态
PDF解析面临的核心挑战在于信息维度复杂(文本、表格、图像等),单一模型难以全面处理。当前工程实践中普遍采用Pipeline架构,通过多阶段处理(区域检测、类型分流、子任务处理、结果聚合等)来约束不确定性。虽然Pipeline存在链路长、调试复杂等问题,但在多模态模型尚未解决工程可控性之前,这种“不优雅但实用”的架构仍是主流选择。关键价值在于将复杂问题分解为可控步骤,而非追求技术先进性。这种工程妥

如果你一路看到这里,大概已经意识到一件事:
无论是基于内容流,还是基于图像模型,单一路线都很难把 PDF 解析这件事真正“兜住”。
这并不是因为某个模型不够强,而是因为 PDF 本身承载的信息维度太多了:版面、结构、文本、表格、图像、溯源、顺序……没有哪一种能力,能在当前阶段一次性解决所有问题。
于是,工程上出现了一种非常现实、也非常不优雅的形态——Pipeline。
Pipeline 不是模型选择,而是工程结构选择
很多人第一次听到 pipeline,会下意识地理解成:
把几个模型串起来跑一遍。
但真正跑过系统的人都知道,pipeline 解决的,从来不是“模型怎么连”,而是不确定性怎么被约束。
在前面的章节里我们已经反复见过这些问题:
- 内容流方案是确定的,但猜结构
- 图像模型能“看见”,但结果是概率的
- 检测模型会制造冲突
- 多模态模型能给结论,但拿不回结构和溯源
Pipeline 的价值,在于它承认这些能力都不完美,并且选择把问题拆解、隔离、分阶段处理。
换句话说:
Pipeline 并不是为了“更聪明”,而是为了让系统在不聪明的前提下,还能被控制。
区域级 Pipeline,本质是在回答一个问题
如果一定要给区域级 pipeline 一个核心问题,那就是:
“这一块区域,接下来应该交给谁来处理?”
你并不是在解析整页 PDF,而是在处理一组被拆分出来的区域。每个区域都有属性:
- 它在页面上的位置
- 它像什么(文本 / 表格 / 图像 / 其他)
- 它的置信度
- 它和其他区域的关系
Pipeline 做的事情,是围绕这些区域不断决策:
- 这个区域是否可信?
- 是否需要降级?
- 是否要换一种能力再试一次?
- 是否需要和其他区域合并或裁决?
这一步一旦拆开,后面的复杂度就不再是“模型复杂”,而是决策复杂。
一个典型的区域级 Pipeline,会经历哪些阶段
不同系统在实现上差异很大,但在抽象层面,区域级 pipeline 往往绕不开下面这些阶段:
- 页面级输入
接收 PDF 页面,处理旋转、裁剪、尺寸等基础问题 - 版面 / 区域检测
生成一组候选区域及其类型和置信度 - 区域级分流
根据区域类型,把任务交给不同能力 - 子任务插件处理
文本、表格、图像、公式,各走各的路径 - 结果聚合与裁决
解决冲突、去重、合并、修正 - 阅读顺序重建
把“一堆对的块”,重新拼成“能读的文档”
这张图并不是某一个具体项目的实现,而是区域级 Pipeline 在工程层面的一个抽象共性:模型能力负责“产出可能性”,而 pipeline 负责把这些可能性组织成可用结果。
你会发现,这套流程里,真正困难的部分并不在模型本身,而是在模型之后。
为什么在“都知道端到端更理想”的前提下,Pipeline 仍然存在
这其实是很多工程团队的真实矛盾。
从研究和产品想象上看,统一的多模态模型显然更优雅:
- 输入一页
- 输出结构化结果
- 少规则、少工程
但现实是,目前阶段的多模态模型,还很难同时满足这些要求:
- 稳定性:同一输入是否可复现
- 可控性:结果错了,怎么修
- 溯源能力:内容来自哪里
- 局部能力:是否能只重跑一小块
- 性能:在线业务通常要求一定时间内解析完成,一个个吐token太慢了。
于是,工程上出现了一种“明知不完美,但不得不用”的选择:
在模型成熟之前,用 pipeline 把系统兜住。
Pipeline 的存在,本身就是对模型能力边界的承认。
为什么很多开源方案,都“长得像 Pipeline”
如果你去看一些主流的开源 PDF / 文档解析方案,会发现一个很有意思的现象:
名字、实现、技术栈各不相同,但架构图看起来却出奇地相似。
它们几乎都在做同一件事:
- 先拆页面
- 再拆区域
- 再按区域类型调用不同能力
- 最后再想办法把结果拼回来
比如
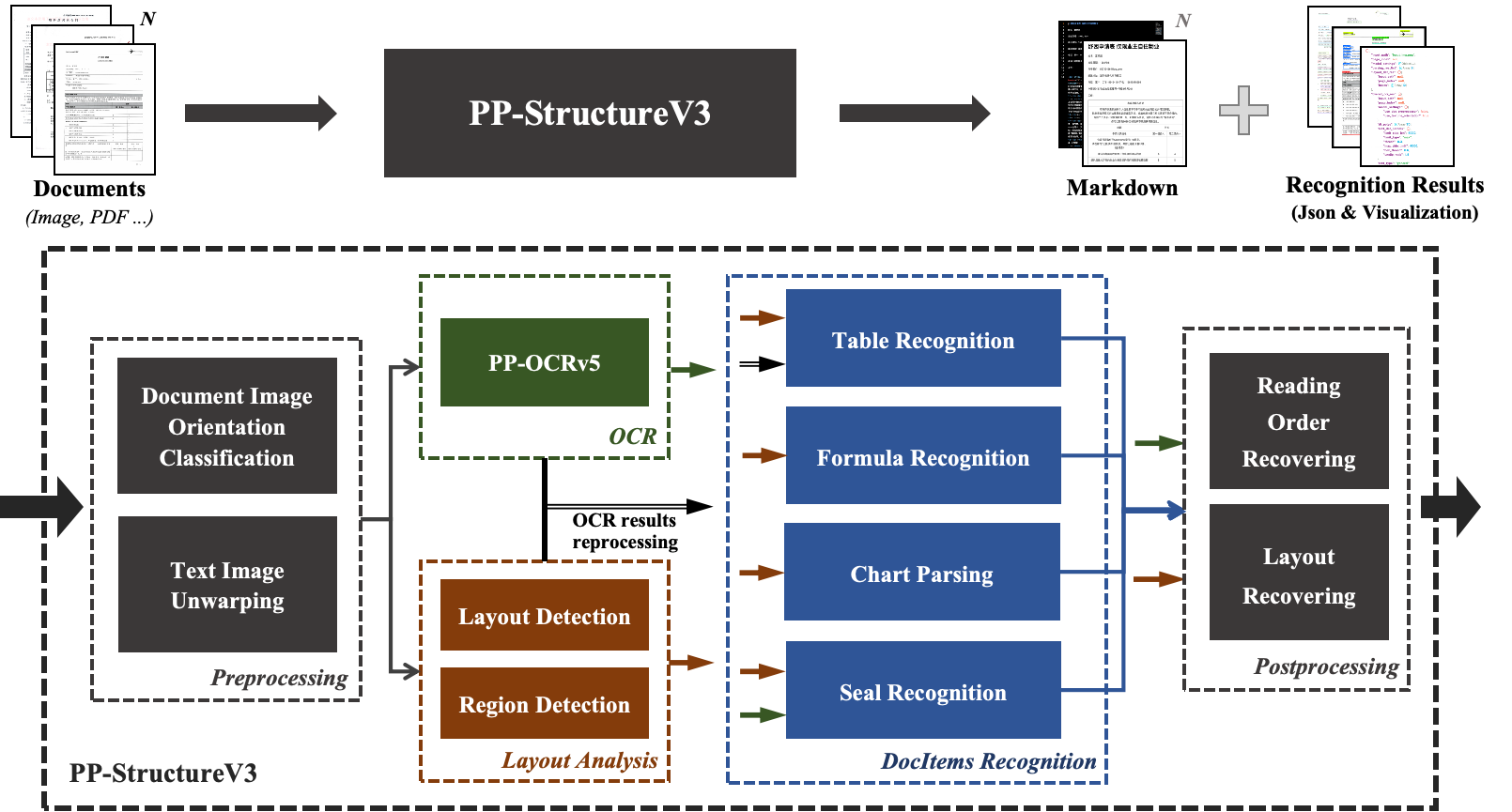
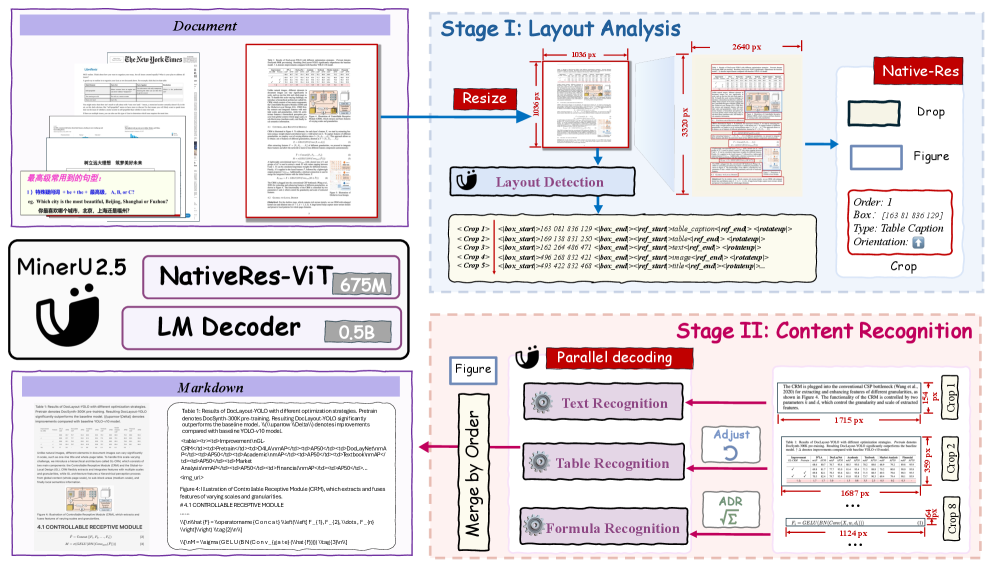
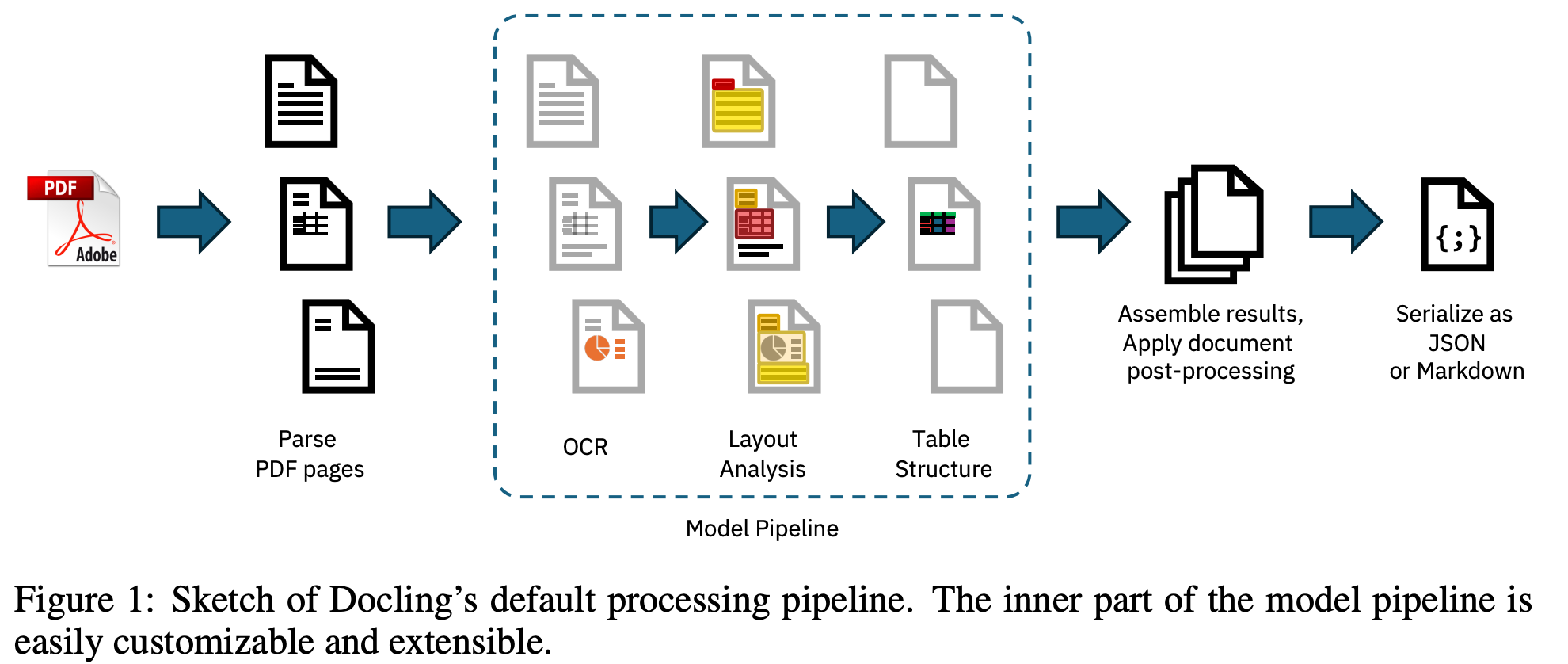
需要强调的是,这并不意味着:
“Pipeline 是行业终局。”
更准确的说法是:
在多模态模型尚未解决工程可控性之前,这是一个被反复验证过的现实选择。
事实上,上面列出的这些项目,也都实际上提供基于多模态的pipeline。作为给用户的选项。
Pipeline 的问题,从来不是“有没有”,而是“怎么收敛”
当然,pipeline 并不完美。
它的问题也非常明显:
- 链路长,调试成本高
- 决策逻辑复杂,容易失控
- 阅读顺序、冲突裁决极其脆弱
- 很难做到一次写完、长期不改
但真正成熟的系统,并不是试图消灭 pipeline,而是不断回答一个更现实的问题:
哪些不确定性,必须留在模型里?
哪些不确定性,必须由工程来兜?
这是 pipeline 能否“活下去”的关键。
小结:Pipeline 不是未来,但几乎是现在
所以,如果你问:
Pipeline 是不是 PDF 解析的未来?
我的答案会很保守。
Pipeline 不是一个优雅的终局解法,它更像是当前阶段的一种工程妥协。
但如果你再问一句:
在多模态模型真正成熟之前,工程上有没有更好的选择?
答案往往是否定的。
Pipeline 不是因为先进而存在,而是因为现实还不够先进。
下一章,我们会继续往 pipeline 里走一层,单独聊一个经常被低估、却决定最终体验的问题——阅读顺序。
那一章,几乎决定了解析结果“看起来像不像人写的”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 39
39 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)